







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文

指标(Metrics)
指标是对桶内的文档进行统计计算,如统计红色汽车的数量、最低价、最高价、平均售价、总销售额等,这些都是根据桶中的文档的值来计算的;
基本概念有所了解后一起通过实战来学习和掌握聚合的知识;
环境信息
以下是本次实战的环境信息,请确保您的Elasticsearch可以正常运行:
-
操作系统:Ubuntu 18.04.2 LTS
-
JDK:1.8.0_191
-
Elasticsearch:6.7.1
-
Kibana:6.7.1
导入实战数据
本次实战用到的数据来自《Elasticsearch权威指南》的示例;
- 实战会用到名为cars的索引,里面的每个文档是一条汽车销售记录,具体字段定义如下:
| 字段 | 类型 | 作用 |
| — | — | — |
| price | long | 汽车售价 |
| color | text | 汽车颜色 |
| make | text | 汽车品牌 |
| sold | date | 销售日期 |
- 通过静态映射的方式来创建索引,在Kibana的Dev Tools页面执行以下命令,就会创建cars索引和transactions类型,并且指定了每个字段的定义:
PUT /cars
{
“mappings” : {
“transactions” : {
“properties” : {
“color” : {
“type” : “keyword”
},
“make” : {
“type” : “keyword”
},
“price” : {
“type” : “long”
},
“sold” : {
“type” : “date”
}
}
}
}
}
- 导入数据:
POST /cars/transactions/_bulk
{ “index”: {}}
{ “price” : 10000, “color” : “red”, “make” : “honda”, “sold” : “2014-10-28” }
{ “index”: {}}
{ “price” : 20000, “color” : “red”, “make” : “honda”, “sold” : “2014-11-05” }
{ “index”: {}}
{ “price” : 30000, “color” : “green”, “make” : “ford”, “sold” : “2014-05-18” }
{ “index”: {}}
{ “price” : 15000, “color” : “blue”, “make” : “toyota”, “sold” : “2014-07-02” }
{ “index”: {}}
{ “price” : 12000, “color” : “green”, “make” : “toyota”, “sold” : “2014-08-19” }
{ “index”: {}}
{ “price” : 20000, “color” : “red”, “make” : “honda”, “sold” : “2014-11-05” }
{ “index”: {}}
{ “price” : 80000, “color” : “red”, “make” : “bmw”, “sold” : “2014-01-01” }
{ “index”: {}}
{ “price” : 25000, “color” : “blue”, “make” : “ford”, “sold” : “2014-02-12” }
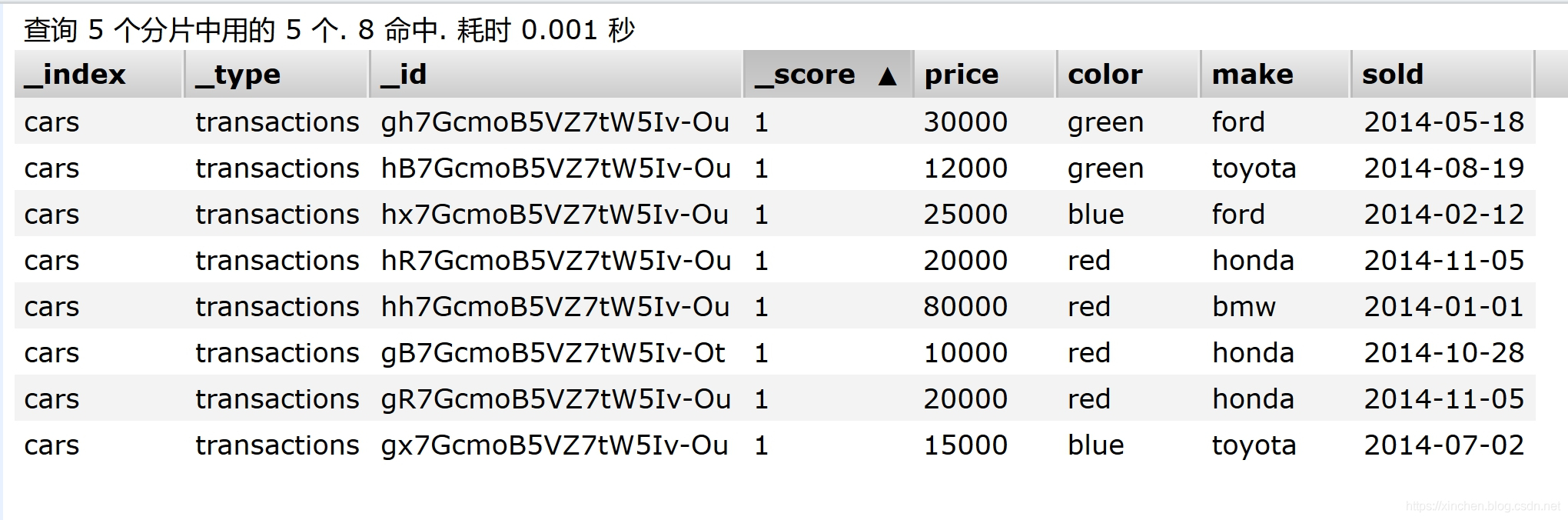
通过head插件看到新建的索引cars的所有数据如下图,例如第一条记录,表示售价30000,汽车颜色是绿色,品牌是ford,销售时间是2014年5月8日:
最简单的聚合:terms桶
第一个聚合命令是terms桶,相当于SQL中的group by,将所有记录按照颜色聚合,执行以下查询命令:
GET /cars/transactions/_search
{
“size”:0,
“aggs”:{
“popular_colors”:{
“terms”: {
“field”: “color”
}
}
}
}
收到响应如下:
{
“took” : 1,
“timed_out” : false,
“_shards” : {
