





mips汇编代码示例解释
Since I’m going to be giving a spiel (or two) about Data and AI at Microsoft Ignite later on this year, I decided it’s about time I stopped ignoring the Data guys and what better way to get to know them than to take them on a virtual date (I’m still in full lockdown and can’t see anyone anyway) so I decided to go on a virtual date with Cosmos (his full name is Azure CosmosDB but he likes to go by the nickname, Cosmos).
由于我将在今年晚些时候在Microsoft Ignite上发表有关数据和AI的一两次(或两篇)文章,因此我决定现在该是我停止无视数据专家的时候了,并且是一种比让他们了解知识更好的方法在虚拟日期上(我仍然处于完全锁定状态,无论如何都看不到任何人),所以我决定与Cosmos进行虚拟日期(他的全名是Azure CosmosDB,但他喜欢使用昵称Cosmos )。
Anyway, here is a summary how the virtual date went…
无论如何,这是虚拟日期过后的摘要...
Hey Cosmos, thanks for doing this virtual date with me, so what do you do for a living?
嗨,Cosmos,感谢您和我一起参加这个虚拟约会,所以您以谋生为生吗?
No worries, I’m glad you picked me. Some people are a little afraid of me because they think I’m trying to replace that SQL guy who used to be super popular but I’m actually a pretty cool guy once you get to know me. And, not to boost my own ego here but people kind of fall in love with me once they realize I’m not that mysterious. Anyway, I work in this field called “Databases” and I store things for a living.
不用担心,很高兴您选择了我。 有些人有点害怕我,因为他们认为我正试图取代曾经超级受欢迎SQL家伙,但是一旦您认识我,我实际上就是一个很酷的家伙。 而且,不是在这里提升我的自我,而是人们一旦意识到我并不那么神秘就爱上了我。 无论如何,我在这个叫做“数据库”的领域工作,我以储存东西为生。
Oh cool, what kind of things do you store? I might be moving houses soon. Do you do furniture storage?
哦,太酷了,您要存储什么样的东西? 我可能很快就要搬家了。 你会做家具存放吗?
Nah, not furniture storage. I store data which is why I’m in the Databases field but I don’t have strict requirements like that SQL guy. I’m a bit more chill and laid back than he is. SQL likes to plan ahead of time, he tells people that they need to call him up before hand, come up with a plan (which he calls a schema) that specifies exactly what data needs to be stored, how to arrange the data, all that kind of stuff before he lets anyone use his storage services. And if people don’t stick to his rigid schema plans, he throws a tantrum. Then everyone ends up having a big fat cry especially those Database Administrator guys who has to deal with him.
不,不是家具存放处。 我存储数据,这就是为什么我在“数据库”字段中,但是我没有像SQL那样严格的要求。 我比他还冷和悠闲。 SQL喜欢提前计划,他告诉人们他们需要事先打电话给他,提出一个计划(他称为模式),该计划确切指定需要存储哪些数据,如何安排数据,所有这种东西,然后再让任何人使用他的存储服务。 而且如果人们不坚持他的严格计划,他就会发脾气。 然后每个人都会大哭一场,尤其是那些必须与他打交道的数据库管理员 。
Honestly, he’s a bit of a neat freak in my opinion. Too structured and relational for my liking. I’m more of a semi-structured, non-relational type of guy. I don’t like making plans but I do have a few basic rules so I just tell people, “Hey, if you can stick to these rules then you’re welcome use my services at anytime. I don’t really care what it is you’re storing as long as you follow my rules.”
老实说,在我看来,他有点整洁。 我太喜欢结构化和关系性。 我更像是半结构化,非关系型的人。 我不喜欢制定计划,但是我有一些基本规则,所以我只是告诉人们:“嘿,如果您可以遵守这些规则,那么随时欢迎您使用我的服务。 只要您遵守我的规定,我就不会在乎您存储的内容。”
Right, and what are these rules they have to follow?
是的,它们必须遵循哪些规则?
