





高可用可伸缩微服务
High-level Design of URL Shortner
URL缩短器的高级设计
介绍 (Introduction)
System design Interview problems are intentionally open-ended. It gives an interviewer opportunity to evaluate design skills and also the depth of technical concepts. Day-to-day engineering work involves architecting a lot many scalable systems. This interview provides a platform to judge a candidate’s problem-solving & communication skills as well.
系统设计面试问题是有目的的。 它使面试官有机会评估设计技能以及技术概念的深度。 日常工程工作涉及架构许多可伸缩系统。 这次面试提供了一个平台,也可以用来评估候选人的解决问题和沟通技巧。
It’s difficult to nail a System Design round without sufficient preparation & practice. Also, it’s intimidating for candidates who don’t have a background in Distributed Systems. At times, interviewees seem to lose their focus & deviate from the topic if they don’t follow a structured methodology.
如果没有充分的准备和实践,就很难确定系统设计方案。 同样,这对没有分布式系统背景的候选人来说也是一个威胁。 有时,如果受访者不遵循结构化的方法,他们似乎会失去焦点并偏离主题。
It’s essential to have conceptual clarity of system design concepts before tackling a problem. In this article, I have chosen a simple problem of designing a URL Shortening service. It’s an easy problem for any beginner. There is no concrete right or wrong answer to a system design problem. However, the candidate has to justify the design choices made while solving the problem.
解决问题之前,必须具有系统设计概念的概念清晰性。 在本文中,我选择了一个设计URL缩短服务的简单问题。 对于任何初学者来说,这都是一个简单的问题。 对于系统设计问题,没有具体的对错答案。 但是,候选人必须证明在解决问题时做出的设计选择是合理的。
We will be looking at how we must go about solving a design problem systematically. Along the way, I’ll also touch upon distributed system fundamentals, APIs, Database Schema design & design trade-offs. Let’s get started.
我们将研究如何系统地解决设计问题。 在此过程中,我还将介绍分布式系统的基础知识,API,数据库架构设计和设计权衡。 让我们开始吧。

了解问题/产品 (Understanding the problem/product)
The problem statement here is ‘Design a URL Shortner like tinyurl.com’. If you don’t know or have never heard of TinyUrl.com, take a pause & visit the website. Before beginning the discussion, one needs to understand the product & it’s behaviour.
这里的问题陈述是“ 像tinyurl.com一样设计URL缩短程序 ”。 如果您不知道或从未听说过TinyUrl.com ,请暂停一下并访问该网站。 在开始讨论之前,您需要了解产品及其行为。
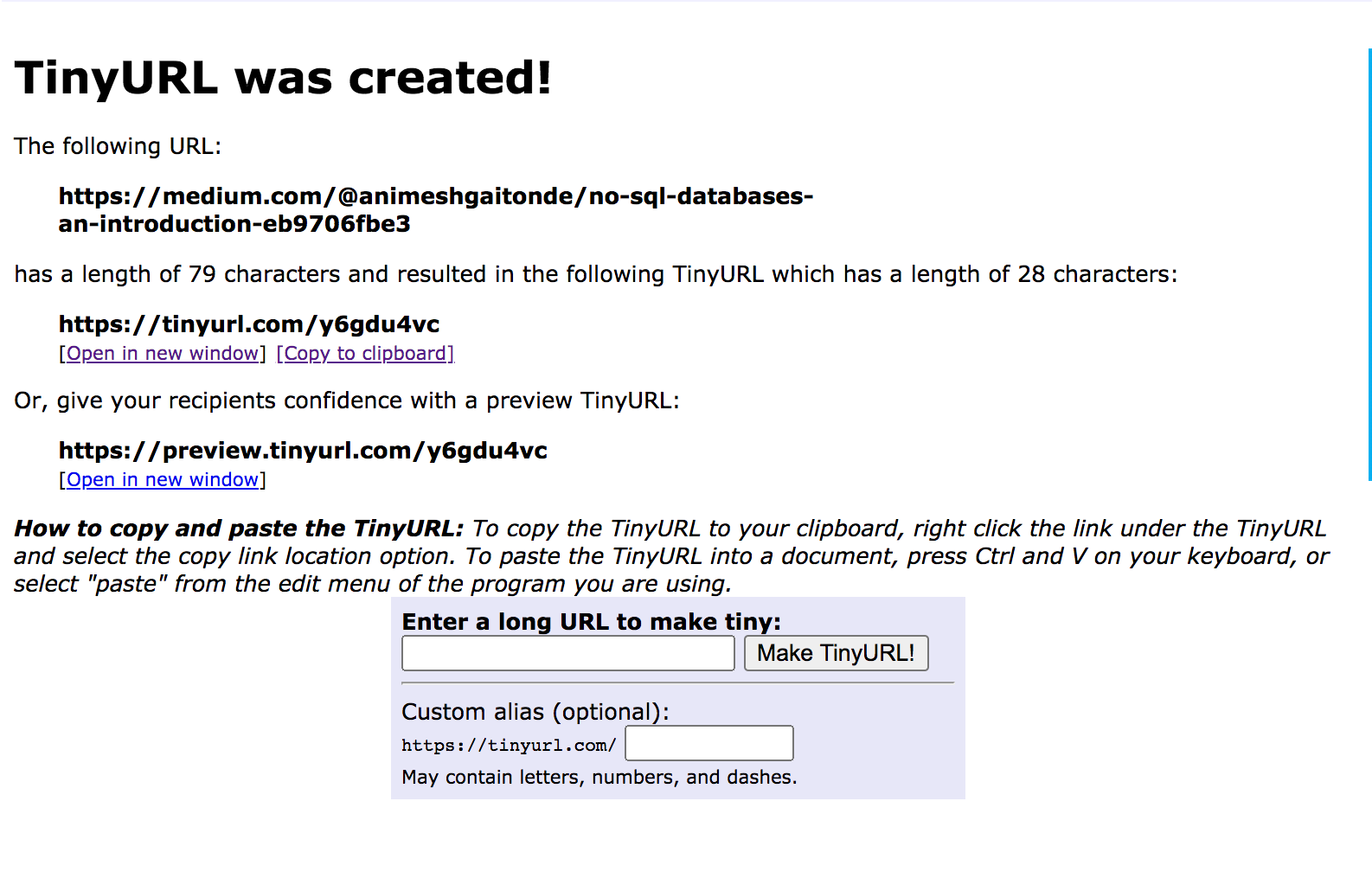
Having used the product will give you an idea of how clients interact with it. Further, it’s always good to ask the interviewer a few clarifying questions —
使用该产品将使您了解客户如何与该产品进行交互。 此外,最好向面试官问一些澄清的问题-
Who are the users of this system — Enterprise users or in general any user
谁是该系统的用户- 企业用户或一般任何用户
