





dask 于数据分析
介绍 (Introduction)
Fraudulent activities have become a rampant activity that has aroused a lot of curiosity in the financial sector. This has posed a lot of issues in helping the sector efficiently manage their customers. In this tutorial, we will be using the Dask machine learning framework to intuitively detect fraudulent transactions in the financial industry. The outcome of the model is for us to efficiently deploy in any type of bank to reduce fraudulent means by alerting the owners of the account and the bank team. The link to this code is provided on Github.
欺诈活动已成为一种猖activity的活动,引起了金融部门的极大好奇。 这在帮助该部门有效管理客户方面提出了很多问题。 在本教程中,我们将使用Dask机器学习框架直观地检测金融行业中的欺诈性交易。 该模型的结果是,我们可以通过警告帐户所有者和银行团队来有效地部署在任何类型的银行中,以减少欺诈手段。 Github上提供了此代码的链接。
First and foremost, since this is a machine learning problem, why do we want to use dask since we have notable frameworks like pandas, bumpy, and scikit-learn to get the job done? I would love to state that dask has proven to be a framework in scaling pandas, bumpy, and scikit-learn workflow efficiently with minimal code. With dask, you get to perform all sorts of numpy, pandas, and scikit-learn operations.
首先,由于这是一个机器学习问题,为什么我们要使用dask,因为我们拥有诸如pandas,bumpy和scikit-learn等著名框架来完成这项工作? 我想指出,事实证明dask是用最少的代码有效扩展熊猫,颠簸和scikit学习工作流的框架。 借助dask,您可以执行各种numpy,pandas和scikit-learn操作。
Dask has proven to be a framework in scaling pandas, numpy and scikit-learn workflow efficiently with minimal code
事实证明,Dask是有效地以最少的代码扩展熊猫,numpy和scikit学习工作流的框架
In this tutorial, we want to build a model from a set of information provided by Bank A from their customer database; in identifying fraudulent transactions from non-fraudulent transactions. This bank has data of customers whose accounts got involved in fraudulent acts and those whose accounts do not have fraudulent history. We will be leveraging this information in predicting fraudulent accounts based on certain features.
在本教程中,我们要根据银行A从其客户数据库提供的一组信息来构建模型。 从非欺诈性交易中识别欺诈性交易。 该银行具有其帐户涉及欺诈行为的客户以及其帐户没有欺诈历史的客户的数据。 我们将利用这些信息来基于某些功能预测欺诈性帐户。
Alright, to get started, I will be using a dataset available on kaggle here. We will be going through the following procedures for solving this problem:
好的,首先,我将使用kaggle 此处的可用数据集。 我们将通过以下过程解决此问题:
- Understanding our data 了解我们的数据
- Data analysis/preprocessing with dask pandas and numpy framework. 使用dask pandas和numpy框架进行数据分析/预处理。
- Data visualization with seaborn and matplotlib. 使用seaborn和matplotlib进行数据可视化。
- Feature engineering 特征工程
- Predictive Modelling using the Dask ML framework. 使用Dask ML框架进行预测建模。
With dask, you get to perform all sorts of numpy, pandas and scikit-learn operations.
借助dask,您可以执行各种numpy,pandas和scikit-learn操作。
数据分析 (Data Analysis)
In this section, we will get to understand our data and perform basic data preprocessing and cleaning using dask while we make decisions on which feature is relevant to modeling the problem. First and foremost, let’s import all libraries and load the dataset by doing this:
在本节中,我们将决定使用哪种功能与问题建模相关的决策,从而了解数据并使用dask进行基本数据预处理和清理。 首先,让我们导入所有库并通过执行以下操作加载数据集:
You can read in data into a dataframe in dask by using the read_csv method and then pass in the csv file. You can go ahead to see the top 5 entries in the data by using the .head attribute of the dataframe. The next for us is to know the features we are working with. In dask, to do this, you can run the dataframe and the column attribute. This is illustrated in the code below.
您可以使用read_csv方法将数据读入dask中的数据帧,然后传入csv文件。 您可以使用数据框的.head属性继续查看数据中的前5个条目。 对我们而言,下一步是了解我们正在使用的功能。 要快速执行此操作,可以运行数据框和列属性。 下面的代码对此进行了说明。
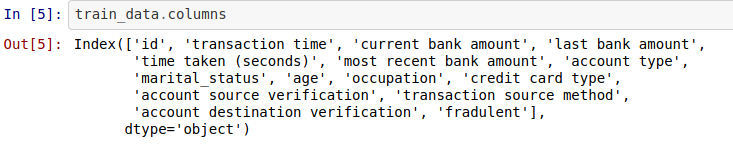
With this, we can say we have an idea of what our data is all about. So our data contains information on transaction time, the current bank amount, last bank amount, time is taken to process a transaction, account type, marital status, and other information provided from each user of the bank. More importantly, we have the feature we are trying to predict or understand with respect to other features which is fraudulent; that is our target feature. We still need to know more about our data so that we can know how to analyze, select the best feature, and transform for perfect modeling. The next thing you may want to do is to have a look at the descriptive analysis of the numerical entries in our data. Dask helps us to do this efficiently by running the code below, and we will have the corresponding output.
