







荣登榜首
2024年6月27日,阿里 Qwen2 成全球开源大模型排行榜第一,从此,在开源大模型领域,中国处于领导地位。
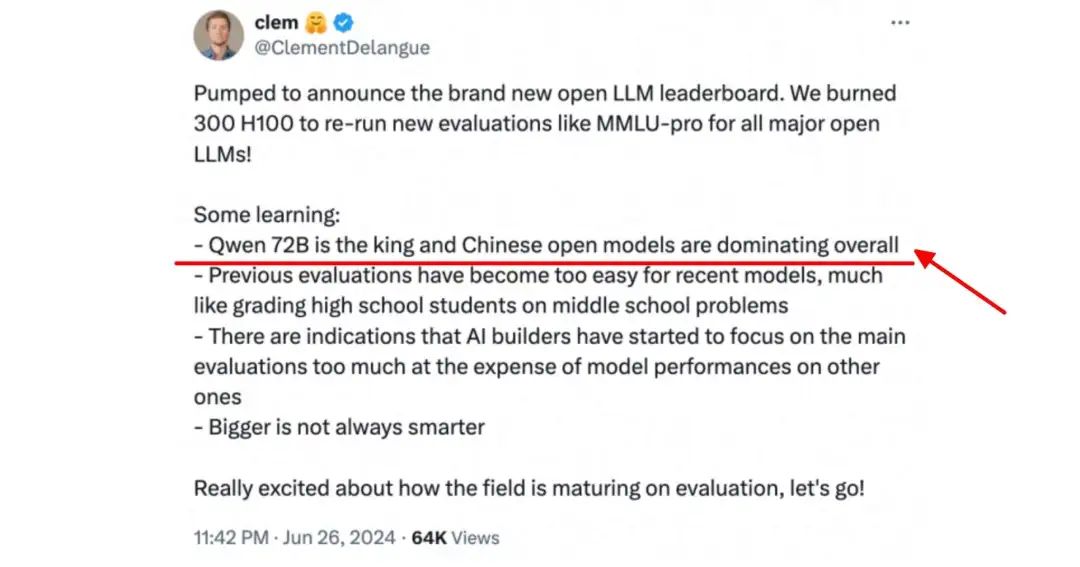
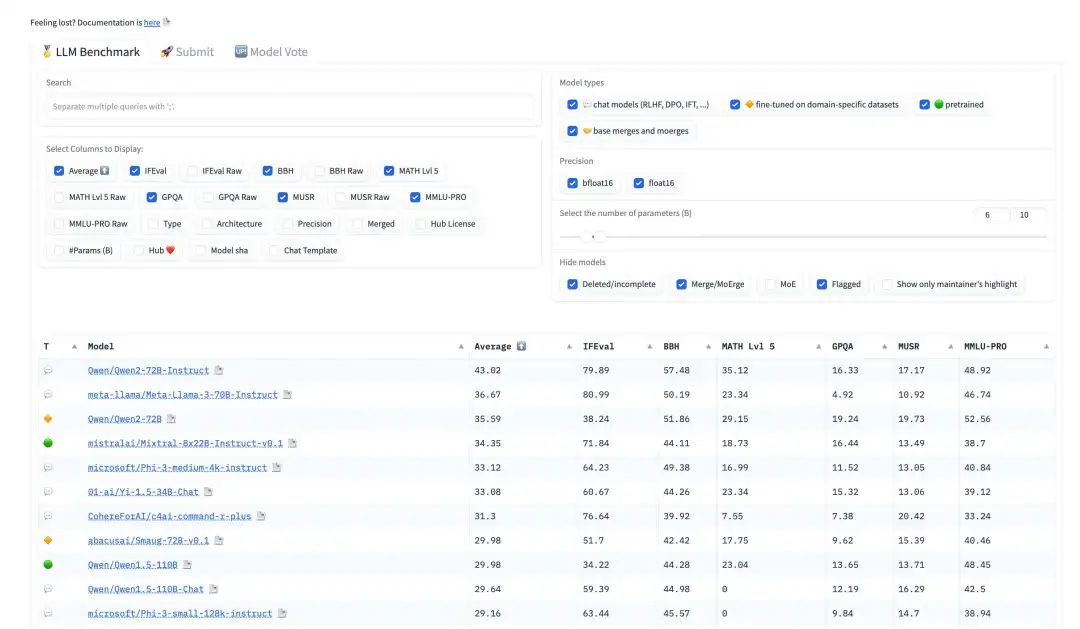
全球著名开源平台 huggingface 的联合创始人兼首席执行官 Clem 在社交平台宣布,阿里最新开源的 Qwen2-72B 指令微调版本,成为开源模型排行榜第一名。
他表示,为了测试一个更公正和准确的开源大模型排名,团队使用了 300 块 H100 对目前全球 100 多个主流开源大模型,例如,Qwen2、Llama-3、mixtral、Phi-3等,在BBH、MUSR、MMLU-PRO、GPQA 等基准测试集上进行了全新评估。
