







📚概述
生产环境监控中,使用了
Prometheus监控MySQL数据库,可以监控到是否有慢查询,但是没有办法定位到具体的慢查询语句。MySQL数据库可以开启慢查询,并可以记录到日志中,这样我们就可以根据慢查询日志来定位具体的慢查询语句,并及时告警。通过Dashboards来实现日志分析。
📗MySQL慢查询配置
默认情况下,MySQL 并没有开启慢日志,可以通过修改 slow_query_log 参数来打开慢日志。与慢日志相关的参数介绍如下:
slow_query_log:是否启用慢查询日志,默认为0,可设置为0、1,1表示开启。
slow_query_log_file:指定慢查询日志位置及名称,默认值为host_name-slow.log,可指定绝对路径。
long_query_time:慢查询执行时间阈值,超过此时间会记录,默认为10,单位为s。
log_output:慢查询日志输出目标,默认为file,即输出到文件。
log_timestamps:主要是控制 error log、slow log、genera log 日志文件中的显示时区,默认使用UTC时区,建议改为 SYSTEM 系统时区(set global log_timestamps='SYSTEM';)。
log_queries_not_using_indexes:是否记录所有未使用索引的查询语句,默认为off。
min_examined_row_limit:对于查询扫描行数小于此参数的SQL,将不会记录到慢查询日志中,默认为0。
log_slow_admin_statements:慢速管理语句是否写入慢日志中,管理语句包含 alter table、create index 等,默认为 off 即不写入。
📐开启慢查询配置
默认情况下,MySQL是没有开启慢查询的。
