





 本文介绍了逻辑斯蒂回归和逻辑回归的概念,重点在于它们在数据分析和预测中的应用。通过翻译自Medium的文章,读者可以了解到这两种回归方法的基本原理和使用场景。
本文介绍了逻辑斯蒂回归和逻辑回归的概念,重点在于它们在数据分析和预测中的应用。通过翻译自Medium的文章,读者可以了解到这两种回归方法的基本原理和使用场景。
逻辑斯蒂回归 逻辑回归
Logistic regression is a classification algorithm, which is pretty popular in some communities especially in the field of biostatistics, bioinformatics and credit scoring. It’s used to assign observations a discrete set of classes(target).
Logistic回归是一种分类算法,在某些社区中非常流行,尤其是在生物统计学,生物信息学和信用评分领域。 它用于为观察值分配一组离散的类(目标)。
为什么不进行物流分类? (Why not logistic classification?)
Logistic regression is strictly not a classification algorithm on its own. Because its output is a probability(a continuous number between 0 and 1), it will be only a classification algorithm in combination with a decision boundary which is generally fixed at 0.5
逻辑回归本身并不是严格的分类算法。 因为它的输出是概率(0到1之间的连续数),所以它仅是分类算法,结合了通常固定为0.5的决策边界
For example, if we have a logistic regression that has to predict whether an email is a spam or not, the output of the function will be 0.2 or 0.7. By default, the logistic regression makes it easier for us by assigning 0(not a spam) for the one who got 0.2 and assigning 1(a spam) for the latter. The threshold is 0.5 but we can manage to change it.
例如,如果我们具有必须预测电子邮件是否为垃圾邮件的逻辑回归,则函数的输出将为0.2或0.7。 默认情况下,逻辑回归使我们更容易,为获得0.2的人分配0(不是垃圾邮件),为获得0.2的人分配1(垃圾邮件)。 阈值为0.5,但我们可以设法对其进行更改。
与线性回归的比较 (Comparison to linear regression)
Let’s suppose you have data on time spent studying, playing and exam score.
假设您有关于学习,游戏和考试成绩的时间数据。
Linear Regression: because it’s a regression, meaning that the output is continuous, it could help us predict the student test score between a certain range.
线性回归:因为它是回归,所以表示输出是连续的,因此可以帮助我们预测学生在一定范围内的考试成绩。
Logistic Regression: this one could help us predict whether the student passed the exam or not. Its output is binary but we can also see the probability given for each student (after all the probability is the real output).
Logistic回归:这可以帮助我们预测学生是否通过了考试。 它的输出是二进制的,但是我们也可以看到为每个学生给出的概率(毕竟概率是真实的输出)。
逻辑回归的类型 (Types of logistic regression)
- Binary (ex: malignant or benign tumor) 二元(例如:恶性或良性肿瘤)
- Multi (ex: Animal classification) 多(例如:动物分类)
- Ordinal: (ex: Low, Medium, High) 顺序:(例如:低,中,高)
二元逻辑回归 (Binary logistic regression)
In this article we will treat binary logistic regression. In a nutshell, logistic regression is a sigmoid of a linear regression.
在本文中,我们将处理二进制逻辑回归。 简而言之,逻辑回归是线性回归的S形。
First of all let’s see how linear regression works.
首先,让我们看看线性回归是如何工作的。
where:
哪里:
- xᵢ are the features we have xᵢ是我们拥有的功能
- ωᵢ are the coefficient of those features ωᵢ是这些特征的系数
- ω₀ is the intercept(a sort of error calibration) ω₀是截距(一种误差校准)
乙状结肠功能 (The sigmoid function)
Here comes the sigmoid function so we can switch from the linear regression principle to a logistic one.
出现了S型函数,因此我们可以从线性回归原理转换为对数函数。
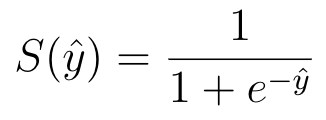
In order to map predicted values to probabilities, we use the sigmoid function. So every real value is converted to a continuous one between 0 and 1.
为了将预测值映射到概率,我们使用了S型函数。 因此,每个实数值都将转换为0到1之间的连续值。
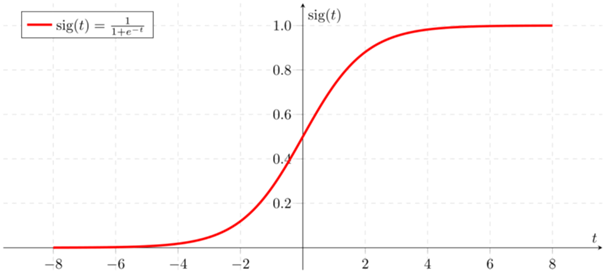
决策边界 (Decision Boundary)
We already talked about the decision boundary or threshold. So, in order to map the output of the sigmoid which is a value between 0 and 1, we can choose a threshold to say whether the observation is from class A or class B. By default, the boundary is 0.5 but it can be really dangerous in some fields like bioinformatics to not decrease it.