结果显示,阿里云开源的通义 Qwen-2 72B 力压科技、社交巨头 Meta 的 Llama-3、法国著名大模型平台 Mistralai 的 Mixtral 成为新的王者,中国在全球开源大模型领域处于领导地位。
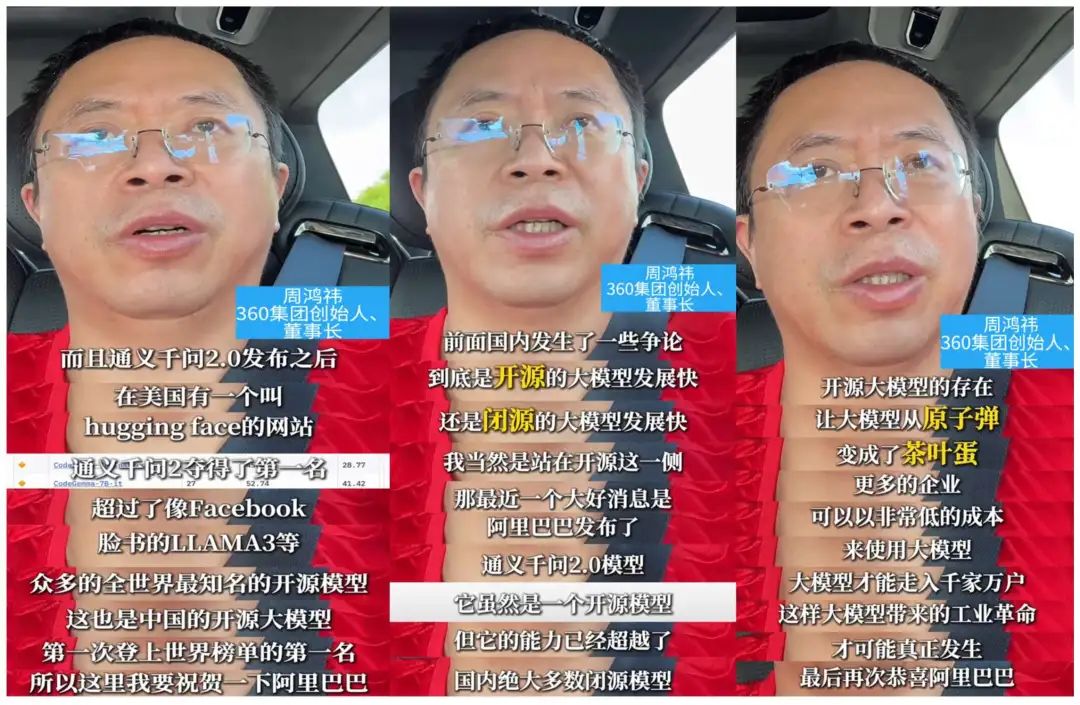
此前,360集团创始人、董事长周鸿祎发布视频,点赞开源的存在,同时,也祝贺阿里巴巴通义Qwen2大模型登上世界榜单第 1 名!让大模型从原子弹变成了茶叶蛋,让企业低成本使用,让大模型时代的工业革命能够发生。
值得注意的是,过去一年中,国产大模型只有 Qwen 多次冲进 LMSys 榜单,LMSys 官方也曾官方发推认证通义千问开源模型的实力。也就是说,在顶尖模型公司的竞争中,目前为止中国模型只有通义千问真正入局,能与头部厂商一较高下。

Qwen2 是什么?