开启慢查询可以通过my.cnf文件配置或者通过命令临时开启,通过my.cnf配置文件开启是永久有效的,但是需要重启MySQL数据库,通过命令开启,MySQL重启后失效。具体配置选择根据实际情况而定,开启慢查询在一定程度上会影响MySQL性能。我这里以配置命令的形式开启慢查询演示。
如果慢日志量比较大,就需要在合适的时间进行清理。
my.cnf配置文件
my.cnf一般在/etc/my.cnf目录
[mysqld]
# 慢查询日志,慢查询设置为2秒,超过2秒的查询会被写入慢查询日志
slow_query_log = on
long_query_time = 2
log_output = FILE
slow_query_log_file = D:\developer_tool\mysql-5.7.23-winx64\log\slow.log
slow_query_log:开启慢查询,on开启,off关闭
long_query_time: 慢查询阈值,即超过阈值即为慢查询
log_output:log输出形式,设置为FILE
slow_query_log_file: 慢查询文件路径
配置完重启MySQL服务即可。
💡命令配置开启慢查询
命令配置开启慢查询,重启MySQL服务后会失效。
查看慢查询开启情况
show variables like 'slow%';

slow_query_log: ON那么说明慢查询操作开启;OFF为未开启
slow_launch_time : SQL操作的时间阀值,单位秒
slow_query_log_file: 慢查询日志存放地址
开启/关闭慢查询
开启:set @@global.slow_query_log = ON;
关闭:set @@global.slow_query_log = OFF;
设置慢查询阈值
设置SQL超过2秒就记录到慢查询中
set @@global.long_query_time=2;
查看设置的值
show variables like '%query%';
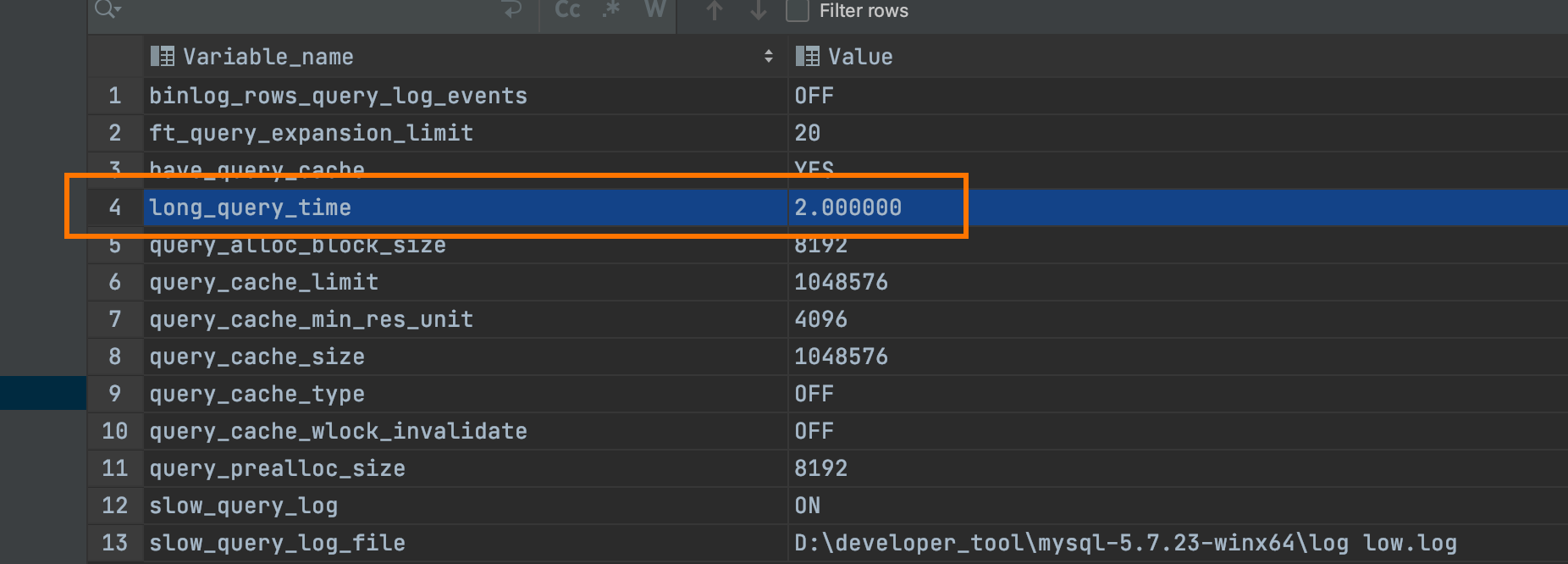
