





 本文翻译自GitConnected,介绍如何利用ARIMA模型预测股票价格。通过深度学习和Python库TensorFlow,构建预测模型以分析和预测股票市场的走势。
本文翻译自GitConnected,介绍如何利用ARIMA模型预测股票价格。通过深度学习和Python库TensorFlow,构建预测模型以分析和预测股票市场的走势。
预测股票价格 模型
前言 (Preface)
If you are reading this, it’s most likely because you love to solve puzzles. I’m a very competitive person by nature. The Mt. Everest of puzzles, in my opinion, is trying to find excess returns through active trading in the stock market. This blog is my first of many posts of an attempt to — hopefully — summit the intimidating Mt. Everest of algorithmic trading and emerge profitably.
如果您正在阅读本文,则最有可能是因为您喜欢解决难题。 我天生就是一个很有竞争力的人。 山。 我认为,珠穆朗玛的难题正试图通过股票市场上的活跃交易来寻找超额收益。 这个博客是我尝试(希望)登顶这座令人生畏的山峰的众多文章中的第一篇。 算法交易的珠穆朗玛峰并盈利。
First off, I must atone for my sins. I am a failed daytrader. I attempted day trading over a summer during a hiatus from work. Everything I read told me to have a plan before I entered a trade, and when I did enter a trade to stick to my trading plan despite whatever emotion I may be feeling. I was confident that this would be no problem. I have a pretty good grasp on all my vices — don’t we all? If you’re human, then the answer is no. No, you don’t have your vices under control. That is the literal definition of a vice. I was naive and thankfully was able to quit before I did any real damage to my account. However, like a moth to a flame, I can’t leave a good puzzle. I am going back into the fray, but this time I have a plan. I plan on building a purely quantitative system that removes the worst part of any trading plan (yourself) from the equation.
首先,我必须赎罪。 我的交易员失败了。 我在工作中断期间试图在整个夏天进行日间交易。 我阅读的所有内容都告诉我在进入交易之前要有一个计划,而当我进入交易时要坚持我的交易计划,尽管我可能会感到任何情绪。 我相信这不会有问题。 我对所有的恶习都掌握得很好–不是所有人吗? 如果您是人类,那么答案是否定的。 不,您不受控制。 那是恶习的字面定义。 我很天真,幸好我能够在对帐户造成任何实际损失之前退出。 但是,就像飞蛾扑火一样,我不能留下一个好谜。 我将重返战场,但是这次我有一个计划。 我计划建立一个纯粹的量化系统,以消除等式中任何交易计划(您自己)的最糟糕部分。
Before you go any farther, let me say this blog post is simply about ARIMA models, and this preface is just a teaser for the full algorithmic trading system that will come in the future. If the intro did not scare you off, let’s begin with a simple ARIMA model that helps us predict tomorrow’s daily closing price of whatever stock you choose.
在继续之前,请允许我说这篇博客文章只是关于ARIMA模型的,并且此序言只是对将来将要使用的完整算法交易系统的预告。 如果介绍没有吓倒您,让我们从一个简单的ARIMA模型开始,该模型可以帮助我们预测所选股票的明天每日收盘价。
让我们编码 (Let’s Code)
ARIMA is an acronym that stands for AutoRegressive Integrated Moving Average. Throughout this blog, I will break down the steps necessary to implement a successful ARIMA model.
ARIMA是首字母缩写词,代表自动回归综合移动平均线。 在整个博客中,我将分解实现成功ARIMA模型的必要步骤。
步骤1:取得资料 (Step 1: Get the data)
For this example, we will use the SPY ETF. The SPY is an ETF that mimics the S&P500, which is a basket of stocks weighted by market cap. Many ETFs mimic the S&P 500, but this is the most common and most liquid fund.
在此示例中,我们将使用SPY ETF。 SPY是模仿S&P500的ETF,S&P500是按市值加权的一篮子股票。 许多ETF模仿标准普尔500指数,但这是最常见和最具流动性的基金。
To use this, we will use the yfinance API. If you do not have this API installed, a simple pip install in your Jupyter Notebook should do. If you wish to learn more about this API, check out the PyPI page for more details.
