





shellcode编写入门
This article discusses a simple approach to implement a handwritten parser from scratch and some fundamentals associated with it. This focuses more on explaining the practical aspects of the implementation rather than the formal definitions of parsers.
本文讨论了一种从头开始实现手写解析器的简单方法以及与之相关的一些基础知识。 这更多地侧重于解释实现的实际方面,而不是解析器的正式定义。
介绍 (Introduction)
A parser is the very first thing that comes to our mind when we speak of compiler-development/compiler-construction. Rightly so, a parser plays a key role in a compiler architecture and can also be considered as the entry-point to a compiler. Before we get into the details of how to write a parser, let's see what parsing actually means.
当我们谈到编译器开发/编译器构造时,解析器是我们想到的第一件事。 正确的是,解析器在编译器体系结构中起着关键作用,也可以被视为编译器的入口点。 在详细介绍如何编写解析器之前,让我们看看解析的实际含义。
解析什么 (What is parsing)
Parsing essentially means converting a source-code into a tree-like object representation — which is called the ‘parse tree’ (also sometimes called the ‘syntax tree’). Often, an abstract syntax tree (AST) is confused with a parse/syntax tree. A parse tree is a concrete representation of the source code. It preserves all the information of the source code, including trivial information such as separators, whitespaces, comments, etc. Whereas, an AST is an abstract representation of the source code, and may not contain some of the information that is there in the source.
解析本质上是指将源代码转换成树状的对象表示形式-称为“解析树”(有时也称为“语法树”)。 通常,抽象语法树(AST)与解析/语法树混淆。 解析树是源代码的具体表示。 它保留了源代码的所有信息,包括琐碎的信息,例如分隔符,空格,注释等。而AST是源代码的抽象表示,并且可能不包含源代码中的某些信息。 。
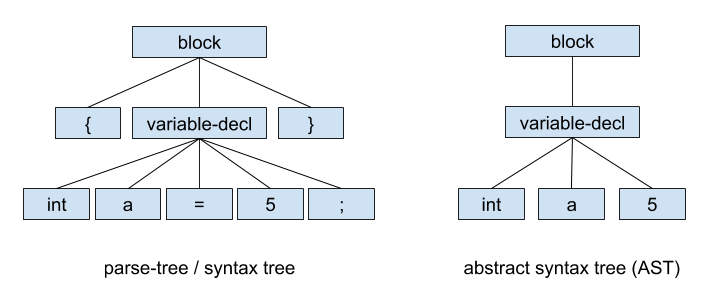
In a parse-tree, each element is called a ‘node’. Leaf-nodes or the terminal-nodes are treated as a special kind of nodes, which is called a ‘token’. The non-terminal nodes are generally referred to as simply ‘node’.
在解析树中,每个元素称为“节点”。 叶节点或终端节点被视为一种特殊的节点,称为“令牌”。 非终端节点通常简称为“节点”。
为什么是手写解析器? (Why a handwritten parser?)
If you look around enough, you will see that there are quite a few parser generators available like ANTLR, Bison, Yacc and etc. With these parser generators, we can simply define a grammar, and automatically generate a parser according to that grammar. That sounds pretty easy! If so, why bother writing a parser from scratch?
如果环顾四周,您会发现有很多解析器生成器,例如ANTLR , Bison ,Yacc等。使用这些解析器生成器,我们可以简单地定义语法,并根据该语法自动生成解析器。 听起来很简单! 如果是这样,为什么还要从头开始编写解析器呢?