未使用索引是否开启记录慢查询日志
可根据需求配置开启。
【开启记录未使用索引sql:set @@global.log_queries_not_using_indexes=1/on】
【关闭记录未使用索引sql:set @@global.log_queries_not_using_indexes=1/off】
show variables like 'log_queries_not_using_indexes';查询未使用索引是否开启记录慢查询日志
使用
set @@global.log_queries_not_using_indexes=1/on等同于set global log_queries_not_using_indexes=1/on
慢查询日志配置
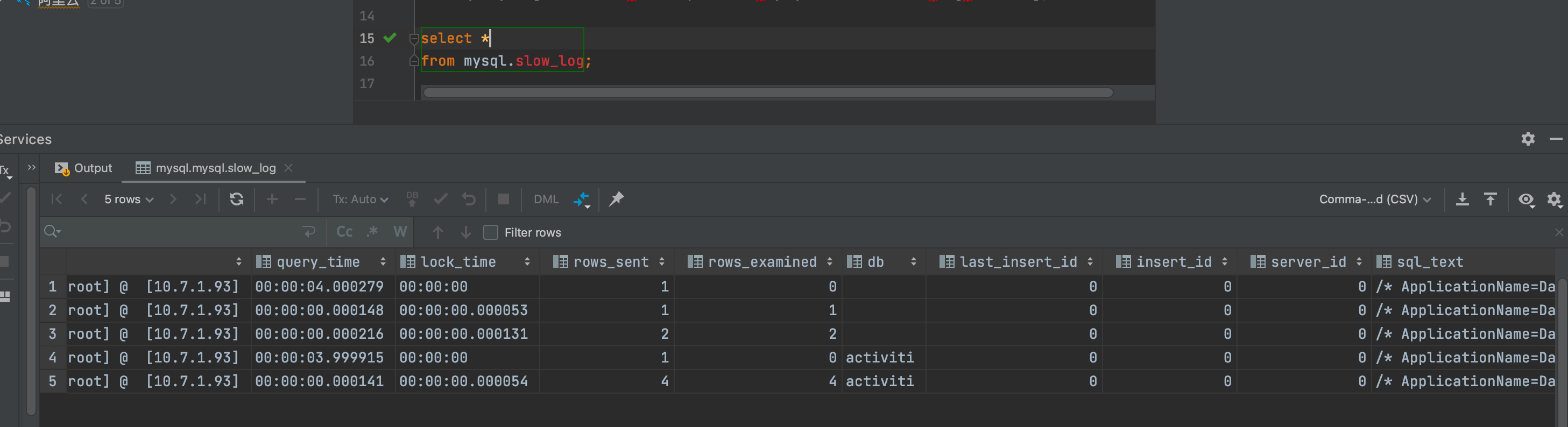
# 设置慢日志出入到表,可以在mysql.slow_log表中查询
set global log_output = 'TABLE';
# 设置为日志文件,需要单独配置日志文件路径
set global log_output = 'FILE';
# 设置文件路径
set global slow_query_log_file ='D:\\developer_tool\\mysql-5.7.23-winx64\\log low.log';
# 查看慢日志记录途径
show variables like 'log_output';
# 查看慢日志日志文件路径
show variables like 'slow_query_log_file';
mysql.slow_log表数据
📙慢查询日志格式
📐日志文件格式
# Time: 2022-11-25T04:55:56.460108Z
# User@Host: skip-grants user[root] @ [10.7.1.93] Id: 2
# Query_time: 14.999654 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
use activiti;