这样,我们可以说我们对数据的意义有了一个想法。 因此,我们的数据包含有关交易时间,当前银行金额,最后银行金额,处理交易所需的时间,帐户类型,婚姻状况以及银行各用户提供的其他信息的信息。 更重要的是,相对于其他欺诈性功能,我们拥有我们正在尝试预测或理解的功能; 这是我们的目标功能。 我们仍然需要更多地了解我们的数据,以便我们知道如何分析,选择最佳功能以及进行转换以实现完美的建模。 您可能要做的下一件事是查看对数据中数字条目的描述性分析。 Dask通过运行以下代码来帮助我们有效地做到这一点,我们将获得相应的输出。
The describe() method of a dask dataframe gives us a statistical insight into the numerical features of our data by telling us the number of valid entries in each feature (count), the mean, median, mode, minimum value, maximum value, standard deviation, lower percentile, upper percentile, and others for each corresponding entry. This actually has unveiled some things about our data, but let’s take note, this is only for the numerical info in our data. What about the non-numerical info’s, we still have to transform them into numerics so as to prepare them for the algorithm that will learn from them. First, let’s have a peek into our data by knowing, which of them is numerical and which is not. The code below helps us to do that in dask.
通过告诉我们每个特征中有效条目的数量(计数),均值,中位数,众数,最小值,最大值,标准,可以使数据框架的describe()方法使我们对数据的数值特征有统计上的了解偏差,较低的百分位数,较高的百分位数以及其他相应条目的值。 这实际上揭示了有关数据的一些信息,但请注意,这仅用于数据中的数字信息。 关于非数字信息,我们仍然必须将它们转换为数字,以便为从中学习的算法做准备。 首先,让我们窥探一下我们的数据,其中哪些是数字的,哪些不是数字的。 下面的代码帮助我们快速完成任务。
From the code above, we are able to see that we have 3 features that are boolean (account source verification, transaction source method, and account destination verification), 6 numerical data and 6 text data (strings). Now, that we have an idea of the information we are trying to model, let’s now dive into this step by step by having an insightful look into each feature using dask. Let’s begin with marital status. The code below gives us an idea of what the content marital status entails.
从上面的代码中,我们可以看到我们具有3个功能,它们是布尔值(帐户来源验证,交易来源方法和帐户目的地验证),6个数字数据和6个文本数据(字符串)。 现在,我们已经知道了要建模的信息,现在让我们通过使用dask深入了解每个功能,逐步进入这一步骤。 让我们从婚姻状况开始。 下面的代码使我们对婚姻状况所涉及的内容有了一个概念。
婚姻状况 (Marital Status)
The marital status feature tells us vividly that the customers on this database are mostly married, while some are single and others didn’t disclose their marital status. Could this be a unique feature in determining fraudulent acts? It may, and it may not. Below is a histogram illustrating the frequency of each unique entry present in marital status.
婚姻状况功能生动地告诉我们,该数据库上的客户大多已婚,有些则是单身,而另一些则没有透露他们的婚姻状况。 这是确定欺诈行为的独特功能吗? 可能会,也可能不会。 下面的直方图说明了婚姻状况中每个唯一条目的出现频率。
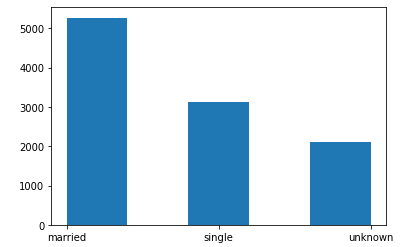
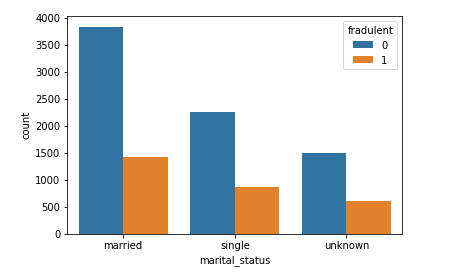
From the above illustration, a lot of married customers don’t have fraudulent histories in their account, this also corresponds to the same ratio for the single and the unknown. From the visual above, the ratio of the fraudulent accounts to the non-fraudulent account is almost the same for each (married, single, and unknown). We can say, there is a directly proportional relationship between marital status and our target, fraudulent. We will keep this because it’s a valid entry to our model.