“total” : 5,
“successful” : 5,
“skipped” : 0,
“failed” : 0
},
“hits” : {
“total” : 8,
“max_score” : 0.0,
“hits” : [ ]
},
“aggregations” : {
“popular_colors” : {
“doc_count_error_upper_bound” : 0,
“sum_other_doc_count” : 0,
“buckets” : [
{
“key” : “red”,
“doc_count” : 4
},
{
“key” : “blue”,
“doc_count” : 2
},
{
“key” : “green”,
“doc_count” : 2
}
]
}
}
}
现在对查询命令中的参数做出解释:
-
size设置为0,这样返回的hits字段为空(hits不是我们本次查询关心的内容),这样可以提高查询速度;
-
aggs:聚合操作都被至于aggs之下,注意aggs是顶层参数,另外使用aggregations替代aggs也可以;
-
popular_colors:为聚合的类型指定名称,本次是按照颜色来聚合的,所以起名为popular_colors,响应内容中可以看到该字段的聚合结果如下:
aggregations" : {
“popular_colors” : {
“doc_count_error_upper_bound” : 0,
“sum_other_doc_count” : 0,
“buckets” : [
{
“key” : “red”,
“doc_count” : 4
},
{
“key” : “blue”,
“doc_count” : 2
},
…
-
terms:在聚合的时候,桶的类型有很多种,terms是常用的一种,作用是按照指定字段来聚合,例如本例指定了color字段,所以所有color为red的文档聚合到一个桶,green的文档聚合到另一个桶,实际上桶类型是有很多种的,常见的类型在后面的实战中会用到,更多详细内容请参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.0/search-aggregations-bucket.html
-
field的值就是terms桶指定的聚合字段,这里是color字段;
-
接下来看看返回的信息,aggregations就是聚合结果,popular_colors是我们指定的别名,buckets是个json数组,里面的每个json对象都是一个桶,里面的doc_count就是记录数;例如结果中的第一条记录就是红色汽车的销售记录;
添加度量指标
-
上面的示例返回的是每个桶中的文档数量,接下es支持丰富的指标,例如平均值(Avg)、最大值(Max)、最小值(Min)、累加和(Sum)等,接下来试试累加和的用法;
-
下面请求的作用是统计每种颜色汽车的销售总额:
GET /cars/transactions/_search
{
“size”:0,
“aggs”:{
“colors”:{
“terms”: {
“field”: “color”
},
“aggs”:{
“sales”:{
“sum”:{
“field”:“price”
}
}
}
}
}
总结
对于面试还是要好好准备的,尤其是有些问题还是很容易挖坑的,例如你为什么离开现在的公司(你当然不应该抱怨现在的公司有哪些不好的地方,更多的应该表明自己想要寻找更好的发展机会,自己的一些现实因素,比如对于我而言是现在应聘的公司离自己的家更近,又或者是自己工作到达了迷茫期,想跳出迷茫期等等)

Java面试精选题、架构实战文档
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
聘的公司离自己的家更近,又或者是自己工作到达了迷茫期,想跳出迷茫期等等)
[外链图片转存中…(img-g3PdT7zV-1713471535501)]
Java面试精选题、架构实战文档
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-4xdYNaj6-1713471535501)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 171
171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









