







九、排序
一组数据按照其相应的关键字的大小进行非递减或非递增的排序。
9.2定义
-
多个关键字的排序,可以转换单个关键字的排序。
比如字符串的相加。 -
稳定性:两个关键词相等的数据,排序后的先后关系和排序前一致,则排序方法是稳定的。反之,不稳定。
-
内排序 : 排序过程中,所有数据全部被放在内存。
外排序:数据太多,不能同时放在内存,需要内外存多次交换数据。 -
内排序的性能分析:
a. 时间性能(比较和移动)
b. 辅助空间
c.算法的复杂性
根据排序中主要操作:分为插入排序,交换排序,选择排序,归并排序。
根据复杂度分为:
简单算法:冒泡,简单选择,直接插入。
改进算法:希尔排序,堆排序,归并排序,快速排序。
9.3冒泡排序
冒泡排序(Bubble Sort):两两比较相邻记录的关键字,如果反序进行交换,直到没有反序。
1.最简单的交换排序
不算冒泡排序,意义是让lists[0]的值小于其他值,然后是lists[1]…
for i in range(len(lists)):
for j in range(i+1,len(lists)):
if lists[i]>lists[j]:
lists[i],lists[j] = lists[j],lists[i]
2.冒泡排序
比较的是相邻元素,最小的元素从最底端一直到最顶端。
for i in range(len(lists)):
#注意从后往前
for j in range(len(lists)-1,i,-1):
if lists[j-1]>lists[j]:
lists[j-1],lists[j] = lists[j],lists[j-1]
3.优化:针对已经有序的情况
如果某一次遍历,整体没有发生交换,说明已经有序 ,可提前终止。
bool flag = True
for i in range(len(lists)):
#注意从后往前
flag = False
for j in range(len(lists)-1,i,-1):
if lists[j-1]>lists[j]:
lists[j-1],lists[j] = lists[j],lists[j-1]
flag = True
if not flag:
break
书上只有这一种排序 。
其他优化:
第二种:当列表尾部部分元素提前完成顺序时,不再进行比较。
第三种:鸡尾酒排序,双向比较交换,无交换时排序结束。
#先M,这两种回头再看。
L = [2, 4, 3, 9, 7, 5, 1, 8, 6]
minindex = 0
maxindex = len(L)
for i in range(len(L)//2):
swap = False
for j in range(minindex+1, maxindex):
if L[j-1] > L[j]:
L[j-1], L[j] = L[j], L[j-1]
maxindex = j
for k in range(maxindex-1, minindex, -1):
if L[k-1] > L[k]:
L[k-1], L[k] = L[k], L[k-1]
minindex = k #当前半段提前完成排序时也不用再比较了
swap = True
if not swap:
break
print(L)
4.复杂度
最好情况:数组有序,需要n-1次比较,交换0次。O(n)
最坏情况:逆序,比较n*(n-1)/2次。并进行相同的移动。复杂度O(n2)
9.4简单选择排序
1.简单选择排序(Simple Selection Sort)通过n-i次关键字的比较,在n-i+1个元素中选出关键字最小的,并和第i个进行交换。1<=i<=n
和冒泡的区别是一个类似于股票的短线操作,一个类似于长线操作。
for i in range(len(lists)):
m=i
for j in range(i+1,len(lists)):
if lists[m]>lists[j]:
m = j
if m != i:
lists[i],lists[m] = lists[m],lists[i]
2.复杂度:
无论最好最坏,都需要比较n*(n-1)/2次。
最坏情况的交换次数:0次。
最好情况的交换次数:n-1次。时间复杂度依然是O(n2)
书上认为简单选择排序略优于冒泡排序,但没考虑m的赋值,最坏情况下,仍然有n*(n-1)/2的赋值操作。
9.5直接插入排序
直接插入排序(Straight Insertion Sort)将一个数据插入到已经排好序的有序排列中。
#直接插入法,用二分法插入不就是,logn+log(n-1)+。。+log(1)= log(n!)< nlog(n)
def direct_insertion_sort(d): # 直接插入排序,因为要用到后面的希尔排序,所以转成function
d1 = [d[0]]
for i in d[1:]:
pos = 0
for j in range(len(d1) - 1, -1, -1):
if i >= d1[j]:
pos = j+1
break
d1.insert(pos, i)# 将元素插入数组
return d1
时间复杂度最好O(n),最坏O(n2)
9.6希尔排序(Shell Sort)
突破O(n2)的第一批算法。
希尔排序:将序列分为几个子序列,分别进行直接插入排序。
第i个元素分别和第i+k进行比较,并根据大小交换.
k从lens的一半,逐渐减小,直到1。
有k= k//3+1,有k=k//2等等。
主要优势在于减少交换次数,将大的元素几步内交换到最后。
性质:1、时间复杂度:O(nlogn) 2、空间复杂度:O(1) 3、非稳定排序 4、原地排序
9.7堆排序(Heap Sort)
堆:本身是完全二叉树,节点的值大于等于子节点的值,称为大顶堆。反之为小顶堆。
堆排序(Heap Sort):将序列构成大顶堆,根节点是最大值。然后移走根节点重新构建堆,反复执行。
1.如何从无序构建成一个堆
从一半往前遍历,(因为只有一半有子节点),子节点和父节点,根据大小关系进行交换。子节点当作父节点继续向下。
时间复杂度O(n)
2.去掉堆顶如何维护堆
先将根节点和最后的节点交换,本身最大的已经排好序。
然后本身第二大第三大已经浮上去了,就从根节点向下,交换比现在新的根节点大的元素。
交换从根节点到叶节点,最坏O(logn),重复n次。复杂度O(nlogn)
特点:最好最坏平均都是O(logn)
3.建堆的复杂度O(n):
从低向上确实是O(n),最底层叶子节点跳过,倒数第二层需要向下遍历一次。倒数第三层向下遍历两次。。。。最后每层加起来:
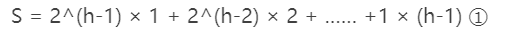
通过错位相减,算出来是n-logn+1,复杂度O(n)
https://blog.csdn.net/LeoSha/article/details/46116959?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
从上向下:这种是没有提前排列,是依次添加元素到树上,确实是O(nlogn)。

