






写在最前面
此贴纯属记录今天的探索过程,在实际中,为解决问题可能会采用手动生成(如人数少),或VBA代码加手动修改等方法,而不会这样无聊去研究一天。我也把主要的代码以及最后得到的数据,共享给大家,可直接下载使用。
链接: https://pan.baidu.com/s/1896YPdDgRdGcSsVTeYKy_Q?pwd=eyc6 提取码: eyc6
因此,纯属探讨,欢迎高手批评指教。
一、需求的提出
在做点菜系统、学生管理系统等需要快速查询的功能时,常会将汉字的首字母提取出来,作为模糊查询时使用。例如,查询“张三”时,用“ZS”肯定比输入汉字快捷,还避免了同音字的问题。
二、网上的解决办法
VBA编程的方法
网上比较好找,大概的代码如下:(VBA代码,好像CSDN不支持)
Function pinyin(p As String) As String
i = Asc(p)
Select Case i
Case -20319 To -20284: pinyin = "A"
Case -20283 To -19776: pinyin = "B"
Case -19775 To -19219: pinyin = "C"
Case -19218 To -18711: pinyin = "D"
Case -18710 To -18527: pinyin = "E"
Case -18526 To -18240: pinyin = "F"
Case -18239 To -17923: pinyin = "G"
Case -17922 To -17418: pinyin = "H"
Case -17417 To -16475: pinyin = "J"
Case -16474 To -16213: pinyin = "K"
Case -16212 To -15641: pinyin = "L"
Case -15640 To -15166: pinyin = "M"
Case -15165 To -14923: pinyin = "N"
Case -14922 To -14915: pinyin = "O"
Case -14914 To -14631: pinyin = "P"
Case -14630 To -14150: pinyin = "Q"
Case -14149 To -14091: pinyin = "R"
Case -14090 To -13319: pinyin = "S"
Case -13318 To -12839: pinyin = "T"
Case -12838 To -12557: pinyin = "W"
Case -12556 To -11848: pinyin = "X"
Case -11847 To -11056: pinyin = "Y"
Case -11055 To -2050: pinyin = "Z"
Case Else: pinyin = p
End Select
End Function
Function getFirstLetter(str)
For i = 1 To Len(str)
getFirstLetter = getFirstLetter & pinyin(Mid(str, i, 1))
Next i
End Function参考网址:https://www.cnblogs.com/flyingfishing/p/12925577.html
存在的问题是:很多汉字不准确,例如:以下的字都返回的字母“Z”。
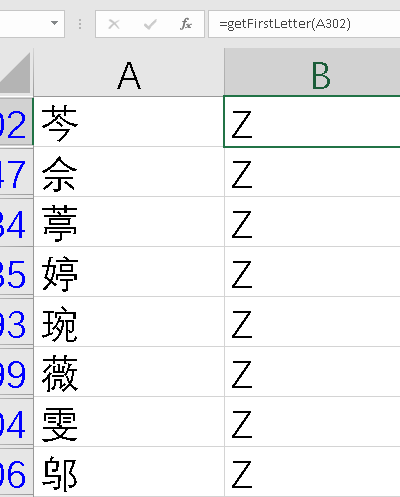
通过word的拼音指南来提取
即先在word自动生成拼音,再复制到excel中,通过phonetic函数进行提取。不但能获得首字母,还能获得带声调的拼音。
参考网址:利用Excel+Word巧妙提取汉字拼音 - 简书 (jianshu.com)
三、我的解决办法
下载一份常用汉字。文件 (lanzoui.com)。并把这份汉字去掉回车、去掉空格,存在hanzi.txt中。
通过python爬虫抓取百度汉语上的拼音。
import json
import traceback
import requests
import re
cnt = 0
cnt_e = 0
dic = dict()
with open("hanzi.txt", "r", encoding='utf-8') as f: # 打开文件
words = f.read() # 读取文件
for word in words:
cnt += 1
print(cnt, ",", word)
# 设置URL
url = "https://dict.baidu.com/s?wd={}&ptype=zici".format(word)
response = requests.get(url)
response.encoding = 'utf-8'
page_text = response.text
# 空字符处理。
page_text = page_text.replace(chr(8194), '')
page_text = page_text.replace(chr(10), '')
page_text = page_text.replace(chr(32), '')
page_text = page_text.replace(chr(13), '\n')
# 用正则找出拼音来
reg = re.compile(r'<divclass="pronounce"id="pinyin"><span>(\S*</b>)<aherf')
tmp = ''
try: # 有个别字返回的格式不一样,需要单独处理。
tmp = reg.findall(page_text)[0]
except Exception as e:
traceback.print_exc()
cnt_e += 1
reg = re.compile(r'<b>(\w*)</b>')
lst = reg.findall(tmp)
tmp = ",".join(lst)
dic[word] = tmp
with open('dic.txt', 'w', encoding='utf-8') as f:
# 将dic dumps json 格式进行写入
f.write(json.dumps(dic, ensure_ascii=False))整理抓取到的数据。把带音调的字母,替换成普通的字母。
抓取的结果:

去除查不到的字
import json
with open('dic.txt', 'r', encoding='utf-8') as f:
tmp = f.read()
dic = eval(tmp)
with open('没查到的汉字.txt', 'r', encoding='utf-8') as f:
words = f.read()
for word in words:
del dic[word]
with open('dic_exist.txt', 'w', encoding='utf-8') as f:
f.write(json.dumps(dic, ensure_ascii=False))
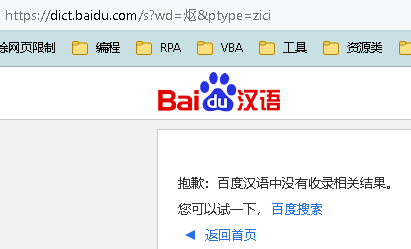
清洗好后的数据,存到数据表。
把带声调的字母,换成普通字母。
提取首字母。
去掉同样的,比如“干”一声和“干”四声,声母是相同的。用集合。
输出到txt 时,采用tab分隔。
import re
with open('dic_exist.txt', 'r', encoding='utf-8') as f:
tmp = f.read()
dic = eval(tmp)
lst = []
for key in dic:
lst.append('{}\t{}'.format(key, dic[key])) # 字和拼音中间用tab分隔,便于复制到excel。
tmp = '\n'.join(lst) # 两个字之间用回车分隔,便于复制到excel中。
# 把结果写入dic_with_tone.txt
with open('dic_with_tone.txt', 'w', encoding='utf-8') as f:
f.write(tmp)
# 以下用正则把声调去掉
dic_rep = {'ā|á|ǎ|à': 'a', 'ō|ó|ǒ|ò': 'o', 'ē|é|ě|è': 'e', 'ī|í|ǐ|ì': 'i', 'ū|ú|ǔ|ù': 'u', 'ǘ|ǚ|ǜ': 'v'}
for key in dic_rep:
reg = re.compile(key)
tmp = reg.sub(dic_rep[key], tmp)
# 把结果写入dic_no_tone.txt
with open('dic_no_tone.txt', 'w', encoding='utf-8') as f:
f.write(tmp)
# 再把首字母找出来,去掉同样的,比如“干”一声和“干”四声,声母是相同的。
lst_return = []
lst = tmp.split('\n')
set_first_letter = set()
for line in lst:
# line 代表去掉声调后的每一行
[word, pinyin] = line.split('\t')
yinjies = pinyin.split(',') # 把拼音按逗号分成若干音节,结果是列表
for yinjie in yinjies:
set_first_letter.add(yinjie[0].upper())
lst_return.append('{}\t{}'.format(word, ','.join(set_first_letter))) # 用集合去重
set_first_letter.clear()
with open('dic_first_letter.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(lst_return))
你可以想你不到,“丁”和“厂”都是多音字:
丁dīng,zhēng
厂chǎng,ān
由于我的应用场景很简单,暂时就存在excel表格中,通过vlookup函数进行查询。最后成功了7894个。
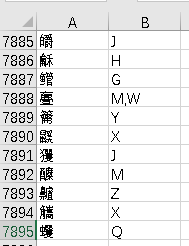
四、多音字探讨
例如,“茜”,xi,qian。比如一个员工叫“张茜”,首字母可能是“ZX”或者“ZQ”。
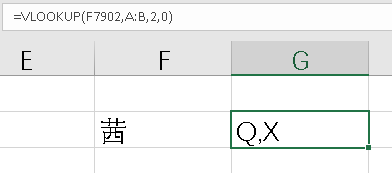
在生成名字首字母时,可以两个都生成,即“ZQ,ZX”,这样在模糊查询时,就可以解决多音字的问题。















 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