要使用此功能,我们将使用yfinance API。 如果您尚未安装此API,则应该在Jupyter Notebook中进行简单的pip安装。 如果您想了解更多有关此API的信息, 请查看PyPI页面以获取更多详细信息 。
!pip install yfinanceNow, let’s pull the entire daily history of the ticker “SPY” into a neat data frame.
现在,让我们将股票代码“ SPY”的整个每日历史记录拉入一个整洁的数据框中。
import yfinance as yf
import pandas as pdspy = yf.Ticker("SPY")# get stock info
spy.info# get historical market data as df
hist = spy.history(period="max")# Save df as CSV
hist.to_csv('SPY.csv')# Read back in as dataframe
spy = pd.read_csv('SPY.csv')# Convert Date column to datetime
spy['Date'] = pd.to_datetime(spy['Date'])If you print out “spy.info” you will get a dictionary of a lot of extra data on the stock. All we are currently worried about for this model is the closing price. The object “hist” is a dataframe, and we send it to CSV to have a local copy. You can run this every day after the market closes and get the most up to date information if you want.
如果您打印出“ spy.info”,您将获得有关大量库存额外数据的词典。 我们目前对此模型担心的只是收盘价。 对象“ hist”是一个数据框,我们将其发送到CSV以获取本地副本。 您可以在市场收盘后每天执行此操作,并根据需要获取最新信息。
步骤2:分割资料 (Step 2: Split your data)
This code is coming directly from my notebook, which multiple models in it, so the data split may seem a bit overkill. For purely this ARIMA model, you would only need a train and test data set. However, the code I provide splits the data into a train, test, and validation data set. Splitting your data is extremely important in all machine learning applications.
这段代码直接来自我的笔记本,笔记本中有多个模型,因此数据拆分似乎有些过头。 仅对于此ARIMA模型,您只需要训练和测试数据集。 但是,我提供的代码将数据分为训练,测试和验证数据集。 在所有机器学习应用程序中,分割数据极为重要。
# Set target series
series = spy['Close']# Create train data set
train_split_date = '2014-12-31'
train_split_index = np.where(spy.Date == train_split_date)[0][0]
x_train = spy.loc[spy['Date'] <= train_split_date]['Close']# Create test data set
test_split_date = '2019-01-02'
test_split_index = np.where(spy.Date == test_split_date)[0][0]
x_test = spy.loc[spy['Date'] >= test_split_date]['Close']# Create valid data set
valid_split_index = (train_split_index.max(),test_split_index.min())
x_valid = spy.loc[(spy['Date'] < test_split_date) & (spy['Date'] > train_split_date)]['Close']#printed index values are:
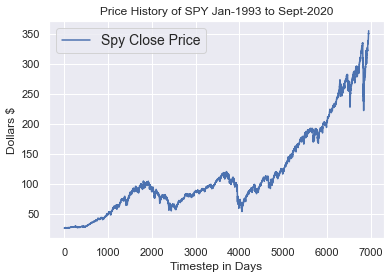
#0-5521(train), 5522-6527(valid), 6528-6947(test)I chose these dates pretty arbitrarily. Feel free to change them to whatever you want. Let’s plot a visual of how our data is split now. The plot below shows how the data segments by differentiating the color. It is important to remember we pulled the daily data, so each time step is equivalent to 1 day. The data in the plot spans from January 1993 until September 1, 2020.
我非常随意地选择了这些日期。 随时将它们更改为您想要的任何内容。 让我们来绘制一下现在如何拆分数据的视图。 下图显示了如何通过区分颜色来细分数据。 重要的是要记住我们提取了每日数据,因此每个时间步等于1天。 该图中的数据跨度为1993年1月至2020年9月1日。

步骤3:测试以查看数据是否稳定 (Step 3: Test to see if the data is stationary)
I can save you this step and tell you that if you are looking at a stock price that it is most likely not going to be stationary. That is because, generally speaking, a stock’s price will increase over time. If you have data that is not stationary, the mean of the data grows over time, which leads to a degradation of your model.
