





linux albert
BERT Algorithm is considered as a revolution in word semantic representation which has outperformed all the previously known word2vec models in various NLP tasks such as Text Classification, Entity Recognition, and Question-Answering.
BERT算法被认为是单词语义表示的一项革命,它在各种NLP任务(例如文本分类,实体识别和问题解答)中均胜过所有先前已知的word2vec模型。
The original BERT (BERT-base) model is made of 12 transformer encoder layers along with a Multi-head Attention.
原始的BERT (基于BERT)模型由12个变压器编码器层以及一个Multi-head Attention组成 。
The pretrained model has been trained on a large corpus of unlabeled text data with self-supervising by using the following tasks:
通过使用以下任务,可以在带有自我监督的大量未标记文本数据集上训练预训练模型:
1. Mask Language Model (NLM) loss — The task is “the filling banks,” where a model uses the context words surrounding a MASKED token to try to predict what the MASKED word should be.
1.蒙版语言模型(NLM)丢失 —任务是“填充库”,其中模型使用围绕MASKED令牌的上下文单词来尝试预测MASKED单词应该是什么。
2. Next Sentence Prediction (NSP) loss — For an input of sentences (A, B), it estimates how likely sentence B is the second sentence in the original text. This mechanism can be a beneficial evaluation metric in conversational systems’ performance.
2.下一个句子预测(NSP)丢失 —对于句子(A,B)的输入,它估计句子B在原始文本中成为第二句的可能性。 这种机制可以作为对话系统性能的有益评估指标。
RoBerta and XLNet are new versions of Bert that outperform original BERT on many benchmarks using more data and new NLM-loss, respectively.
RoBerta和XLNet是Bert的新版本,在使用更多数据和新的NLM损失的许多基准上,其性能均优于原始BERT。
BERT is an expensive model in terms of memory and time consumed on computations, even with GPU. The original BERT contains 110M parameters to be fine-tuned, which takes a considerable amount of time to train the model and excellent memory to save the model’s parameters. Therefore, we prefer lighter algorithms with excellent performance as BERT. So we shall talk about a recent article that introduces a new version of BERT named ALBERT. The authors of ALBERT claim that their model brings an 89% parameter reduction compared to BERT with almost the same performance on the benchmark. We will compare ALBERT with BERT to see whether it can be a good replacement for BERT.
就内存和计算消耗的时间而言,即使使用GPU,BERT还是一个昂贵的模型。 原始的BERT包含要微调的110M参数,这需要花费大量时间来训练模型,并需要大量内存来保存模型的参数。 因此,与BERT相比,我们更喜欢性能优异的轻型算法。 因此,我们将讨论最近的文章 ,该文章介绍了名为ALBERT的BERT的新版本。 ALBERT的作者声称,与BERT相比,他们的模型将参数减少了89%,性能几乎与基准测试相同。 我们将ALBERT与BERT进行比较,看看它是否可以很好地替代BERT。
The pretrained ALBERT model comes in two versions: “Albert-base-v1” (Not-recommended) and “Albert-base-v2” (Recommended) that can be downloaded from Hugging Face website containing all models in the Bertology domain. You can also load the model directly in your code by using the transformers module as follows:
预先训练的ALBERT模型有两个版本:“ Albert-base-v1”(不推荐)和“ Albert-base-v2”(推荐),可以从Hugging Face网站下载,其中包含Bertology域中的所有模型。 您还可以通过使用以下转换器模块直接在代码中加载模型:
from transformers import AlbertTokenizer, AlbertModeltokenizer = AlbertTokenizer.from_pretrained(“albert-base-v2”)
model = AlbertModel.from_pretrained(“albert-base-v2”)And by using this link, you can find the model and the codes for performing different tasks on benchmark data in the paper.
通过使用此链接,您可以在本文中找到用于对基准数据执行不同任务的模型和代码。
First, we look at the innovations in ALBERT, which are the reasons that named this algorithm as “A Lite BERT.” We then discuss the question: Is ALBERT solving memory and time consumption issues of BERT?
首先,我们看一下ALBERT的创新,这就是将该算法命名为“ A Lite BERT”的原因。 然后我们讨论问题:ALBERT是否在解决BERT的内存和时间消耗问题?
ALBERT的创新 (Innovations in ALBERT)
1. Cross-layer parameter sharing is the most significant change in BERT architecture that created ALBERT. ALBERT architecture still has 12 transformer encoder blocks stacked on top of each other like the original BERT. Still, it initializes a set of weights for the first encoder that is repeated for the other 11 encoders. This mechanism reduces the number of “unique” parameters, while the original BERT contains a set of unique parameters for every encoder (see Figure 1).
1.跨层参数共享是创建ALBERT的BERT体系结构中最重大的变化。 与原始BERT一样,ALBERT架构仍然具有12个彼此堆叠的变压器编码器块。 仍然,它为第一个编码器初始化一组权重,并为其他11个编码器重复这些权重。 这种机制减少了“唯一”参数的数量,而原始BERT为每个编码器包含了一组唯一参数(参见图1)。

