





q-learning
I recently watched AlphaGo — The Movie, a documentary about DeepMind’s AlphaGo. AlphaGo is an AI that plays the game Go, and the documentary details the story leading up to its match against Lee Sedol. When IBM’s Deep Blue defeated the chess grandmaster Gary Kasparov in 1997, Go players around the world posited that this would not be possible with Go. 20 years later, Google’s AI beat one of the best Go players the world has ever seen. Some of the strategies it employed are believed to be very creative and are being studied by Go experts. I found all of this to be fascinating.
我最近看了有关DeepMind的AlphaGo的纪录片AlphaGo- 电影 。 AlphaGo是一款玩Go游戏的AI,纪录片详细介绍了与Lee Sedol进行比赛时的故事。 当IBM的Deep Blue在1997年击败国际象棋大师加里·卡斯帕罗夫(Gary Kasparov)时,世界各地的围棋选手都认为围棋是不可能做到的。 20年后,Google的AI击败了世界上最好的Go播放器之一。 人们认为它采用的某些策略很有创造力,并且正在由Go专家进行研究。 我发现所有这些都很有趣。
While I would not be able to build an AI of that caliber, I wanted to explore reinforcement learning. I decided on the game Snake (a much simpler game!) and it didn’t take very long to get some pretty great results. My code is shared in full via Github.
虽然我无法建立这种能力的AI,但我想探索强化学习。 我决定玩游戏Snake(一个简单得多的游戏!),花了很长时间才获得一些不错的结果。 我的代码通过Github完全共享。
什么是Q学习? (What is Q-Learning?)
Quality Learning, or Q-learning, is similar to training a dog. My dog was a puppy when we first brought her home. She didn’t know any tricks. She didn’t know not to bite our shoes. And most importantly, she wasn’t potty trained. But she loved treats. This gave us a way to incentivize her. Every time she sat on command or shook her paw, we gave her a treat. If she bit our shoes… well, nothing really, she just didn't get a treat. Nevertheless, over time, she even learned to press down on our feet when she needed to be let outside to use the washroom.
优质学习或Q学习类似于训练狗。 我们第一次带她回家时,我的狗是小狗。 她什么都不懂。 她不知道不咬我们的鞋子。 最重要的是,她没有如厕训练。 但是她喜欢吃零食。 这给了我们激励她的方法。 每当她下达命令或摇动爪子时,我们都会给她请客。 如果她咬我们的鞋子……好吧,什么都没有,她只是没有得到治疗。 然而,随着时间的流逝,当她需要被放到外面使用洗手间时,她甚至学会了压下我们的脚。
Q-learning is a reinforcement learning method that teaches a learning agent how to perform a task by rewarding good behavior and punishing bad behavior. In Snake, for example, moving closer to the food is good. Going off the screen is bad. At each point in the game, the agent will choose the action with the highest expected reward.
Q学习是一种强化学习方法,它教学习者如何通过奖励良好行为和惩罚不良行为来执行任务。 例如,在Snake中,靠近食物是好的。 离开屏幕是不好的。 在游戏的每个点,代理都会选择预期奖励最高的动作。
那看起来像什么? (So what does that look like?)
At first, the snake doesn’t know how to eat the food and is less “purposeful”. It also tends to die a lot by going the opposite way that its currently going and immediately hitting its tail. But it doesn’t take very long for the agent to learn how to play the game. After less than 30 games, it plays quite well.
起初,蛇不知道如何吃食物,因此“目的性”较弱。 它也倾向于以与当前相反的方式死亡,并立即撞向尾巴。 但是,代理商很快就可以学会如何玩游戏了。 经过不到30场比赛,它的表现还是不错的。
Training:
训练:
After 100 games:
经过100场比赛:
Lets take a look at how we got there.
让我们看看我们如何到达那里。
游戏引擎 (Game Engine)
In this post, we will be focusing more on the learning agent than the game. That said, we still need a game engine. I found this tutorial by Edureka that provides a great introduction into Pygame using Snake as an example. I made some minor changes to the code that allows it to interact with the learning agent and it was ready to go. Thank you Edureka!
在本文中,我们将重点放在学习代理上而不是游戏上。 也就是说,我们仍然需要一个游戏引擎。 我发现Edureka的本教程以Snake为例,对Pygame进行了很好的介绍。 我对代码进行了一些小的更改,使其可以与学习代理进行交互,并且可以开始使用了。 谢谢Edureka!
游戏状态 (Game State)
We need a way of defining the current game state. We want to define this in a way that we can represent all possible states of the game, or at least the critical parts of the game. I will define my states as a combination of:
我们需要一种定义当前游戏状态的方法。 我们希望以一种可以代表游戏所有可能状态或至少游戏关键部分的方式来定义它。 我将状态定义为以下各项的组合:
- Horizontal orientation from the food — Is the snake currently to the left or right of the food? 食物的水平方向-蛇当前在食物的左侧还是右侧?
- Vertical orientation — Is the snake currently above or below the food? 垂直方向-蛇当前在食物上方还是下方?
- Are there walls or tails in the adjacent (left, right, above, below) squares? 相邻(左,右,上,下)方块中是否有墙或尾巴?
This lets us generalize the game a bit and the state space of the game is fairly small.
这使我们对游戏进行了概括,并且游戏的状态空间很小。
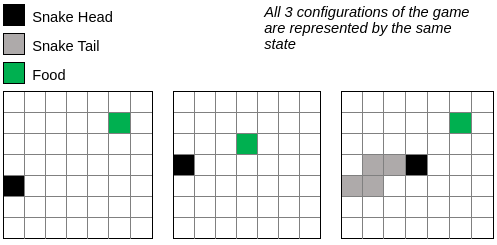
Since the snake has an immediate danger to the left, and the food is above and to the right of the snake, all 3 scenarios are represented by the same state.
由于蛇的左边有直接危险,并且食物在蛇的上方和右边,因此所有3种情况都以相同的状态表示。
贝尔曼方程 (The Bellman Equation)
We use the Bellman Equation to compute the total expected reward of an action, and store the information in a Q-Table.
我们使用Bellman方程来计算动作的预期总回报,并将信息存储在Q表中 。
At time t, we have the following state and action:
在时间t ,我们具有以下状态和动作:

