





图像卷积神经网络


深层学习基础 (DEEP LEARNING BASICS)
Aim of this article is to provide an intuitive understanding of the key layers in a convolution neural network. The idea is to go beyond simply stating the facts and exploring how image manipulation actually works.
本文的目的是提供 对 卷积神经网络中 关键层的直观了解 。 这个想法 不只是简单地陈述事实 , 而是 探索 图像处理的实际作用 。
目标 (The Objective)
Suppose our aim is to train a deep learning network to successfully distinguish between cat and dog images like those shown below
假设我们的目标是训练一个深度学习网络,以成功地区分猫狗图像,如下图所示

Let us start by thinking about what challenges such an algorithm must overcome. To begin with, it must be able to detect cats and dogs of different color, size, shape, and breed. It must also work when only a certain portion and not the entire dog/cat is visible. The algorithm must be sensitive to the presence of more than one dog/cat in the image and most importantly, it must be spatially invariant — it must not expect the dog/cat to be in a certain part of the image. In the following sections, we explore how different components of a CNN architecture result in all these capabilities.
让我们首先考虑一下这种算法必须克服的挑战。 首先,它必须能够检测出不同颜色,大小,形状和品种的猫和狗。 当只有一部分而不是整个狗/猫可见时,它也必须起作用。 该算法必须对图像中存在不止一只狗/猫敏感,最重要的是,该算法必须在空间上不变-它不能指望狗/猫在图像的特定部分。 在以下各节中,我们将探索CNN架构的不同组件如何产生所有这些功能。
计算机如何读取图像。 (How a computer reads images.)
Images are composed of pixels with values that depict brightness and range from 0–255. 0 means black, 255 is white and everything else is some shade of grey. More the pixels, better the image quality.
图像由像素组成,其值表示亮度,范围为0-255。 0表示黑色,255表示白色,其他所有内容均为灰色。 像素越多,图像质量越好。

While a greyscale image is made of a single channel (i.e. a single 2D array of pixels), colored images in the RBG format are composed of three different layers, stacked on top of each other.
虽然灰度图像是由单个通道(即单个2D像素阵列)组成的,但是RBG格式的彩色图像由三个不同的层组成,彼此堆叠。

多层感知器的局限性。 (Limitations of a multi-layered perceptron.)
Conventional neural networks are not suitable for deep learning applications like image classification. The contents of each pixel are fed into the perceptron separately in the input layer. For a RGB image of dimensions 600*377*3, the total number of parameters to be learned for the input layer alone will be (600*377*3*2 (two parameters per neuron, weight and bias)) ~1.5 million. This number will scale linearly with the number of layers. This, however, is not the only challenge with MLPs. MLPs have no inbuilt mechanism for being spatially invariant. If a MLP has been trained to detect dogs in the top right corner of the image, it will fail when dogs are located in other locations.
传统的神经网络不适用于像图像分类这样的深度学习应用。 每个像素的内容分别在输入层中馈送到感知器中。 对于尺寸为600 * 377 * 3的RGB图像,仅输入层要学习的参数总数将为(600 * 377 * 3 * 2(每个神经元两个参数,权重和偏差))约150万。 该数字将与层数成线性比例。 但是,这并不是MLP的唯一挑战。 MLP没有内置的机制来保持空间不变。 如果已训练MLP在图像的右上角检测狗,则当狗位于其他位置时它将失败。
A convolution neural network aims to ameliorate these drawbacks using a built-in mechanism for (1) extracting different high level features (2) introducing spatial invariance (3) improving networks learning ability.
卷积神经网络旨在使用一种内置机制来改善这些缺点,该机制用于 (1)提取不同的高级特征(2)引入空间不变性(3)提高网络学习能力。
图像特征提取。 (Image feature extraction.)
Convolution (discrete convolution to be specific) is based on use to linear transformations to extract key features from images while preserving the ordering of information. The input is convolved with a kernel to generate the output, similar to the response generated by a network of neurons in the human visual cortex.
卷积(具体来说是离散卷积)是基于线性变换的使用,可从图像中提取关键特征,同时保留信息的顺序。 输入与 内核 进行 卷积 以生成输出,类似于由人类视觉皮层中的神经元网络生成的响应。
核心 (Kernel)
The kernel (also known as a filter or a feature detector) samples the input image matrix with a pre-determined step size (known as stride) in both horizontal and vertical directions. As the kernel slides over the input image, the element-wise product between each element of the kernel and overlapping elements of the input image is calculated to obtain to the output for the current location.
内核(也称为过滤器或特征检测器 )在水平和垂直方向 上以预定步长(称为 stride ) 对输入图像矩阵进行采样 。 当内核在输入图像上滑动时,将计算内核的每个元素与输入图像的重叠元素之间的逐元素乘积,以获取当前位置的输出。

