





I recently wrote an implementation of the Soundex Algorithm which attempts to assign the same encoding to words which are pronounced the same but spelled differently. In this post I’ll cover the Levenshtein Word Distance algorithm which is a related concept measuring the “cost” of transforming one word into another by totalling the number of letters which need to be inserted, deleted or substituted.
我最近写了一个Soundex算法的实现,该实现试图为发音相同但拼写不同的单词分配相同的编码。 在本文中,我将介绍Levenshtein单词距离算法,该算法是一个相关概念,用于通过总计需要插入,删除或替换的字母数来衡量将一个单词转换为另一个单词的“成本”。
The Levenshtein Word Distance has a fairly obvious use in helping spell checkers decided which words to suggest as alternatives to mis-spelled words: if the distance is low between a mis-spelled word and an actual word then it is likely that word is what the user intended to type. However, it can be used in any situation where strings of characters need to be compared, such as DNA matching.
Levenshtein单词距离在帮助拼写检查人员确定建议使用哪些单词作为错误拼写单词的替代项方面有相当明显的用途:如果错误拼写单词与实际单词之间的距离很短,则很可能单词是用户打算输入。 但是,它可用于需要比较字符串的任何情况,例如DNA匹配。
Levenshtein字距 (The Levenshtein Word Distance)
I usually leave the program’s output until near the end of each post but this time I’ll put it up front as it is the easiest way of showing how the algorithm works. I’ll actually show two program outputs, the first being after the required data structure has been initialized but before the algorithm has been run, and the second after the algorithm has been run.
我通常将程序的输出保留到每篇文章的结尾处,但是这次我将其放在最前面,因为这是显示算法工作原理的最简单方法。 实际上,我将显示两个程序输出,第一个是在初始化所需的数据结构之后但在算法运行之前,第二个是在算法运行之后。
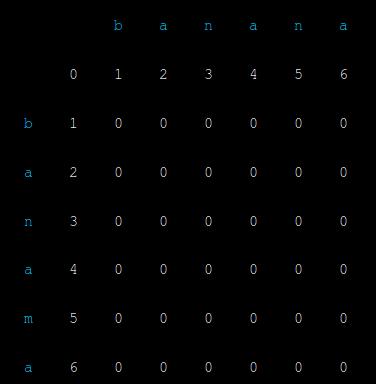
Here we have a hypothetical situation where somebody has typed “banama” and we want to see how close it is to “banana”. The source word “banama” is shown down the left and the target word “banana” is along the top. We also have a grid of integers with one more row than the number of letters in the source, and one more column than the number of letters in the target.
在这里,我们有一个假设的情况已经有人输入“banama”我们希望看到它是如何接近“ 香蕉 ”。 源词“ banama ”显示在左下方,目标词“ banana ”显示在顶部。 我们还有一个整数网格,其中行比源中的字母数多一列,比目标中的字母数多一列。
Most values are initially set to 0, but the first row of numbers represent the cumulative number of letters which need to be inserted to form the target, and the first column shows the cumulative number of deletions to remove the source. In other words, to transform “banama” into “banana” you could delete six letters and insert six more. Obviously that’s not the most efficient way though as only one operation needs to be done, the substitution of the “m” with an “n”. Let’s now look at the program output after the algorithm has been run.
大多数值最初都设置为0,但是数字的第一行表示需要插入以形成目标的字母的累积数量,而第一列显示了删除源的删除的累积数量。 换句话说,改造“banama”变成“ 香蕉 ”,你可以删除六个字母和插入六个。 显然,这不是最有效的方法,因为只需执行一个操作,即用“ n”替换“ m”。 现在让我们看一下算法运行后的程序输出。
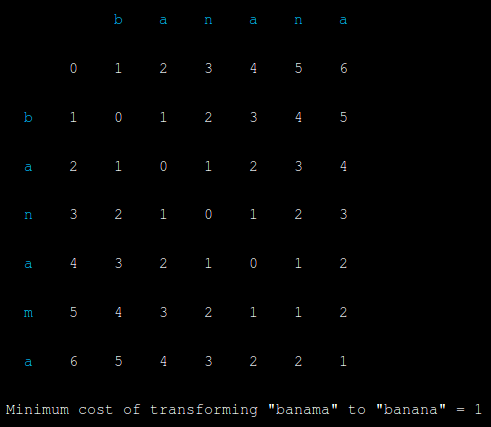
All the other numbers have been filled in, and the number in the bottom right is the total cost of transforming “banama” to “banana” using the minimum number of operations, in this case 1.
