




2022年6月阿里云发布了全新的云计算架构-CIPU,这是下一代云计算的核心基础设施。我们知道CPU、GPU是中央处理器和图形处理器,而CIPU是云基础设施处理器,即云时代数据中心内部的专用处理器,是为阿里云飞天操作系统量身定制的硬件,对计算存储,网络都具有云介入能力,并且能够实现硬件加速,完成超高的性能提升。

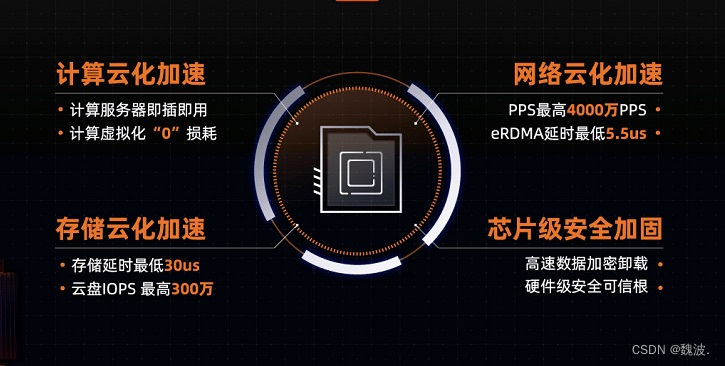
现在的云计算面临着客户对低时延和高带宽的强烈需求,特别是数据中心越来越多,越来越分散之后,一个大的应用会分布在多个子系统中进行部署,而这些系统之间往往需要高速的互联才能满足云计算需求,这样一来内部消耗的网络和流量就会随着规模水涨船高,而CIPU是网络加速和存储加速的结合体,相当于新开了一条高速公路,把各种设备连接起来,让数据跑得更快更流畅。
我们最关心的还是CIPU对算力资源本身有什么影响,回顾一下云计算的发展过程,其实就是一个算力不断虚拟化的过程,想要上云就要把分布式在不同地方的计算机资源虚拟化,用软件定义的方式把以物理节点形式,分散、分布的算力资源汇总成一个大池子,然后根据用户不同需求进行算力的分配使用。为了完成这个虚拟化,云计算服务器必然要消耗额外的算力,采用软件定义方式的确可以提升云资源利用的便捷性,但势必会损失一些硬件的性能,这也就是所谓的云计算“税”,比如原本10核的CPU,其中可能需要拿出两核用来支持虚拟化,也就是跑云系统。这就会像你买房时的公摊面积,而CIPU的出现突破了数据中心的传统计算体系架构,让云系统跑在CIPU上,CPU用来跑系统的算力,这样就能实现100%的算力虚拟化,也就是公摊面积由开发商承担。
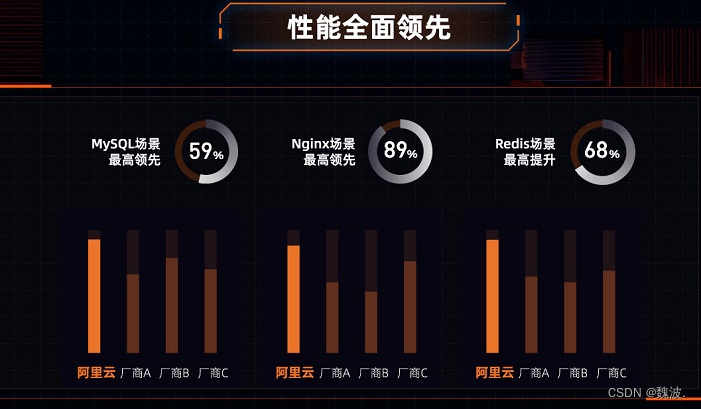
数据显示,CIPU加飞天操作系统以后,数据库、AI深度学习等场景性能提升20%~80%。阿里通过软硬结合,消除了数据中心内部的税,真正做到了普惠用户。
云计算是各行各业走向数字化的重要基础设施,还需要更多创新引导行业发展,实现云上生态的繁荣。



















 5207
5207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