The reward that we get for that action at that state can be expressed as:
我们在该状态下对该动作所获得的奖励可以表示为:
When we take an action, we transition to the next state, where we can select another action to gain another reward. In addition the immediate reward, we want to look ahead to see if there are large rewards in the future. This is especially important for games like chess where the agent must think several moves ahead. We can then say that the total expected reward at time t is:
当我们执行一个动作时,我们会转换到下一个状态,在这里我们可以选择另一个动作来获得另一个奖励。 除了立即获得的奖励外,我们还希望展望未来是否有大额奖励。 对于象棋这样的游戏来说,这尤其重要,在这种游戏中,代理商必须考虑一些前进的步伐。 然后我们可以说,在时间t的总预期报酬是:
And then we introduce the idea of impatience — A reward now is better than reward later. That is, we scale down the future rewards. The discount factor is a number between 0 and 1. The larger this factor, the more weight we give to future rewards.
然后,我们介绍了不耐烦的想法-现在的奖励比以后的奖励更好。 也就是说,我们缩减了未来的回报。 折扣系数是介于0和1之间的数字。此系数越大,我们对未来奖励的重视程度就越高。
And simplifying, we get:
并简化,我们得到:
Before the agent plays the first game, it has no idea what the expected reward of any action will be. So we start with a Q-Table with all zeros. As the agent plays, it observes the value of these rewards for each action a, so that it learn which a is best for each state s.
在坐席进行第一个游戏之前,不知道任何动作的预期收益是多少。 因此,我们从全零的Q表开始。 当代理人玩游戏时,它会观察每个动作a的奖励价值,从而了解哪个a对每个状态s最佳。
选择动作 (Selecting an Action)
At each given state, the agent looks at the Q-Table and takes the action that has the highest expected reward. The takeaway here is that there is no pre-defined logic on how the snake should act. It is entirely learned from the data.
在每个给定状态下,代理查看Q表并采取具有最高预期报酬的动作。 这里的要点是,关于蛇的行为没有预先定义的逻辑。 它是完全从数据中学到的。
But there is something else going on here — a technique called Epsilon-Greedy. Most of the time, it follows the Q-Table. But what if there is a path that has not yet been explored that leads to a higher reward? This is the trade-off between exploitation (the best option based on what we know so far) and exploration (searching for a potentially better option). During the training phase, we tell the agent to occasionally select an action at random. In this case, 10% of the time. We call this 10% epsilon.
但是,这里还有其他事情在发生-一种叫做Epsilon-Greedy的技术。 大多数情况下,它遵循Q表。 但是,如果有一条尚未探索的途径会带来更高的回报呢? 这是开发(基于我们目前所知的最佳选择)和勘探(寻找可能更好的选择)之间的权衡。 在训练阶段,我们告诉业务代表偶尔随机选择一个动作。 在这种情况下,占10%的时间。 我们称此为10%ε。
更新Q表 (Updating the Q-Table)
After each move, we will update our Q Table using the Bellman Equation. If snake has moved closer to the food, or has eaten the food, it will get a positive reward. If the snake hit its tail or a wall, or has moved further from the food, it will get a negative reward. Notice the reversed list of the history list which allows to compute the Bellman Equation easily.
每次移动后,我们将使用Bellman方程更新Q表。 如果蛇靠近食物,或者已经吃掉了食物,它将获得积极的回报。 如果蛇撞到它的尾巴或墙壁,或者从食物中移开,它将获得负面奖励。 请注意,历史记录列表的反向列表使您可以轻松计算Bellman方程。
研究结果 (Study the Results)
We also want to see if the scores are increasing over time, or if it has plateaued. So we output the score after each game and plot the rolling 30 scores. We disable epsilon after 100 games to see how it performs.
我们还想查看分数是否随着时间增加,或者是否已经稳定。 因此,我们在每场比赛后输出得分,并绘制滚动的30分。 我们会在100场游戏后禁用epsilon,以查看其性能。

