





伯特斯卡斯
重点 (Top highlight)
On October 25, 2019, Pandu Nayak, VP of Search for Google announced:
Google搜索副总裁Pandu Nayak于2019年10月25日宣布:
by applying BERT models to both ranking and featured snippets in Search, we’re able to do a much better job helping you find useful information. In fact, when it comes to ranking results, BERT will help Search better understand one in 10 searches in the U.S. in English, and we’ll bring this to more languages and locales over time. [1]
通过将BERT模型应用于Search中的排名和特色片段,我们可以做得更好,帮助您找到有用的信息。 实际上,就排名结果而言,BERT可以帮助Search更好地理解美国英语中十分之一的搜索,并且随着时间的推移,我们会将其带入更多的语言和地区。 [ 1 ]
Google’s remarks and explanations raise some key questions:
Google的言论和解释提出了一些关键问题:
- How much better is BERT than prior search relevance efforts? BERT比以前的搜索相关性要好多少?
- How are BERT models created? How are they fine tuned? BERT模型如何创建? 他们如何微调?
- What are the limitations and biases of BERT models? BERT模型的局限性和偏见是什么?
- How might these biases color how BERT sees webpage content? 这些偏见如何使BERT如何看待网页内容?
- Could a person use BERT to determine how well her content would perform for a particular query? 一个人可以使用BERT来确定其内容在特定查询中的效果如何?
- How does one “apply a BERT model” for a query and possible target pages to come up with a ranking? 如何为查询“应用BERT模型”以及可能的目标页面得出排名?
BERT比以前的搜索相关性要好多少? (How much better is BERT than prior search relevance efforts?)
In 2015, Crowdflower (now Appen←Figure-Eight←Crowdflower) hosted a Kaggle competition [2] where data scientists built models to predict the relevance for search results given a query, a product name and a product description. The winner, ChenglongChen pocketed $10,000 when his best model took first place by scoring 72.189% [3]. Although the competition has been closed for five years, the data set is still available and the Kaggle competition scoring functionality still works for the private leaderboard (it just doesn’t award any site points). I pulled the data, fine tuned a BERT classification model, predicted a submission, and it scored 77.327% [4].
2015年,Crowdflower(现在为Appen←Figure-Eight←Crowdflower)举办了Kaggle竞赛[ 2 ],数据科学家构建了模型来预测给定查询,产品名称和产品描述与搜索结果的相关性。 冠军,成龙,当他的最佳模特获得第一名时获得了10,000美元,得分为72.189%[ 3 ]。 尽管竞赛已经结束了五年,但数据集仍然可用,并且Kaggle竞赛计分功能仍适用于私人排行榜(它只是不授予任何现场得分)。 我提取了数据,微调了BERT分类模型,预测了提交,它的得分为77.327%[ 4 ]。
This winning result, although years late, shows how BERT has dramatically leapfrogged past the prior state of the art. The contest winner used an ensemble of 12 (!) machine learning models to vote on the best result:
这一获胜的结果尽管已经晚了几年,但显示出BERT是如何大大超越现有技术水平的。 竞赛获胜者使用12种(!)机器学习模型的组合对最佳结果进行投票:
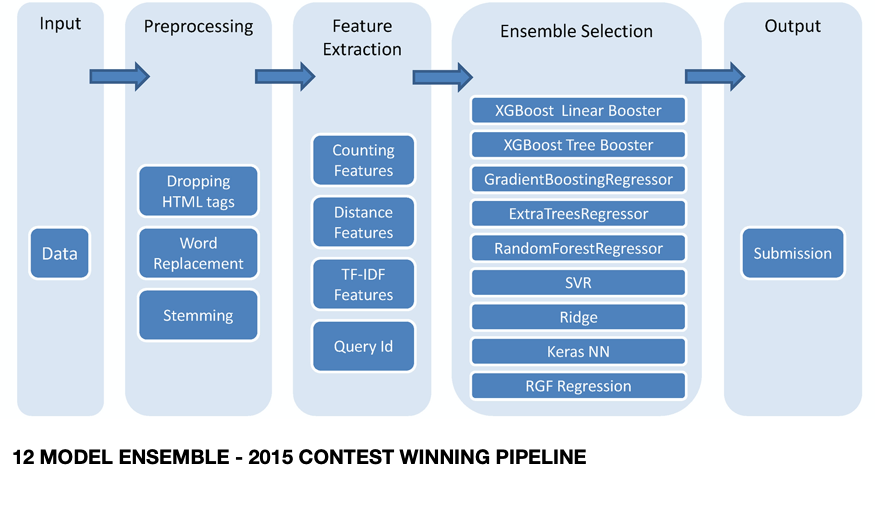
In contrast, my higher scoring result used one BERT model and a relatively simple pipeline:
相反,我的较高评分结果使用了一个BERT模型和一个相对简单的管道:

For my first model (and last model), featurization was “just take the first 505 tokens” across the three pieces of data (query, product title, product description) — without any special processing — and those are the results you see. In this article, we’ll look at how and why BERT can perform well with terrible and dirty input later in this article.