How are they going to use it — Web Browsers or Mobile devices
他们将如何使用它-Web浏览器或移动设备
Application’s goal — Shorten any URL on the internet or organization’s internal URL
应用程序的目标- 缩短Internet或组织内部URL上的任何URL
- Can customers provide custom short URLs? 客户可以提供自定义短网址吗?
- Data storage — Temporary short URLs or permanent ones 数据存储-临时短URL或永久URL
The responses to the above questions will help one gain clarity about the problem. Asking questions also shows that an individual doesn’t jump into the solution. It helps one to clear any doubt and proceed with the design with enough clarity.
对以上问题的回答将有助于使您更清楚地了解问题。 提出问题还表明,个人不会跳入解决方案。 它有助于消除任何疑问,并以足够的清晰度进行设计。
要求 (Requirements)
Let’s break our requirements into Functional & Non-Functional requirements.
让我们将需求分为功能需求和非功能需求。
Following will be the Functional requirements:-
以下是功能要求:
- The system should convert a long URL to a short URL 系统应将长网址转换为短网址
- On typing short URL in the browser, the user must be redirected to the long URL link 在浏览器中输入短URL时,必须将用户重定向到长URL链接
- User should have the ability to provide a custom short URL for a given long URL 用户应具有为给定的长URL提供自定义短URL的能力
- The system should store the URL for a year & later purge all old entries 系统应将URL存储一年,然后清除所有旧条目
Following will be the Non-Functional requirements:-
以下是非功能性要求:
- The service must be highly available & scalable 该服务必须高度可用且可扩展
- It should handle high throughput with minimum latency 它应该以最小的延迟处理高吞吐量
- The application should be durable and fault-tolerant 该应用程序应持久且具有容错能力
As we have clarity on what needs to be designed, we can proceed to the next step in design.
由于我们清楚需要设计的内容,因此可以继续进行下一步设计。
CP与AP系统 (CP vs AP System)
We need to decide whether the system will be a CP or an AP system.
我们需要确定系统是CP还是AP系统。
For URL shortener, are we fine to compromise Consistency over Availability? This is something that needs discussion with the Interviewer.
对于URL缩短器,我们可以妥协于可用性一致性吗? 这是需要与采访者讨论的内容。
In this case, let’s assume that if a new URL is created it may not be immediately available for use. For eg:- A newly created URL can be available after a delay of few milliseconds. Until then, the system will throw an error indicating the URL is not found. The system will be highly available and continue to respond to the user’s queries.
在这种情况下,我们假设如果创建了一个新的URL,它可能不会立即可用。 例如:-经过几毫秒的延迟后,新创建的URL可用。 在此之前,系统将引发错误,指示找不到URL。 该系统将具有很高的可用性,并将继续响应用户的查询。
As we have chosen to design an AP system, every read request may not follow the most recent write. However, the system will be eventually consistent.