SET timestamp=1669352156;
/* ApplicationName=DataGrip 2020.3.2 */ select sleep(15);
# Time: 2022-11-25T12:11:31.666022Z
# User@Host: skip-grants user[root] @ [10.7.1.93] Id: 37
# Query_time: 0.000147 Lock_time: 0.000058 Rows_sent: 5 Rows_examined: 5
use activiti;
SET timestamp=1669378291;
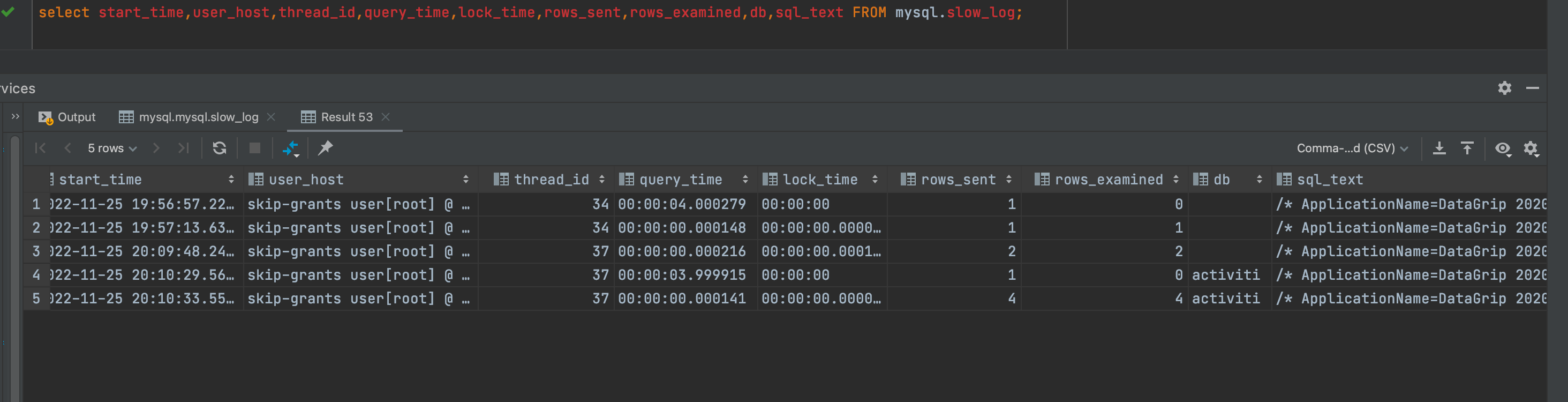
/* ApplicationName=DataGrip 2020.3.2 */ select *
from mysql.slow_log;
日志格式说明:
第一行:记录时间
第二行:用户名 、用户的IP信息、线程ID号
第三行:执行花费的时间【单位:毫秒】、执行获得锁的时间、获得的结果行数、扫描的数据行数
第四行:这SQL执行的时间戳
第五行:具体的SQL语句
慢查询日志异同点:
- 每个版本的
Time字段格式都不一样- 相较于
5.6、5.7版本,5.5版本少了Id字段use db语句不是每条慢日志都有的- 可能会出现像下边这样的情况,慢查询块
# Time:下可能跟了多个慢查询语句
💡mysql.slow_log表结构
SELECT COLUMN_NAME AS '字段名',
DATA_TYPE AS `数据类型`,
CHARACTER_MAXIMUM_LENGTH AS `字符长度`,
NUMERIC_PRECISION AS `数字长度`,
NUMERIC_SCALE AS `小数位数`,