对于我的第一个模型 (也是最后一个模型),特征化是“跨越第三个数据(查询,产品标题,产品描述)仅获取前505个令牌”,而无需任何特殊处理,这就是您看到的结果。 在本文中,我们将在本文后面探讨BERT如何以及为什么在糟糕而肮脏的输入下表现良好。
The Kaggle Crowdflower Search Relevance data set has 20,571 labeled samples, and generating a submission requires predictions on 22,513 test samples. Although this is a small amount of data, and the domain is restricted to eCommerce products — data that BERT base wasn’t trained on — the BERT classifier nonetheless was able to start learning and predicting with groundbreaking accuracy.
Kaggle Crowdflower搜索相关性数据集具有20,571个标记的样本,并且要生成提交,需要对22,513个测试样本进行预测。 尽管这是少量数据,并且该域仅限于电子商务产品(BERT尚未接受过训练的数据),但BERT分类器仍能够以突破性的准确性开始学习和预测。
BERT模型如何创建? 他们如何微调? (How are BERT models created? How are they fine tuned?)
BERT is an acronym for Bidirectional Encoder Representations from Transformers [5], and it’s a language model. A language model encodes words and the log probabilities of words occurring together. The original BERT models did this by being trained on English Wikipedia and the Toronto BookCorpus. The training goals were next sentence prediction, and masked word prediction.The next sentence task chooses some neighboring sentences and gives them positive weights; and then chooses some random sentences and gives them negative weights: in this way, the BERT model learns to tell whether or not two sentences occurred in sequence. Many people theorize that this gives BERT a basis for some the Natural Language Understanding (NLU) that the model displays. In practice, BERT seems to know which words and sentences go together.The masked word task randomly hides a word and rewards BERT for being able to predict the missing word. This task, combined with network dropout, allows BERT to learn to infer a larger context from surrounding words.In practice, BERT is commonly used as the base layer for a more complex model; for example, an additional final layer is typically added and then the new layer is fine tuned to act as a classifier.
BERT是来自Transformers [ 5 ]的双向编码器表示的首字母缩写,它是一种语言模型。 语言模型对单词和在一起出现的单词的对数概率进行编码。 最初的BERT模型是通过在英语Wikipedia和Toronto BookCorpus上进行培训来做到这一点的。 培训目标是下一句预测和掩盖词预测。 下一个句子任务选择一些相邻的句子并赋予它们正的权重; 然后选择一些随机句子并赋予它们负的权重:通过这种方式,BERT模型可以学会判断两个句子是否依次出现。 许多人认为,这为BERT提供了模型显示的某些自然语言理解(NLU)的基础。 实际上,BERT似乎知道哪些单词和句子组合在一起。被掩盖的单词任务随机隐藏一个单词并奖励BERT能够预测丢失的单词。 这项任务与网络丢失相结合,使BERT可以学习从周围的单词中推断出更大的上下文。实际上,BERT通常用作更复杂模型的基础层。 例如,通常会添加一个额外的最终层,然后对新层进行微调以充当分类器。
I will not explain here the mechanics of the transformer model, read about it here [5]. The details of the best fine tuning techniques are still being worked out (judging by the number of Arxiv papers being published), and although hyperparameter tuning depends on your data, further exploration will surely be rewarding. However, before we rush to obsess over details, let us not miss the main point: when a new model with suboptimal hyperparameter tuning beats the previous state of the art by a large margin, search engine companies adopt it. Perfect is the enemy of the good. And sometimes the new good enough, is so good it causes companies to immediately adopt it as a strategic advantage even if the optimal fine tuning regime hasn’t been determined publicly.