When the input image is composed of multiple channels (which is almost always the case), the kernel has the same depth as the number of channels in the input image. The dot product in such cases is added to achieve the final feature map composed of a single channel. If you are new to matrix multiplication, check out this youtube video for a detailed explanation.
当输入图像由多个通道组成时(几乎总是这样),内核的深度与输入图像中通道的数量相同。 在这种情况下,点积被添加以获得由单个通道组成的最终特征图。 如果您不熟悉矩阵乘法,请 观看 此 youtube视频以获取详细说明。

Each convolution layer is composed of many different filters, each of which extracts different features. And while a CNN made of a single convolution layer will only extract/learn low level features, adding successive convolution layers significantly improves the ability to learn high level features.
每个卷积层由许多不同的滤镜组成,每个滤镜提取不同的特征。 而且,虽然由单个卷积层组成的CNN仅会提取/学习低层特征,但添加连续的卷积层会大大提高学习高层特征的能力。

整流器 (Rectifier)
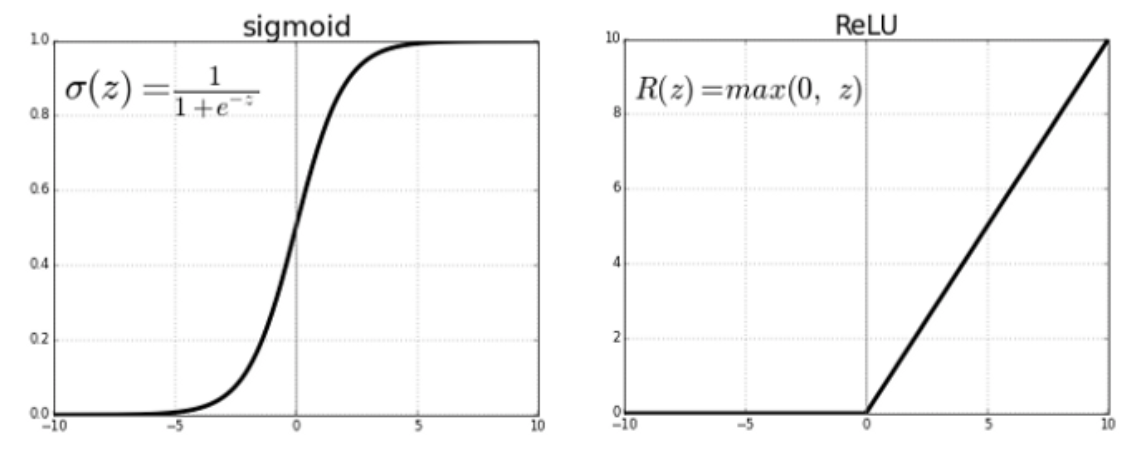
To introduce non-linearity into the system and improve the learning capacity, the output from the convolution operation is passed through a non-saturating activation function like sigmoid or rectified linear unit (ReLU). Check out this excellent article about these and several other commonly used activation functions. The most commonly used activation function ReLU essentially preserves positive values and replaces negative values with a zero.
为了将非线性引入系统并提高学习能力,卷积运算的输出将通过非饱和激活函数(如S型或整流线性单元(ReLU))传递。 查看 关于这些以及其他几个常用激活功能的 出色文章 。 最常用的激活函数ReLU本质上保留正值并将负值替换为零。
填充 (Padding)
The feature map resulting from convolution is smaller in size compared to the input image. For an input image of I*I that is convolved with a kernel of size K*K with a stride S, the output will be [(I-F)/S + 1]* [(I-F)/S + 1]. This can result in a substantial reduction in image size in CovNets made of several convolution layers. A zero padding of [(F-1)/2] all around the output image can be used to preserve the convolution output.
与输入图像相比,由卷积产生的特征图的大小较小。 对于 I * I 的输入图像,该图像 与大小为 K * K 且步幅为 S 的内核卷积 ,输出将为 [(IF)/ S +1] * [(IF)/ S +1] 。 这可能会导致由多个卷积层构成的CovNets中的图像大小大大减小。 输出图像周围的 [[F-1)/ 2] 零填充 可用于保留卷积输出。
For the most general case where an input image of size I*I is convolved with a filter of size K*K with a stride S and padding P, the output will have the dimension [(I+2P-K)/S +1]*[(I+2P-K)/S +1].
对于最常见的情况,输入大小为 I * I 的输入图像与大小 为 K * K 的滤镜( 具有步幅 S 和填充 P )进行卷积时 ,输出的尺寸为 [(I + 2P-K)/ S +1 ] * [(I + 2P-K)/ S +1] 。