当我们选择设计AP系统时,每个读取请求可能不会跟随最新的写入。 但是,系统最终将是一致的。
容量估算 (Capacity Estimation)
流量计算 (Traffic Computation)
While designing a large-scale system, we need to know how many users will use the system. What will be the data access patterns? how many application & data servers will be needed.
在设计大型系统时,我们需要知道将有多少用户使用该系统。 数据访问模式将是什么? 需要多少个应用程序和数据服务器。
The answer to the above questions in guestimation. The candidate is supposed to come up with a rough estimate of how many users will use the service?
对上述问题的回答为客户评价。 应聘者应该对使用该服务的用户数量有一个大概的估计。
Assume that we have 200 Mn users. Out of the 200Mn users, 2 Mn users can be actively shortening the URL. For each day, on average, let’s say 10 requests (read + write) are received.
假设我们有2亿用户。 在2亿用户中,有200万用户可以主动缩短URL。 假设每天平均每天收到10个请求(读+写)。
So, we have 20 Mn such records created every day. The remaining 20Mn users would be getting the long URL back from the short URL. Assuming each user fires 10 requests, we have an overall 200 Mn request. This turns out to be 2300 requests/per sec.
因此,我们每天创建2000万个这样的记录。 剩下的2000万用户将从短URL重新获得长URL。 假设每个用户触发10个请求,我们总共有200 Mn个请求。 结果是每秒2300个请求。

储存计算 (Storage Computation)
20 Mn URLs are generated every day. Let’s say the system is designed to handle requests for the next five years.
每天生成2000万个URL。 假设该系统旨在处理未来五年的请求。
Total URLs to be stored = 20 Mn * 30 (days) * 12 * 5 = 36 Bn
要存储的URL总数= 2000万* 30(天)* 12 * 5 = 360亿