我不会在这里解释变压器模型的机制,请在此处阅读[ 5 ]。 最佳微调技术的详细信息仍在制定中(根据发表的Arxiv论文数量来判断),尽管超参数微调取决于您的数据,但进一步的探索肯定会有所收获。 但是,在我们急于着迷细节之前,让我们不要错过重点:当具有次优超参数调整功能的新模型大大超越了先前的技术水平时,搜索引擎公司就会采用它。 完美是善的敌人。 有时,新的好产品是如此之好,以至于即使没有公开确定最佳的微调机制,公司也会立即将其用作战略优势。
To understand why BERT is so good at predicting search relevance, we’ll have to look into some its internals, limitations and biases.
要了解BERT为什么在预测搜索相关性方面如此出色,我们必须研究其内部,局限性和偏见。
BERT模型的局限性和偏见是什么? (What are the Limitations and Biases of BERT models?)
1. Limit of 512 tokens ~ words
1.最多512个令牌〜个单词
The BERT baseline model accepts a maximum of 512 tokens. Although it’s possible to construct a BERT model with less tokens, e.g. 256 tokens for tweets — or define and train a BERT model from scratch, e.g. with 1024 tokens for larger documents, the baseline is 512 for virtually all of the commonly available BERT models.
BERT基线模型最多接受512个令牌。 尽管可以用更少的令牌(例如,用于tweet的256个令牌)构建BERT模型,或者从头开始定义和训练BERT模型(例如,对于较大的文档使用1024个令牌),但是对于几乎所有常用的BERT模型,基线是512。
If your page is longer than 512 tokens or words, search engines might:
如果您的网页长度超过512个标记或单词,则搜索引擎可能会:
Just take the first 512 tokens
只需获得前512个令牌
— if your page doesn’t make its point in the first 512 tokens, the engine may not even see it (probably already true).
—如果您的页面没有在前512个令牌中找到其指向,则引擎甚至可能看不到它(可能已经是真的)。
- Reduce your page content to under 512 tokens via summarization algorithms (TextRank, Deep Learning, etc) or by applying algorithms to drop out unimportant words and sentences — but these computations are costly, so they might not be done for most pages. 通过汇总算法(TextRank,深度学习等)或通过应用算法删除不重要的单词和句子,将页面内容减少到512个令牌以下,但是这些计算成本很高,因此对于大多数页面而言,这样做可能是不可行的。
Note: Although we say 512 tokens/words, in practice, BERT will typically look at 505 tokens (assuming a 4 word query, with the required 3 BERT token separators). In practice the number of tokens of your content under consideration by a search algorithm may be far less than 505, as we’ll see.
注意:尽管我们说512个令牌/单词,但实际上,BERT通常会查看505个令牌(假设查询为4个单词,并带有3个BERT令牌分隔符)。 实际上,我们将看到,搜索算法正在考虑的内容令牌的数量可能远远少于505。
2. Not all words are tokens: many common words become single tokens; but longer and unfamiliar words are broken up into subtokens.