我可以为您省下这一步,并告诉您,如果您查看的是股票价格,则很有可能不会停滞不前 。 这是因为,一般而言,股票的价格会随着时间的推移而上涨。 如果您的数据不稳定,则数据的平均值会随着时间增长,这会导致模型性能下降。
Instead, you should predict the day-to-day return, or difference, in a stock’s closing price rather than the actual price itself. To test if the data is stationary, we use the Augmented Dickey-Fuller Test. Here is a snippet of code that will help speed this process up.
相反, 您应该预测股票的收盘价而不是实际价格本身的每日收益或差额。 要测试数据是否稳定,我们使用增强Dickey-Fuller测试。 这是一段代码,将有助于加快此过程。
from statsmodels.tsa.stattools import adfullerdef test_stationarity(timeseries, window = 12, cutoff = 0.01):#Determing rolling statisticsrolmean = timeseries.rolling(window).mean()rolstd = timeseries.rolling(window).std()#Plot rolling statistics:fig = plt.figure(figsize=(12, 8))orig = plt.plot(timeseries, color='blue',label='Original')mean = plt.plot(rolmean, color='red', label='Rolling Mean')std = plt.plot(rolstd, color='black', label = 'Rolling Std')plt.legend(loc='best')plt.title('Rolling Mean & Standard Deviation')plt.show()#Perform Dickey-Fuller test:print('Results of Dickey-Fuller Test:')dftest = adfuller(timeseries, autolag='AIC', maxlag = 20 )dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])for key,value in dftest[4].items():dfoutput['Critical Value (%s)'%key] = valuepvalue = dftest[1]if pvalue < cutoff:print('p-value = %.4f. The series is likely stationary.' % pvalue)else:print('p-value = %.4f. The series is likely non-stationary.' % pvalue)print(dfoutput)Now that you have the function let’s put it to use.
现在您有了函数,让我们使用它。
test_stationarity(series)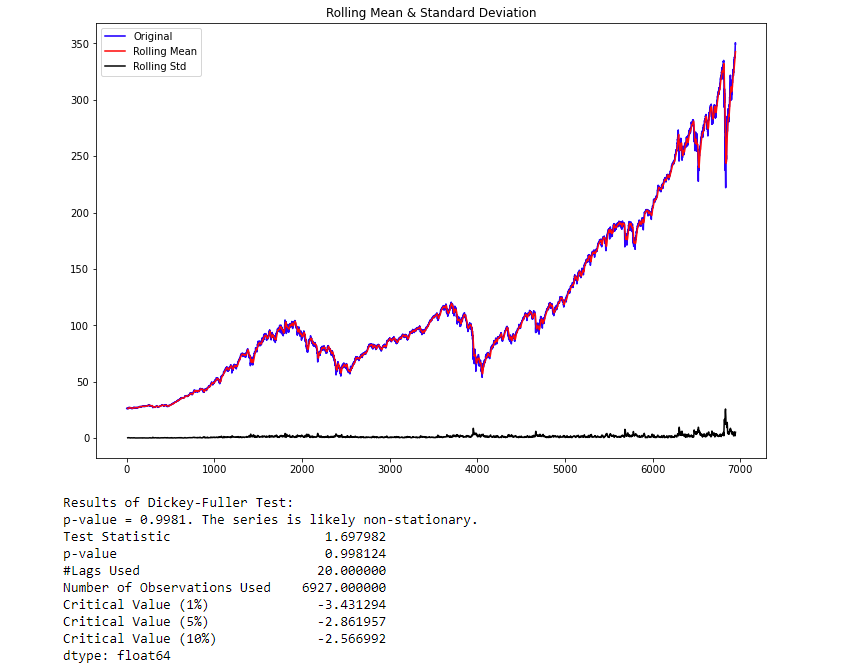
The p-value obtained is greater than the significance level of 0.05, and the ADF test statistic is greater than any of the critical values. There is no reason to reject the null hypothesis. So, the time series is non-stationary
获得的p值大于0.05的显着性水平,并且ADF测试统计量大于任何临界值。 没有理由拒绝零假设。 因此,时间序列是非平稳的
As you can see, this function gives you all the information necessary in case you forget. As we thought, the data is not stationary. To make the data stationary, we need to take the first-order difference of the data. Which is just a fancy way of saying subtract today’s close price from yesterday’s close price. As expected, Pandas has a handy function to do this for us.
