





The news media is supposed to be a mirror of our society. It’s how many of us become informed about the events that shape our society and affect our lives. Unfortunately, we live in a world of inequality, with white, heterosexual men disproportionately occupying positions of power across many areas of our industry, politics and culture. For example, only 23% of the U.S. Congress are female, with numbers being only marginally better in the UK and Australia. When the news media holds up its mirror, the stories told and the people given a voice, come predominantly from a privileged minority.
新闻媒体应该是我们社会的一面镜子。 我们当中有多少人了解了塑造我们的社会并影响我们生活的事件。 不幸的是,我们生活在一个不平等的世界中,白人,异性恋男人在我们行业,政治和文化的许多领域占据着过多的权力位置。 例如, 美国国会中只有23%是女性,而在英国和澳大利亚 ,这一数字仅略有提高。 当新闻媒体举起镜子时,讲的故事和人们发出的声音主要来自特权少数群体。
While we’ve undoubtedly made a great deal of progress in the last hundred years, there’s still a long road ahead to close the gap. The question I want to help answer is whether or not the news media is helping or hindering this process with its representation of people and stories from across society.
在过去的一百年里,我们无疑取得了长足的进步,但要缩小差距,还有很长的路要走。 我想帮助回答的问题是,新闻媒体是否代表整个社会的人物和故事来帮助或阻碍这一进程。
该项目 (The Project)
To create a dataset of faces featured in images on popular news websites.
在流行新闻网站上的图像中创建面部数据集。
By periodically scraping image data from a selection of popular news websites, using computer vision to detect faces and predict their gender and age, we will create a dataset providing a record as to where, when and what type of faces are presented.
通过定期从精选的新闻网站中抓取图像数据,使用计算机视觉检测面Kong并预测面Kong的性别和年龄,我们将创建一个数据集,以提供有关何时何地呈现什么类型面Kong的记录。
分析潜力 (Potential lines of analysis)
Using this data, we can ask some of the following questions:
使用此数据,我们可以提出以下一些问题:
- Is there an equal balance between male and female faces in images on news websites? 新闻网站上图片中的男性面Kong和女性面Kong之间是否存在平等的平衡?
- Which websites are the most equal/unequal with their presentation of different gendered faces? 哪些网站展示不同性别的面Kong最平等/最不平等?
- Are male faces often featured more prominently (size or closeness to the top of the image) than female faces? 男性面Kong的特征通常比女性面Kong更突出(大小或靠近图像顶部)吗?
- Do images featuring male faces stay on the site longer than those featuring female faces? 具有男性面Kong的图像在网站上的停留时间是否比具有女性面Kong的图像停留的时间更长?
Are female faces largely confined to specific sections of the front page (e.g. the Daily Mail’s celebrity sidebar)?
女性的面Kong是否主要局限于首页的特定部分(例如,《 每日邮报》的名人侧栏)?
- Are the men pictured on news media of a different age distribution than women? 在新闻媒体上描绘的男性与女性的年龄分布是否不同?
- Are news stories biased towards certain age groups? 新闻故事是否偏向特定年龄段?