A common mistake in compiler construction is thinking that we need to write a parser from scratch — or thinking that we don’t need our own parser. Well, that sounds contradictory! The catch is, both approaches have on its own pros and cons. So it is important to know when to write a parser by hand or to use a parser generator:
编译器构造中的一个常见错误是认为我们需要从头开始编写解析器,或者认为我们不需要自己的解析器。 好吧,听起来很矛盾! 要注意的是,这两种方法各有优缺点。 因此,了解何时手动编写解析器或使用解析器生成器非常重要:
A generated parser:
生成的解析器:
Easy to implement — Define the grammar in a necessary format, and generate the parser. eg: For ANTLR, all we need is to define the grammar in a
.g4format. Then, generating the parser is as simple as running a single command.易于实现-以必要的格式定义语法,并生成解析器。 例如:对于ANTLR,我们所需要的只是以
.g4格式定义语法。 然后,生成解析器就像运行单个命令一样简单。- Easy to maintain — Updating the grammar rule and regenerating the parser is all you need to do. 易于维护-您只需要做的就是更新语法规则并重新生成解析器。
- Can be compact in size. 尺寸可以紧凑。
- However, it doesn’t have the advantages of a handwritten parser have (see below). 但是,它没有手写解析器所具有的优势(请参阅下文)。
A handwritten parser:
手写解析器:
- Writing a parser by hand is a moderately difficult task. Complexity may increase if the language-grammar is complex. However, it has the following advantages. 手工编写解析器是一项中等难度的任务。 如果语言语法复杂,则复杂性可能会增加。 但是,它具有以下优点。
- Can have better and meaningful error messages. Auto-generated parsers can sometimes result in totally unhelpful errors. 可能会有更好且有意义的错误消息。 自动生成的解析器有时可能会导致完全无用的错误。
- Can support resilient parsing. In other words, it can produce a valid parse tree even upon syntax error. This also means a handwritten parser can detect and handle multiple syntax errors at the same time. In generated parsers, this can be achieved to a certain extend with extensive customizations, but might not be able to fully support resilient parsing. 可以支持弹性解析。 换句话说,即使出现语法错误,它也可以产生有效的解析树。 这也意味着手写解析器可以同时检测和处理多个语法错误。 在生成的解析器中,可以通过广泛的自定义实现一定程度的扩展,但可能无法完全支持弹性解析。
- Can support incremental parsing — Parse only a portion of the code, upon an update to the source. 可以支持增量解析—更新源代码后仅解析部分代码。
- Usually better in-terms of performance. 通常情况下,性能更好。
- Easy to customize. You own the code and has the full control over it — eg: In ANTLR4, if you want to customize a parsing logic, then you’ll either have to extend and do a bit of hacking into the generated parser or write some custom logic in the grammar file itself, in another language. This can be messy at times and the level of customization that can be done is very limited. 易于定制。 您拥有代码并拥有对代码的完全控制权-例如:在ANTLR4中,如果要自定义解析逻辑,则要么必须扩展并对生成的解析器进行一点改动,要么在其中编写一些自定义逻辑。语法文件本身,使用另一种语言。 有时这可能很麻烦,并且可以完成的定制级别非常有限。
- Can easily handle context-aware grammars. Not all languages are 100% context-free. There can be situations where you want to tokenize the input or construct the parse-tree differently depending on the context. This is a very difficult, or near-impossible task when it comes to generated parsers. 可以轻松处理上下文感知语法。 并非所有语言都是100%无上下文的。 在某些情况下,您可能希望根据上下文对输入进行标记化或构造不同的解析树。 对于生成的解析器,这是一个非常困难或几乎不可能的任务。
So all in all, if you want to get a production-grade, highly optimized parser that is resilient, and if you are have an ample amount of time, then a handwritten parser is the way to go. On the other hand, what you need is a decent enough parser in a very quick time and the performance or resiliency is not one of your requirements, a generated parser would do the trick.
因此,总而言之,如果您想获得具有弹性的生产级,高度优化的解析器,并且如果您有足够的时间,那么手写解析器就是您的最佳选择。 另一方面,您需要的是在非常短的时间内有足够不错的解析器,而性能或弹性不是您的要求之一,生成的解析器就可以解决问题。
语法 (Grammar)
Despite whether to implement a handwritten parser or to use a generated-parser, there is one thing that is always going to be needed: a well-defined grammar (a formal grammar) for the language we are going to implement. A grammar defines the lexical and syntactical structure of a program of that language. A very popular and simple format for defining context-free grammar is the Backus-Naur Form (BNF) or one of its variants such as the Extended Backus-Naur Form (EBNF).