Two simple rules really, they just need to tell me the Partition Key and the Throughput.
实际上,有两个简单的规则,它们只需要告诉我分区密钥和吞吐量即可 。
The Partition Key gives me an idea of how they want to separate their data (logically) and then I do some magic math in my head to work out how to physically store their logical partitions into my physical storage space.
分区键让我了解了他们如何(逻辑上)分离数据,然后我脑海中进行了一些魔术运算,以确定如何将其逻辑分区物理存储到我的物理存储空间中。
And Throughput is really about how much work I have to do for them like will I have to move their data around a lot, find things for them, get and replace things for them, or remove things? All that labour work will cost them so they need to give me an idea of how much work they are expecting me to do for them. I call this Request Units (RUs) so I tend to ask people how many RUs they need from me. You can think of an RU as a unit of work or effort.
吞吐量实际上是关于我必须为他们做多少工作,例如我是否需要大量移动数据,为他们找到东西,为他们获取和替换东西,或删除东西? 所有的劳动都会使他们付出代价,因此他们需要让我知道他们期望我为他们做多少工作。 我称此为请求单位 (RU),所以我倾向于向人们询问我需要多少个RU。 您可以将RU视为工作或努力的单位。
Ok, but how would I decide what Partition Key or Throughput to give you?
好的,但是我将如何决定要给您的分区密钥或吞吐量?
So when it comes to data, you’re generally doing either one of these two things: Read or Write.
因此,在数据方面,您通常会做以下两件事之一: Read或Write 。
Read is essentially getting data or filtering data or aggregating data, doing some sort of manipulation with the data and then returning the results. Write is generally inserting new data or modifying existing data or removing data. So when people ask me what to choose for their Partition Key, I tell them to look at what kind of queries they will be getting. Will it be read-heavy or write-heavy? You know, what are the most frequent queries they will be getting. Like if it is going to be read-heavy, then we probably want to have lots of replicas (basically copies of the same data) to avoid “hot” partitions and make sure that reads are highly available. If it is going to be write-heavy, then we probably want to make sure we can keep the replicas as consistent as possible in the shortest amount of time and try to avoid or mitigate any write conflicts that might occur.
读取本质上是获取数据或过滤数据或聚合数据,对数据进行某种处理,然后返回结果。 写操作通常是插入新数据或修改现有数据或删除数据。 因此,当人们问我要为分区密钥选择什么时,我告诉他们看看他们将得到什么样的查询。 是重读还是重写? 您知道,他们将得到的最常见的查询是什么。 就像要读取大量数据一样,我们可能希望拥有很多副本(基本上是同一数据的副本),以避免“热”分区并确保读取具有高可用性。 如果要进行大量写操作,那么我们可能要确保我们可以在最短的时间内使副本尽可能保持一致,并尝试避免或减轻可能发生的任何写冲突。
It also affects the Throughput or number of RUs they need from me as well. For example, if it is read-heavy, I could probably go find your data from any of the replicas but if it is write-heavy, I will need to go and make changes to all the replicas and you know, I’m definitely going to charge more RUs for doing more work.
它还影响我需要的吞吐量或RU数量。 例如,如果读量很大,我可能可以从任何副本中找到您的数据,但如果写量很大,则需要对所有副本进行更改,并且您知道,我绝对将为执行更多工作而向更多RU收费。
You mentioned some stuff I didn’t understand here like Hot Partitions, Replicas, Conflicts, High Availability, and Consistency. Can you explain what they are?
您提到了一些我在这里不了解的东西,例如热分区,副本,冲突,高可用性和一致性。 您能解释一下它们是什么吗?
Yeah, sure.
当然可以。
Let’s see, I’ll go through how I store data and why I do it that way. So when someone comes to me and says they need me to store their data, I tell them to create an account first because you know, I need to keep track of my customers so I don’t accidentally mistaken one person’s data for someone else’s data. Once they have set up their account, they can create a Database to start storing their data. Their data actually gets store inside Containers and these data could be Collections, Tables, or Graphs. I’ll just talk about Collections for now otherwise we could be here for a while.