We will store long URL, short URL, created and modified fields in the data store. Every record will consume 0.5 Kb of memory. Thus, the total storage needed will be 36 Bn * 0.5 Kb = 18 TB
我们将在数据存储区中存储长URL,短URL,创建和修改的字段。 每条记录将消耗0.5 Kb的内存。 因此,所需的总存储量将为36 Bn * 0.5 Kb = 18 TB
蜜蜂 (APIs)
As agreed in the requirements, we will have the below APIs:-
按照要求中的约定,我们将提供以下API:-
Shorten long URL
缩短长网址
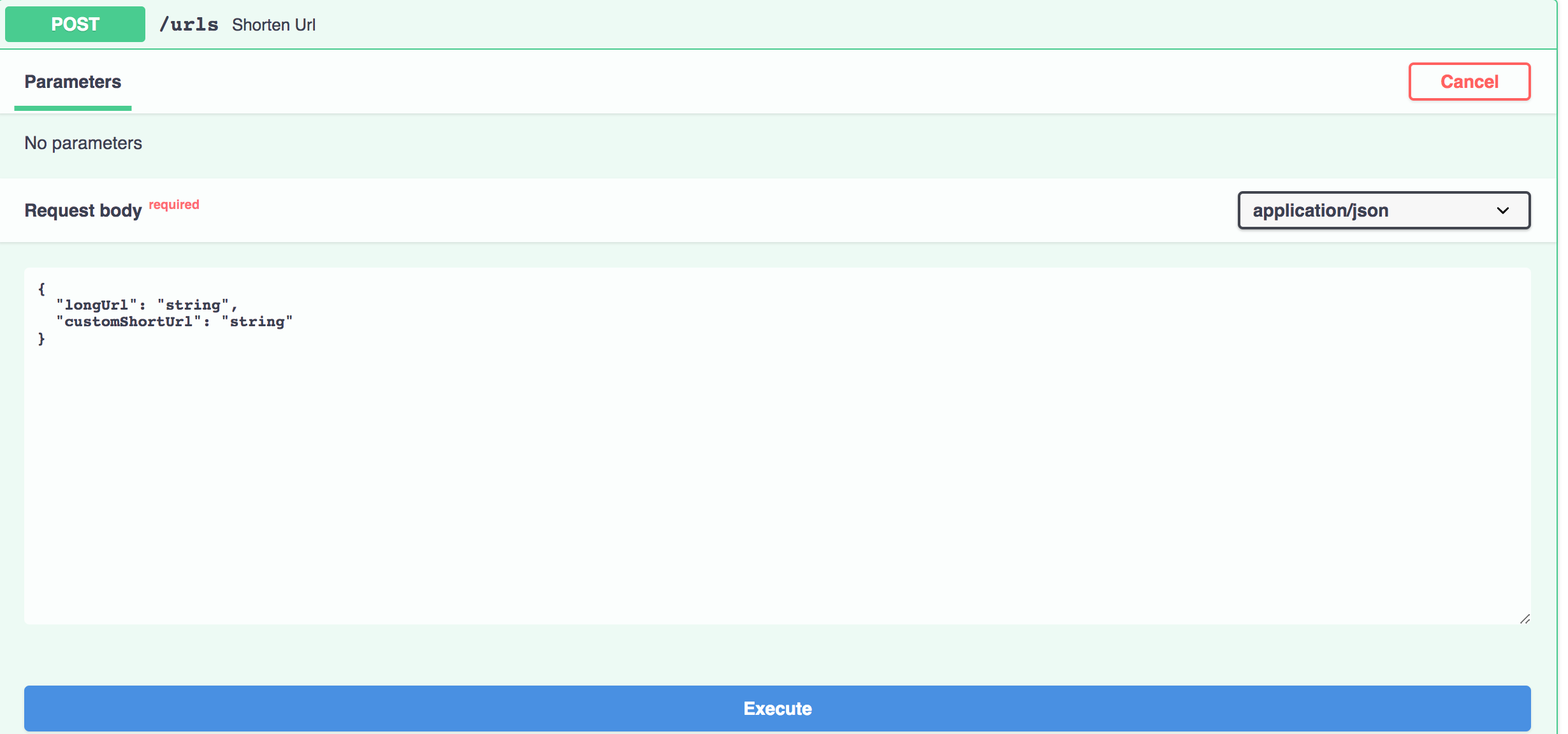
The request body will take customShortUrl as an optional parameter. If not present, it will assume empty.
请求正文将使用customShortUrl作为可选参数。 如果不存在,它将假定为空。
Backend server will perform validation on the length of the long URL. Accordingly, it will return the following response codes:-
后端服务器将对长URL的长度执行验证。 因此,它将返回以下响应代码:
▹ 400- Bad request
▹400-错误的要求
▹ 201- Created. Url mapping entry added
▹201-已创建。 网址映射条目已添加
▹ 200- OK. Idempotent response for the duplicate request
▹200-好。 重复请求的幂等响应
Fetch long Url from short URL
从短网址获取长网址
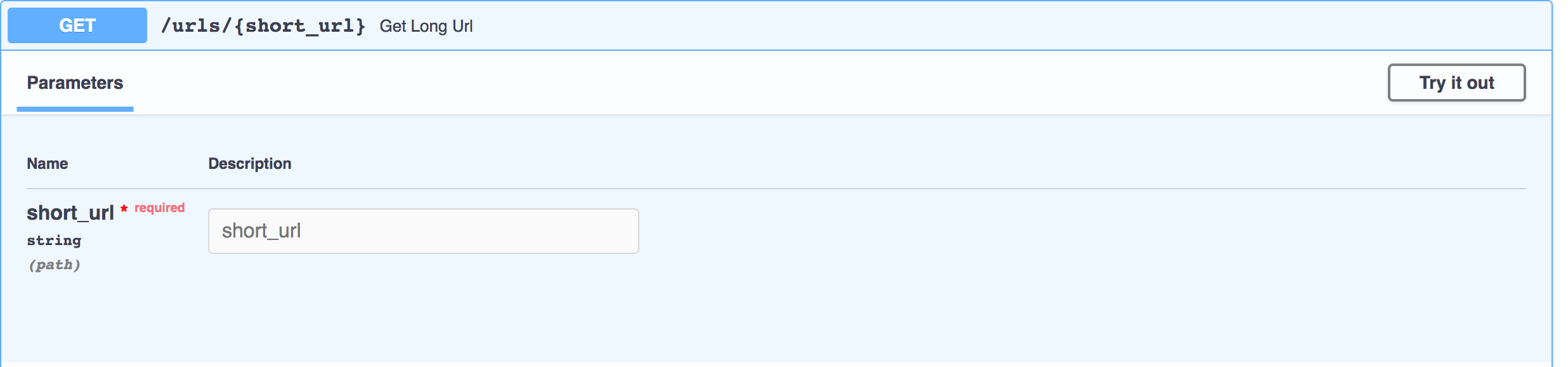
If the system finds the long URL corresponding to the short URL, the user will be redirected. The HTTP response code will be 302.
如果系统找到与短URL对应的长URL,则将重定向用户。 HTTP响应代码将为302。
The service will throw a 404 (Not Found) in case the short URL is absent. It will perform a length check on the input. In case, the length exceeds the threshold, 400 (Bad Request) will be thrown.