汇集 (Pooling)
The convolution output is pooled so as to introduce spatial invariance i.e the ability to detect the same feature in different images. The idea here is to retain key information corresponding to important features that the CNN must learn and at the same time reduce image size by getting rid of insignificant information. While there are several variations, max pooling is the most commonly used strategy. The convolution product is split into non-overlapping patches of size K*K and only the maximum value of each patch is recorded in the output.
合并卷积输出以引入空间不变性,即在不同图像中检测相同特征的能力。 这里的想法是保留与CNN必须学习的重要功能相对应的关键信息,同时通过消除无关紧要的信息来减小图像尺寸。 尽管存在多种变体,但最大池化是最常用的策略。 卷积积被拆分为大小为 K * K的 非重叠面片, 并且仅每个面片的最大值记录在输出中。

Other less frequently used pooling strategies include average pooling, ‘mixed’ max-average pooling, stochastic pooling, and spatial pyramid pooling.
其他不常用的合并策略包括平均合并,“混合”最大平均合并,随机合并和空间金字塔合并。

The two key elements of CNN discussed so far: the convolution layer (defined by kernels, stride, activation function) and the pooling layer are combined in predetermined patterns to define the CNN architecture. While I won’t get into the architectural details, in the next section we discuss some general features of image processing by these neural networks.
到目前为止,我们讨论了CNN的两个关键元素:卷积层(由内核,步幅,激活函数定义)和池化层以预定模式组合在一起,以定义CNN体系结构。 虽然我不会深入探讨体系结构的细节,但在下一部分中,我们将讨论这些神经网络进行图像处理的一些常规功能。
可视化内层 (Visualizing the inner layers)
I used a publicly available dataset of labelled cat & dog images and trained a binary classifier (inceptionv3). Using this trained network we can get a feel of how a CNN actually processes an image.
我使用了 公开的 带有 标签的猫和狗图像的数据集,并训练了二进制分类器(inceptionv3)。 使用这个训练有素的网络,我们可以了解CNN实际如何处理图像。
First, we take a sample image and pass it through this trained network. The output of 3 convolution and associated activation layers (I used ReLU)are visualized below. What is immediately evident is that as we move down the network, the output becomes increasingly incomprehensible. By the time we are in layer 25, it is difficult to tell if the image fed into the network was a dog or a cat. It is worth noting that the overall architecture of this network is rather complex (and not included here) and layer 25 is not even half way down the network. So what are these layers actually learning? It is not obvious by merely looking at the image below.
首先,我们获取样本图像,并将其通过这个经过训练的网络。 下面显示了3个卷积和相关激活层(我使用ReLU)的输出。 显而易见的是,随着我们向下移动网络,输出变得越来越难以理解。 到我们进入第25层时,很难分辨馈入网络的图像是狗还是猫。 值得注意的是,该网络的总体架构相当复杂(此处未包括在内),而第25层甚至不在网络的中间。 那么这些层实际上在学习什么呢? 仅看下面的图像并不清楚。

The image above merely visualizes the output of each layer for an input image. What we need is to visualize the different kernels of each convolution layer. This will tell us what each of these filters is detecting. We start with an image made of random noise and optimize it for every kernel in a layer. In other words, we take a bunch of filters in a trained network and ask “ what kind of input image will activate this particular kernel’. Knowing this image will tell us more about what that particular filter is detecting. A more detailed explanation of this logic and associated code can be found here and here.
上面的图像仅可视化了输入图像每一层的输出。 我们需要的是可视化每个卷积层的不同内核。 这将告诉我们每个过滤器正在检测什么。 我们从随机噪声制成的图像开始,然后针对层中的每个内核对其进行优化。 换句话说,我们在训练有素的网络中使用了一堆过滤器,并询问“什么样的输入图像将激活此特定内核”。 了解此图像将告诉我们有关该特定过滤器正在检测的内容的更多信息。 有关此逻辑和相关代码的详细说明,请参见 此处 和 此处 。

Visualized above are some of the filter activation patterns for the same layers as above. Different layers are activated by different parts of the image. Layer 1 is essentially an edge detector that is activated by horizontal and vertical edges. As we go deeper into the network, patterns recognized by convolution kernels become complex and sparse as more abstract image features are extracted in these stages.
上面可视化的是与上述相同层的一些过滤器激活模式。 图像的不同部分会激活不同的图层。 层1本质上是一个边缘检测器,由水平和垂直边缘激活。 随着我们深入网络,在这些阶段提取更多抽象图像特征时,卷积核识别的模式变得复杂而稀疏。
结论。 (Conclusion.)
In this article, I have attempted to explain the design and inner workings of different convolution layers. Please do leave a comment or write to me at aseem.kash@gmail.com if you have any suggestions.
在本文中,我尝试解释了不同卷积层的设计和内部工作原理。 如果您有任何建议,请发表评论或写信至aseem.kash@gmail.com。
翻译自: https://towardsdatascience.com/how-convolution-neural-networks-interpret-images-1f99913070b2
图像卷积神经网络















 4791
4791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