让我们看看,我将详细介绍如何存储数据以及为什么要这样做。 因此,当有人来找我说他们需要我存储他们的数据时,我告诉他们首先创建一个帐户,因为您知道,我需要跟踪我的客户,这样我才不会将一个人的数据误认为另一个人的数据。 设置帐户后,他们可以创建数据库来开始存储数据。 他们的数据实际上存储在Containers中,这些数据可以是Collections ,Tables或Graphs。 我现在只谈论集合,否则我们可能会在这里待一会儿。
Collections is just documents of data stored in JSON format and JSON stands for JavaScript Object Notation and, do you have a pen and paper?
集合只是以JSON格式存储的数据文档,而JSON代表JavaScript Object Notation,并且您有纸和笔吗?
No, sorry.
不,对不起
That’s ok. I have a pen and this napkin here will work just fine. So JSON is just a way of storing and exchanging data and it looks kind of like this:
没关系。 我有一支笔,这里的餐巾纸可以正常工作。 因此,JSON只是一种存储和交换数据的方式,它看起来像这样:
{ "name": "Cosmos",
"bio": {
"dateOfBirth": "May 2017",
"friends": ["MongoDb", "Gremlin", "Cassandra", "Azure
Table Storage", "Core SQL"]
}
}You see, if I wanted to find out my own bio, I just need to ask for “bio” and then inside the value for “bio”, I can find my “dateOfBirth” or my “friends”.
您会看到,如果我想找出自己的个人简介,我只需要询问“个人简介”,然后在“个人简介”的值内找到我的“ dateOfBirth”或“朋友”。
Anyway, when someone comes up to me with a bunch of JSON documents to put into the container, I automatically create an index which just helps me keep track of the documents I have stored so if they want me to look up some stuff inside their documents, I can do it easily by going through my index:
无论如何,当有人向我提出将一堆JSON文档放入容器时,我会自动创建一个索引 , 该索引仅有助于我跟踪存储的文档,因此如果他们希望我在其文档中查找一些内容,我可以通过浏览索引轻松地做到这一点:
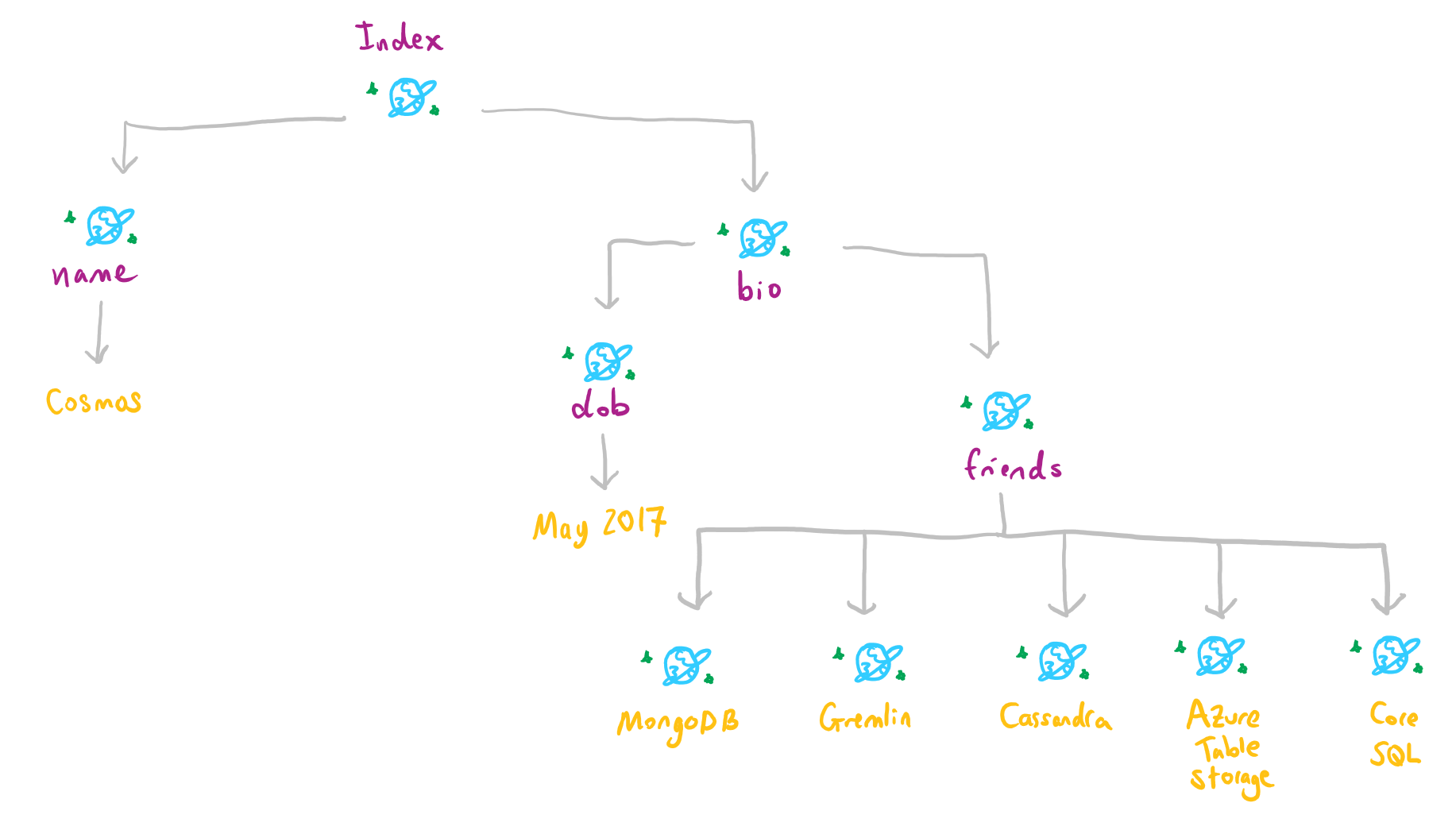
Sometimes people don’t want me to keep track of everything in their documents so they can specify an Index Policy which basically tells me not to index certain stuff for them.