如果缺少短网址,该服务将抛出404(未找到)。 它将对输入执行长度检查。 如果长度超过阈值,将抛出400(错误请求)。
构件块和URL缩短算法 (Building Blocks & URL Shortening Algorithm)
关键部件 (Key Components)
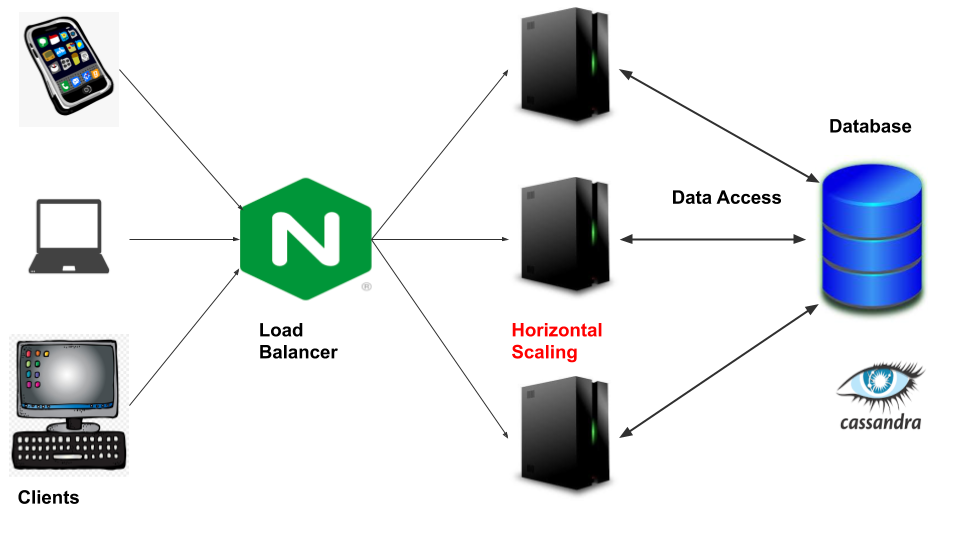
Following will be the key components in the URL shortening application:-
以下是URL缩短应用程序中的关键组件:-
- Clients- Web Browsers/Mobile app. It will communicate with the backend servers via HTTP protocol 客户端-网络浏览器/移动应用。 它将通过HTTP协议与后端服务器通信
- Load Balancer- To distribute the load evenly among the backend servers 负载均衡器-在后端服务器之间平均分配负载
- Web Servers- Multiple instances of web servers will be deployed for horizontal scaling Web服务器-将部署Web服务器的多个实例以进行水平扩展
- Database- It will be used to store the mapping of long URLs to short URLs 数据库-将用于存储长URL到短URL的映射
Below is a high-level sketch of the components and interaction between them:-
以下是组件及其之间的交互作用的简要示意图:
缩短算法 (Shortening Algorithm)
We estimated that the system would need to store 36 Bn URLs. The short URL can consist of lower-case (‘a’ — ‘z’), upper-case (‘A’-’Z’) & numbers (0–9). To support 36 Bn URLS, the short URL must be at least 6 characters long.
我们估计该系统将需要存储360亿个URL。 短URL可以由小写( 'a'-'z' ),大写( 'A'-'Z' )和数字( 0-9 )组成。 要支持360亿个URL,短URL的长度必须至少为6个字符。
⁶²⁶ = 56.8 Bn.
⁶= 568亿美元。
One of the simplest approach to convert a long URL to a short URL is to use hashing. Pass the long URL to a hashing function to obtain a fixed-length string (For eg:- 32-byte string). Then extract the first 6 characters to get the short URL.
将长URL转换为短URL的最简单方法之一是使用哈希。 将长URL传递给哈希函数以获得固定长度的字符串(例如:-32字节字符串)。 然后提取前6个字符以获取短URL。
However, there are two downsides of using the above approach:-
但是,使用上述方法有两个缺点:
- Two different URLs can map to the same short URL. This is as a result of collisions. Using a uniform hash function can reduce the chances of a collision. Additionally, a pseudo-random number can be used for hashing 两个不同的URL可以映射到相同的短URL。 这是碰撞的结果。 使用统一的哈希函数可以减少冲突的机会。 此外,伪随机数可用于哈希
- If a User tries to shorten the same long URL multiple times, he should get a different result every time. In this case, due to collision, chances that the long URL returns the same short URL are high 如果用户尝试多次缩短相同的长URL,则每次都应获得不同的结果。 在这种情况下,由于冲突,长网址返回相同短网址的机会很高
URL生成器服务 (URL Generator service)
We need to guarantee uniqueness for every long URL that is being shortened. For this, we can pre-generate a set of short URLs and persist it in the database. A new layer can be introduced to manage these short URLs. Let’s call this service layer URL Generator Service.