方法 (Method)
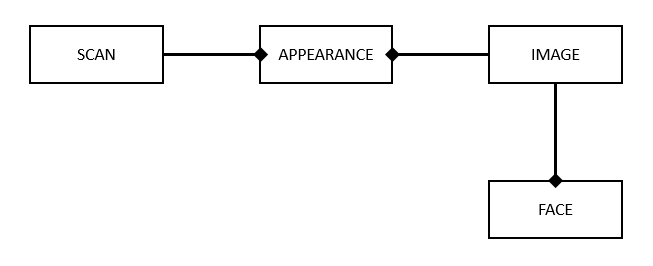
The data is collected via a Python script, which runs periodically (once an hour via cron). It polls each website using Selenium, records any new images from each page and then uses Azure’s Face API to extract face data for each image. Four tables are built up over time:
数据是通过Python脚本收集的,该脚本会定期运行(通过cron每小时运行一次)。 它使用Selenium轮询每个网站,记录每个页面中的任何新图像,然后使用Azure的Face API提取每个图像的面部数据。 随着时间的推移,将建立四个表:
- Scans: Each row represents a scan of a particular website, recording its url and a timestamp of that scan. 扫描:每行代表对特定网站的扫描,记录其网址和该扫描的时间戳。
- Images: Each row represents a unique (by url) image. An image can appear in many scans and a scan can yield many images, necessitating the following table: 图片:每行代表一个唯一的(按url)图片。 一张图像可以出现在许多扫描中,一次扫描可以产生许多图像,因此需要下表:
- Appearances: Each row represents the occurrence of a particular image within a particular scan. 外观:每行代表特定扫描中特定图像的出现。
- Faces: Each row represents a face, identified within an image. 面Kong:每行代表一张在图片中标识的面Kong。
Selenium (Selenium)
Because some content on popular news sites is loaded dynamically, using a simple http request would risk missing some images.
由于热门新闻网站上的某些内容是动态加载的,因此使用简单的http请求可能会丢失某些图像。
Selenium is a framework for the automated testing of web applications, and serves our purposes quite nicely. Because the page is automatically rendered, we have the added benefit of being able to detect the pixel location that each image is displayed.
Selenium是用于Web应用程序自动化测试的框架,可以很好地满足我们的目的。 因为页面是自动呈现的,所以我们还有一个额外的好处,就是能够检测显示每个图像的像素位置。
Azure API (Azure API)
Within Azure’s Cognitive Services suite, sits the Face API. Pass in an image URL and it returns a list of faces present in the image. Each face comes complete with a set of attributes including age, gender, head position and orientation, emotion, hair colour and whether or not the person is wearing glasses.
Face API位于Azure的Cognitive Services套件中。 传递图片网址,它将返回图片中存在的面Kong列表。 每张脸都有一组属性,包括年龄,性别,头部位置和方向,情感,头发颜色以及该人是否戴着眼镜。
By extracting this information for images found on popular news sites, we can build up a rich dataset describing how different demographics are represented.
通过为流行新闻网站上的图像提取此信息,我们可以建立一个丰富的数据集,描述不同人口统计的表示方式。
The API was easy to set up, and I was calling it in Python within a few minutes. Pricing includes a free tier, limited at 20 images per minute, or USD $1 per 1,000 if you creep above. There are alternatives such as Amazon Rekognition, which is near identical in features and in price.
该API易于设置,我在几分钟内就用Python调用了它。 定价包括免费套餐,每分钟限制为20张图片,如果您超出上述价格,则每1,000张图片需支付1美元。 有诸如Amazon Rekognition之类的替代产品,其功能和价格几乎相同。
网站 (The Websites)
The websites chosen for this analysis were selected from Alexa’s top 50 news sites. I excluded any messageboards or aggregation sites, and also added a handful of UK and Australian news providers so as not to be too U.S. focused.
选择进行此分析的网站选自Alexa的前50个新闻网站 。 我排除了任何留言板或汇聚网站,还添加了一些英国和澳大利亚的新闻提供者,以免过于关注美国。
代码 (The Code)
The full code is located at https://github.com/richfarnworth/news_face_data. The environment.yml file is provided to setup your environment via Conda and the main script to run is scrape_news.py.
完整代码位于https://github.com/richfarnworth/news_face_data 。 提供了environment.yml文件以通过Conda设置环境,要运行的主要脚本为scrape_news.py。
数据 (The Data)
The process was kicked off on the 4th September 2020. As such we are collecting data as we speak and hope to do some preliminary analysis by early October. The dataset itself will be uploaded to Kaggle at regular intervals to allow others to do their own analysis.
该过程于2020年9月4日开始。因此,我们正在收集我们所讲的数据,并希望在10月初进行一些初步分析。 数据集本身将定期上载到Kaggle,以允许其他人自己进行分析。
局限性 (Limitations)
As with any approach, it’s important to understand the shortfalls of our method.