We see the scores increasing until about 150 games where it flattens out. More on this in the next section.
我们看到分数不断增加,直到大约150场比赛才趋于平缓。 下一节将对此进行更多介绍。
注意事项 (Caveats)
In my implementation of Q-Learning, my agent will never play a perfect game. Other than avoiding immediate dangers, it is always moving closer to the food. But we know that this wont always work.
在实施Q-Learning时,我的经纪人永远不会玩完美的游戏。 除了避免眼前的危险之外,它总是离食物越来越近。 但是,我们知道这将永远不会奏效。

In this scenario, the snake should move down and go around its tail. Instead, It would move up and get stuck. I need to change the state space in a way that can capture this and learn from it.
在这种情况下,蛇应该向下移动并绕尾巴走。 相反,它将向上移动并卡住。 我需要以一种可以捕获并从中学习的方式来更改状态空间。
总结思想 (Closing Thoughts)
I was surprised at how simple the implementation of Q-Learning was, and how effective it was. But as we saw above, it clearly has its drawbacks. There are more sophisticated methods of reinforcement learning that work better with more complex games. Some day soon, I would love to be able to build an AI that plays chess.
我对Q-Learning的实施如此简单和有效感到惊讶。 但是正如我们在上面看到的,它显然有其缺点。 有更多复杂的强化学习方法可以更好地与更复杂的游戏一起使用。 不久的将来,我希望能够构建一个能够下棋的AI。
The complete code can be found here on my Github. If you have any thoughts on how I might improve my code or learning agent, please share!
完整的代码可以发现在这里我Github上。 如果您对我如何改善我的代码或学习代理有任何想法,请分享!
翻译自: https://towardsdatascience.com/teaching-a-computer-how-to-play-snake-with-q-learning-93d0a316ddc0
q-learning















 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