我们需要保证每个要缩短的长URL的唯一性。 为此,我们可以预先生成一组短URL并将其保存在数据库中。 可以引入一个新层来管理这些短URL。 我们将此服务层称为URL生成器服务。
The service will act as a source of all short URLs. The URL Shortener service will get a new short URL from this service. Subsequently, it will store the mapping between long & short URLs. Following diagram illustrates this process:-
该服务将充当所有短URL的来源。 URL Shortener服务将从此服务获取新的短URL。 随后,它将存储长URL和短URL之间的映射。 下图说明了此过程:
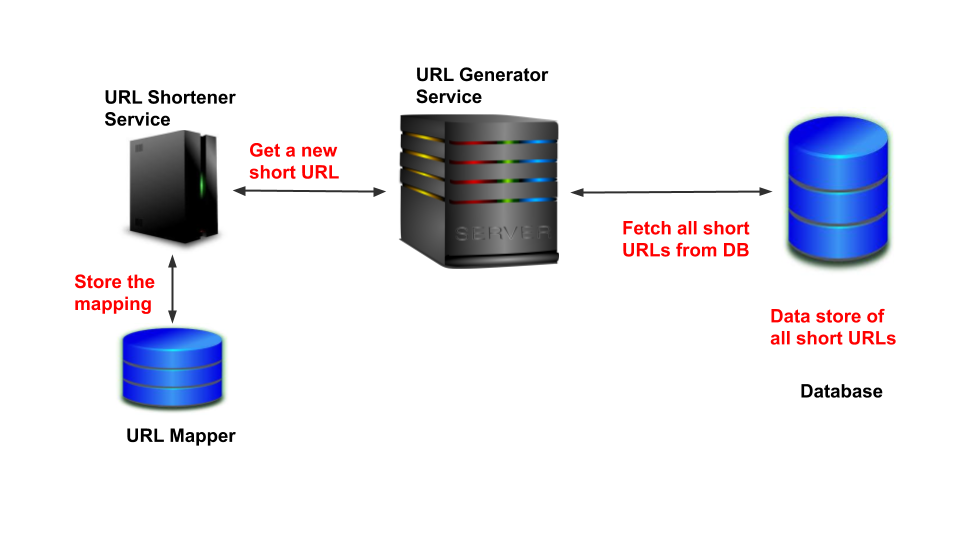
The above process will ensure that every request is allocated a unique short URL. There are a few challenges with the above approach. We considered the case of a single service requesting a tiny URL. What if multiple URL Shortener services running are running?
上面的过程将确保为每个请求分配一个唯一的短URL。 上述方法存在一些挑战。 我们考虑了单个服务请求一个微小URL的情况。 如果正在运行多个URL Shortener服务怎么办?
并发问题 (Concurrency Issues)
Scaling the above system may result in concurrency issues. If not handled correctly, the same URL may get allocated to two different services.
扩展上述系统可能会导致并发问题。 如果处理不正确,则可能会将同一URL分配给两个不同的服务。
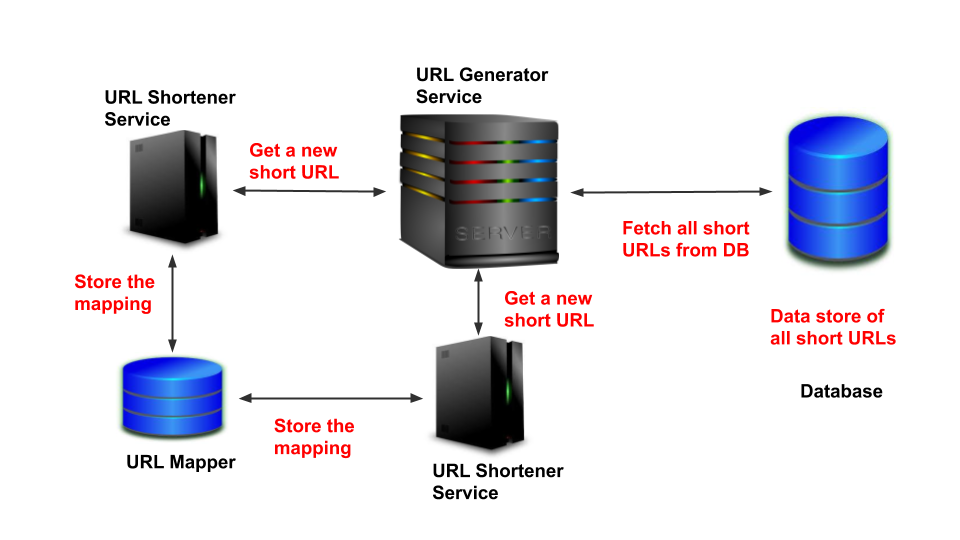
To solve this, we can associate state to a tiny URL. The tiny URL can have two states — ACTIVE, and INACTIVE. By default, all URLs will be in an INACTIVE state. Once it’s allocated to a client, it must be marked as ACTIVE. Only ACTIVE URLs can be assigned to clients.