有时人们不希望我跟踪他们文档中的所有内容,因此他们可以指定一个索引策略 ,该策略基本上告诉我不要为他们为某些内容编制索引。
So, what other Azure services have you also got lined up for a virtual date?
那么,您还为虚拟约会准备了哪些其他Azure服务?
Well, I was thinking of Azure HDInsight, Azure Databricks, and um, maybe Azure Synapse Analytics?
好吧,我在考虑Azure HDInsight,Azure Databricks和um,也许是Azure Synapse Analytics?
Ok, let’s say you are using my Document or Collection store to keep track of your virtual date’s profiles. You will probably create a document for each one of them and inside that document will be contain all their details:
好的,假设您使用我的“文档”或“收藏集”存储来跟踪虚拟日期的配置文件。 您可能会为每个文档创建一个文档,并且该文档中将包含其所有详细信息:
Document 1: {
"name" : "HDInsight",
"type" : "data analytics",
"cloud" : "Azure",
"Apache" : ["Hadoop", "Spark", "HBase", "Storm", "Kafka",
"Hive"]
} Document 2: {
"name" : "Databricks",
"cloud" : "Azure",
"Apache" : "Spark"
} Document 3: {
"name" : "Synapse Analytics",
"cloud" : "Azure",
"type" : ["data warehouse", "data analytics"],
"SQLSupport" : true
}Just having a quick look at this and I can already tell you that a good Partition Key to use would be “name” because then I know that each document is its own logical partition as the value is distinct, unique and will probably have a good range (as far as I know, all Azure services have different names). If we choose “cloud” as the Partition Key then I would treat all 3 documents as a single logical partition because they all have the same value. Do you know why choosing a good Partition Key is important?
