





ocr tesseract
The code is available on GitHub
该代码可在 GitHub上获得
Let’s say you want to extract some information from paper prescriptions (to perform some trend analysis afterwards, or to simply check if the prescription is valid against a database; the exact reasons may vary and are not too important here). You could type them into a computer database manually and call it a day. But it gets tedious if the number of those to type in becomes large, and the time is precious. This is when Optical Character Recognition (OCR) techniques may come in handy.
假设您要从纸质处方中提取一些信息(以便在以后进行一些趋势分析,或者只是根据数据库检查该处方是否有效;确切的原因可能有所不同,在这里并不太重要)。 您可以将它们手动输入到计算机数据库中,并称之为一天。 但是,如果要键入的内容数量增加,这将变得很乏味,并且时间很宝贵。 这就是光学字符识别(OCR)技术可能派上用场的时候。
OCR is an umbrella term encompassing a range of different technologies that detect, extract and recognise text from images. There exist a multitude of approaches for OCR from very simple ones, that can only recognise clear text in a specific font, to particularly advanced, that employ machine learning and can work with both printed and handwritten texts in multiple languages. We are going to focus our attention on two specific ones here.
OCR是一个笼统的术语,涵盖了从图像中检测,提取和识别文本的一系列不同技术。 OCR存在许多方法,从非常简单的方法到只能识别特定字体的清晰文本,再到特别高级的方法,它们采用了机器学习,并且可以同时处理多种语言的印刷文本和手写文本。 在这里,我们将注意力集中在两个特定的方面。
我们有什么选择? (What are our options?)
In this article we are going with two specific OCR tools: Tesseract OCR and Google Cloud’s Vision API
在本文中,我们将使用两种特定的OCR工具: Tesseract OCR和Google Cloud的Vision API
Tesseract OCR is an offline tool, which provides some options it can be run with. The one that makes the most difference in the example problems we have here is page segmentation mode. In many cases, one might resort to run it in auto-mode, but it’s always useful to think about what the potential layouts of the documents might be and hence provide some hints to Tesseract, so it can yield more accurate results. For simplicity, I will not cover all of the modes available, but experiment with three, that, at least intuitively, might fit the layouts of the documents we are working with here:
Tesseract OCR是一个离线工具,提供了一些可以运行的选项。 在这里的示例问题中,最大的区别是页面分割模式。 在许多情况下,可能会选择以自动模式运行它,但是思考文档的潜在布局可能总是很有用的,因此可以为Tesseract提供一些提示,以便可以产生更准确的结果。 为简单起见,我不会介绍所有可用的模式,而是尝试三种模式,至少在直观上,这些模式可能适合我们在此使用的文档的布局:
- Single Block: the system assumes that there is a single block of text on the image 单个块:系统假定图像上有单个文本块
- Sparse Text: the system tries to extract as much text as possible, disregarding its location and order 稀疏文本:系统尝试提取尽可能多的文本,而不考虑其位置和顺序
- Single Column: the system assumes that there’s a single column of lines of texts 单列:系统假设文本行只有一列
Google Vision, on the other hand, does not provide as much control over its configuration as Tesseract. However, its defaults are very effective in general. There are two distinct OCR models that are worth experimenting with:
另一方面,Google Vision对其配置的控制能力不及Tesseract。 但是,其默认设置通常非常有效。 有两种不同的OCR模型值得尝试:
- Text Detection model: detects and recognises all text on a provided image 文本检测模型:检测并识别提供的图像上的所有文本
- Document Text Detection model: practically performs the same task, but is tuned to better suit dense texts and documents 文档文本检测模型:实际上执行相同的任务,但已调整为更好地适合密集的文本和文档
进入第一个例子 (Into the first example)
N.B. the full recognised text results are not provided here, for the sake of keeping the article readable. However, the reader is encouraged to play around with the notebook provided and see full results for themselves.