尽管是实现手写解析器还是使用生成的解析器,但始终需要做一件事:针对将要实现的语言的明确定义的语法(正式语法)。 语法定义了该语言程序的词汇和句法结构。 定义上下文无关语法的一种非常流行且简单的格式是Backus-Naur形式(BNF)或其变体之一,例如Extended Backus-Naur形式(EBNF) 。
解析器的组件: (Components of a Parser:)
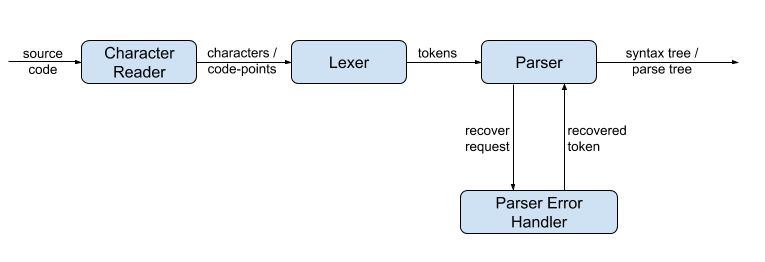
Even though a parser often refers to as a single component within a compiler architecture, it consists of several components, including but not limited to a lexer, a parser, and several other abstractions such as input/character reader(s) and an error handler. The below diagram shows the components and how they are connected to each other, in our parser implementation.
即使解析器通常被称为编译器体系结构中的单个组件,它也包含多个组件,包括但不限于词法分析器,解析器和其他一些抽象概念,例如输入/字符阅读器和错误处理程序。 下图显示了解析器实现中的组件以及它们之间的连接方式。
字符阅读器/输入阅读器 (Character Reader / Input Reader)
The character reader, also called the input reader, reads the source code and provides characters/code-points to the lexer upon request. Source-code can be many things: a file, an input stream, or even a string.
字符读取器(也称为输入读取器)读取源代码,并根据请求向词法分析器提供字符/代码点。 源代码可以有很多东西:文件,输入流甚至是字符串。
It is also possible to embed the input-reader capabilities to the lexer itself. However, the advantage of abstracting out the reader from the lexer is that, depending on the input, we can plug-in different readers, to the same lexer. And the lexer doesn’t have to worry about handling different types of inputs.
也可以将输入阅读器功能嵌入词法分析器本身。 但是,从词法分析器中抽象出阅读器的好处是,根据输入,我们可以将不同的阅读器插入同一个词法分析器中。 而词法分析器不必担心处理不同类型的输入。
An input reader consists of three sets of important methods:
输入阅读器包含三组重要方法:
peek()/peek(k) — Get the next character /next k-th character from the input. This is used to look ahead the characters without consuming/removing them from the input stream. Calling the
peek()method more than once will return the same character.peek()/ peek(k) -从输入中获取下一个字符/下一个第k个字符。 这用于在不消耗/从输入流中删除字符的情况下预见字符。 多次调用
peek()方法将返回相同字符。consume()/consume(k) — Get the next character /next k-th token from the input, and remove it from the input. This means, calling the
consume()method multiple times will return a new character at each invocation. Sometimes thisconsume()method is also referred to asread()ornext().消耗()/消耗(k) -从输入中获取下一个字符/下一个第k个令牌,并将其从输入中删除。 这意味着,多次调用
consume()方法将在每次调用时返回一个新字符。 有时,将该consume()方法也称为read()或next()。isEOF() — Checks whether the reader has reached the end of the input.
isEOF() —检查阅读器是否已到达输入的末尾。
Lexer (The Lexer)
The lexer reads characters from the input/character reader and produces tokens. In other words, it converts a character stream into a token stream. Hence its sometimes also called the tokenizer. These tokens are produced according to the defined grammar. Usually, the implementation of the lexer is slightly complex than the character-reader, but much simpler than the parser.