与任何方法一样,了解我们方法的不足很重要。
- We’re assuming a binary view of gender. Gender is a hugely complex subject and there are many different ways which people can identify. Constrained by the tools available, however, we’re forced to assume a simplistic binary categorisation. 我们假设性别的二元观点。 性别是一个非常复杂的主题,人们可以通过许多不同的方式进行识别。 但是,受可用工具的限制,我们不得不假定其简单的二进制分类。
- Age and Gender are the only demographic dimensions we are able to analyse, as (probably wisely), Microsoft doesn’t attempt to identify race with their Face API service. 年龄和性别是我们能够分析的唯一人口统计维度,因为(可能明智地),Microsoft不会尝试通过其Face API服务来识别种族。
- We’re completely at the mercy of the (unpublished) accuracy of the Azure Face API. If for example, it’s worse at detecting male faces, or can detect female age less accurately, then this would introduce a skew to any further analysis. I did do a few experiments with pictures of celebrities for which I could look up the age and it seemed to guess within a couple of years of the correct answer most of the time. But this was far from rigorous and given more time it would be useful to properly analyse the service’s performance. 我们完全依靠Azure Face API(未发布)的准确性。 例如,如果在检测男性面部时较差,或者在检测女性年龄时较不准确,则这将在任何进一步的分析中引入偏差。 我确实做了一些名人照片的实验,可以查询他们的年龄,而且大多数时候似乎都在正确答案的几年之内。 但这远非严格,给了更多时间,适当地分析服务的性能将很有用。
- The data will be highly dependent on the main stories going on right now. I started the scraping process on the 31st August, meaning that many news sites will be prominently featuring the US Election and the Coronavirus Pandemic. Given both candidates are male and in their 70s, and the chief medical officers of the US, UK and Australia are all in a similar demographic, this will likely skew any analysis. To mitigate this, we’d want to collect data over a longer period of time. 数据将高度依赖当前发生的主要事件。 我于8月31日开始抓取过程,这意味着许多新闻网站将以美国大选和冠状病毒大流行为主要特色。 考虑到两位候选人都是男性,都在70多岁,而且美国,英国和澳大利亚的首席医疗官都处于相似的人口统计特征,这很可能会歪曲任何分析结果。 为了减轻这种情况,我们希望在更长的时间内收集数据。
- I use the default Selenium browser window settings using Chrome as the webdriver. While some dynamically loaded content will be extracted, features such as infinite scroll will not be activated. 我使用默认的Selenium浏览器窗口设置,将Chrome用作网络驱动程序。 在提取一些动态加载的内容时,诸如无限滚动之类的功能将不会被激活。
- In using the images from the home page of each news site, the image files are often thumbnails with lower resolution than the feature image on the actual article. This can lower the identification rate of the Azure Face API. “Clicking” through the link to the original article and extracting the feature image from there might help, although some news sites have different images for home page links and feature images. 在使用每个新闻站点主页上的图像时,图像文件通常是缩略图,其分辨率比实际文章上的特征图像低。 这会降低Azure Face API的识别率。 通过“单击”原始文章的链接并从中提取特征图像可能会有所帮助,尽管某些新闻站点的首页链接和特征图像具有不同的图像。
- All content will be assumed to be static, with no personalisation based on location, cookies, browser etc. 假定所有内容都是静态的,不会根据位置,Cookie,浏览器等进行个性化设置。
潜在扩张 (Potential expansion)
While this initial scraping is just focused on the front pages of each site, it would be interesting to expand this to top level subsections. For example, do the gender and age biases change between political, business and sports reporting?
虽然最初的抓取只是针对每个站点的首页,但将其扩展到顶级子部分将是很有趣的。 例如,政治,商业和体育报道之间的性别和年龄偏见是否有所变化?
关注此空间 (Watch this space)
Updates, datasets and analysis to come.
即将进行更新,数据集和分析。
翻译自: https://towardsdatascience.com/creating-a-gender-equality-in-the-news-dataset-69bf618479e2














 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