注意:为了使文章易于阅读,此处未提供完整的识别文本结果。 但是,建议读者阅读提供 的笔记本电脑 ,自己看看完整的结果。
Starting with our first example: a scanned prescription for amoxicillin (kind of antibiotic). We will first look at how the methods described above handle this form as is.
从我们的第一个例子开始:阿莫西林(一种抗生素)的扫描处方。 我们将首先看一下上述方法如何按原样处理这种形式。
A couple of observations to make here:
这里有几个观察结果:
- Both Single Block and Single Column Tesseract modes detect some spurious boxes as text (we may assume that the text is not dense enough for these modes) 单块和单列Tesseract模式都将一些虚假框检测为文本(我们可能认为这些模式的文本密度不足)
- Both Google models detect the text on the watermarks, that is not relevant to our task 两种Google模型都检测到水印上的文本,这与我们的任务无关
I will not be talking about the accuracy of the recognition yet, since there’s a way to improve the detection first!
我不会谈论识别的准确性,因为有一种方法可以首先改善检测效果!
图像预处理有帮助吗? (Does image pre-processing help?)
There’s, of course, a plethora of ways that images can be pre-processed before analysis, including but not limited to different ways of filtering and de-noising, lightning adjustments, sharpening, you name it. But here we don’t have to do anything too convoluted to remove the background. We can perform thresholding, an operation that turns an image into a binary one by setting the pixels to black if their intensity values are above a certain threshold, and to white otherwise. Conveniently, the OpenCV library provides a method to threshold the image. Instead of picking and hard-coding some specific threshold Otsu method can be used, which chooses the best threshold, based on the distribution of pixel intensities. The results after thresholding already look more promising. Let’s investigate what we see here.
当然,在分析之前,有很多方法可以对图像进行预处理,包括但不限于过滤和降噪,闪电调整,锐化等各种方法,您可以自己命名。 但是在这里,我们不必做任何复杂的事情即可删除背景。 我们可以执行阈值处理,通过将像素的强度值高于某个阈值设置为黑色,将像素设置为黑色,否则将图像设置为白色,从而将图像转换为二进制图像。 方便地,OpenCV库提供了一种对图像进行阈值处理的方法。 代替选择和硬编码某些特定阈值,可以使用Otsu方法 ,该方法根据像素强度的分布选择最佳阈值。 阈值化后的结果看起来更有希望。 让我们调查一下我们在这里看到的内容。
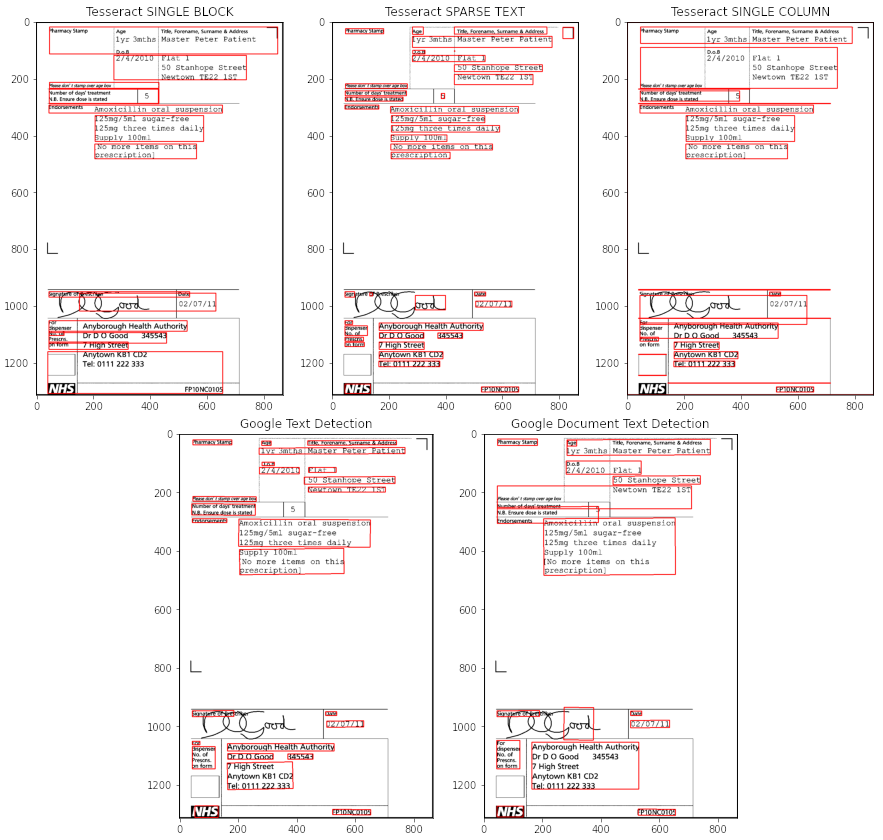
- Tesseract’s results haven’t changed much (since it was not affected by the background anyway). Tesseract的结果没有太大变化(因为它始终不受背景影响)。