2.并非所有单词都是标记:许多常见单词变成单个标记; 但较长且不熟悉的单词会分解为子标记。
A good illustration of this can be seen with some words that have variations between the British and American English spellings. Sometimes the subword tokenization can be quite costly:
某些单词在英美英语拼写之间存在差异,可以很好地说明这一点。 有时,子词标记化可能会非常昂贵:
bert_tokenizer.tokenize(‘pyjamas’), bert_tokenizer.tokenize(‘pajamas’)[‘p’, ‘##y’, ‘##ja’, ‘##mas’], [‘pajamas’]
bert_tokenizer.tokenize('pyjamas'),bert_tokenizer.tokenize('pajamas')['p','## y','## ja','## mas'],['pajamas']
bert_tokenizer.tokenize(‘moustache’), bert_tokenizer.tokenize(‘mustache’)[‘mo’, ‘##ust’, ‘##ache’], [‘mustache’]
bert_tokenizer.tokenize('moustache'),bert_tokenizer.tokenize('mustache')['mo','## ust','## ache'],['mustache']
Sometimes, there is no difference:
有时,没有区别:
[‘colour’], [‘color’]
['colour'],['color']
but often the less familiar spellings yield multiple tokens:
但通常不太熟悉的拼写会产生多个标记:
[‘aero’, ‘##plane’], [‘airplane’][‘ars’, ‘##e’], [‘ass’][‘jem’, ‘##my’], [‘jimmy’][‘orient’, ‘##ated’], [‘oriented’][‘special’, ‘##ity’], [‘specialty’]
['aero','## plane'],['airplane'] ['ars','## e'],['ass'] ['jem','## my'],['jimmy' ] ['orient','## ated'],['iented'] ['special','## ity'],['specialty']
Rarely, but sometimes, the British spelling variation becomes tokenized with fewer tokens:
很少(但有时),英式拼写变化会以较少的标记被标记化:
[‘potter’], [‘put’, ‘##ter’]
['potter'],['put','## ter']
3. Outright misspelling are implicitly penalized:
3.完全拼写错误将受到隐式处罚:
bert_tokenizer.tokenize(‘anti-establishment’)[‘anti’, ‘-’, ‘establishment’]
bert_tokenizer.tokenize('反建立')['反','-','建立']
bert_tokenizer.tokenize(‘anti-establisment’)[‘anti’, ‘-’, ‘est’, ‘##ab’, ‘##lism’, ‘##ent’]
bert_tokenizer.tokenize('anti-establisment')['anti','-','est','## ab','## lism','## ent']
Although these penalties may seem shocking, they actually indicate how forgiving BERT is; the model will try to make sense of just about anything you give it, instead of dropping misspelled words or ignoring something it hasn’t seen before. Also, these biases are not a plot against British language spelling variations, but rather a side effect of the training data: a BERT model and its BERT tokenizer typically have a limited vocabulary (typically 30,000 words, including subtokens) carefully chosen so that virtually any word can be encoded, and many of the most common words are promoted to being represented as individual tokens. This popularity contest of words and tokens is based on the original training data. The original BERT models were trained on English Wikipedia and some additional texts from the Toronto BookCorpus (11,038 books, 47,004,228 sentences). Clearly, British spelling variations weren’t dominant in that corpus.
尽管这些惩罚似乎令人震惊,但它们实际上表明了BERT的宽容程度。 该模型将尝试弄清您提供的所有内容,而不是删除拼写错误的单词或忽略之前从未见过的内容。 而且,这些偏见不是针对英语拼写变化的图,而是训练数据的副作用:BERT模型及其BERT令牌生成器通常只有经过严格选择的词汇量(通常为30,000个单词, 包括子令牌),因此几乎单词可以被编码,并且许多最常见的单词被提升为表示为单独的标记。 这次单词和代币的流行竞赛基于原始的训练数据。 最初的BERT模型在英语维基百科和多伦多BookCorpus的一些其他文本上进行了训练(11,038本书,47,004,228句子)。 显然,英国语的拼写变化在该语料库中并不占主导地位。
If you’re analyzing documents with British English spelling variations, it would probably be profitable to normalize the spellings prior to feeding them into a BERT model. A well-trained model can generalize about things it hasn’t seen before, or only has been partially trained on, but the best model performance occurs with familiar data.
如果您要分析具有英式英语拼写差异的文档,则在将拼写输入BERT模型之前对其进行规范化可能会很有利。 训练有素的模型可以概括一下以前从未见过的东西,或仅对其进行了部分训练,但最佳模型性能来自熟悉的数据。
With many other language models, and word vectors, it’s easy to identify if the word is new and if the language model has been trained on it, and these types of words have their own term: OOV, out of vocabulary. But it’s not easy to determine if BERT has never seen a word or been repeated trained with it, since so many words are broken up by subtokens. But this minor weakness is a source of great strength: in practice BERT can synthesize a word’s meaning based on the history and understanding of similar neighboring tokens.