所有其他号码已经被填入,并在右下角的数字是转化“banama”到“ 香蕉 ”使用操作的最小数目,在这种情况下1的总成本。
The values for each of the 36 numbers initialized to 0 are calculated as follows:
初始化为0的36个数字中每个数字的值计算如下:
- Find the value diagonally top-left and if the corresponding letters are different add 1 (substitution cost) 在对角线左上角找到值,如果对应的字母不同,则加1(替代成本)
- Find the value above and add 1 (deletion cost) 找到上面的值并加1(删除成本)
- Find the value to the left and add 1 (insertion cost) 在左侧找到值,然后加1(插入成本)
- Set the current value to the lowest of the above three values 将当前值设置为上述三个值中的最小值
For this project I will use 1 as the “cost” of all three possible operations: substitution, insertion and deletion. However, this is not mandatory and in some circumstances different costs might be considered appropriate. For example in a spell checker you might feel someone is more likely to type the wrong letter than to miss out a letter or type an extra letter. Setting the insert and delete cost to > 1 will therefore make words with the same number of letters more likely to be suggested as alternatives than words where inserts or deletes are required.
对于此项目,我将使用1作为所有三种可能的操作的“成本”:替换,插入和删除。 但是,这不是强制性的,在某些情况下,可以考虑使用不同的成本。 例如,在拼写检查器中,您可能会觉得某人输入错字母的可能性比漏掉字母或输入多余字母的可能性更大。 因此,将插入和删除成本设置为> 1会使与要求插入或删除的单词相比,更可能建议使用具有相同字母数的单词作为替代单词。
The overall plan of the implemention of Levenshtein’s Word Distance should now be clear — given two words we just need to create a suitably sized 2D list, initialize the numbers and then iterate the rows and columns, setting the elements to their final values.
Levenshtein的单词距离实现的总体计划现在应该很清楚-给定两个单词,我们只需要创建一个适当大小的2D列表,初始化数字,然后迭代行和列,将元素设置为其最终值即可。
该项目 (The Project)
This project consists of two files which you can clone or download from the Github repository.
该项目包含两个文件,您可以从Github存储库中克隆或下载它们。
- levenshtein.py levenshtein.py
- main.py main.py
This is the first file.
这是第一个文件。
The __init__ method simply creates a few attributes in our class with default values.
__init__方法仅在我们的类中创建一些具有默认值的属性。
The calculate method is central to this whole project, and after calling __init_grid it iterates the source word letters and then the target word letters in a nested loop. Within the inner loop it calculates the substitution, deletion and insertion cost according to the rules described above, finally setting the grid value to the minimum of these. After the loop we set the minimum cost to the bottom right value.
在整个项目中, calculate方法至关重要。在调用__init_grid它将在嵌套循环中依次迭代源单词字母和目标单词字母。 在内部循环中,它根据上述规则计算替换,删除和插入成本,最后将网格值设置为最小。 循环后,我们将最小成本设置为右下角的值。
The print_grid method is necessarily rather fiddly, and prints the words and grid in the format shown above. The separate print_cost method is much simpler and just prints the cost with a suitable message, or a warning if it has not yet been calculated.
print_grid方法一定很print_grid ,并以上面显示的格式打印单词和网格。 单独的print_cost方法要简单得多,它只用适当的消息或如果尚未计算出警告就打印成本。
The __init_grid function called in calculate firstly empties the grid for those circumstances where we are reusing the object. It then loops the rows and columns, setting the first values to 1, 2, 3… and the rest to 0. Finally minimum_cost is set to -1 as an indicator that the costs have not yet been calculated, and is used in print_cost.