快速浏览一下,我已经可以告诉您,要使用的分区键是“名称”,因为那之后我知道每个文档都是自己的逻辑分区,因为值是独特的,唯一的,并且可能具有良好的范围(据我所知,所有Azure服务都有不同的名称)。 如果我们选择“ cloud”作为分区键,那么我会将所有3个文档都视为一个逻辑分区,因为它们都具有相同的值。 您知道为什么选择好的分区密钥很重要吗?
Is it so you can uniquely identify and find each document in the Collection?
这样您就可以唯一地标识并找到集合中的每个文档吗?
Nah, not quite. Remember what I told you earlier that the Partition Key helps me decide where to put stuff into my physical storage space? Yeah, so basically I take the Partition Key that you give me, put it through a hash function that does consistent hashing to get a random physical partition to put that logical partition into. So you can imagine, if these partition keys are not unique then I’m probably going to end up mapping all the logical partitions into the same physical partition.
不,不是。 还记得我之前告诉您的,分区键可以帮助我确定将内容放入物理存储空间的位置吗? 是的,所以基本上我会使用您提供给我的分区密钥,将其通过哈希函数进行哈希处理,该哈希函数会执行一致的哈希运算以获取将逻辑分区放入其中的随机物理分区。 可以想象,如果这些分区键不是唯一的,那么我可能最终将所有逻辑分区映射到同一物理分区。
Um, physical partition?
嗯,物理分区?
Oh, uh, you can think of a physical partition like a physical storage room. If I put all your stuff in the same room then when you want me to get a lot of things out, I’m going to have to keep visiting the same room but, if I have them distributed across multiple rooms, I can hire other people to go look for all your stuff at the same time (in parallel) and so you can imagine just how much more effective that is.
哦,嗯,您可以想到一个物理分区,例如物理存储室。 如果我把所有东西都放在同一个房间里,那么当你要我把很多东西都拿出来时,我将不得不继续拜访同一个房间,但是,如果我把它们分配到多个房间里,我可以租用其他东西。人们可以同时(并行)查找您所有的东西,因此您可以想象这会更有效。
In the Database world, when we talk about avoiding “hot” partitions, we essentially mean we want to avoid putting all your stuff in the same place because then for any requests that comes in, we have to send them all to one place and that’s just bad.
在数据库世界中,当我们谈论避免“热”分区时,本质上是指我们要避免将所有内容放在同一个位置,因为对于收到的任何请求,我们都必须将它们全部发送到一个位置,这就是不好
Ah ok, got it.
好的,知道了。
Yeah, so anyway, my storage services have this reputation of being “highly available”, “resilient”, “durable”, “consistent”, and “globally connected” that I kind of need to uphold otherwise I might lose my job and go out of business so I tell people that I can make guarantees that 99.999% of the time that I can always find and return the things they’re looking for or perform some action on their data.
是的,所以无论如何,我的存储服务享有“高可用性”,“弹性”,“耐用”,“一致”和“全球连接”的美誉,我需要坚持这一点,否则我可能会失业并失业。停业,因此我告诉人们,我可以保证在99.999%的时间内,我始终可以找到并返回他们要查找的内容或对其数据执行某些操作。
How are you so confident that you can make this guarantee?
您如何自信地可以做出此保证?
Well, ok I’ll let you in on a little secret. I have this Replica strategy which means when I store people’s data, I actually make 3 more copies of it so in total I have 4 replicas stored in the same physical partition and I call this the Replica Set.
好吧,好的,我给你一个秘密。 我有这个副本策略 ,这意味着当我存储人们的数据时,实际上我会再制作3个副本,因此总共我在同一物理分区中存储了4个副本,我称之为副本集。
How does having 4 replicas help you?
拥有4个副本对您有何帮助?