如果提前排列,从根节点遍历所有非叶子节点,还是O(n)。
区别是一个一个元素添加肯定有先上去又下来的元素。
4.维护堆的特点:最好最坏平均都是O(logn)
#感觉不太对,本身有序,最好应该是O(1)啊,然后n次O(n)。
9.8归并排序
归并排序(Merging Sort):将n个数分为[n//2]个长度为2或1 的有序子序列,两两归并。也称为2路归并排序。
时间复杂度:最好最坏O(logn)。但递归占用空间。
非递归的迭代方法,空间复杂度O(n)。
9.9快速排序
快速排序(Quick Sort):选择一个数(枢轴pivot),小的数放在左面,大的数在右面。
def quickSort(listx):
if len(listx)<=1:
return listx
pivot = listx[len(listx)//2] #取列表中中间的元素为被比较数pivot
listl = [x for x in listx if x < pivot] #<pivot的放在一个列表
listm = [x for x in listx if x ==pivot] #=pivot的放在一个列表
listr = [x for x in listx if x > pivot] #>pivot的放在一个列表
left = quickSort(listl) #递归进行该函数
right = quickSort(listr) #递归进行该函数
return left + listm + right #整合
print(quickSort([9,3, 6, 8, 9, 19, 1, 5])) #[1, 3, 5, 6, 8, 9, 9, 19]
#代码来自https://www.cnblogs.com/jxba/p/11946735.html
时间复杂度:数选的好,那就是O(nlogn)。最坏情况其中一边没有元素O(n2)。
通过不等式估计出的复杂度:


平均情况也是O(nlogn)。
2.优化:三数取中(median-of-three)
快排的问题就是数可能取得不好,所以找三个数,取中间那个,这样取到最小最大的概率都会降低。
甚至还有九数取中,先分三组,每组三个数取中,结果三个数再取中。
3.优化不必要的交换
4.优化:小数组的排序
当7个或50个数字以内,采用直接插入排序
5.采用迭代而不是递归
9.10总结

1.最好情况,冒泡,直接插入更好。当数组基本有序,不应该考虑复杂算法。
2.最坏情况,堆排序和归并排序。
3.归并排序需要空间。快速排序需要一定空间。
4.要求稳定性应该用归并排序。
5.数字本身很长,存储空间占用大,应该用简单选择排序,应为移动次数少。
















 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









