





pytorch ocr
After completing Jeremy Howard’s excellent deep learning course , I was wondering if I could crack real world CAPTCHAs by basic neural nets instead of using the conventional OCR technique. I decided to give it a try using Fast.ai’s PyTorch based library and was able to build a model that correctly solves over 93% of CAPTCHAs. Here is a very basic outline of the two approaches I used (working code for which can be found here):
在完成了杰里米·霍华德(Jeremy Howard)出色的深度学习课程后 ,我想知道是否可以通过基本的神经网络而不是使用传统的OCR技术来破解现实世界的验证码。 我决定尝试使用Fast.ai的基于PyTorch的库,并能够构建一个可以正确解决93%以上的验证码的模型。 这是我使用的两种方法的非常基本的概述(可以在此处找到其工作代码):
- Solving for one character at a time (and its analysis using Class Activation Maps) 一次求解一个字符(及其使用类激活图的分析)
- Solving whole captcha in one go using complete one-hot encoding 使用完整的一键编码一次性解决整个验证码
Let’s start with a general question pertinent to the “current AI surge” :
让我们从与“当前AI激增”有关的一般问题开始:
“深度学习”值得炒作吗? (Is “Deep Learning” worth the hype?)
It is, indeed. The reason being the powerful underlying theorem it works on — The Universal Approximation Theorem. In simple terms, UAT says that:
确实是。 原因是它所依据的强大的基本定理— 通用逼近定理 。 简单来说,UAT表示:
you can always come up with a deep neural network that will approximate any complex relation between input and output.
您总是可以想出一个深层的神经网络,它将近似于输入和输出之间的任何复杂关系。
数据集 (Dataset)
The images in the dataset look like this:
数据集中的图像如下所示:

The dataset has following properties:
数据集具有以下属性:
- Each captcha consists of either 6 or 7 characters 每个验证码由6个或7个字符组成
- A character might appear multiple times in a single captcha 一个字符可能在一个验证码中出现多次
The label for each image is given by its filename. ‘eigment.png’ for the example above. This allows for easy extraction of the labels while training.
每个图像的标签由其文件名给出。 上面的示例为“ eigment.png”。 这样可以在训练时轻松提取标签。
第一部分:一次一个字符 (Part-1: One character at a time)
In this approach, we train the model for each character-position separately i.e. create a separate model for each position. Then, we use these models one-by-one on an image to solve for each character of captcha.
在这种方法中,我们分别为每个角色位置训练模型,即为每个位置创建一个单独的模型。 然后,我们在图像上一对一地使用这些模型来解决验证码的每个字符。
解决验证码的第一个字符 (Solving for the first character of captcha)
This is a typical classification task. The input is the image of the captcha, the output is a single label corresponding to the first character.
这是典型的分类任务。 输入是验证码的图像,输出是与第一个字符相对应的单个标签。
data = ImageDataBunch.from_df('',df, folder='train', size=(77,247),label_col=1)
data.show_batch(rows=3, figsize=(7,6))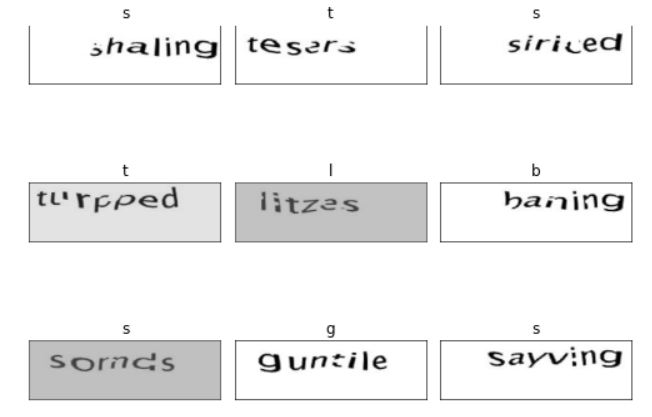
Now we train the model as a normal image classification problem. For this, we first define our learner object with a particular architecture (ResNet-50 here) and then start training by the usual “fit_one_cycle” function:
现在我们将模型训练为正常的图像分类问题。 为此,我们首先定义具有特定体系结构的学习者对象(此处为ResNet-50),然后通过常规的“ fit_one_cycle”函数开始训练:
learn = cnn_learner(data, models.resnet50, metrics=accuracy)
lr=1e-2
learn.fit_one_cycle(14,max_lr=lr,wd=0.01)
Initially, I trained only for 14 epochs because I wanted to see which pair of characters the model struggles the most with.