So these replicas are actually spread across multiple fault domains. A fault domain is essentially anything that has a single point of failure. Think of your PC, if you pulled out the power plug, your PC will shut down due to a loss of power. That’s single point of failure for your PC. So if I had these replicas all live on the same fault domain, they might all get wiped if I ever experience a failure no matter how many replicas I create so that’s why they’re spread across multiple fault domains. So now, even if a replica experiences some failure, I’ve still got other replicas or copies and I can act like nothing went wrong and continue to serve my customers but really what I’m doing in the background is trying to restore that replica loss using the other replicas. But my customers won’t see this impact so in front of my customers, I am always highly available, resilient to failures and durable.
因此,这些副本实际上分布在多个故障域中 。 故障域本质上是具有单点故障的任何事物。 想想您的PC,如果拔下电源插头,由于断电,您的PC将关闭。 那是您PC的单点故障。 因此,如果我所有这些副本都生活在同一个故障域中,那么无论我创建多少副本,如果我遇到故障,它们都可能会被擦除,这就是为什么它们分布在多个故障域中的原因。 所以现在,即使某个副本出现故障,我仍然会有其他副本或副本,并且我可以采取行动,就像没有发生任何错误并继续为我的客户提供服务,但实际上我在后台所做的就是尝试还原该副本使用其他副本丢失。 但是我的客户不会看到这种影响,因此在客户面前,我总是很忙碌,对故障有弹性且经久耐用。
Anyway, in terms of consistency and being a globally distributed data storage service, I have 5 consistency offerings that my customers can choose from.
无论如何,就一致性和作为全球分布的数据存储服务而言,我有5种一致性产品可供客户选择。
What do you mean by consistency offerings?
您所说的一致性产品是什么意思?
Basically I have consistency offerings that starts from Strong consistency to Bounded Staleness to Session to Consistent Prefix to Eventual consistency. I have to make these consistency offerings because of the replicas that I make for high availability, resiliency and globally distributing the data.
基本上,我提供一致性产品,从强一致性到有限的陈旧性到会话到一致性前缀到最终一致性。 我必须提供这些一致性产品,是因为我为实现高可用性,弹性和在全球范围内分发数据而制作了副本。
Why?
为什么?
Because there are trade-offs. Think about it. If I made all these replicas for high availability, it’s pretty hard to guarantee consistency without some form of latency. Let’s say someone came in and said, can you go and delete this thing inside this document for me. If I was only dealing with one copy, that’ll be easy and I won’t have to worry about consistency but the thing is I’ve made all these replicas so I need to go and delete the same thing from all the replicas otherwise someone might go look at one of the replicas and get inconsistent results. But then, if I have to go and make all my replicas consistent, that’s going to take time, right?
因为有权衡。 想一想。 如果我使所有这些副本都具有高可用性,那么很难保证没有某种形式的延迟的一致性。 假设有人进来说,您能帮我删除此文档中的内容吗? 如果我只处理一个副本,那将很容易,并且我不必担心一致性,但是问题是我已经制作了所有这些副本,因此我需要从所有副本中删除同一件事有人可能会去看其中一个副本并获得不一致的结果。 但是,如果我必须使所有副本保持一致,那将需要一些时间,对吗?
Uh huh.
嗯。
And so during this time, I can’t make any of the replicas available for use and so I’ve lost my high availability status. But then, if I want to keep my high availability status, I can’t guarantee 100% consistency at all times so typically with Databases, there is a trade-off between availability and consistency.
因此在这段时间内,我无法使用任何副本,因此我失去了高可用性状态。 但是,如果我想保持自己的高可用性状态,就不能始终保证100%的一致性,因此通常对于数据库,在可用性和一致性之间要进行权衡。
Ah, right, ok.