对于我们要重用该对象的情况,在__init_grid调用__init_grid函数首先会清空网格。 然后,它循环行和列,将第一个值设置为1、2、3…,将其他值设置为0。最后,minimum_cost设置为-1,以指示尚未计算成本,并在print_cost中使用。
Let’s now move on to main.py.
现在让我们进入main.py。
Firstly we create two lists of word pairs to run the algorithm on, and then create a Levenshtein object. Then we iterate the lists, setting the words and calling the methods.
首先,我们创建两个单词对列表来运行算法,然后创建一个Levenshtein对象。 然后,我们迭代列表,设置单词并调用方法。
Run the code with this command.
使用此命令运行代码。
python3.8 main.py
python3.8 main.py
I have already included the banama/banana output above so won’t repeat it here. The word distance there was 1, so banana easily qualifies as a sensible suggestion if somebody mis-types banama. However, if you typed banama you wouldn’t expect your word processor to suggest elephant, so let’s try those two words.
我已经包括了banama / 香蕉产量的上方,这里就不再重复了。 这个词的距离有1,所以香蕉容易有资格作为一个明智的建议,如果有人误类型banama。 但是,如果您输入banama ,则不会期望您的文字处理器会提示“ 大象” ,因此让我们尝试这两个单词。
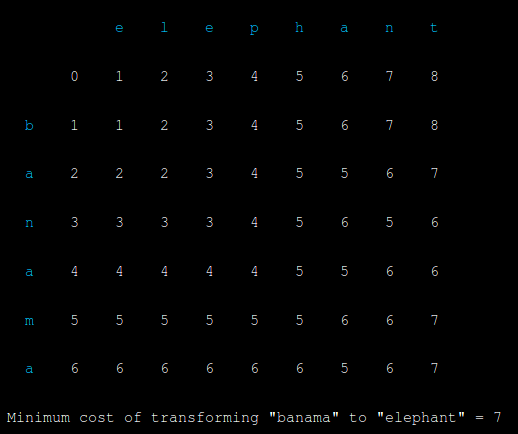
The word distance here is 7 as banama needs to be almost completely re-typed to get to elephant. Clearly not a valid alternative.
这里的距离一词是7,因为香蕉需要几乎完全重新键入才能到达大象 。 显然不是有效的选择。
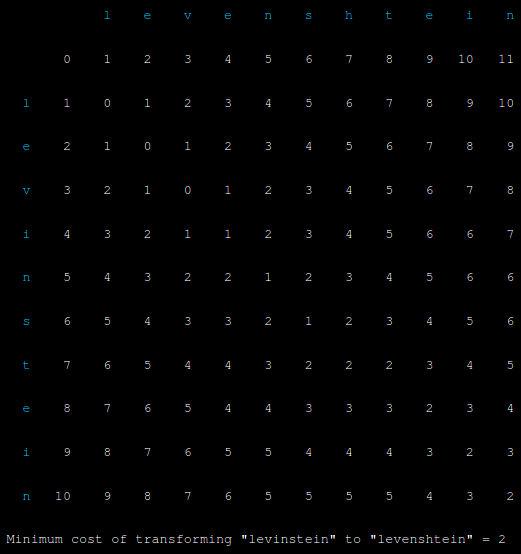
Finally levinstein/levenshtein. One substitution and one insertion give us a word distance of 2, also a sensible suggestion. You would probably consider word distances of 2 or perhaps 3 to be reasonable for alternative suggestions, but no more.
最后莱文斯坦 / 莱文施泰因 。 一个替换和一个插入给我们一个词的距离为2,这也是一个明智的建议。 对于替代建议,您可能会认为2或3的词距是合理的,但仅此而已。
翻译自: https://medium.com/explorations-in-python/levenshtein-word-distance-in-python-e276422f4162















 1955
1955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