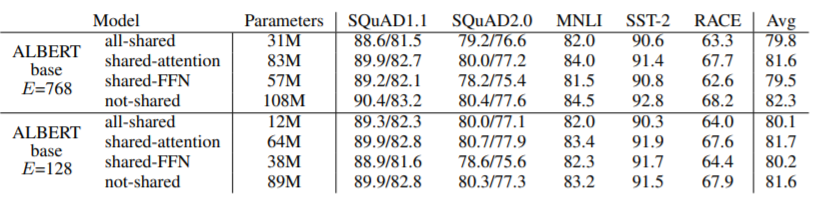
People who are familiar with fundamentals of Deep Learning know that every layer of a Neural Networks model is responsible for catching certain features or patterns of data and the deeper layers learn more complicated patterns and concepts, and to make this happen, each layer should contain its specific parameters different independent from other layers’. Therefore, one can conclude that this architecture can not outperform BERT architecture, and as you see in the following table, the shared parameters do not leverage the accuracy significantly, but interestingly, the results are almost the same as BERT.
熟悉深度学习基础知识的人知道,神经网络模型的每一层都负责捕获数据的某些特征或模式,而更深的层则学习更复杂的模式和概念,并且要做到这一点,每一层都应包含其独立于其他层的特定参数。 因此,可以得出这样的结论:该架构不能胜过BERT架构,并且如下表所示,共享参数并没有显着利用准确性,但是有趣的是,结果几乎与BERT相同。
2. Embedding Factorization The embedding size in BERT is equal to the size of the hidden layer (768 in original BERT). ALBERT adds a smaller size layer between vocabulary and hidden layer to decompose the embedding matrix of size |V|x|H| (between the vocabulary of size |V| and a hidden layer of size |H|) into two small matrices of size |V|x|E| and |E|x|H|. This idea reduces the number of parameters between vocabulary and the first hidden layer from O(|V|x|H|) to O(|V|x|E| + |E|x|H|), where |E| is the size of the new embedding layer between the hidden layer and vocabulary (see Figure 2).
2.嵌入分解 BERT中的嵌入大小等于隐藏层的大小(原始BERT中的768)。 ALBERT在词汇和隐藏层之间添加一个较小的层,以分解大小为| V | x | H |的嵌入矩阵 (大小为| V |的词汇和大小为| H |的隐藏层之间)分成大小为| V | x | E |的两个小矩阵 和| E | x | H |。 这个想法将词汇表和第一隐藏层之间的参数数量从O(| V | x | H |)减少到O(| V | x | E | + | E | x | H |) ,其中| E | 是隐藏层和词汇表之间的新嵌入层的大小(请参见图2)。