最初,我只训练了14个时期,因为我想看看模型最难与哪对角色在一起。
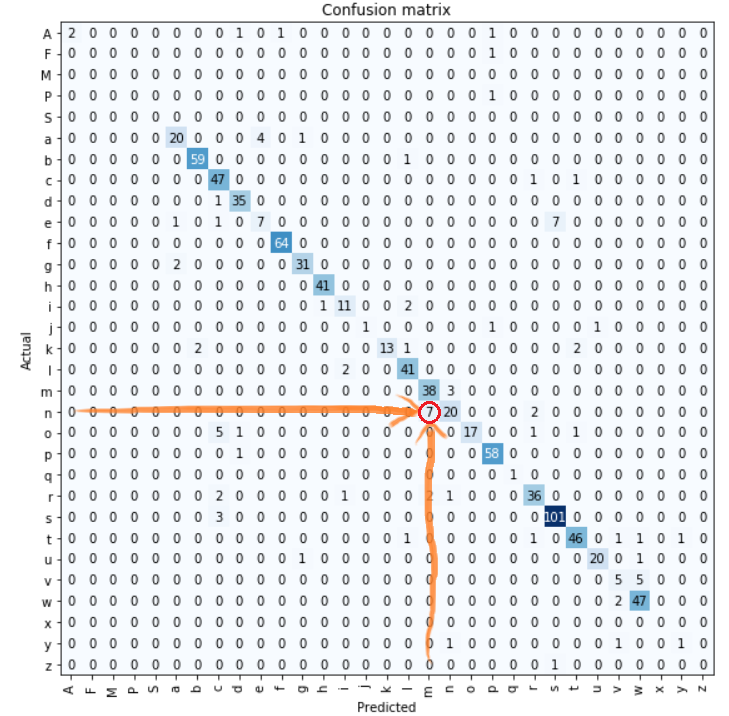
From this classification matrix, we can clearly see the “difficult” pair. Unsurprisingly it’s “m” & “n”. Intuitively also, I’d say that “m” and “n” are hard to distinguish.
从这个分类矩阵中,我们可以清楚地看到“困难”对。 毫不奇怪,它是“ m”和“ n”。 同样从直觉上来说,我很难说“ m”和“ n”。
We now train for complete 20 epochs and achieve an accuracy of 98% for the first character.
现在,我们训练了20个完整的时期,并且第一个字符的准确性达到了98%。

Similarly we train for each position of captcha (from 1 to 7). For the CAPTCHAs having only 6 characters, we assign a unique label “X” as the 7th character for those CAPTCHAs. This works pretty well and the model starts to learn the white-space at the end of image (of 6 characters) as label “X”.
同样,我们针对验证码的每个位置(从1到7)进行训练。 对于只有6个字符的验证码,我们为这些验证码指定唯一的标签“ X”作为第7个字符。 这样效果很好,模型开始学习图像末尾的空白(6个字符),标签为“ X”。
CAM(类激活图) (CAM (Class Activation Map))
CAMs tell us about the part of the input image that is important in the classification process. For the above example, we’d expect to have high activation around the first character.