为了解决这个问题,我们可以将状态关联到一个很小的URL。 小型URL可以具有两种状态-ACTIVE和INACTIVE 。 默认情况下,所有URL均处于INACTIVE状态。 将其分配给客户端后,必须将其标记为ACTIVE 。 只能将ACTIVE URL分配给客户端。
To improve latency, the URL Generator Service can prefetch all tiny URLs from the datastore. This will avoid database calls for every new request. Moreover, it can now use a locking data structure to synchronize access by multiple client applications.
为了提高延迟, URL Generator服务可以从数据存储中预取所有微小的URL。 这样可以避免对每个新请求的数据库调用。 而且,它现在可以使用锁定数据结构来同步多个客户端应用程序的访问。
数据库架构 (Database Schema)
We will need a single table to store the mapping between long URLs and short URLs. Following schema can be used:-
我们将需要一个表来存储长URL和短URL之间的映射。 可以使用以下模式:
URL Mapping schema
URL映射架构
Since the short_url column is a primary key, its indexed and lookups will be quick. Two timestamp fields created_at and modified_at have been included. These fields will help to purge out all the old entries in the table.
由于short_url列是主键,因此它的索引和查找将很快。 包括两个时间戳字段created_at和modified_at 。 这些字段将有助于清除表中的所有旧条目。
To decide between RDBMS or No-SQL database system, let’s revisit our storage estimates. We want to store at least 18 TB of data. Further, we want to serve the requests with minimum latency.
要在RDBMS或No-SQL数据库系统之间做出决定,让我们重新查看我们的存储估计。 我们要存储至少18 TB的数据。 此外,我们希望以最小的延迟为请求提供服务。
It’s better to have the data distributed on different machines. This will prevent a single point of failure. Hence, data sharding will be necessary in this case.
最好将数据分布在不同的计算机上。 这样可以防止单点故障。 因此,在这种情况下将需要数据分片。
Further, we don’t have a data model with relations. There is no requirement for joins here. Also, we expect our data to grow in size gradually. Additionally, our system is supposed to function as an AP system.
此外,我们没有具有关系的数据模型。 这里没有加入的要求。 此外,我们希望我们的数据规模会逐渐增长。 另外,我们的系统应该用作AP系统。
Taking the above points into account, NoSQL seems like a clear winner here. NoSQL databases have built-in sharding and are easier to scale.
考虑到以上几点,NoSQL在这里显然是赢家。 NoSQL数据库具有内置的分片并且更易于扩展。
权衡与瓶颈 (Trade-offs & Bottlenecks)
如何缩放阅读 (How to scale reads)
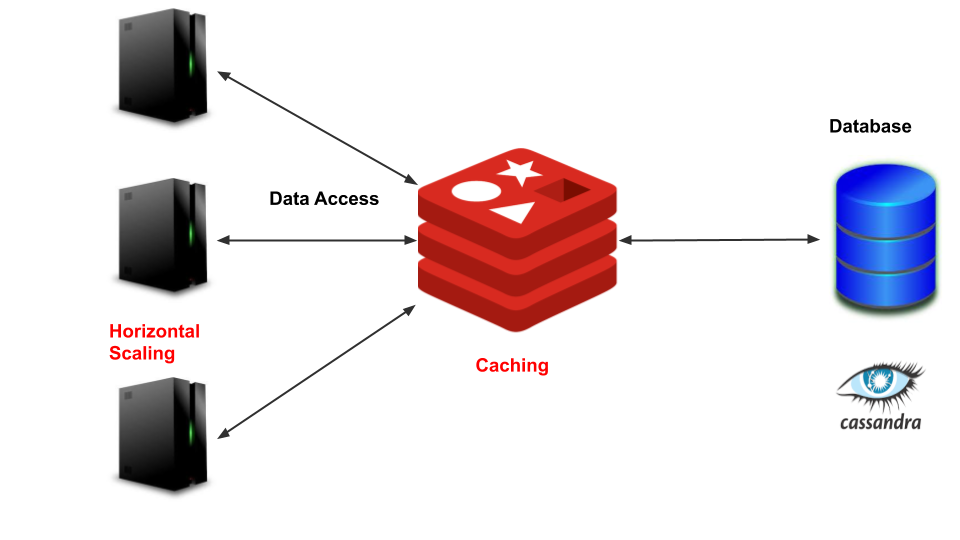
Caching- By introducing a cache, we can scale the read queries. If multiple queries are received with the same short URL, the service can return long URL from the cache. We can use LRU (Least Recently Used) as the Cache eviction policy.