我们已经讨论了决策边界或阈值。 因此,为了映射Sigmoid的输出(介于0和1之间的值),我们可以选择一个阈值来说明观察结果是来自A类还是来自B类。默认情况下,边界为0.5,但实际上可以是在某些领域很危险,例如生物信息学,不能减少它。
成本函数 (Cost function)
Unfortunately we cannot use the means square error(MSE) used in the linear regression. Why ? good question. Well now because our sigmoid function is not linear, squaring it would not let the problem be a convex one, thus the gradient descent will not work correctly. It may find a local minimum which can be very far from the global one.
不幸的是,我们不能使用线性回归中使用的均方误差(MSE)。 为什么呢 好问题。 现在好了,因为我们的S形函数不是线性函数,对它进行平方将不会使问题成为凸函数,因此梯度下降将无法正常进行。 它可能会发现一个局部最小值,该最小值可能与全局最小值相差甚远。
Instead we can use the Cross-Entropy also known as Log-Loss. It’s a convex simple function with which the gradient descent feels good to be applied to.
相反,我们可以使用交叉熵(也称为对数损失)。 这是一个凸的简单函数,可用于渐变下降感觉很好。

where:
哪里:
- Omega is the set of coefficients 欧米茄是系数的集合
- m is the number of observations m是观察数
梯度下降 (Gradient Descent)
Now we have our loss function, we need a way to minimize it which is equivalent to maximize the probability we want to have. For that, we use the gradient descent just like in other machine learning algorithms like neural networks.
现在我们有了损失函数,我们需要一种最小化它的方法,这等效于最大化我们想要的概率。 为此,就像在其他机器学习算法(例如神经网络)中一样,我们使用梯度下降。

We can improve the computation by adding a step alpha and an optimizer to our gradient.
我们可以通过在渐变中添加阶跃alpha和优化器来改善计算。
正则化 (Regularization)
Regularization is a sort of calibration to not overfit the training set but are also a type of optimization. Regularization does NOT improve the performance on the training data, however it can improve the generalization performance which means when we’ll test our model in a different dataset, it has more chance to perform well as it tries as much to not overfit the training data.
正则化是一种校准,它不会过度拟合训练集,但也是一种优化。 正则化不能改善训练数据的性能,但是可以改善泛化性能,这意味着当我们在不同的数据集中测试模型时,它会有更多的表现机会,因为它会尽力避免过度拟合训练数据。
L2正则化(Ridge) (L2 Regularization (Ridge))
In ridge regularization, the loss function is bit changed by adding a penalty equivalent to square of the magnitude of the coefficients.
在脊正则化中,通过添加等于系数幅度平方的罚分来对损失函数进行位更改。
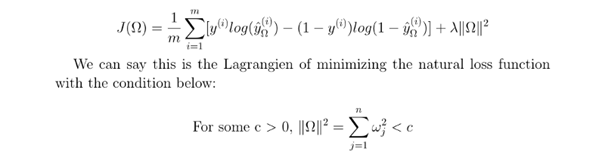
So here we can see that lambda is playing the coefficients regulator, i.e the higher lambda is, the more large values are penalized and if λ = 0, it’s just the simple loss function. The lower λ is, the model will be similar to the one without a regularization.
因此,在这里我们可以看到lambda扮演着系数调节器的角色,即lambda越高,惩罚的数值越大,如果λ= 0,那只是简单的损失函数。 较低的λ是,该模型将类似于没有正则化的模型。
L1正则化(套索) (L1 Regularization (Lasso))
In lasso regularization, the loss function is added by a penalty equivalent to the absolute value of the magnitude of the coefficients. And the same explanation for Ridge goes here.
在套索正则化中,损失函数被加上等于系数大小的绝对值的罚分。 对Ridge的解释也一样。
We can see below how the conditions change the true optimal point which is the black one to the point where the red curve and the blue area are intersecting.
我们可以在下面看到条件如何将真正的最佳点(黑色点)更改为红色曲线和蓝色区域相交的点。
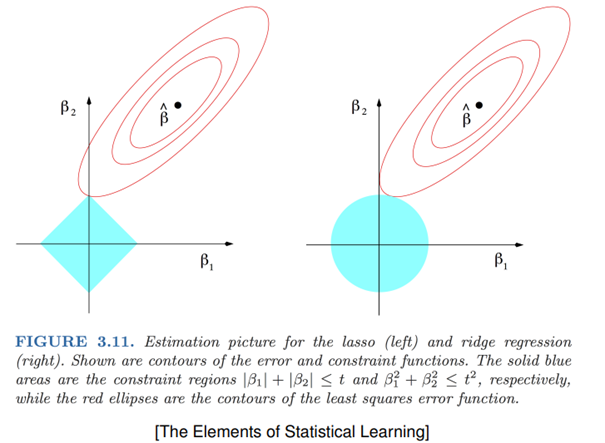
In the left(lasso regularization), we can clearly see that the optimal point gives us one feature and totally penalise the other. And here it comes the optimisation of the complexity. So in a higher dimension space, we can really earn time by penalizing some features.