CAM告诉我们输入图像中在分类过程中很重要的部分。 对于上面的示例,我们希望第一个字符周围具有较高的激活率。

Similarly for positions 2,3 and 4,
对于位置2,3和4,同样

训练所有7个分类器(每个位置一个) (Training all 7 classifiers (one for each position))
We loop our previous code to train all the positions:
我们循环我们之前的代码来训练所有位置:
learn_list=[]
for i in range(7):
data = ImageDataBunch.from_df('',df, folder='train', size=(77,247),label_col=i+1)
learn = cnn_learner(data, models.resnet50, metrics=accuracy)
lr=1e-2
learn.fit_one_cycle(30,max_lr=lr,wd=0.01)
learn_list.append(learn)Here are the final accuracies I got for each position:
这是我为每个职位获得的最终精度:
- First character : 98.34% 首字符:98.34%
- Second character : 97.16% 第二角色:97.16%
- Third character : 96.45% 第三角色:96.45%
- Fourth character : 94.09% 第四角色:94.09%
- Fifth character : 94.44% 第五角色:94.44%
- Sixth character : 96.57% 第六位:96.57%
- Seventh character : 98.46% 第七角色:98.46%
Running all 7 models on a test case,
在测试用例上运行所有7个模型,
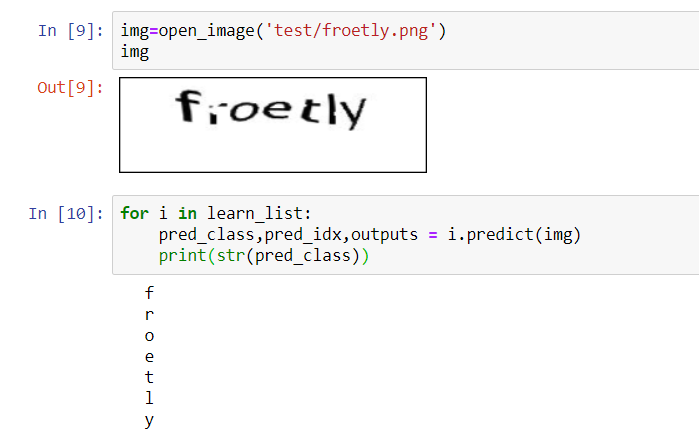
Hence, we have successfully solved our captcha.
因此,我们已成功解决了验证码问题。
Now let’s look at another approach where, instead of solving character-by-character, we solve the whole captcha simultaneously using one-hot encoding.
现在,让我们看另一种方法,而不是逐个字符地解决问题,而是使用单点编码同时解决整个验证码问题。
第2部分:一次完整的验证码 (Part-2: Whole captcha in one go)
One naive approach is to use the whole captcha text as a label for the image. This would make it a typical classification task. However, since all the images have unique captcha, this approach gives each image a different label, and each label will have only one corresponding image. “ankaser” would be just as different from “ankarse” as it would be from “jazched”. It does not use the fact that a captcha is made up of 7 parts. The model trained using this approach might “hard-learn” these training images, but clearly, it won’t be predictive when run on new data. Hence, let’s think of some other approach.
一种幼稚的方法是将整个验证码文本用作图像的标签。 这将使其成为典型的分类任务。 但是,由于所有图像都具有唯一的验证码,因此此方法为每个图像提供了不同的标签,并且每个标签将只有一个对应的图像。 “ankaser”将是刚刚从“ankarse”不同,因为它是从“jazched”。 它不使用验证码由7个部分组成的事实。 使用这种方法训练的模型可能会“硬学习”这些训练图像,但是很显然,当使用新数据运行时,它不会具有预测性。 因此,让我们考虑其他方法。
We know, 26 different characters (a-z) are present in our dataset. We can model a captcha as a vector of length 26 where each element of the vector corresponds to one of the possible characters (a-z). The number at each index of the vector indicates the position at which the corresponding character is present in the captcha. So 1 for position one, 2 for position two and so on. 0 if the character is not present in the captcha.