如您所见,此功能可为您提供所有必要的信息,以防万一您忘记了。 正如我们认为的那样,数据不是固定的。 为了使数据稳定, 我们需要对数据进行一阶差分。 这只是从昨天的收盘价中减去今天的收盘价的一种奇特的说法。 不出所料,熊猫为我们做到了这一点。
# Get the difference of each Adj Close point
spy_close_diff_1 = series.diff()# Drop the first row as it will have a null value in this column
spy_close_diff_1.dropna(inplace=True)Now that we have attempted to make our data set stationary, let’s test it to be sure. Re-run test_stationarity(spy_close_diff_1).
现在,我们已经尝试使数据集保持平稳,让我们对其进行测试以确保确定。 重新运行test_stationarity(spy_close_diff_1)。
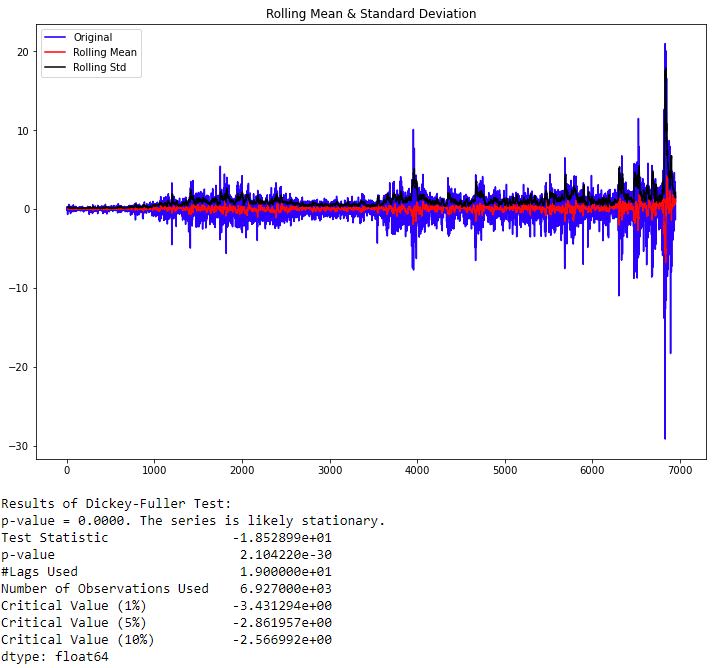
The p-value obtained is less than the significance level of 0.05, and the ADF statistic is lower than any of the critical values. We reject the null hypothesis. So, the time series is, in fact, stationary. Finally, our data is stationary, and we can continue. In some instances, you may have to do this more than once.
获得的p值小于0.05的显着性水平,并且ADF统计量低于任何临界值。 我们拒绝原假设。 因此,时间序列实际上是固定的。 最后,我们的数据是固定的,我们可以继续。 在某些情况下,您可能必须多次执行此操作。
步骤3:自相关和部分自相关 (Step 3: Autocorrelation and Partial Autocorrelation)
Autocorrelation is the correlation between points at time t (Pₜ) and the point at(Pₜ₋₁). Partial autocorrelation is the point at time t (Pₜ) and the point (Pₜ₋ₖ) where k is any number of lags. Partial autocorrelation ignores all of the data in between both points.
