






此处代码来自王道数据结构考研复习指导书中第二章顺序表的基本操作的实现:

在顺序表中:
代码中的 i 表示 顺序表的位序;而 length 表示 顺序表当前的长度,即 数据元素的个数;
在数组中:
代码中的 i 等价于 数组下标 i-1;而 length 等价于 数组下标为 length - 1;(这是因为数组下标是从0开始计数的,而位序泛化的说就是位置,是从1开始计数的)
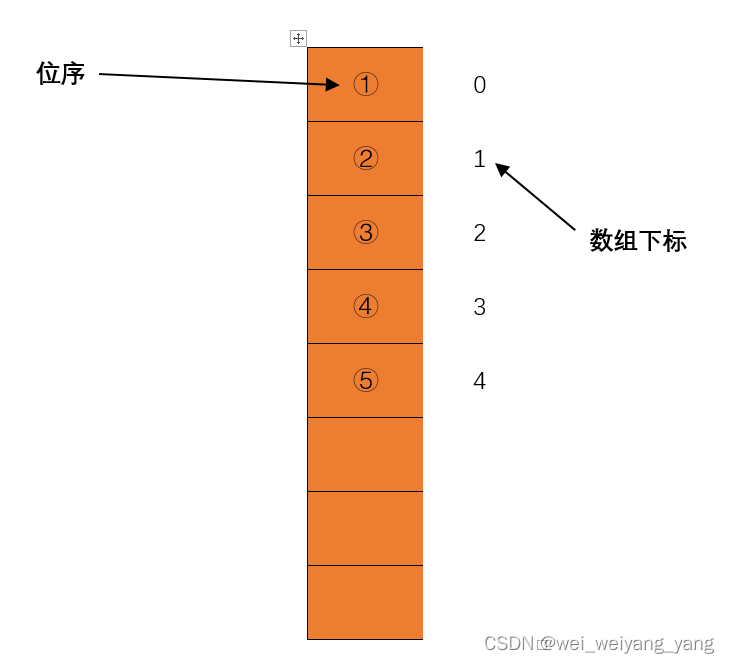
那么,
当 i = 1 时就是向位序为 1 的位置插入新的元素,即把原先存在第一个位置(位序为 1)的元素及其后面的所有元素依次往后移一个位置,然后把该新元素插入空出来的第一个位置;
当 i = length + 1 时,就是向顺序表的末尾位置(此时位序为 length)后面插入新的元素;为什么这么说呢?当然是有依据的。因为前面刚刚提到过 length 表示的含义,是该顺序表的长度,也是该顺序表中最后一个元素的位序,所有 i = length +1 则是向位序为 length 的后面插入新的元素,此时新的元素的位序是 length + 1;
故 i 的范围是 [ 1 , length +1 ],在判断插入时 i 的值是否合法时,i 的值为什么要满足
i<1 || i>length +1。其实答案是一目了然了,就是让 i 的值不在 i 的范围中,即 i 的值不合法。
而移动元素的for语句为什么是 j = length 和 j >= i,那是因为要在第 i 个位序插入了新的元素,就要保证第 i 个位序有空位,所有就要让原有在第 i 个位序上的元素及其它后面的所有元素通通往后面挪一个位置,所有原来的顺序表长度增加了,变为 length+1 了,数组下标为 length 。所以才有后面的操作:
L.data[ j ] = L.data[ j - 1 ];
j -- ;
直到 j = i 为止,L.data[ i ] = L.data[ i - 1 ]; 其中 L.data[ i - 1 ] 表示位序为 i 的元素

运行完该for语言代码后即表示把原有在第 i 个位序(数组下标为 i - 1)上的元素及其它后面的所有元素通通往后面挪一个位置。
所以说移动元素的for语句是 j = length 和 j >= i。
















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