Qwen2 是由阿里云通义千问团队开源的新一代大语言模型,此次迎来了从Qwen1.5到Qwen2的重大升级,主要包括:
5个尺寸的预训练和指令微调模型, 包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B;
在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据;
多个评测基准上的领先表现;
代码和数学能力显著提升;
增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)。
模型基础信息
Qwen2 系列包含 5 个尺寸的预训练和指令微调模型,其中包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 和 Qwen2-72B。如下表所示:
| 模型 | Qwen2-0.5B | Qwen2-1.5B | Qwen2-7B | Qwen2-57B-A14B | Qwen2-72B |
|---|---|---|---|---|---|
| 参数量 | 0.49B | 1.54B | 7.07B | 57.41B | 72.71B |
| 非 Embedding 参数量 | 0.35B | 1.31B | 5.98B | 56.32B | 70.21B |
| GQA | True | True | True | True | True |
| Tie Embedding | True | True | False | False | False |
| 上下文长度 | 32K | 32K | 128K | 64K | 128K |
斩获多项世界冠军
Qwen2 到底有多强呢?让我们来回顾一下,Qwen2 发布以来取得的成绩。
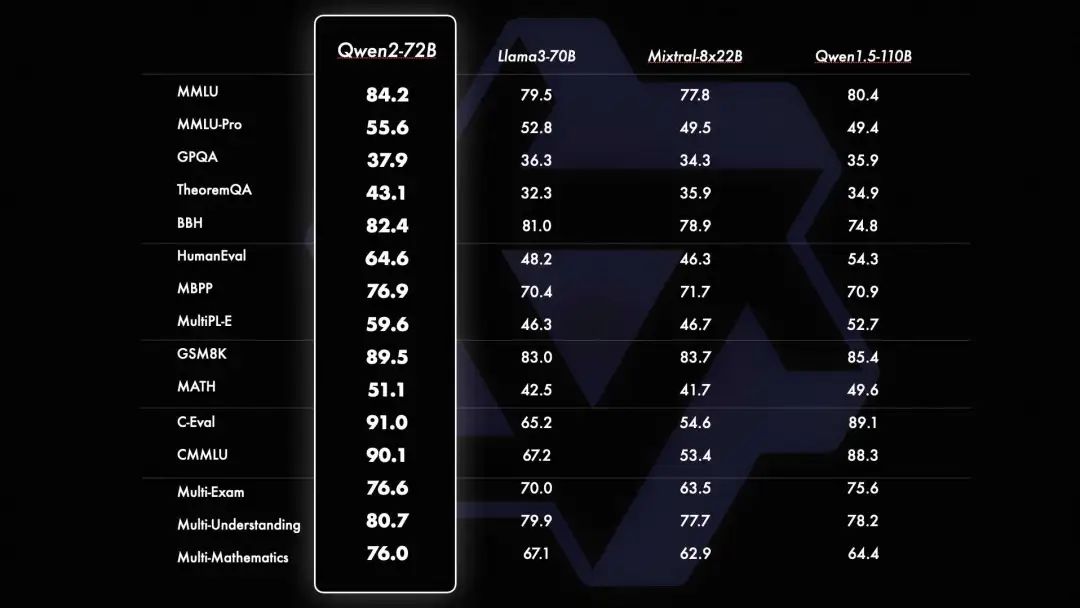
2024 年 6 月 7 日, Qwen2 发布后在十几项国际权威测评中,一举斩获多项世界冠军
Qwen2-72B 在 MMLU、GPQA、HumanEval、GSM8K、BBH、MT-Bench、Arena Hard、LiveCodeBench 等国际权威测评中,均评分世界第一。
美国最新开源榜单:全球第一
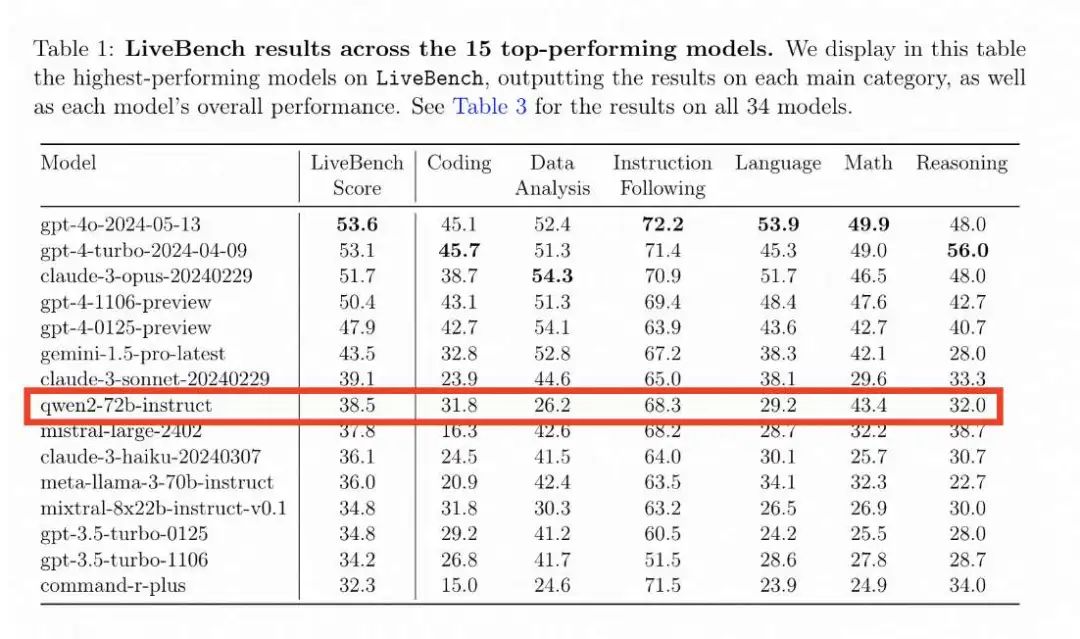
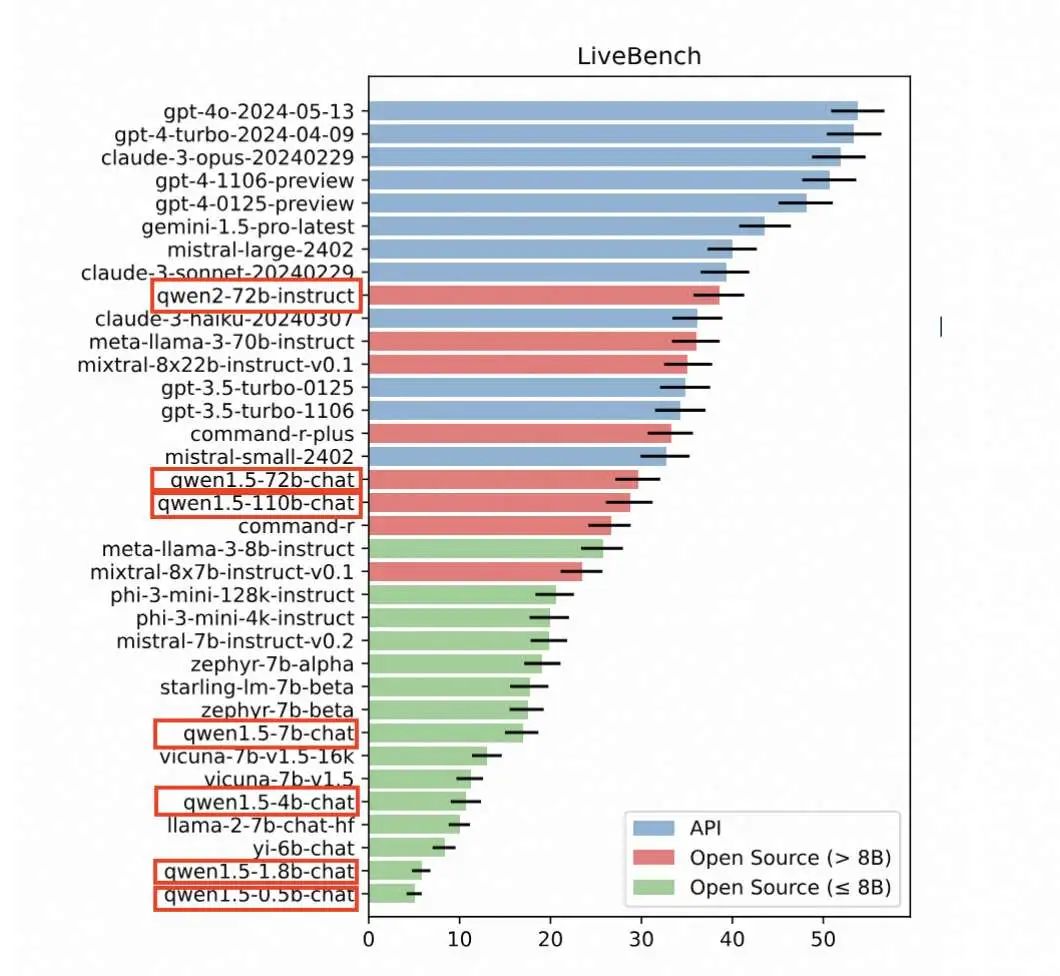
2024 年 6 月 14 日,Qwen2 拿下美国最新测评榜单开源大模型全球第一
Qwen2-72B 在图灵奖得主、Meta 首席 AI 科学家杨立昆(Yann LeCun)联合 Abacus.AI、纽约大学等机构推出全新的大模型测评基准 LiveBench AI 中,在开源大模型中排名世界第一,也是十榜单中唯一的开源大模型、唯一的中国大模型。
 !
!