啊,对,好的。
Anyway, the consistency offerings is basically a continuum from strong consistency (at the cost of lower availability or high latency) to eventual consistency (for high availability but the replicas may return inconsistent results). To give you a bit more detail:
无论如何,一致性产品基本上是从强一致性(以降低可用性或高延迟为代价)到最终一致性(对于高可用性,但是副本可能返回不一致结果)的连续体。 为您提供更多细节:
- Strong consistency means any reads and writes will always be consistent, so whatever replica it is reading from or writing to, these changes will always be propagated such that there will never be any inconsistent results. 强大的一致性意味着任何读写操作都将始终保持一致,因此无论从其读取或写入的副本,这些更改都将始终传播,从而永远不会出现任何不一致的结果。
- With Bounded Staleness, they get to set a “window” of how many writes can lag from one replica to another or how long this lag from one replica to another can take. So the changes will still be written in the same order but there might just be some window of lag (or latency) from one to be completely updated and identical to another. 借助“有局限性的陈旧性”,他们可以设置一个“窗口”,以了解从一个副本到另一个副本可以滞后多少次写入,或者从一个副本到另一个副本可以滞后多长时间。 因此,更改仍将以相同的顺序进行写入,但是可能会有一些滞后(或延迟)窗口从一个窗口完全更新并与另一个窗口完全相同。
- With Session, basically those connected to the same session will be able to read the latest changes, those not connected to the same session will eventually see these changes but not immediately. 使用会话,基本上连接到同一会话的用户将能够读取最新的更改,未连接到同一会话的用户最终将看到这些更改,但不会立即看到。
- With Consistent Prefix, the ordering of writes is still kept (like in a log book) and then these changes are eventually made to the rest of the replicas so there is latency in getting the latest updates replicated across all the copies but you’ll never see any inconsistencies (out of order writes), you might just not be able to read the latest updates for a while. 使用一致前缀,仍然可以保持写入顺序(就像在日志中一样),然后最终对其余副本进行这些更改,因此在所有副本之间复制最新更新存在延迟,但是您永远不会看到任何不一致的地方(乱写),您可能只是暂时无法读取最新更新。
- Finally Eventual Consistency is well, how do I say this? It will become consistent, eventually. So all the replicas will eventually be the same but until then, they might differ from one another. What that means is that you might see inconsistencies when reading from the replicas because there is no guarantee on the ordering. But it’s highly available because you can always read from the replicas, they might just return inconsistent results (until it eventually becomes consistent). 最终最终一致性很好,我怎么说呢? 最终它将变得一致。 因此,所有副本最终都将是相同的,但是在那之前,它们可能会彼此不同。 这意味着您在读取副本时可能会看到不一致的地方,因为无法保证订购的顺序。 但这是高度可用的,因为您始终可以从副本中读取内容,它们可能只会返回不一致的结果(直到最终变得一致)。
So remember, as we move from Strong to Eventual, we are making that trade-off of consistency (and latency) for high availability.
因此请记住,当我们从“强”过渡到“最终”时,我们正在权衡一致性(和延迟)以实现高可用性。
Oh wow, that was…quite a lot to take in. I feel like I should’ve brought a notebook or something to this virtual date.
哦,哇,那真是太好了。我觉得我应该为这个虚拟约会带上笔记本或其他东西。
Yeah, well, I haven’t even talked about why I’m also known as Mr Worldwide (you know, as a globally distributed, multi-model database service and all) but if you’re up for a second virtual date, you can always find me here.
是的,嗯,我什至没有说过为什么我也被称为全球先生(您知道,作为全球分布的多模型数据库服务以及所有服务),但是如果您打算第二次虚拟约会,您可以我总能在这里找到我。
😊
😊
P.S: I know this is a slightly different approach to what I normally do but I felt like doing something different (mostly to entertain myself). Again, I would love to hear your feedback (good, bad or otherwise). Also, I should probably mention that any characters created in this are purely fictional. The technology however, is real.
PS:我知道这与平时的工作方式略有不同,但是我想做点不同的事情(主要是为了娱乐自己)。 再次,我很想听听您的反馈(好,坏或其他)。 另外,我可能应该提到,在此创建的任何字符都是虚构的。 但是,这项技术是真实的。
Originally published at https://www.linkedin.com.
最初发布在 https://www.linkedin.com 。
Author: Michelle Xie
作者:谢雪儿
翻译自: https://medium.com/swlh/explain-by-example-cosmosdb-151710a6a9cc
mips汇编代码示例解释















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