从上图可以看出,许多已婚客户的帐户中没有欺诈历史记录,这也对应于未婚和未婚客户的相同比率。 从上面的视觉效果来看,欺诈性帐户与非欺诈性帐户的比率对于每个帐户(已婚,单一和未知)几乎都是相同的。 可以说,婚姻状况和我们的目标(欺诈)之间存在直接比例的关系。 我们将保留它,因为它是模型的有效条目。
Let’s move on to the next set of features which are:
让我们继续下一组功能:
- Id ID
- current bank amount 当前银行金额
- last bank amount, and 最后的银行金额,以及
- most recent bank amount. 最近的银行金额。
We are dropping them because we want to assume that they can’t be a unique determinant in determining fraudulent transactions. The code below (in dask), helps us to execute this.
我们之所以删除它们,是因为我们想假设它们在确定欺诈性交易中不是唯一的决定因素。 下面的代码(快速)可帮助我们执行此操作。
Now we are left with less information yet to be processed. We can do the same thing done between marital status and fraudulent for other features with respect to fraudulent and we can have the following visuals.
现在,我们剩下的信息尚待处理。 对于欺诈的其他功能,我们可以在婚姻状况和欺诈之间做同样的事情,并且可以得到以下视觉效果。
Let’s take some other features, analyze, and transform. To begin, let’s look into the transaction time. Since this has to do with time, we will need to use the time, date library in python to process this. The code below helps us to do this efficiently:
让我们采用其他一些功能,进行分析和转换。 首先,让我们看一下交易时间。 由于这与时间有关,因此我们将需要使用python中的时间,日期库进行处理。 以下代码可帮助我们有效地做到这一点:
What was done above was for us to apply basic string operation in splitting the time into the year, month, day, hour, minute, and seconds for every entry present in that feature (transaction time). Having done this, we transformed them into new features for our dataframe and then dropped the original transaction time column. The next is for us to separate the data into X and y, such that X contains all features we want to work with and y is the target feature. To do this we have:
上面所做的是让我们应用基本的字符串操作,将功能中存在的每个条目的时间分为年,月,日,小时,分钟和秒(事务时间)。 完成此操作后,我们将其转换为数据框的新功能,然后删除了原始交易时间列。 接下来是让我们将数据分为X和y,以便X包含我们要使用的所有功能,而y是目标功能。 为此,我们有:
特征工程 (Feature Engineering)
Now that we have some ideas regarding the data, let’s go-ahead to do some feature engineering. There are two main ways of generating more features in your data:
现在,我们对数据有了一些想法,让我们继续进行一些功能设计。 有两种主要方法可在数据中生成更多功能:
Label Encoder — Here, feature parameters or entries are encoded in the order of priorities.
标签编码器 —在这里,要素参数或条目按优先级顺序编码。
One-hot Encoder — Here, feature parameters or entries are encoded by giving all entry equal priorities. More so, this sort of encoder tends to increase the dimension of the data by the number of valid entries in a particular feature.
一键式编码器 -在这里,特征参数或条目通过赋予所有条目相同的优先级进行编码。 更重要的是,这种编码器倾向于通过特定功能中有效条目的数量来增加数据的大小。
Polynomials — A polymeric means of data expansion for input features present in the data.
多项式-数据中存在的输入要素的数据扩展聚合方式。
But for the sake of this tutorial, we will focus on label encoding and one-hot. Dask does have support for label encoding and one-hot encoding. To get started, here are some of the features we have looked into and we want to encode them from being an object into numerics. This is because our algorithm works with numbers, not strings, so they need to be encoded, if relevant to the data. We are encoding the following features using label encoding:
但是,出于本教程的考虑,我们将重点介绍标签编码和one-hot 。 Dask确实支持标签编码和一键编码。 首先,这是我们研究过的一些功能,我们希望将它们从成为对象转变为数字。 这是因为我们的算法只处理数字,而不处理字符串,因此,如果与数据相关,则需要对它们进行编码。 我们正在使用标签编码来编码以下功能:
- Account source verification. 帐户来源验证。
- Account Destination verification. 帐户目标验证。
- Transaction source method. 交易来源方法。
To encode them using dask here is how to do it, using the code below:
要使用dask对其进行编码,下面是使用以下代码的方法:
Some features are less important in determining fraudulent transactions, like time taken for a transaction to get processed, age, and Id. So to drop them from our data we do the following:
在确定欺诈性交易时,某些功能不太重要,例如,处理交易所需的时间,期限和ID。 因此,要从我们的数据中删除它们,请执行以下操作:
Now we are left with just 6 features in building a model that will efficiently determine if a transaction is fraudulent or not. To confirm this, you can use the .head attribute of the dataframe to view. Doing this below we have:
现在,我们只剩下6个功能来构建模型,该模型将有效地确定交易是否为欺诈行为。 要确认这一点,可以使用数据框的.head属性进行查看。 在下面执行此操作,我们有:
Since all our features are now numeric, we can go ahead to standardize and reduce the variance of each feature using any of the following technique:
由于我们所有的功能现在都是数字的,因此我们可以使用以下任何一种技术来标准化并减少每个功能的差异:
Standard Scaler — A means of rescaling your data based on standard deviation.
