





groupby.nth
Often there comes a need to compute operations on groups. But there are times when getting the first or the nth row from each group is the highest priority.
通常需要对组进行运算。 但是有时候从每个组中获得第一行或第n行是最高优先级。
Comic-con tickets🎫️ were going on sale on next Tuesday and the sale was divided into 3 sessions. First in the morning at 10 AM, second at 2 PM and the last one at 8 PM.
Comic-con门票🎫️将于下周二开始销售,此次销售分为3节。 首先是早上10点,第二点是下午2点,最后一个是晚上8点。
It was decided that the first user🥇 of each session will be given a free tour to any country that the user specifies during the ticket reservation.
决定第一个用户 🥇 每次会议的一次将免费参观用户在机票预订期间指定的任何国家。
After the end of the day following user data was collected:
在一天结束之后,收集了以下用户数据:

从每个会话中提取第一个用户 (Extracting the first user from each session)
Pandas dataframe has groupby([column(s)]).first() method which is used to get the first record from each group.
熊猫数据框具有groupby([column(s)])。first()方法,该方法用于从每个组获取第一条记录。

The result of grouby.first() is going off the road a little bit with the last group — that is, 8PM where Penny was the first one to get the ticket. Due to some reasons Penny left the country field empty but the above result has Australia in it.
grouby.first()的结果与最后一组稍有不同,即8PM ,其中Penny 是第一个拿到票的人。 由于某些原因, Penny将该country字段留空了,但以上结果包含了Australia 。
As a result of which Penny was forced to go to Australia✈️. Poor Penny🤣.
因此,Penny被迫去澳大利亚✈️。 可怜的竹🤣。
It seems that there is something wrong with the GroupBy.first method😕
看来GroupBy.first方法有问题😕
The expected result should be
预期结果应该是

groupby.first() was expected to give the above result ✔️
groupby.first()预期会得到以上结果✔️
There is nothing wrong with the groupby.first()method. It rather works that way.
groupby.first()方法没有任何问题。 而是这样工作的。
So, if there is a null value in the first record then the first non-null value in the group is carried up into the first record. This is reason why Penny went on a tour to Australia.
因此,如果在第一个记录中有一个空值,则该组中的第一个非空值将被带入第一个记录中。 这就是潘妮去澳大利亚旅游的原因。
What if the entire group contains the null values, then what should be expected from GroupBy.first?
如果整个组都包含空值,那么应该从GroupBy.first中得到什么呢?
Lets take a look at the last year comic-con where no one wanted to on a tour.
让我们看一下去年的漫画展,没人想去参观。

Getting the first user of each session.
获取每个会话的第一个用户 。

What if there is only one record in group and the same record has null in it?
如果组中只有一条记录并且同一条记录中包含空值,该怎么办?
The result stays the same as the above scenario — that is, the record of that group will have null in it.
结果与上述情况相同-即该组的记录中将为空。
Is there a way to make it work to get the correct result using GroupBy.first?
有没有一种方法可以使它使用GroupBy.first获得正确的结果?
The way to fix this problem is to replace the np.nan(NaN) with None using the np.where()method.
解决此问题的方法是使用np.where()方法将np.nan(NaN)替换为None 。
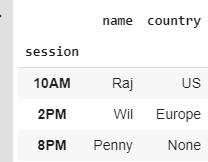
There’s a simple way to get this things done without worrying about the np.nan and None. GroupBy.nth comes in handy during such situation⛑️.
有一种简单的方法可以完成此任务,而无需担心np.nan和None。 在这种情况下, GroupBy.nth会派上用场⛑️ 。
GroupBy.nth doesn’t change anything and gives the result as per order even though if the first record of the group has null value in it. Also, it has extra capabilities.
GroupBy.nth不会进行任何更改,即使组的第一条记录中包含空值,它也会按顺序给出结果。 此外,它还具有其他功能。

The np.nan is not replaced with None and the GroupBy.nth gives the expected result. The result stays the same even if the np.nan are replaced with None
该 np.nan 不与无替代和 GroupBy.nth 给出了预期的结果。 即使将 np.nan 替换为 None ,结果也保持不变
GroupBy.nth has some extra powers
GroupBy.nth具有一些额外的功能
Now, Comic-con wants to select 2 users from each session. First and Third user will be the lucky winners.
现在,Comic-con希望从每个会话中选择2个用户。 First和Third用户将是幸运的获胜者。
GroupBy.nth can be used to get multiple specific records within each group.
GroupBy.nth可用于获取每个组中的多个特定记录。

Finally, the day has arrived when Sheldon, Leonard, and Raj (except Howard😞) got lucky. Country was pre-planned by the group. Comic-con decided to get first 3 entries from each session.
最终,谢尔顿,伦纳德和拉吉(霍华德😞除外)幸运的日子到了。 国家是由小组预先计划的。 Comic-con决定从每个会话中获取前3个条目。
Is there a way to get the first n records from each group?
有没有办法从每个组中获取前n条记录?
During such a time GroupBy.head comes to the rescue🏃♂️. GroupBy.nth can be used but the catch here is to provide a sequence of list starting from 0 to all the way to n-1.
在这段时间里, GroupBy.head得以营救🏃🏃️。 可以使用GroupBy.nth但是这里的GroupBy.nth是提供一个从0一直到n-1的列表序列。

The GroupBy.head preserves the index of the original dataframe.
GroupBy.head保留原始数据帧的索引。
GroupBy.head can also be used to get the first record from each group irrespective of np.nan(NaN) and None.
GroupBy.head也可以用于从每个组获取第一条记录,而不管np.nan(NaN)和None 。
Safe journey to the winners.
获胜者的安全旅程。
翻译自: https://medium.com/swlh/pandas-groupby-first-vs-groupby-nth-vs-groupby-head-7f63fea5b870
groupby.nth















 2106
2106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