3. Sentence order prediction (SOP) predicts “+1” for consecutive pairs of sentences in the same document, and it predicts “-1” if the order of sentences is swapped or sentences are from separate documents. The idea is to replace the NSP loss by SOP loss. SOP loss will leverage topic prediction in BERT to coherence prediction in ALBERT. As you see in Table 2, ABERT slightly surpasses NSP loss by using SOP loss on four benchmarks, particularly on Stanford Question Answering (SQuAD).
3.句子顺序预测(SOP)为同一文档中的连续句子对预测“ +1”,如果句子顺序互换或句子来自不同的文档,则句子预测为“ -1”。 这个想法是用SOP损失代替NSP损失。 SOP丢失将利用BERT中的主题预测与ALBERT中的相干预测。 如表2所示,通过在四个基准上使用SOP损失,ABERT略超过NSP损失,尤其是在斯坦福问题解答(SQuAD)上。

讨论区 (Discussion)
We aimed to focus on memory issues, time consumed on training the model, and whether ALBERT fixes these issues? Table 2 shows the number of parameters in BERT versus ALBERT.
我们旨在关注内存问题,训练模型所花费的时间以及ALBERT是否解决了这些问题? 表2显示了BERT与ALBERT中的参数数量。

Is Albert significantly reducing the training time consumption? The answer is no because the authors only mentioned the number of unique parameters. Still, these parameters are repeated 12 times for each encore block, and the model performs backpropagation on all repeated parameters. For example, if you look at Albert-XXlarge, it has 235M parameters, but this is the number of the shared parameters per encoder, and the real number of parameters that pass through the backpropagation process is indeed 235Mx12 = 2.82B parameters in total. The only small difference might come from the embedding matrix that is containing a lower number of parameters as we explained above.
艾伯特会大大减少培训时间的消耗吗? 答案是否定的,因为作者只提到了唯一参数的数量。 尽管如此,这些参数对于每个Encore块都重复了12次,并且模型对所有重复的参数执行反向传播。 例如,如果您查看Albert-XXlarge,它具有235M个参数,但这是每个编码器共享参数的数量,并且经过反向传播过程的实际参数总数实际上总共为235Mx12 = 2.82B个参数。 唯一的细微差别可能来自包含如上所述的较少参数的嵌入矩阵。
Is Albert reducing the memory issues? The answer is yes since the parameter sharing part of the ALBERT helps us to store only one transformer block instead of 12 transformers. Therefore, the size of the stored model will be much smaller than the original BERT.
Albert减少了内存问题吗? 答案是肯定的,因为ALBERT的参数共享部分可帮助我们仅存储一个变压器块,而不是12个变压器。 因此,存储模型的大小将比原始BERT小得多。
最后一个字 (The Last Word)
While I was reading the abstract, I thought this could mean a breakthrough in transformers which helps us to have lighter models with almost the same performance as BERT. Still, after going through further details, it is not clear to me if this kind of repeated transformers work well on real problems and can capture different concepts of text data by only one set of repeated parameters. The fine-tuning might become much harder in less synthetic settings.
当我阅读摘要时,我认为这可能意味着变压器的突破,这将有助于我们获得重量更轻,性能几乎与BERT相同的模型。 不过,在进一步研究细节之后,我仍然不清楚这种重复的变形器是否可以很好地解决实际问题,并且仅通过一组重复的参数就可以捕获文本数据的不同概念。 在合成较少的环境中,微调可能会变得更加困难。
ALBERT is a proof of concept which brings promising results, and I still appreciate this direction and believe similar solutions might become more critical in the future. If these kinds of ideas can be used on a larger scale in the industry, they would be a perfect replacement for compact models implemented in small Embedded Devices like medical devices, phones, and the internet of things that require lighter models in terms of memory allocation.
ALBERT是一个概念证明,可带来可喜的结果,我仍然赞赏这个方向,并相信类似的解决方案将来可能变得越来越重要。 如果这些想法可以在行业中大规模使用,它们将是在小型嵌入式设备(如医疗设备,电话和需要在内存分配方面要求较轻的模型的物联网)中实现的紧凑模型的完美替代。 。
翻译自: https://medium.com/visionwizard/is-albert-short-for-bert-8c7891f1f711
linux albert















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