在左侧(套索正则化)中,我们可以清楚地看到最优点为我们提供了一个功能,而对另一个功能则完全不利。 这就是复杂性的优化。 因此,在更高维度的空间中,我们可以通过惩罚某些功能来真正节省时间。
我应该标准化我的数据吗? (Should I standardize my data?)
Standardization or normalization isn’t required for logistic regression. It’s just to make convergence in the optimization faster otherwise you can run your model without any standardization BUT if you are using Lasso or Ridge regularization you SHOULD apply it first since regularization is based on the magnitude of the coefficient i.e features with large coefficients will be more penalized.
逻辑回归不需要标准化或标准化。 只是为了使优化中的收敛更快,否则,如果您使用的是Lasso或Ridge正则化,则可以在没有任何标准化BUT的情况下运行模型,因此应首先应用它,因为正则化基于系数的大小,即具有较大系数的特征会更多受罚的。
The ridge/Lasso solutions are not equivariant under scaling of the inputs, and so one normally standardizes the inputs before solving.[1]
脊/套索解在输入的缩放比例下不是等变的,因此通常在求解之前将输入标准化。[1]
Standardization also helps us interpreting the coefficients.
标准化还有助于我们解释系数。
系数分析 (Coefficient Analysis)
After scaling the data, it’s simple to interpret and explain the sign of the coefficient:
缩放数据后,可以很容易地解释和解释系数的符号:
- The positive one means the feature is correlated positively with the target 正数表示特征与目标正相关
- The negative one means it’s correlated negatively with the target. 负数表示它与目标负相关。
However, because of outliers, unbalanced data or sometimes the nature of the feature, we can have different results if we just ignore an observation. So one way to make sure your logistic regression is robust and consistent, is to do a bootstrapping method so we can see the behavior of the coefficients and assert that they are very good or not.
但是,由于异常值,数据不平衡或者有时是要素的性质,如果我们忽略观察值,我们可能会得到不同的结果。 因此,确保逻辑回归稳定且一致的一种方法是采用自举方法,以便我们可以看到系数的行为并断言它们是否很好。
If it’s a good coefficient, we’ll have a Gaussian distribution.
如果它是一个好的系数,我们将有一个高斯分布。
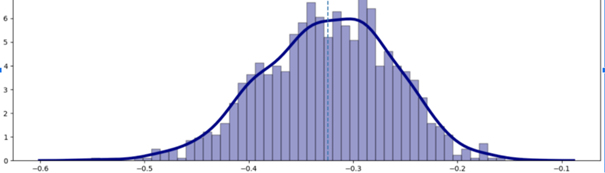
Remember, your coefficients should not:
请记住,您的系数不应:
- Change their sign, otherwise something is wrong because it will no longer be interpretable. 更改其符号,否则将出现问题,因为它将不再可解释。
- Have a different distribution other than Gaussian one or at least the skewed normal distribution. 除高斯一或至少偏态正态分布外,具有不同的分布。
结论 (Conclusion)
What you need to keep from this article are:
您需要从本文中保留的是:
- Logistic regression is a sigmoid function on top of linear regression Logistic回归是线性回归基础上的S形函数
- The loss function for logistic regression is the cross-entropy and not the mean square error Logistic回归的损失函数是交叉熵,而不是均方误差
- We can add regulators to have performance on different set and sometimes for optimisation 我们可以添加调节器以在不同设备上具有性能,有时还可以进行优化
- Do not forget to do a small analysis of your coefficients so you can be sure your model is robust 不要忘记对系数进行小幅分析,以确保模型可靠
You can find the source code of logistic regression from scratch here.
您可以在此处从头找到逻辑回归的源代码。
[1] T. Hastie, R. Tibshirani and J Friedman, The Elements of Statistical Learning (2008), Data Mining, Inference, and Prediction p.63
[1] T. Hastie,R。Tibshirani和J Friedman, 《统计学习的要素》 (2008年),数据挖掘,推理和预测,第63页
翻译自: https://medium.com/the-innovation/introduction-to-logistic-regression-fb273b84b186
逻辑斯蒂回归 逻辑回归















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