- However, Google’s results have definitely improved: no more unwanted elements are recognised. 但是,Google的结果肯定得到了改善:不再识别出任何多余的元素。
- Tesseract’s Sparse Text mode still stands superior to the other two, detecting the layout correctly, and recognising most of the text without mistakes. There are some occasional extra characters inserted: for example “i 50 Stanhope Street”, where ‘i’ is not a real character, but part of the box to the left of the text. Tesseract的“稀疏文本”模式仍然优于其他两个模式,可以正确检测布局并正确识别大多数文本。 偶尔会插入一些额外的字符:例如“ i Stanhope Street 50”,其中“ i”不是真实字符,而是文本左侧方框的一部分。
- Google Document Text Detection model does not seem to perform well on this one, combining texts into a single paragraph when they clearly do not belong together. The possible reason here is that the text is not dense enough for that particular model. Google文档文本检测模型在此模型上似乎效果不佳,当文本明显不属于同一文本时,将它们合并为一个段落。 此处可能的原因是该文本对于该特定模型而言不够密集。
- We can also see one of the weak sides of Google Vision: it sometimes fails to recognise short strings or lone characters standing on their own (Google Text Detection model failed to detect that single ‘5’ in the middle of the page). But overall, when the text was detected, it was indeed recognised correctly. 我们还可以看到Google Vision的弱点之一:它有时无法识别短字符串或单独的字符(Google文字检测模型无法在页面中间检测到单个“ 5”)。 但是总的来说,当检测到文本时,确实可以正确识别它。
So, as you can see, there’s no one-size-fits-all model. In this particular case, after the experiment, I would go with either Tesseract Sparse Text mode or Google Text Detection model (leaning more towards the former, as the 5 and other single-digit numbers that may come in the following documents, that Google misses, might be quite important for the task), with the thresholding as the preprocessing step.
因此,如您所见,没有一种适合所有人的模型。 在这种特殊情况下,经过实验后,我将使用Tesseract稀疏文本模式或Google文本检测模型(更倾向于前者,因为以下文档可能会包含5个和其他个位数的数字,但Google会忽略掉,对于该任务可能非常重要),并以阈值作为预处理步骤。
那不同的布局呢 (What about a different layout)
To illustrate that the nature of a document might influence the choice of a model, let’s go through another example. Here we have a receipt from a hotel, that was submitted to claim reimbursement.