自相关是在时间t(Pₜ)处的点与(p between)处的点之间的相关性。 局部自相关是时间t处的点(Pₜ)和点(P number),其中k是任意数量的滞后。 局部自相关会忽略两点之间的所有数据。
In terms of a movie theater’s ticket sales, autocorrelation determines the relationship of today’s ticket sales and yesterday’s ticket sales. In comparison, partial autocorrelation defines the relationship of this Friday’s ticket sales and last Friday’s ticket sales.
就电影院的票务而言,自相关决定了今天的票务与昨天的票务之间的关系。 相比之下,部分自相关定义了此星期五的票务销售与上周五的票务销售之间的关系。
Here is a quick way to plot Autocorrelation and Partial Autocorrelation:
这是绘制自相关和部分自相关的快速方法:
from statsmodels.graphics.tsaplots import plot_acf,plot_pacfplot_acf(spy_close_diff_1)
plt.xlabel('Lags (Days)')
plt.show()# Break these into two separate cells
plot_pacf(spy_close_diff_1)
plt.xlabel('Lags (Days)')
plt.show()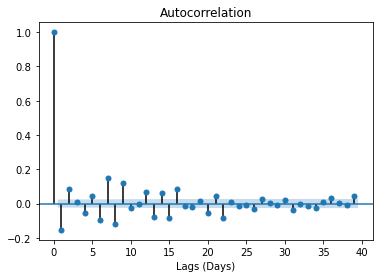

These plots look almost identical, but they’re not. Let’s start with the Autocorrelation plot. The important detail of these plots is the first lag. If the first lag is positive, we use an autoregressive (AR) model, and if the first lag is negative, we use a moving average (MA) plot. Since the first lag is negative, and the 2nd lag is positive, we will use the 1st lag as a moving average point.
这些图看起来几乎相同,但事实并非如此。 让我们从自相关图开始。 这些图的重要细节是第一个滞后。 如果第一个滞后为正,则使用自回归(AR)模型;如果第一个滞后为负,则使用移动平均(MA)图。 由于第一个延迟为负,第二个延迟为正,因此我们将第一个延迟用作移动平均点。
For the PACF plot, since there is a substantial dropoff at lag one, which is negatively correlated, we will use an AR factor of 1 as well. If you have trouble determining how what lags are the best to use, feel free to experiment, and watch the AIC. The lower the AIC, the better.
对于PACF图,由于滞后1处有一个很大的下降,它是负相关的,因此我们也将AR因子设为1。 如果您无法确定最佳使用滞后的方法,请随时尝试并观看AIC。 AIC越低越好。
The ARIMA model takes three main inputs into the “order” argument. Those arguments are ‘p’ for the AR term, ‘d’ for the differencing term, ‘q’ for the MA term. We have determined the best model for our data is of order (1,1,1). Once again, feel free to change these numbers and print out the summary of the models to see which variation has the lowest AIC. The training time is relatively quick.
ARIMA模型将三个主要输入纳入“ order”参数。 这些参数对于AR项是“ p”,对于差分项是“ d”,对于MA项是“ q”。 我们确定最佳数据模型为(1,1,1)。 再一次,可以随意更改这些数字并打印出模型摘要,以查看哪个版本的AIC最低。 训练时间相对较快。
# Use this block to
from statsmodels.tsa.arima_model import ARIMA# fit model
spy_arima = ARIMA(x_train, order=(1,1,1))
spy_arima_fit = spy_arima.fit(disp=0)
print(spy_arima_fit.summary())步骤4:预测 (Step 4: Forecasting)
Now that you have figured out which model has the best AIC score, I am using order = (1,1,1). Let’s use this model to make predictions on our test data set.. Now, I am sure there has to be a faster way of getting this done, but this is my approach. The run time on this cell may take some time. The run time is long because it moves across one data point at a time, refitting the model and creating a prediction for the next day. The last line of code is critical, as it is a magic command for Jupyter Notebook and will store the model predictions even if you restart your notebook’s kernel. This line will prevent you from having to rerun this cell in the future.