缓存 -通过引入缓存,我们可以扩展读取查询。 如果使用相同的短URL接收到多个查询,则该服务可以从缓存中返回长URL。 我们可以使用LRU(最近最少使用)作为缓存驱逐策略。
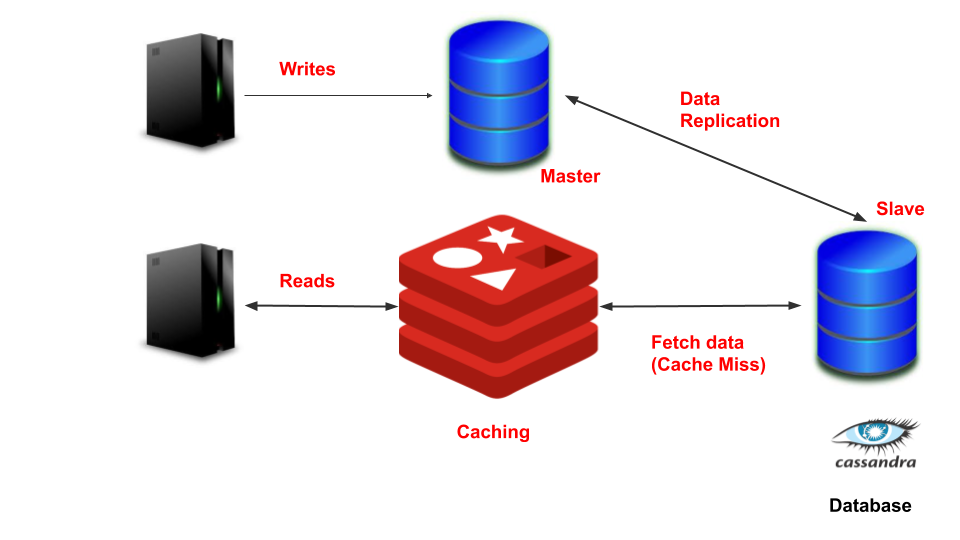
Data replication- We can segregate the reads from the write queries. Writes can be performed on the master and data can be replicated to slaves. Slaves can be used for executing read queries.
数据复制-我们可以将读操作与写查询分开。 可以在主机上执行写操作,并且可以将数据复制到从机上。 从站可用于执行读取查询。
如何分片数据 (How to shard the data)
Storing data on a single database server can cause bottlenecks. There can be a single point of failure. With growing traffic, the read/write pressure on a database will also increase. Hence, it’s better to distribute data on different database servers.
将数据存储在单个数据库服务器上可能会导致瓶颈。 可能存在单点故障。 随着流量的增长,对数据库的读/写压力也会增加。 因此,最好将数据分布在不同的数据库服务器上。
We have the following three strategies for sharding the data:-
我们有以下三种分片数据策略:
Range-based partitioning- In this strategy, URLs starting with ‘a-h’ can be assigned to server 1, the ones starting with ‘i-o’ to server 2 and so on. With this approach, there is a possibility of uneven data distribution. This might result in one shard having twice or thrice the data of another
基于范围的分区 -在这种策略中,可以将以ah开头的URL分配给服务器1,将以io开头的URL分配给服务器2,依此类推。 使用这种方法,可能会导致数据分布不均。 这可能导致一个分片的数据量是另一个分片的两倍或三倍
Hash-based partitioning- This method eliminates the possibility of uneven data distribution. However, it doesn’t scale well when new servers are introduced or existing ones are removed.
基于哈希的分区 -这种方法消除了数据分布不均的可能性。 但是,当引入新服务器或删除现有服务器时,它的伸缩性不好。
Consistent Hashing- This partitioning strategy overcomes the limitations of the above two strategies. The data distribution is even and the addition or removal of new servers has an impact on a minimum number of records.
一致的哈希 -此分区策略克服了以上两个策略的局限性。 数据分布均匀,添加或删除新服务器对最小记录数有影响。
清理网址 (Cleanup of URLs)
An asynchronous job needs to be scheduled to remove all the expired shortened URLs. This job will filter all the expired URLs and return them to the data store for future use. Once the URLs are cleaned up, the tiny URL’s state will be changed to INACTIVE. The service will continue to function as it is and allocate one of the INACTIVE URLs to a new client request.
需要安排异步作业以删除所有过期的缩短的URL。 该作业将过滤所有过期的URL,并将它们返回到数据存储中以备将来使用。 清除网址后,小网址的状态将更改为INACTIVE 。 该服务将继续按原样运行,并将INACTIVE URL之一分配给新的客户端请求。
升级编码 (Level Up Coding)
Thanks for being a part of our community! Subscribe to our YouTube channel or join the Skilled.dev coding interview course.
感谢您加入我们的社区! 订阅我们的YouTube频道或参加Skilled.dev编码面试课程 。
高可用可伸缩微服务














 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