我们知道,我们的数据集中存在26个不同的字符(az)。 我们可以将验证码建模为长度为26的向量,其中向量的每个元素对应于可能的字符(az)之一。 向量每个索引处的数字表示在验证码中相应字符存在的位置。 所以1代表位置1,2代表位置2,依此类推。 如果验证码中不存在该字符,则为0 。
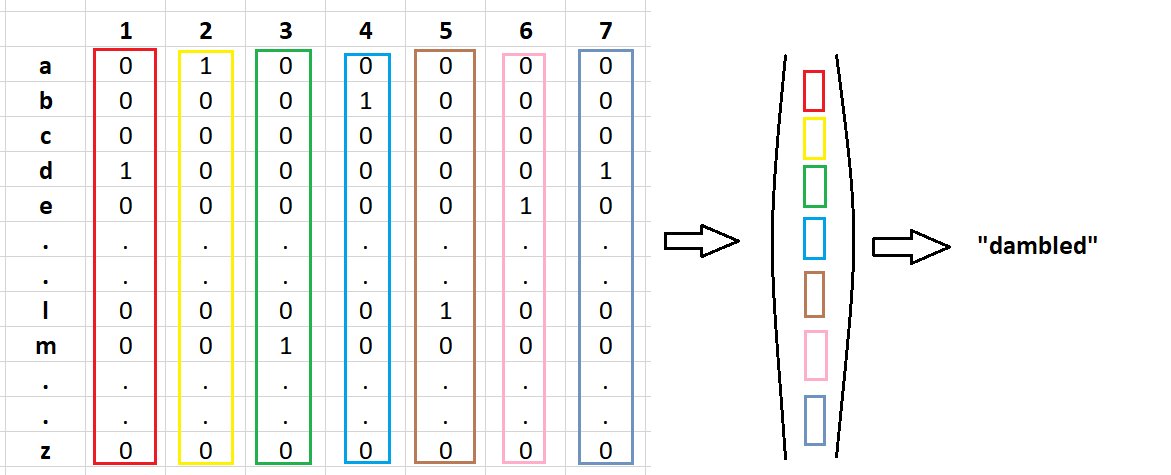
Using this encoding, for the captcha “damble”, we have :
使用这种编码,对于验证码“ damble”,我们有:
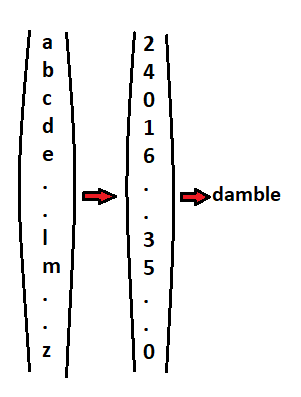
But still, there’s one problem. Any character can appear multiple times in the same captcha. This can not be represented in this approach. We can overcome this problem by employing complete one-hot encoding.
但是,仍然有一个问题。 任何字符都可以在同一验证码中多次出现。 这不能用这种方法表示。 我们可以通过使用完整的一键编码来克服此问题。
完整的一键编码 (Full one-hot encoding)
In the character-by-character classification approach, the character at position i was represented as a vector of length 26. Encoding the whole captcha would lead to a 26 by 7 matrix. The columns of the matrix correspond to the one-hot encoded character at the given position. Flattening this encoding matrix leads to a one-dimensional vector of length 26*7=182.
在逐字符分类方法中,位置i处的字符表示为长度为26的向量。对整个验证码进行编码将导致26 x 7矩阵。 矩阵的列对应于给定位置的一键编码字符。 展平该编码矩阵导致长度为26 * 7 = 182的一维矢量。
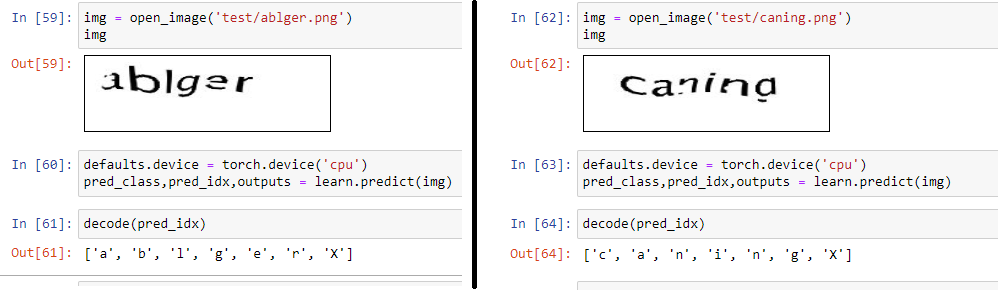
After some tweaks (applying weight decay and other regularization techniques), this model trains extremely well! After 70 iterations we get to 94% accuracy on the validation set.
经过一些调整(应用权重衰减和其他正则化技术)后,该模型训练得非常好! 经过70次迭代,验证集的准确度达到94%。

制作一个“ Captcha-solver”网络应用 (Making a “Captcha-solver” web-app)
Using flask (a micro web framework written in Python), I developed a small web-app so that this trained model can be used by anyone, regardless of their knowledge of Python or Deep Learning.