IS_NULLABLE AS `是否允许非空`,
CASE WHEN EXTRA = 'auto_increment' THEN 1 ELSE 0 END AS `是否自增`,
COLUMN_DEFAULT AS `默认值`,
COLUMN_COMMENT AS `备注`
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = 'mysql'
AND TABLE_NAME = 'slow_log';
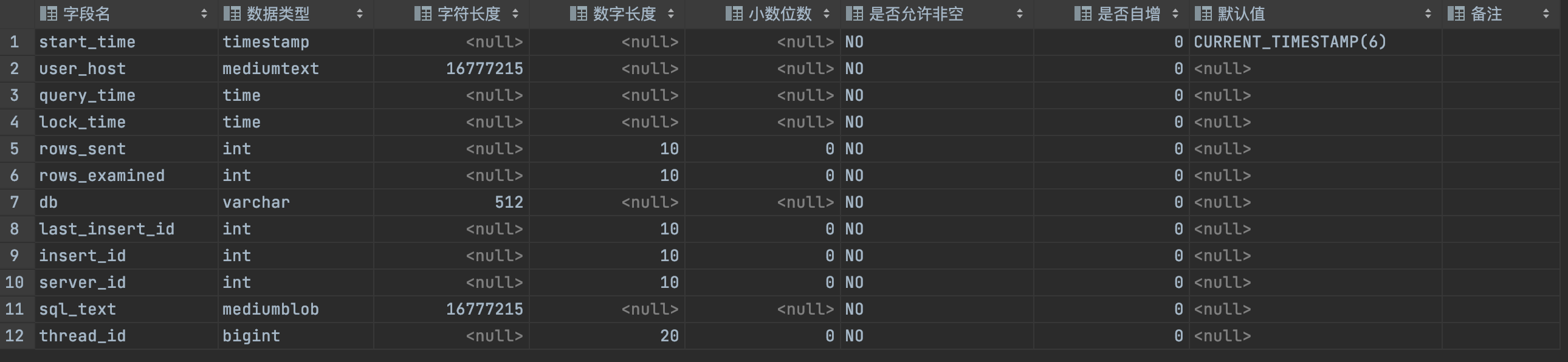
start_time:开始时间
user_host:用户名和IP
thread_id:线程ID
query_time:执行时间
lock_time:执行获取锁时间
rows_sent:获取结果行数
rows_examined:扫描数据行数
db:数据库实例
sql_text:具体SQL
🖲graylog采集日志
🎁处理思路
根据上边的日志格式,我们知道一般情况下日志由4-5行的数据,启动use database这一行不一定有。那么如何处理日志数据呢?
拼装日志行:MySQL 的慢查询日志多行构成了一条完整的日志,日志收集时要把这些行拼装成一条日志传输与存储,即需要实现多行合并。
Time行处理:# Time: 开头的行一定存在,可以根据该行来处理多行合并问题,不是以# Time开头的都合并到一行。
一条完整的日志:最终将以# Time开始的行,以SQL语句结尾的行合并为一条完整的慢日志语句。
确定SQL对应的DB:**use database**这一行不是所有慢日志**SQL**都存在的,所以不能通过这个来确定**SQL**对应的**DB**,慢日志中也没有字段记录**DB**,所以这里建议为**DB**创建账号时添加**db name**标识。例如我们的账号命名方式为:**projectName_dbName**,这样看到账号名就知道是哪个**DB**了。