使用许多其他语言模型和单词向量,可以很容易地确定单词是否是新单词以及是否已经对其进行了语言模型训练,并且这些类型的单词都有其自己的术语:OOV, 不属于词汇 。 但是,要确定BERT是否从未看过一个单词还是经过反复训练,并不容易,因为这么多单词被子标记分解了。 但是,这种弱点是强大力量的源泉:实际上,BERT可以根据历史和对类似相邻标记的理解来综合一个单词的含义。
4. BERT will ignore some items. Categorically, emojis are unknown to BERT. - Typically, BERT tokenizes emojis as Unknown (literally ‘[UNK]’), and if these aren’t dropped when compressing your page, they don’t add any value when the model sees them.
4. BERT将忽略某些项目。 绝对来说,BERT不知道表情符号。 -通常,BERT将表情符号标记为Unknown(字面意义为[[UNK]]),如果在压缩页面时这些表情符号没有被丢弃,则当模型看到它们时它们不会增加任何值。
toker.tokenize(‘😍 🐶 ❤️’)[‘[UNK]’, ‘[UNK]’, ‘[UNK]’]
toker.tokenize('😍❤❤️')['[UNK]','[UNK]','[UNK]']
这些偏见如何使BERT如何看待网页内容? (How might these biases color how BERT sees webpage content?)
Fundamentally, since BERT models accept a limited amount of tokens (typically < 505), if your page uses unusual words or uncommon spellings, your page content will be split into more tokens, and in effect, the BERT model will end up seeing less of your page than a similar page that uses more common words and popular spellings.
从根本上讲,由于BERT模型接受的令牌数量有限(通常<505),因此,如果您的页面使用不正常的单词或不常见的拼写,则页面内容将被拆分为更多的令牌,实际上,BERT模型最终会看到更少的您的网页要比使用更多常用词和常用拼写的相似网页好。
This does not mean that you should aim to create pages that exactly mimic the style of Wikipedia. For a long time, search engines have preferred articles with general appeal, using common words and standardized spellings, written more akin to the news or Wikipedia articles than an aimless wandering of verbiage. So in a sense, the use of BERT natively supports the best practices of writing content for search engines.
这并不意味着您应该致力于创建完全模仿Wikipedia风格的页面。 长期以来,搜索引擎一直偏爱具有通用吸引力的文章,使用的是常用词和标准化的拼写,它们的撰写更类似于新闻或维基百科的文章,而不是漫无目的的游说。 因此,从某种意义上讲,BERT的使用本身就支持为搜索引擎编写内容的最佳实践。
为什么BERT这么擅长预测搜索结果? (Why is BERT so good at predicting search results?)
Fundamentally both of BERT’s training objectives work together: word masking helps BERT build a context for understanding, and the next sentence prediction, well, — isn’t the problem of content relevance often a matter of determining how well one search query “sentence” is paired with one search result “sentence”?
根本上,BERT的两个培训目标都可以协同工作:单词屏蔽可以帮助BERT建立理解的上下文,接下来的句子预测-内容相关性的问题通常不是确定一个搜索查询“句子”的好坏的问题。与一个搜索结果“句子”配对?
We have already seen how BERT has the ability to synthesize meaning from subword tokens and neighboring words. This skill gives BERT an advantage since 15% of search queries contain words that have never been seen before [1]. BERT is a natural predictor for the meaning of unknown terms needed to determine search relevance.
我们已经看到了BERT如何具有从子词标记和相邻词中合成含义的能力。 这项技术为BERT带来了优势,因为15%的搜索查询包含以前从未见过的单词[ 1 ]。 BERT是确定搜索相关性所需的未知术语含义的自然预测器。
一个人可以使用BERT来确定其内容在特定查询中的效果如何? (Could a person use BERT to determine how well her content would perform for a particular query?)
In short, probably not; to understand why, lets deep dive on how BERT is likely used to assess how well a query and a page match. On a high level, to answer this, they might pick a number of pages to check and run your query against those pages to predict the relevance.