词法分析器从输入/字符读取器读取字符并产生令牌。 换句话说,它将字符流转换为令牌流。 因此,它有时也称为令牌生成器。 这些标记是根据定义的语法生成的。 通常,词法分析器的实现比字符读取器稍微复杂,但比解析器简单得多。
An important aspect of the lexer is handling whitespaces and comments. In most languages, the language semantics are independent of the whitespaces. Whitespaces are only required to mark the end of a token and hence are also called ‘trivia’ or ‘minutiae’ as they have little value for the AST. However, this is not the case with every language, because whitespace can have semantic meanings in some languages such as python. Different lexers handle these whitespaces and comments differently:
词法分析器的重要方面是处理空格和注释。 在大多数语言中,语言语义独立于空格。 仅需要空格来标记令牌的结尾,因此也被称为“琐事”或“细节”,因为它们对AST的价值很小。 但是,并非每种语言都如此,因为空格在某些语言(例如python)中可能具有语义。 不同的词法分析器对这些空白和注释的处理方式不同:
- Discard them at the lexer — Disadvantage of this approach is, it will not be able to reproduce the source from the syntax/parse tree. This can become an issue if you are planning to use the parse-tree for purposes like code-formatting and etc. 在词法分析器中丢弃它们-这种方法的缺点是,它将无法从语法/解析树中重现源代码。 如果您打算将解析树用于代码格式化等目的,则可能会成为问题。
- Emit whitespaces as separate tokens, but to a different stream/channel than the normal token. This is a good approach for languages where whitespaces have semantic meaning. 将空格作为单独的令牌发出,但发送到与常规令牌不同的流/通道。 对于空格具有语义含义的语言,这是一种很好的方法。
- Persist them in the parse tree, by attaching them to the nearest token. In our implementation, we will be using this approach. 通过将它们附加到最近的令牌,在解析树中保留它们。 在我们的实现中,我们将使用这种方法。
Similar to the character reader, lexer consists of two methods:
类似于字符阅读器,lexer包含两种方法:
peek()/peek(k) — Get the next token /next k-th token. This is used to look ahead the tokens without consuming/removing them from the input stream. Calling the
peek()method more than once will return the same token.peek()/ peek(k) —获取下一个令牌/下一个第k个令牌。 这用于在不消耗/从输入流中删除令牌的情况下预告令牌。 多次调用
peek()方法将返回相同的令牌。consume()/consume(k) — Get the next token /next k-th token, and remove it from the token stream. This means, calling the
consume()method multiple times will return a new token at each invocation. Sometimes thisconsume()method is also referred to asread()ornext().消耗()/消耗(k) -获取下一个令牌/下一个第k个令牌,并将其从令牌流中删除。 这意味着,多次调用
consume()方法将在每次调用时返回一个新令牌。 有时,将该consume()方法也称为read()或next()。
Once the lexer reaches the end of the input from the character reader, it emits a special token called the ‘EOFToken’ (end of file token). The parser uses this EOFToken to terminate the parsing.
一旦词法分析器到达字符读取器输入的末尾,它将发出一个特殊的令牌,称为“ EOFToken”(文件令牌的末尾)。 解析器使用此EOFToken终止解析。
解析器 (The Parser)
The parser is responsible for reading the tokens from the lexer and producing the parse-tree. It gets the next token from the lexer, analyzes it, and compare it against a defined grammar. Then decides which of the grammar rule should be considered, and continue to parse according to the grammar. However, this is not always very straightforward, as sometimes it is not possible to determine which path to take only by looking at the next token. Thus, the parser may have to check a few tokens into the future to as well, to decide the path or the grammar rule to be considered. We will discuss this in detail in the next article. However, due to the complication like these, the parser is also the most complex component to implement in a parser-architecture.