为了说明文档的性质可能会影响模型的选择,让我们来看另一个示例。 在这里,我们有一家酒店的收据,已据要求索偿。

- All three modes of Tesseract did a good job detecting the text on the image. However, Single Block and Column modes kept the lines of the text intact, which is convenient if you wants to match label-value pairs in the analysis afterwards. Tesseract的所有三种模式都很好地检测了图像上的文字。 但是,“单块和列”模式可以使文本的行保持完整,如果以后要在分析中匹配“标签-值”对,这将非常方便。
- Tesseract’s recognition, on the other hand, is far from perfect (e.g. “MTE: Jin, 26,16 TIE: 03:4” instead of “DATE: Jun, 26, 16 TIME: 09:47”). My guess would be that it is due to a narrow font and the image quality not being the sharpest. Some pre-processing steps to improve edges of the letters might yield better results, but this is just a speculation, since this was not tested. 另一方面,Tesseract的认可远非完美(例如,“ MTE:Jin,26,16 TIE:03:4”,而不是“ DATE:Jun,26,16 TIME:09:47”)。 我的猜测是这是由于字体较窄且图像质量不是最清晰。 一些改善字母边缘的预处理步骤可能会产生更好的结果,但这只是一种推测,因为未经测试。
- In comparison, Google Vision recognises all the text with almost no errors, including the handwritten “Housing” (which Tesseract recognised as “‘stflrg”) 相比之下,Google Vision几乎可以识别所有文本,包括手写的“外壳”(Tesseract将该文本识别为“'st fl rg”)
- The segmentation by the Text Detection model was again better in comparison to the Document Text Detection model, even though it breaks up some of the lines of text 与文档文本检测模型相比,“文本检测”模型的分割还是更好的,尽管它分割了一些文本行
At this point, I’d like to add a note on matching label-value pairs. Tesseract’s Single Column mode conveniently provides lines of the receipt, so the label-value pairs can be parsed trivially. However, if this was not the case (and it isn’t for the results of Google Vision), the pairs can still be matched if needed by using the coordinates of the detected text, which are provided by both Tesseract and Google.
在这一点上,我想对匹配的标签值对添加一条注释。 Tesseract的“单列”模式可方便地提供收据行,因此可以轻松解析标签-值对。 但是,如果不是这种情况(不是Google Vision的结果),则仍可以根据需要使用Tesseract和Google所提供的检测到的文本的坐标来匹配这些对。
In conclusion, even though Tesseract Single Column provides a nice layout, I would choose Google Vision for this task, as it provides much better accuracy of recognition (including the handwritten part, which is important for this particular example).
总之,即使Tesseract Single Column提供了一个不错的布局,我还是会选择Google Vision来完成此任务,因为它提供了更好的识别精度(包括手写部分,这对于该特定示例很重要)。
带回家的消息 (Take-home message)
In this short blog post, we’ve compared how Tesseract OCR and Google Vision perform on two specific tasks, but this is by no means an exhaustive overview. When employing OCR, you need to consider the nature of the images you are working with, and experiment with different OCR models to find one that is the most suitable for their application. Additionally, the real-world data might not be as clean as the examples above, therefore some pre-processing steps might be required for recognition to be successful. And finally, even though this step is out of the scope of this post, it is worth mentioning, that after the recognition some post-processing might be required, such as removal of the extra characters, or spell-checking (it depends on what the further analysis is).
在这篇简短的博客文章中,我们比较了Tesseract OCR和Google Vision在两个特定任务上的执行情况,但这绝不是详尽的概述。 使用OCR时,您需要考虑所使用图像的性质,并尝试使用不同的OCR模型以找到最适合其应用的图像。 此外,现实世界中的数据可能不如上面的示例那么干净,因此可能需要一些预处理步骤才能使识别成功。 最后,即使此步骤不在本文讨论范围之内,但值得一提的是,在识别之后,可能需要进行一些后期处理,例如删除多余的字符或进行拼写检查(取决于哪些内容)。进一步的分析是)。
The notebook with the code producing the results for the examples in this post is available. The readers are highly encouraged to give it a try and experiment with their sample data.
提供了带有生成本文中示例结果的代码的笔记本 。 强烈建议读者尝试并尝试使用其样本数据。
翻译自: https://medium.com/fuzzylabsai/the-battle-of-the-ocr-engines-tesseract-vs-google-902c302e71a1
ocr tesseract















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