现在您已经确定了哪个模型的AIC得分最高,我在使用order =(1,1,1)。 让我们使用此模型对测试数据集进行预测。现在,我确信必须有一种更快的方法来完成此操作,但这是我的方法。 在此单元格上的运行时间可能需要一些时间。 运行时间很长,因为它一次跨一个数据点移动,因此需要重新拟合模型并为第二天创建预测。 最后一行代码很关键,因为它是Jupyter Notebook的神奇命令,即使重新启动Notebook的内核,它也会存储模型预测。 此行将防止您将来不得不重新运行此单元格。
# Create list of x train valuess
history = [x for x in x_train]# establish list for predictions
model_predictions = []# Count number of test data points
N_test_observations = len(x_test)# loop through every data point
for time_point in list(x_test.index):
model = ARIMA(history, order=(1,1,1))
model_fit = model.fit(disp=0)
output = model_fit.forecast()
yhat = output[0]
model_predictions.append(yhat)
true_test_value = x_test[time_point]
history.append(true_test_value)
MAE_error = keras.metrics.mean_absolute_error(x_test, model_predictions).numpy()
print('Testing Mean Squared Error is {}'.format(MAE_error))%store model_predictionsBelow is the code on how to reload the stored variable from the Jupyter magic command. It is also best practice to save and reload your model too.
以下是有关如何从Jupyter magic命令重新加载存储的变量的代码。 最好也保存和重新加载模型。
# %store model_predictions
%store -r model_predictions# Check to see if it reloaded
model_predictions[:5]# Load model
from statsmodels.tsa.arima.model import ARIMAResults
loaded = ARIMAResults.load('arima_111.pkl')步骤5:可视化模型 (Step 5: Visualize your model)
It is always important to view your model’s outputs to understand how it handled specific situations in your data. You may find some peculiar behavior that could lead to further model improvements.
查看模型的输出以了解其如何处理数据中的特定情况始终很重要。 您可能会发现一些特殊行为,这些行为可能导致进一步的模型改进。
from sklearn.metrics import mean_absolute_value
arima_mae = mean_absolute_error(x_test,model_predictions)
arima_maeFor this model, I used the mean absolute error as the loss function. I like this loss function for financial models because it is in units that are easy to imagine. The loss of the ARIMA(1,1,1) model was 2.788. This loss means the average difference between the actual value and the model’s predicted value was off by $2.79. Looking at the volatility over this period, I’d say $2.97 isn’t too bad with the crazy amount of volatility we have had over our testing period. Let’s plot the graph and see what it looks like upon further inspection.