我使用flask(用Python编写的微型Web框架)开发了一个小型Web应用程序,因此,无论他们对Python或深度学习有什么了解,任何人都可以使用这种经过训练的模型。
At the homepage, user uploads an image of a captcha.
在主页上,用户上传验证码图像。
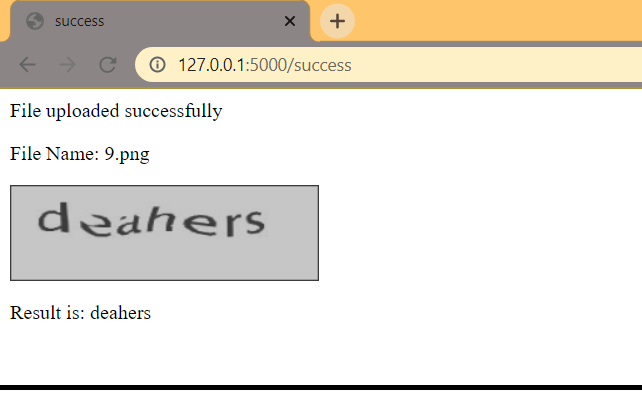
After uploading the image, the app loads the trained model in the back-end, inputs the uploaded image to the model, and then prints the result as shown below:
上载图像后,应用程序将训练后的模型加载到后端,将上载的图像输入模型,然后打印结果,如下所示:
You can find working code for the web-app here.
您可以在此处找到该网络应用程序的工作代码。
This concludes my blog-post about solving captchas with DeepLearning.
我的博客文章结束了有关使用DeepLearning解决验证码的文章。
At the end, I would like to again emphasize on the power of Deep Learning and the underlying Universal Approximation Theorem:
最后,我想再次强调深度学习的力量和潜在的通用近似定理 :
A feedforward network with a single layer is sufficient to represent any function, but the layer may be infeasibly large and may fail to learn and generalize correctly.
具有单层的前馈网络足以表示任何功能,但是该层可能过大,并且可能无法正确学习和概括。
— Ian Goodfellow, DLB
— Ian Goodfellow, DLB
This is an incredible statement. If you accept most classes of problems can be reduced to functions, this statement implies a neural network can, in theory, solve any problem.
这是一个令人难以置信的声明。 如果您接受大多数类型的问题都可以简化为函数,那么该声明暗示着神经网络理论上可以解决任何问题。
Maybe someday I’ll take the derivative of my up-votes and update my writing-style in the direction that maximizes views.
也许有一天,我会接受我的投票的衍生作品,并朝着最大化观看次数的方向更新我的写作风格。
[1]: Oliver Müller. (June 8, 2019). Solving Captchas with DeepLearning https://medium.com/@oneironaut.oml/solving-captchas-with-deeplearning-part-1-multi-label-classification-b9f745c3a599
[1]:奥利弗·穆勒(OliverMüller)。 (2019年6月8日)。 使用DeepLearning解决验证码 https://medium.com/@oneironaut.oml/solving-captchas-with-deeplearning-part-1-multi-label-classification-b9f745c3a599
[2]: Brendan Fortuner. (March 8, 2017). Can neural networks solve any problem? https://towardsdatascience.com/can-neural-networks-really-learn-any-function-65e106617fc6
[2]:Brendan Fortuner。 2017年3月8日)。 神经网络可以解决任何问题吗? https://towardsdatascience.com/can-neural-networks-really-learn-any-function-65e106617fc6
[3]: Michael Neilson. (Dec 26, 2019). A visual proof that neural nets can compute any function http://neuralnetworksanddeeplearning.com/chap4.html
[3]:迈克尔·尼尔森。 (2019年12月26日)。 神经网络可以计算任何函数的视觉证明 http://neuralnetworksanddeeplearning.com/chap4.html
翻译自: https://medium.com/swlh/solving-captchas-using-resnet-50-without-using-ocr-3bdfbd0004a4
pytorch ocr














 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