解析器负责从词法分析器读取令牌并生成解析树。 它从词法分析器获取下一个标记,对其进行分析,并将其与定义的语法进行比较。 然后决定应考虑哪个语法规则,并继续根据语法进行解析。 但是,这并不总是很简单,因为有时无法仅通过查看下一个令牌来确定要采用的路径。 因此,解析器可能还必须检查一些将来的令牌,以决定要考虑的路径或语法规则。 我们将在下一篇文章中对此进行详细讨论。 但是,由于此类复杂性,解析器还是解析器体系结构中要实现的最复杂的组件。
Generally, a parser only needs one method — A parse() method which will do all the parsing, and returns the parser-tree.
通常,解析器仅需要一个方法—一个parse()方法将完成所有解析,并返回解析器树。
Given the fact that our objective is to implement a parser that is both resilient and gives proper error messages, it is quite an important aspect of the parser to properly handle syntax errors. A syntax error is a case where an unexpected token is reached, or in other words, the next token does not match the defined grammar, during the parsing. In such cases, parser asks the ‘error handler’ (see the next section) to recover from this syntax error, and once the error handler recovers, the parser continues to parse the rest of the input.
考虑到我们的目标是实现一个既有弹性又能给出正确错误消息的解析器,因此正确处理语法错误是解析器的一个重要方面。 语法错误是在解析过程中到达意外令牌或换句话说,下一个令牌与定义的语法不匹配的情况。 在这种情况下,解析器会要求“错误处理程序”(请参见下一节)从此语法错误中恢复,并且一旦错误处理程序恢复,解析器将继续解析其余的输入。
错误处理程序 (Error Handler)
As discussed in the previous section, the objective of an error handler is to recover upon a syntax error. It plays a key role in a modern resilient parser, especially to be able to produce a valid parser tree even with syntax errors and to give proper and meaningful error messages.
如上一节所述,错误处理程序的目的是在语法错误时恢复。 它在现代的弹性解析器中起着关键作用,尤其是即使语法错误也能够产生有效的解析器树并提供适当且有意义的错误消息。
Error handling capabilities can also be embedded into the parser itself. The advantage of doing so is, since the errors will be handled then and there at the parser, there is a lot of contextual information available at the point of recovery. However, there are more disadvantages than the advantages of embedding recovery capabilities into the parser itself:
错误处理功能也可以嵌入解析器本身。 这样做的好处是,由于错误将在解析器中处理,因此在恢复点有很多可用的上下文信息。 但是,将恢复功能嵌入解析器本身的优点比其他优点更多:
- Trying to recover each and every place will result in a lot of repetitive-tasks and duplicate codes 试图恢复每个地方都会导致很多重复任务和重复代码
- The parser logic will be cluttered with error handling logic, which will eventually make the codebase to be hard to read and understand. 解析器逻辑将被错误处理逻辑所困扰,最终将使代码库难以阅读和理解。
- By having a separate error handler, it is also possible to plug-in different error-handlers for different use-cases. For example, one might want to use one error handling approach for the CLI tools, and a different error handling approach for the interactive IDEs. Because IDEs might want to facilitate code completion, etc, and hence the pattern of recovery would be more closer to the user’s writing pattern. 通过具有单独的错误处理程序,还可以针对不同的用例插入不同的错误处理程序。 例如,可能要对CLI工具使用一种错误处理方法,而对于交互式IDE使用另一种错误处理方法。 由于IDE可能希望促进代码完成等,因此恢复模式将更接近用户的书写模式。
In this article, we discussed the basic architecture of a parser, some terminologies, and when to go for a handwritten parser and when to not. We also discussed some high-level details of different components of a parser and their requirements. In the next article, I will discuss in detail about each of these components, and the algorithms to be followed including some implementation details.
在本文中,我们讨论了解析器的基本体系结构,一些术语以及何时使用手写解析器以及何时不使用手写解析器。 我们还讨论了解析器的不同组件及其要求的一些高级细节。 在下一篇文章中,我将详细讨论这些组件中的每一个,以及将要遵循的算法,包括一些实现细节。
翻译自: https://medium.com/swlh/writing-a-parser-getting-started-44ba70bb6cc9
shellcode编写入门















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