确定SQL对应的主机:根据具体的filebeat来对应即可。filebeat中有相关的字段,例如source字段。
🏍️Sidecar-filebeat配置
使用filebeat采集慢SQL日志。通过graylog-sidecar形式采集,sidecar中的配置信息如下,包含了日志换行处理,以及filebeat配置的优化,新增了fields用于对日志分类,通过Stream中配置的规则,可以将日志存储到不同的index中。
# Needed for Graylog
fields_under_root: true
fields.collector_node_id: ${sidecar.nodeName}
fields.gl2_source_collector: ${sidecar.nodeId}
max_procs: 1 # 限制一个CPU核心,避免过多抢占业务资源
tags:
- windows
filebeat.inputs:
- type: log
enabled: true
multiline.pattern: '^# Time'
multiline.negate: true # 不符合上述规则
multiline.match: after # 追加在上条日志后边
tail_files: true # 定义是从文件开头读取日志还是结尾,这里定义为true,从现在开始收集,之前已存在的不管
ignore_older: 24h # 忽略这个时间之前的文件(根据文件改变时间)
fields: # 用于对日志进行分类处理,需要与运维系统中配置保持一致
app_name: mysql_slow_query_log # 应用服务编码,保持唯一
environment: pro # 环境 只支持生产和预生产 pro pre
log_type: MySQL # 日志类型 MySQL
paths:
- D:\developer_tool\mysql-5.7.23-winx64\log low.log # 日志路径