Standard Scaler ( 标准缩放器) —一种基于标准偏差重新缩放数据的方法。
Normalizer — A means of normalizing all input to a particular feature to 1
归一化器 —一种将特定特征的所有输入归一化的方法
Min-max scaler — A means of reducing the variance in various features by rescaling all corresponding entries for each column by the corresponding maximum number.
最小-最大缩放器 —一种通过将每个列的所有相应条目重新缩放相应的最大数量来减少各种功能差异的方法。
These techniques are scaling techniques used for data science and ML tasks before modeling. Dask does have support for this, to import them do the following:
这些技术是在建模之前用于数据科学和ML任务的缩放技术。 Dask对此有支持,要导入它们,请执行以下操作:
Having done the scaling and data standardization we can go ahead to model. Dask does have support in helping us model our data, the above code shows us how to import necessary libraries needed for efficient modeling of our data. This includes the train_test_split, to split our data into train and test data for modeling and testing the model performance. More so, you can import the logistic regression algorithm as shown above using dask (this will be the algorithm to model our data). Finally, we can go ahead to import the metrics using dask, that is, accuracy score and log_loss which are available metrics for classification in desk. First, let’s proceed to split our train data into two parts, one for modeling and the other for testing, to do this, we have the following:
完成缩放和数据标准化后,我们可以进行建模。 Dask确实在帮助我们对数据进行建模方面提供了支持,以上代码向我们展示了如何导入必要的库,以高效地对数据进行建模。 这包括train_test_split ,将我们的数据分为训练和测试数据,以对模型性能进行建模和测试。 此外,您可以使用dask导入如上所示的逻辑回归算法(这将是对数据进行建模的算法)。 最后,我们可以继续使用dask导入指标,即准确性得分和log_loss ,它们是可在桌面中进行分类的指标。 首先,让我们将火车数据分为两部分,一个用于建模 ,另一个用于测试 ,为此,我们需要以下内容:
Dask does have support in helping us model our data,
Dask在帮助我们建模数据方面确实有支持,
Since we have been able to split into the modeling data and the testing data, we can go ahead to feed the modeling data into our algorithm to learn using dask and finally to evaluate the model while training. The following code below shows us how to do that:
由于我们已经能够分为建模数据和测试数据,因此我们可以继续将建模数据输入到我们的算法中,以使用dask进行学习,最后在训练时评估模型。 下面的代码向我们展示了如何做到这一点:
While training, the model was approximately 72% accurate, this shows that this model learned. Let’s go-ahead to make predictions on the test data and evaluate its performance on the data it hasn’t seen before. The code below helps us to do this:
在训练过程中,该模型的准确性约为72%,这表明该模型是有经验的。 让我们继续对测试数据进行预测,并根据之前从未见过的数据评估其性能。 下面的代码可以帮助我们做到这一点:
- How to perform data preprocessing and cleaning with dask. 如何使用dask执行数据预处理和清理。
Dask gives us an end-to-end flexibility of analyzing and modelling our data.
Dask为我们提供了分析和建模数据的端到端灵活性。
How to perform data preprocessing and cleaning with dask.
如何使用dask执行数据预处理和清理。
- Data modeling and prediction with dask. 使用dask进行数据建模和预测。
I hope you have learned a lot, if you do love this tutorial, do share it with friends. Thanks.
希望您学到了很多东西,如果您喜欢本教程,请与朋友分享。 谢谢。
链接和参考 (Links and References)
https://github.com/elishatofunmi/Medium-Intelligence/tree/master/Introduction%20to%20dask (notebook to this work).
https://github.com/elishatofunmi/Medium-Intelligence/tree/master/Introduction%20to%20dask (这项工作的笔记本)。
https://colab.research.google.com/drive/1uvRpOp9L1Hge2GNniJ5fJ0H7VL0LQmbZ?usp=sharing (colaboratory notebook).
https://colab.research.google.com/drive/1uvRpOp9L1Hge2GNniJ5fJ0H7VL0LQmbZ?usp=sharing (实验室笔记本)。
https://docs.dask.org/en/latest/ (dask documentation).
https://docs.dask.org/en/latest/ (黄昏文档)。
https://github.com/dask/dask-tutorial (dask tutorial).
dask 于数据分析














 3443
3443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