对于此模型,我使用平均绝对误差作为损失函数。 我喜欢金融模型的损失函数,因为它的单位很容易想象。 ARIMA(1,1,1)模型的损失为2.788。 这种损失意味着实际价值与模型预测价值之间的平均差额为$ 2.79。 观察这段时期的波动性,我想说2.97美元对我们在测试期间所经历的疯狂波动性来说还算不错。 让我们绘制图表,并查看进一步检查的外观。
plt.rcParams['figure.figsize'] = [10, 10]plt.plot(x_test.index[-100:], model_predictions[-100:], color='blue',label='Predicted Price')
plt.plot(x_test.index[-100:], x_test[-100:], color='red', label='Actual Price')
plt.title('SPY Prices Prediction')
plt.xlabel('Date')
plt.ylabel('Prices')
# plt.xticks(np.arange(881,1259,50), df.Date[881:1259:50])
plt.legend()
plt.figure(figsize=(10,6))
plt.show()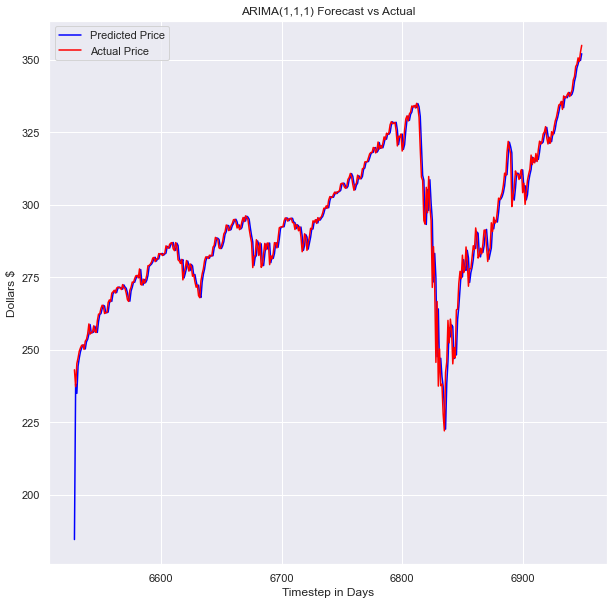
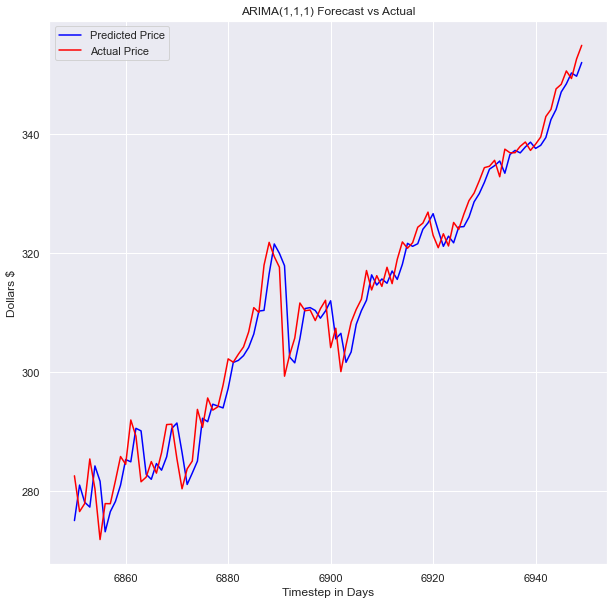
The model looks pretty good! Looking at the full test data set, you can’t see any space between our prediction and the actual values. This model performs well even when put up against more complex deep learning models. This model outperformed many of the deep learning models I built and trained on the same data sets.
模型看起来不错! 查看完整的测试数据集,您看不到我们的预测和实际值之间的任何空格。 即使遇到更复杂的深度学习模型,该模型也能很好地执行。 该模型优于我在同一数据集上构建和训练的许多深度学习模型。
结论 (Conclusion)
Thank you for making it this far and reading my blog! I hope you enjoyed it and learned something from it. There is still a lot of work to be done to put this model before implementing this model into a trading system.
感谢您到目前为止所做的并阅读我的博客! 希望您喜欢它并从中学到一些东西。 在将此模型实现到交易系统之前,仍有很多工作要做。
Typical trading systems are a conglomeration of multiple models and data sources that output trading signals. It is crucial to understand how you want to use your model to generate trading signals, and then thoroughly backtest your model accounting for all trading costs. Only then should you try to implement your system on a paper trading account and see how it does.
典型的交易系统是输出交易信号的多种模型和数据源的集合。 了解您要如何使用模型来生成交易信号,然后对所有交易成本进行全面回溯测试,这一点至关重要。 只有这样,您才应该尝试在纸币交易帐户上实施您的系统并查看其工作方式。
I have not yet gotten to those next stages, but when I do, I will be sure to share my findings!
我还没有进入下一个阶段,但是当我这样做时,我一定会分享我的发现!
LinkedIn:
领英
www.linkedin.com/in/blakesamaha
www.linkedin.com/in/blakesamaha
Personal Website:
个人网站:
Twitter:
推特:
翻译自: https://levelup.gitconnected.com/build-an-arima-model-to-predict-a-stocks-price-c9e1e49367d3
预测股票价格 模型















 7993
7993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