output.logstash:
hosts: ["10.0.107.55:5044"] # graylog服务端IP和端口,默认端口为5044
path:
data: C:\Program Files\Graylog\sidecar\cache\filebeat\data
logs: C:\Program Files\Graylog\sidecar\logs
🏷️Grok Pattern配置
MySQL慢日志中的数据看起来比较凌乱,不方便处理,为了做日志分析和查询,需要对慢日志进行字段解析处理。
在Graylog中使用Grok进行正则匹配即可。具体解析的配置如下:
#%{SPACE}Time:%{SPACE}%{TIMESTAMP_ISO8601:time}
#%{SPACE}User@Host:%{SPACE}%{DATA:user}%{SPACE}@%{SPACE}\[%{DATA:host}\]%{SPACE}Id:%{SPACE}%{NOTSPACE:thread_id}
#%{SPACE} Query_time:%{SPACE}%{BASE10NUM:query_time;float}%{SPACE} Lock_time:%{SPACE}%{BASE10NUM:lock_time;float}%{SPACE}Rows_sent:%{SPACE}%{BASE10NUM:rows_sent;long}%{SPACE}Rows_examined:%{SPACE}%{BASE10NUM:rows_examined;long}(?:\nuse %{DATA:db};|())
SET%{SPACE} timestamp=%{BASE10NUM:exec_timestamp;long};
%{DATA:sql}$
注意:
- 由于日志中可能没有
use database这一样,所以这里需要特殊处理,GrokPatern严格按照上述格式粘贴即可。Grok中对不同的字段制定了数据类型,方便后续做日志分析使用。
