







 博主分享了自己学习编译原理过程中实现词法分析器的经历。文章详细介绍了实验目的和内容,包括处理的关键字、运算符、标识符和整型常数的定义,以及如何处理空格。博主强调了实现过程中的逻辑思考,如何处理各种情况和交叉部分。最后,给出了实验要求和一个简单的源程序示例,展示词法分析后的输出序列。
博主分享了自己学习编译原理过程中实现词法分析器的经历。文章详细介绍了实验目的和内容,包括处理的关键字、运算符、标识符和整型常数的定义,以及如何处理空格。博主强调了实现过程中的逻辑思考,如何处理各种情况和交叉部分。最后,给出了实验要求和一个简单的源程序示例,展示词法分析后的输出序列。
闲话
最近在学编译原理,需要用语言实现一个词法分析器,其实挺简单的,主要涉及一些语言字符串操作处理,如果会正则表达式的话,感觉实现这个会很简单,但是我并不会啊,然后自己用java实现了,也算是加强了对java的一些字符操作方法的使用。
实现这个分析器,算法上基本上没什么难度,但是其中涉及的一些逻辑上的思考,说白了就是这么多种情况,有写情况还有交叉部分,你怎么让自己不绕进去,并且用代码实现自己的对这个问题思路。
那么闲话就说到这,具体我怎么想的,怎么处理的看下面
问题要求
####一、 实验目的
设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
####二、 实验内容
2.1 待分析的简单词法
(1)关键字:所有的关键字都是小写
begin if then while do end
-
(2)运算符和界符
- := + - * / < <= <> > >= = ; ( ) #
(3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义:
ID = letter (letter | digit)*
NUM = digit digit*
(4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、NUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:

2.3 词法分析程序的功能:
输入:所给文法的源程序字符串。
输出:二元组(syn,token或num)构成的序列。
其中:syn为单词种别码;
token为存放的单词自身字符串;
num为整型常数。
例如:对源程序begin x:=9; if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:
(1,begin) (10,x) (18,:=) (11,9) (26,;) (2,if)……
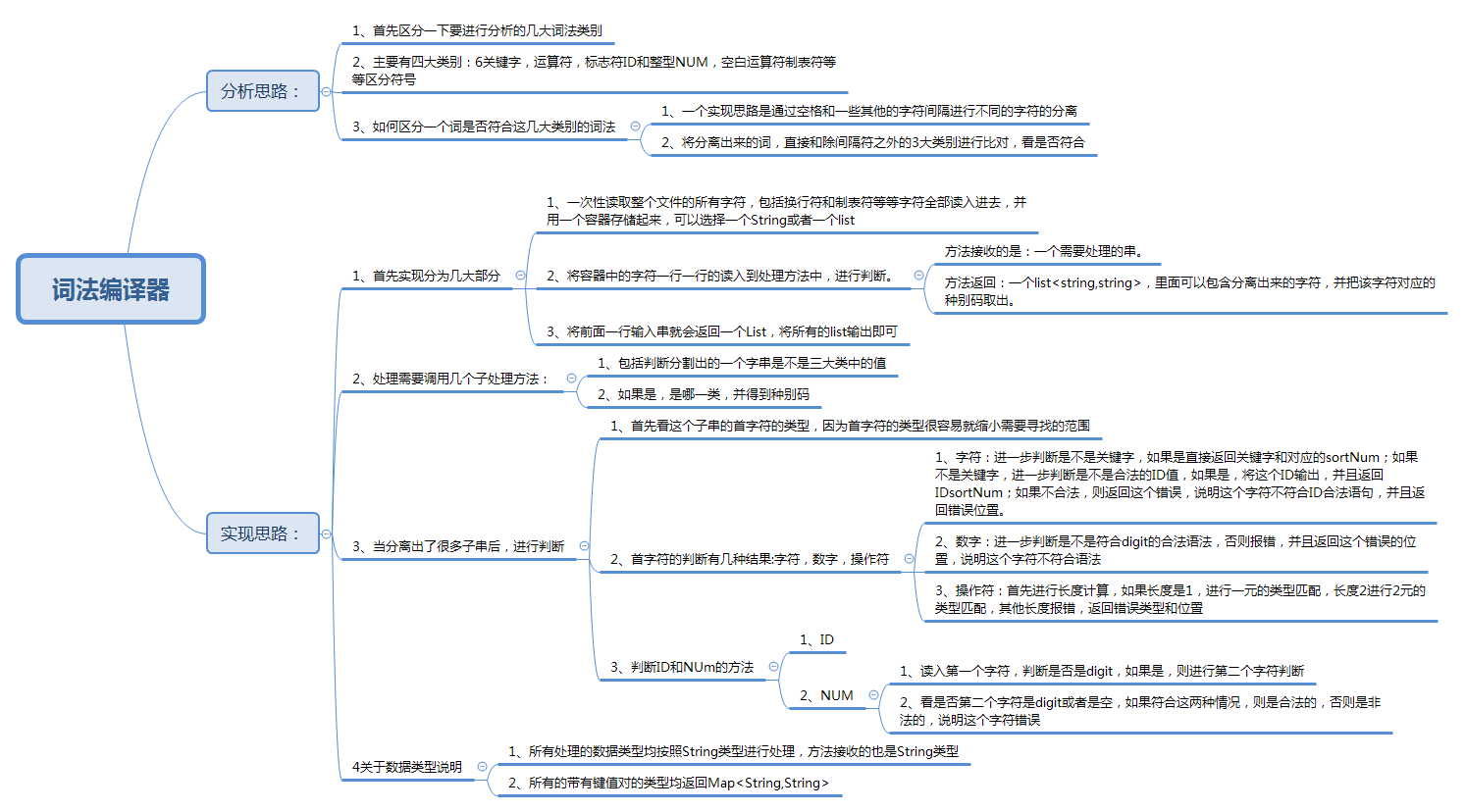
思维导图
先上思维导图, 根据思维导图看看我是怎么想这个问题的。

















 2646
2646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