简而言之,可能不是; 要了解原因,请深入探讨BERT如何用于评估查询和页面匹配的程度。 从高层次上讲,他们可能会选择许多页面进行检查并针对这些页面运行查询以预测相关性。

Most search queries are four words or less, and most page summaries are less than five hundred and five words (otherwise it isn’t much of a summary). Search relevance scores are commonly segmented as: 1. off topic, 2. okay, 3. good, and 4. excellent. [2]
大多数搜索查询少于四个字,大多数页面摘要少于505个字(否则,摘要不多)。 搜索相关性分数通常分为以下几类:1.脱离主题; 2。可以; 3。良好; 4。优秀。 [ 2 ]
When ML engineers build a model to estimate how well a query matches to search results, it’s common that they will train on about 1 million examples. Why so many? A deep learning model needs a lot of data to be able to generalize well and predict things it hasn’t seen before. If you’re trying to build an all purpose general search engine, you’ll need a lot of data. However, if your search space is smaller, such as just eCommerce technology, or just the products of a home improvement website, etc, then only a few thousand labeled samples may be necessary to beat the previous state of the art. Uncommon data is a regular component of search queries:
当ML工程师建立模型来估计查询与搜索结果的匹配程度时,通常会训练大约一百万个示例。 为什么那么多? 深度学习模型需要大量数据,才能很好地概括和预测以前从未见过的事物。 如果您要构建通用的通用搜索引擎,则需要大量数据。 但是,如果您的搜索空间较小(例如,仅是电子商务技术或仅是家装网站的产品等),那么仅需几千个带有标签的样本即可击败以前的最新技术。 罕见数据是搜索查询的常规组成部分:
15 percent of those queries are ones we haven’t seen before — Pandu Nayak, VP Search, Google
其中有15%的查询是我们之前从未见过的-Google搜寻副总裁Pandu Nayak
Several thousand labeled samples can provide some good results, and of course, a million labeled samples will likely provide great results.
数千个标记的样本可以提供一些良好的结果,当然,一百万个标记的样本可能会提供出色的结果。
如何为查询“应用BERT模型”和可能的目标页面得出排名? (How does one “apply a BERT model” for a query and a possible target page to come up with a ranking?)
The Kaggle Crowdflower competition data provides interesting hints about how extra data is often used in practice. Typically more features, when available, are added to a model to make it more flexible and be able to predict across a range of inputs.For example, earlier we formulated the search ranking problem as:
Kaggle Crowdflower竞赛数据提供了有关实践中如何经常使用额外数据的有趣提示。 通常,将更多功能(如果可用)添加到模型中,以使其更加灵活并能够在一系列输入中进行预测。例如,我们之前将搜索排名问题表述为:
But in the Kaggle submission query data, extra information is available, or sometimes missing, so the features would be formatted as:
但是在Kaggle提交查询数据中,额外的信息可用,或者有时会丢失,因此功能的格式应为:

In some of the test cases, only the query and the product title are provided, and in real world situations there might be little or no page content provided.For example if your company has a product page for “Sony PS6 — Founders Edition” and that page has dynamic content like recent tweets or testimonials of purchasers, user images, etc, it is quite possible a search engine might only use the page title (or some type of metadata about the page) and effectively none of the page content. The lesson is clear, when providing web content it’s important to focus on relevant information that accurately reflects your product and content first and foremost.
在某些测试案例中,仅提供查询和产品标题,而在实际情况下,可能提供的页面内容很少或根本没有。例如,如果您的公司有“ Sony PS6-Founders Edition”的产品页面,而该页面具有动态内容,例如最近的推文或购买者的推荐书,用户图像等,很有可能搜索引擎可能只使用页面标题(或有关页面的某些类型的元数据),而实际上没有页面内容。 本课很清楚,在提供Web内容时,着重于首先准确地反映您的产品和内容的相关信息非常重要。
BERT is here to stay, and its impact on search relevance is only going to increase. Any company that provides search to their customers or in-house clients can use BERT to improve the relevance of their results. With very little data, a BERT classifier can beat the previous state of the art, and more data will help yield better results and more consistent performance.
BERT留在这里,它对搜索相关性的影响只会增加。 任何向其客户或内部客户提供搜索的公司都可以使用BERT来提高其结果的相关性。 只需很少的数据,BERT分类器就可以超越现有技术水平,而更多的数据将有助于产生更好的结果和更一致的性能。
翻译自: https://towardsdatascience.com/how-bert-determines-search-relevance-2a67a1575ac4
伯特斯卡斯















 1641
1641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