没有use database行时解析结果如下:
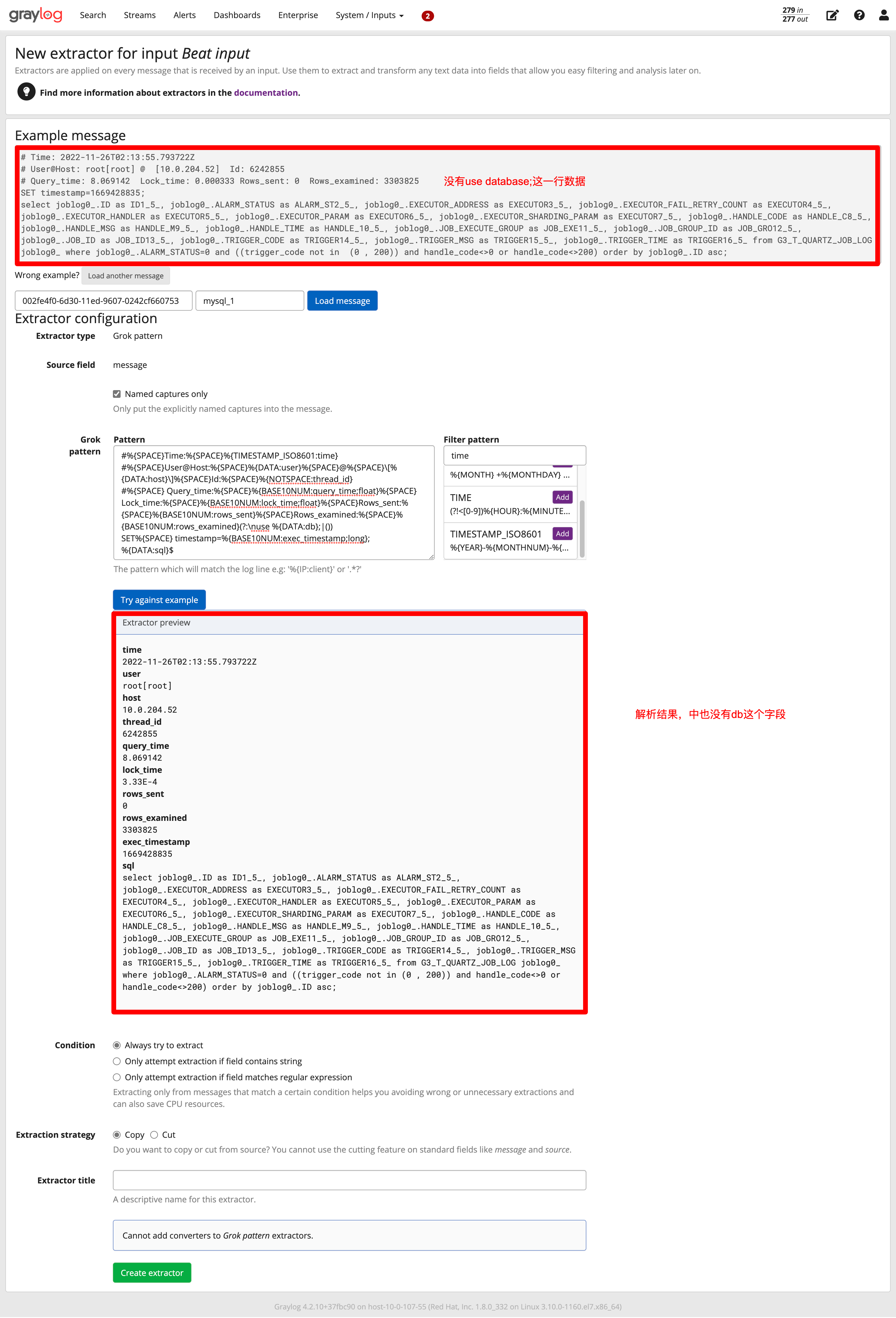
有use database解析结果如下:
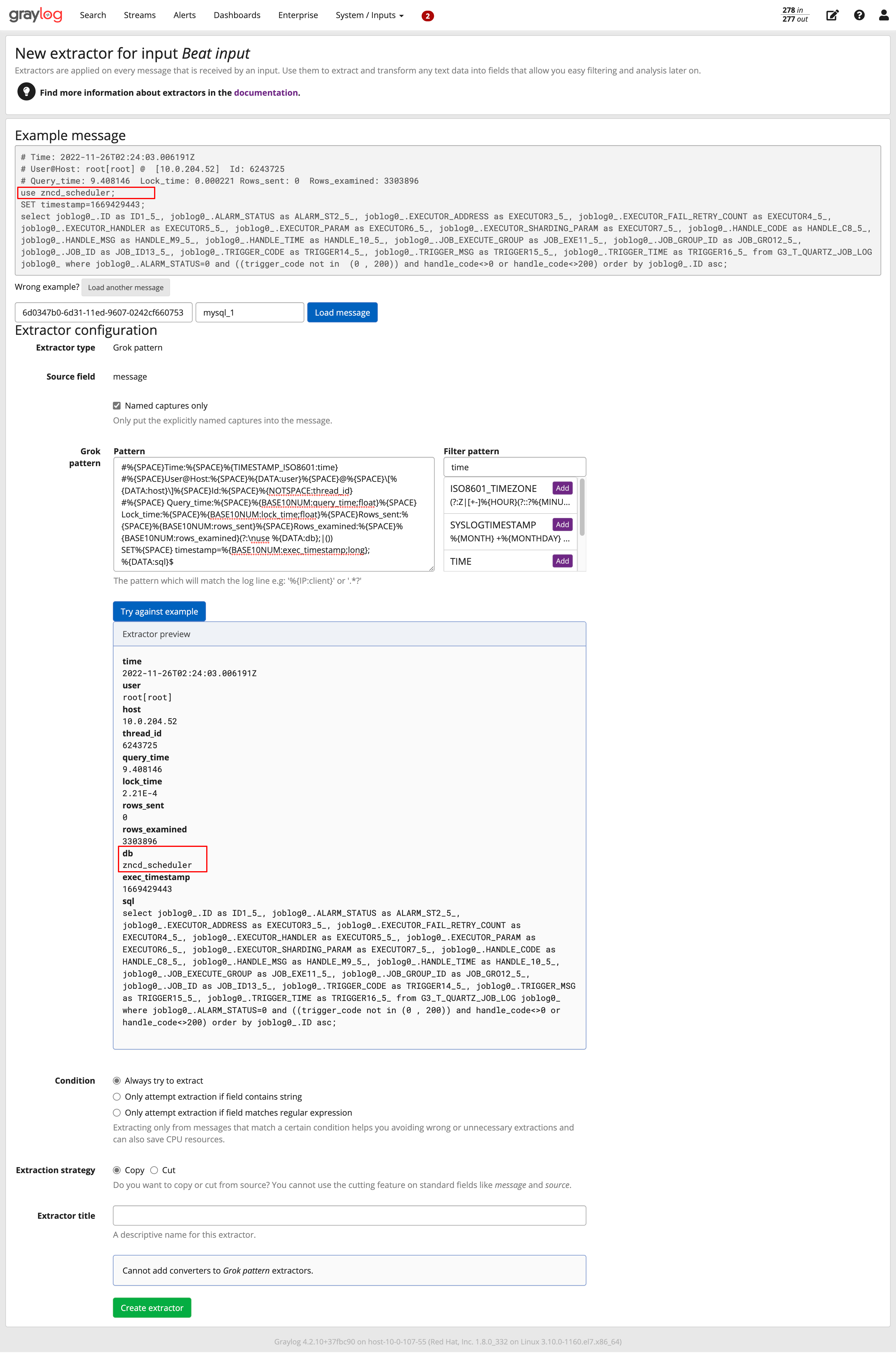
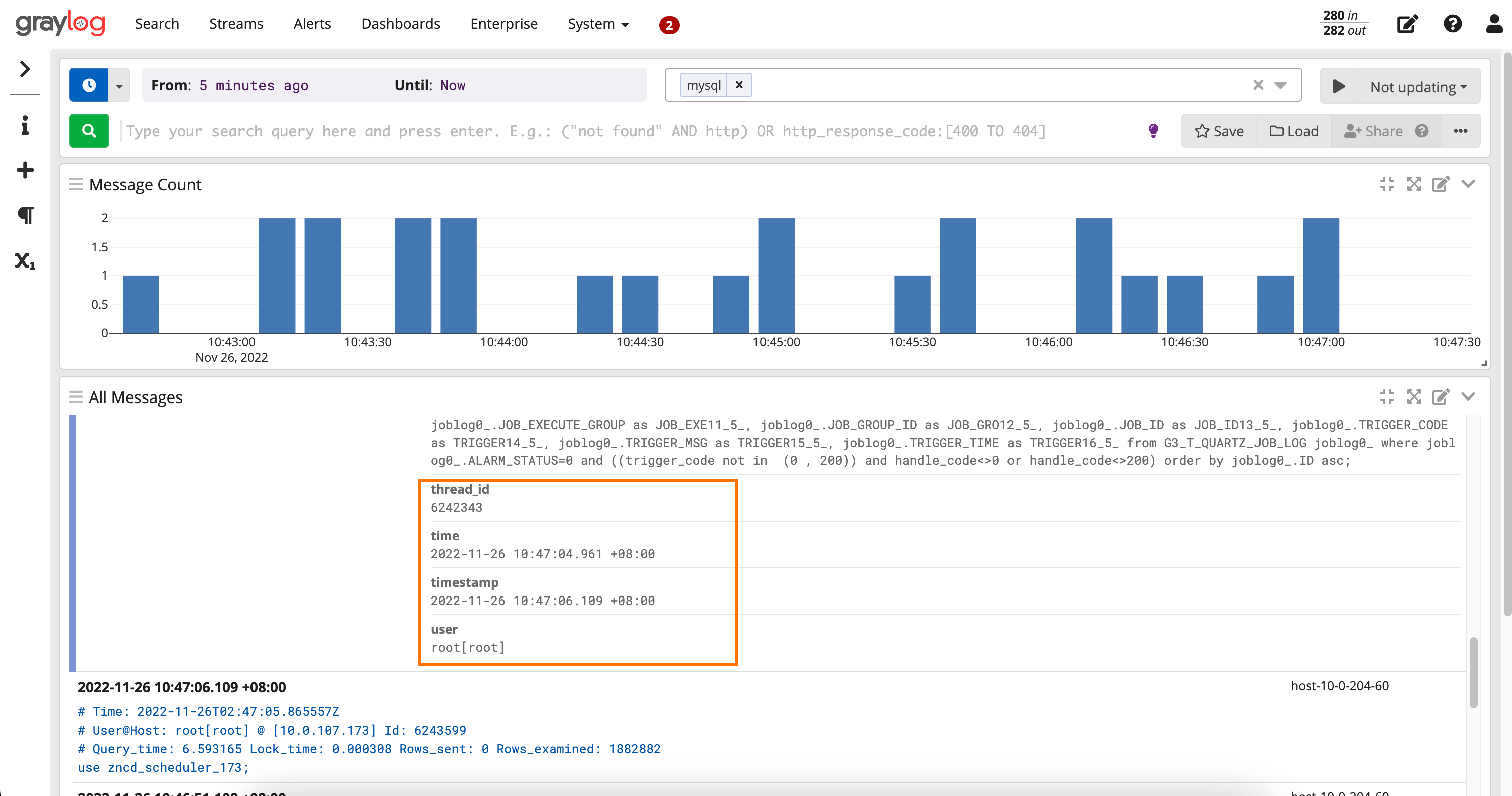
日志查看
按照上边的配置,我们已经把MySQL慢查询日志接入到Graylog中,并进行了字段解析。现在已经可以在Search中查看日志信息了。
📈使用Graylog进行MySQL日志分析
针对慢查询日志分析,MySQL官方提供了mysqldumpslow ,借助这个命令工具,可以辅助完成一些分析。但是现阶段已经使用了Graylog进行分析,那么就直接利用Graylog来呈现可视化页面即可。
🎢pipeline配置
由于部分慢查询没有database,所以需要对没有db字段的赋值一个指定值,避免日志分析分组时丢失数据。
rule "mysql db"
when
!has_field("db") && to_string($message.filebeat_fields_log_type) == "MySQL"
then
set_field("db","-");
end
📃Dashboard配置
整体效果:
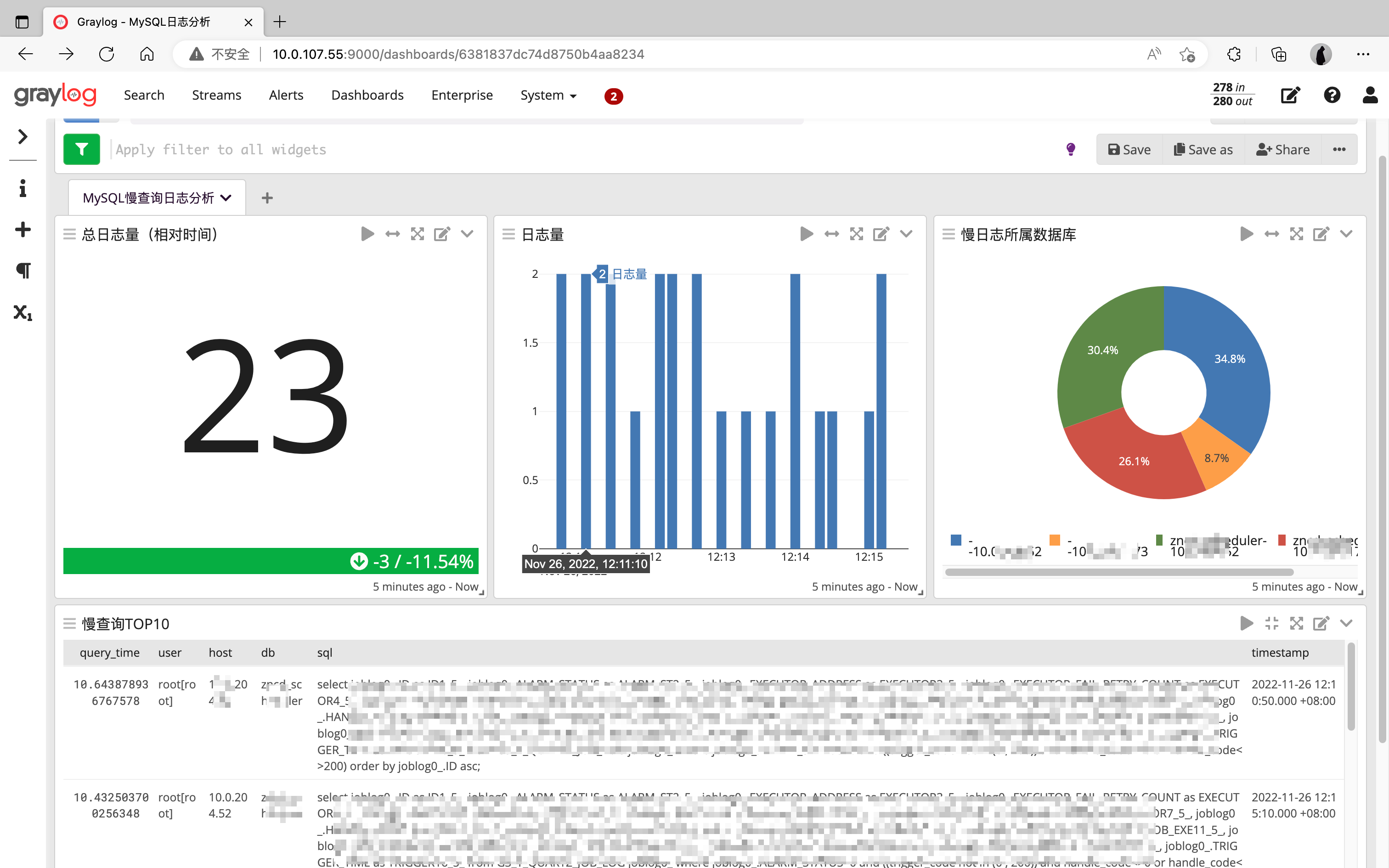
详细配置:
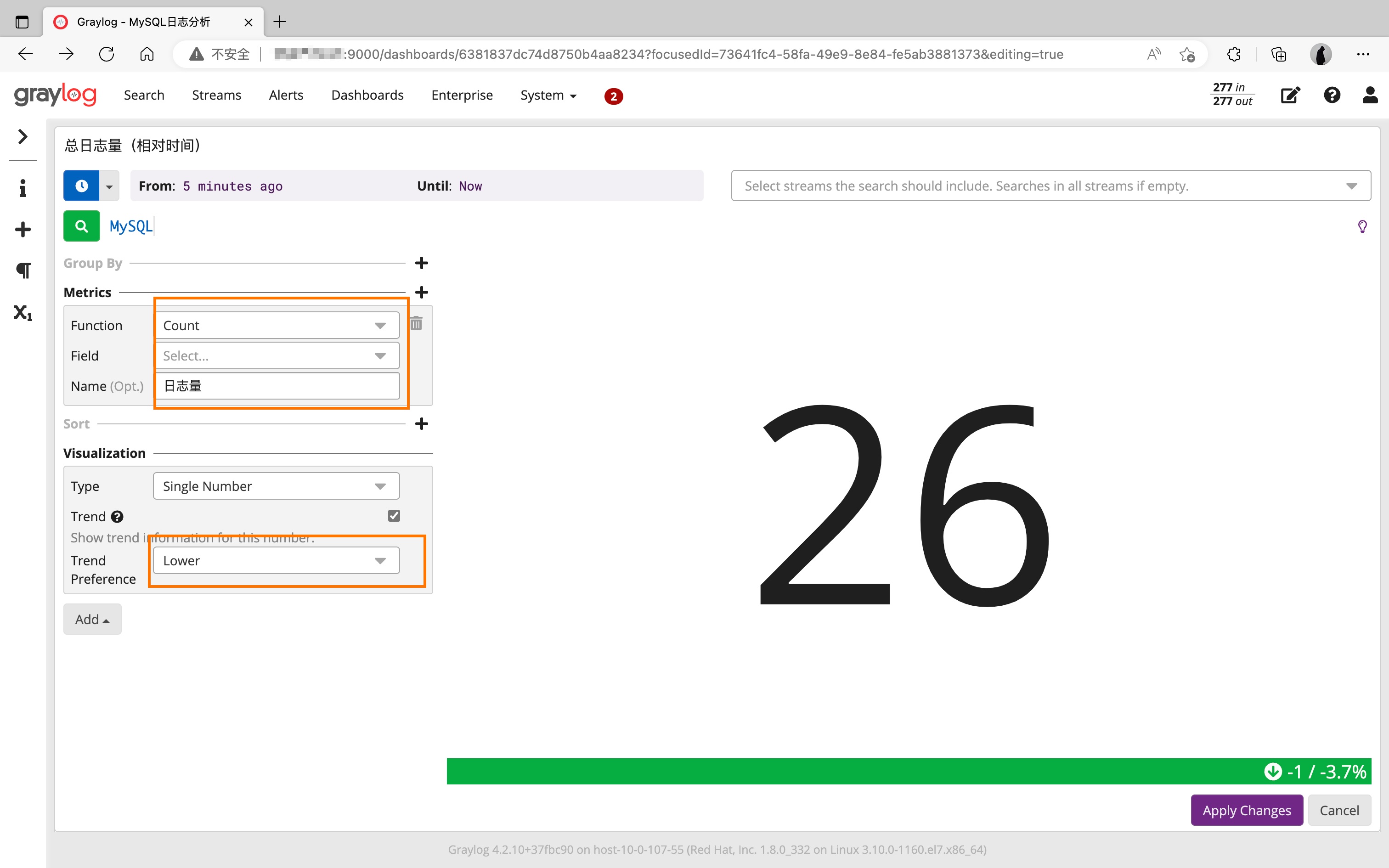
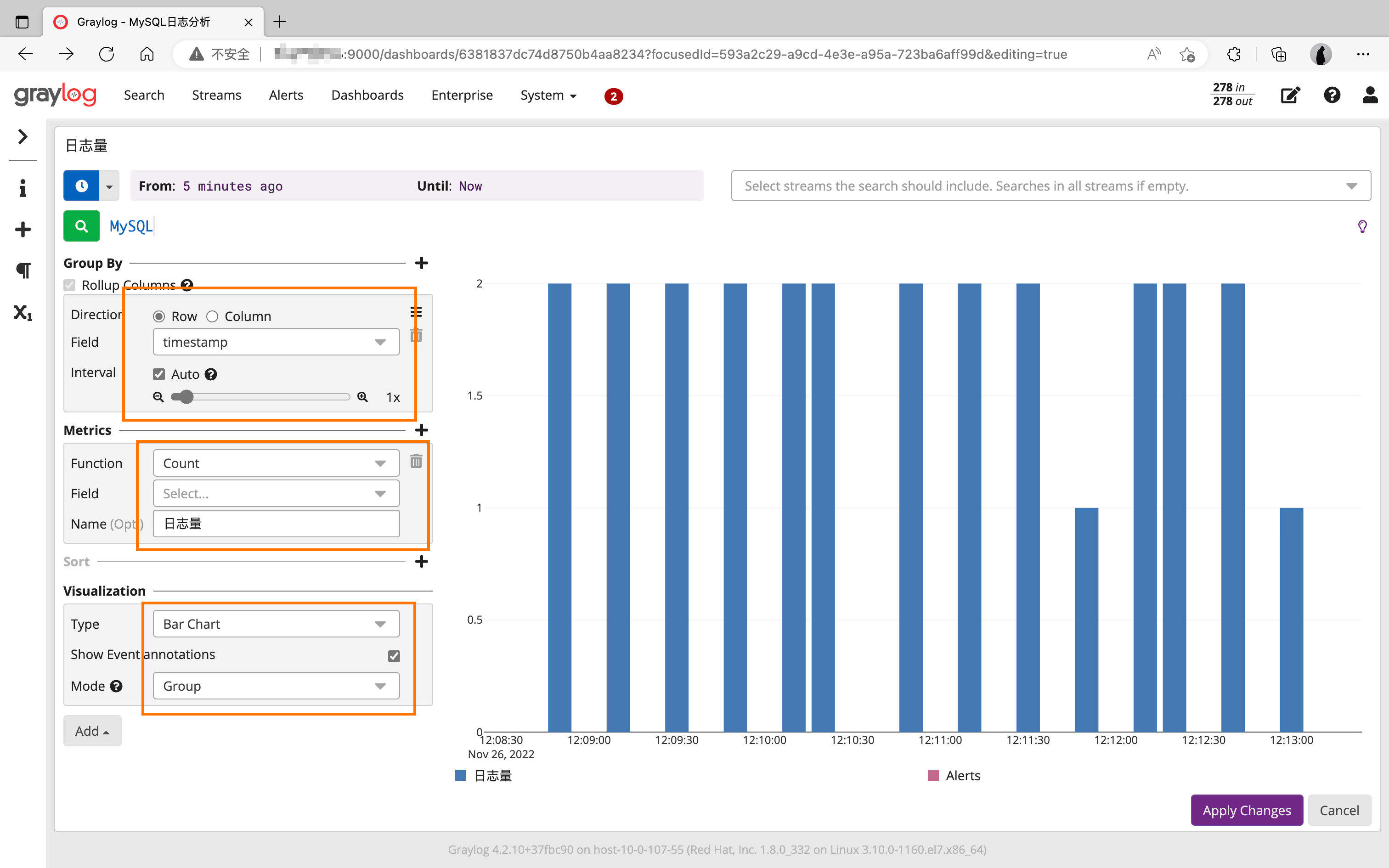
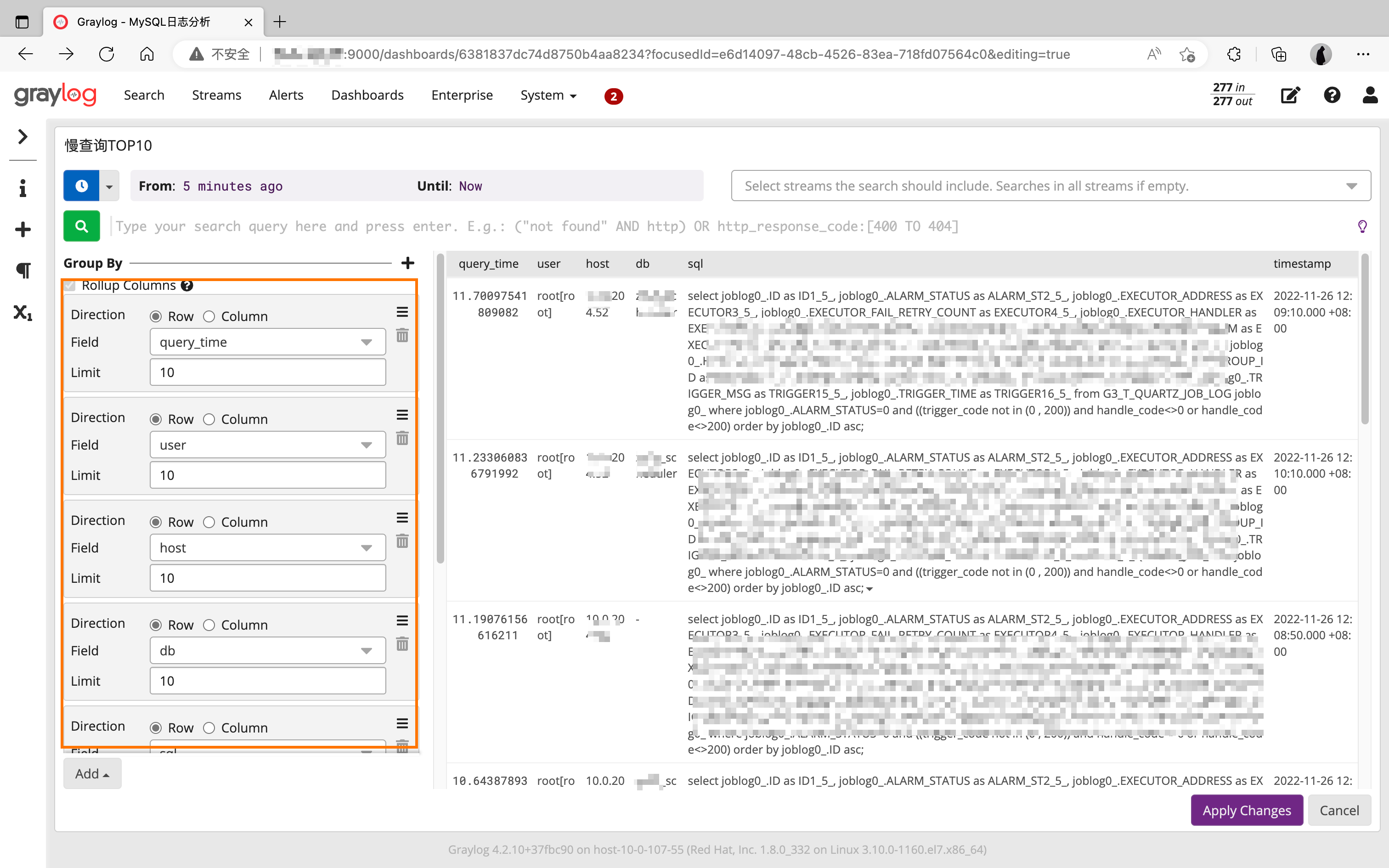















 1524
1524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