AI 高考全卷评测:排名第一,超越GPT-4o
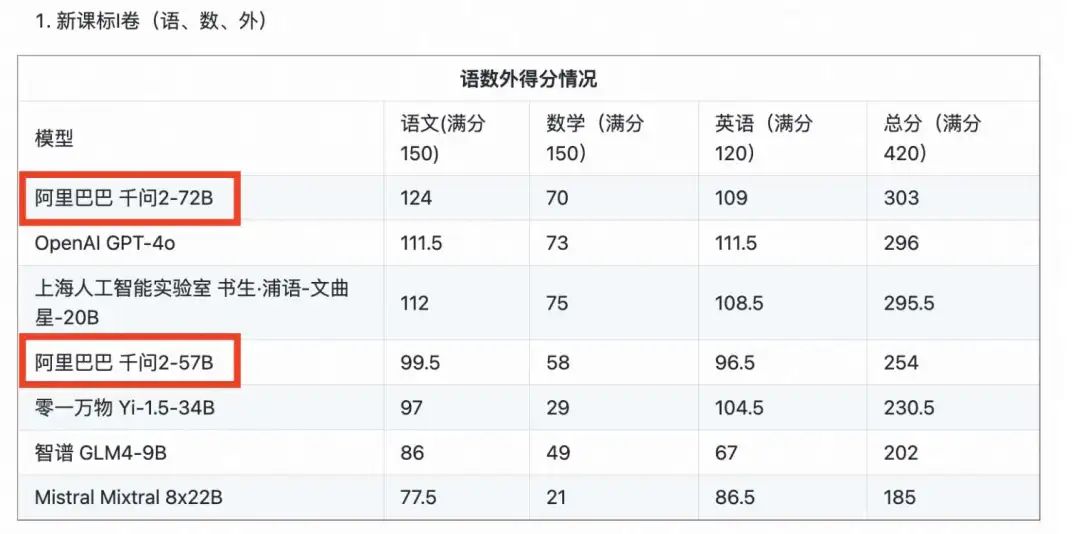
2024 年 6 月 19 日,首个AI高考全卷评测结果发布,阿里通义 Qwen2 模型排名第一,超越 GPT-4o
上海人工智能实验室发布首个AI高考全卷评测结果,月初开源的阿里通义千问大模型 Qwen2-72B 排名第一,在语数外三科 420 分的满分中获得 303 分,高于OpenAI 的 GPT-4o 和上海人工智能实验室的书生·浦语2.0文曲星(InternLM2-20B-WQX)。
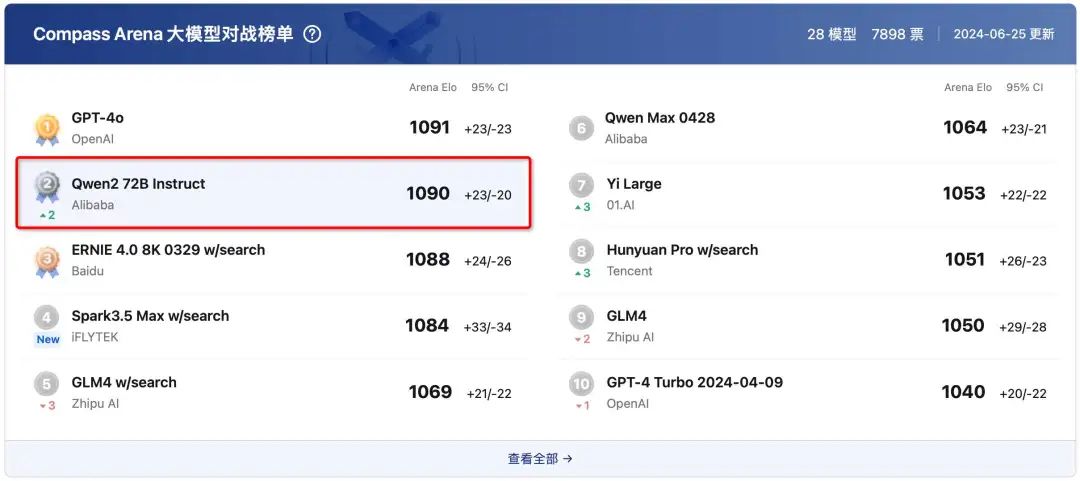
超越国产闭源大模型
上海人工智能实验室大模型测评榜单 Compass Arena 公布最新结果,阿里通义千问 Qwen2-72B 得分仅次于 GPT-4o,以 1 分之差排名第二,成为排名最高的开源大模型,总成绩超过文心 4.0、讯飞星火 3.5 等中国闭源大模型。Compass Arena 是由上海人工智能实验室推出的权威榜单,聚焦于中国主流大模型的能力测评。
最后,希望阿里通义千问持续迭代,再创辉煌,推出更多高性能开源模型,造福全世界开发者!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









