





 通过对柏拉图共和国I~II中对话的情感分析,揭示了不同角色如Cephalus、Polemarchus、Thrasymachus对正义的不同观点。使用BERT模型和Scattertext进行负面情绪分析,展现了正义定义争论中的核心词汇。通过可视化,突显了传统雅典价值观与苏格拉底对正义追求的冲突。
通过对柏拉图共和国I~II中对话的情感分析,揭示了不同角色如Cephalus、Polemarchus、Thrasymachus对正义的不同观点。使用BERT模型和Scattertext进行负面情绪分析,展现了正义定义争论中的核心词汇。通过可视化,突显了传统雅典价值观与苏格拉底对正义追求的冲突。
介绍 (Introduction)

Plato’s Republic, which introduces questions that dominate western political philosophy even nowadays, is fundamentally a dialogue. Plato endeavours to conceptualize the ideal society through philosophical discussions and these tendencies for spirited debates are quite explicit in books I~II. Early in The Republic, Socrates refutes the potential definitions of justice suggested by various figures such as Cephalus, Polemarchus, and Thrasymachus. Since negative emotions often accompanied these arguments, I thought conducting sentiment analysis could help contextualize the main ideas covered in The Republic. Using the BERT-based sentiment classification model provided by Huggingface’s Transformers package, I attempted to extract the sentence tokens of negative sentiment and visualize their word frequencies with the Scattertext package.
从根本上说,柏拉图共和国在当今仍引入了主导西方政治哲学的问题,这从根本上来说就是一场对话。 柏拉图致力于通过哲学讨论将理想社会概念化,而这些激烈辩论的趋势在第一至第二本书中是很明显的。 在共和国初期,苏格拉底驳斥了诸如塞费勒斯,波勒玛格鲁斯和Thrasymachus等人物提出的正义的潜在定义。 由于负面情绪经常伴随着这些论点,因此我认为进行情绪分析可以帮助将《共和国》中的主要思想背景化。 使用Huggingface的Transformers软件包提供的基于BERT的情感分类模型,我尝试提取负面情感的句子标记,并使用Scattertext软件包可视化它们的词频。
数据预处理 (Data Preprocessing)
import nltk
import pandas as pd
from transformers import pipeline
nlp_sentiment = pipeline("sentiment-analysis")
full_text = open("/mnt/d/nemo/philosophy_analysis/Plato/Plato's Republic/Plato's Republic - Book I - II/data/Dialogue with Glaucon.txt","r",encoding='UTF8').read()
full_text = [' '.join(nltk.word_tokenize(s)) for s in full_text.replace('?', '.').replace('!', '.').split('.') if len(s)>20]
results = nlp_sentiment(full_text)
sentiment = []
for s in results:
if s['label'] == 'NEGATIVE' and s['score'] > 0.9:
sentiment.append('NEGATIVE')
else:
sentiment.append('NEUTRAL')
speaker = ['Glaucon'] * len(sentiment)
galucon_df = pd.DataFrame({'text':full_text, 'sentiment':sentiment, 'speaker':speaker})Republic I~II, which are a series of arguments about the essence of justice, would be an excellent subject for sentiment analysis. First, I prepared a dataset of texts from the Republic. Then, using the BERT sentiment classifier, I was able to determine whether a given text contained negative sentiment. As a result, I created a pandas dataframe with a sentiment column that consists of NEGATIVE or NEUTRAL.
关于正义本质的一系列论证的共和国一到二,将是情感分析的一个很好的主题。 首先,我准备了一个来自共和国的文本数据集。 然后,使用BERT情感分类器,我能够确定给定文本是否包含负面情感。 结果,我创建了一个pandas数据框,其中的情绪列由NEGATIVE或NEUTRAL组成。

情绪分析 (Sentiment Analysis)
import spacy
import scattertext as st
import pandas as pd
dialogue_df = pd.read_csv('/mnt/d/nemo/philosophy_analysis/Plato/Plato\'s Republic/Plato\'s Republic - Book I - II/data/dialouge_data.csv', index_col=0)
nlp = spacy.load('en')
corpus = st.CorpusFromPandas(dialogue_df, category_col='sentiment', text_col='text', nlp=nlp).build()
html = st.produce_scattertext_explorer(corpus, category='NEGATIVE',
category_name='NEGATIVE',
not_category_name='NEUTRAL',
width_in_pixels=1000,
metadata=dialogue_df['speaker'])
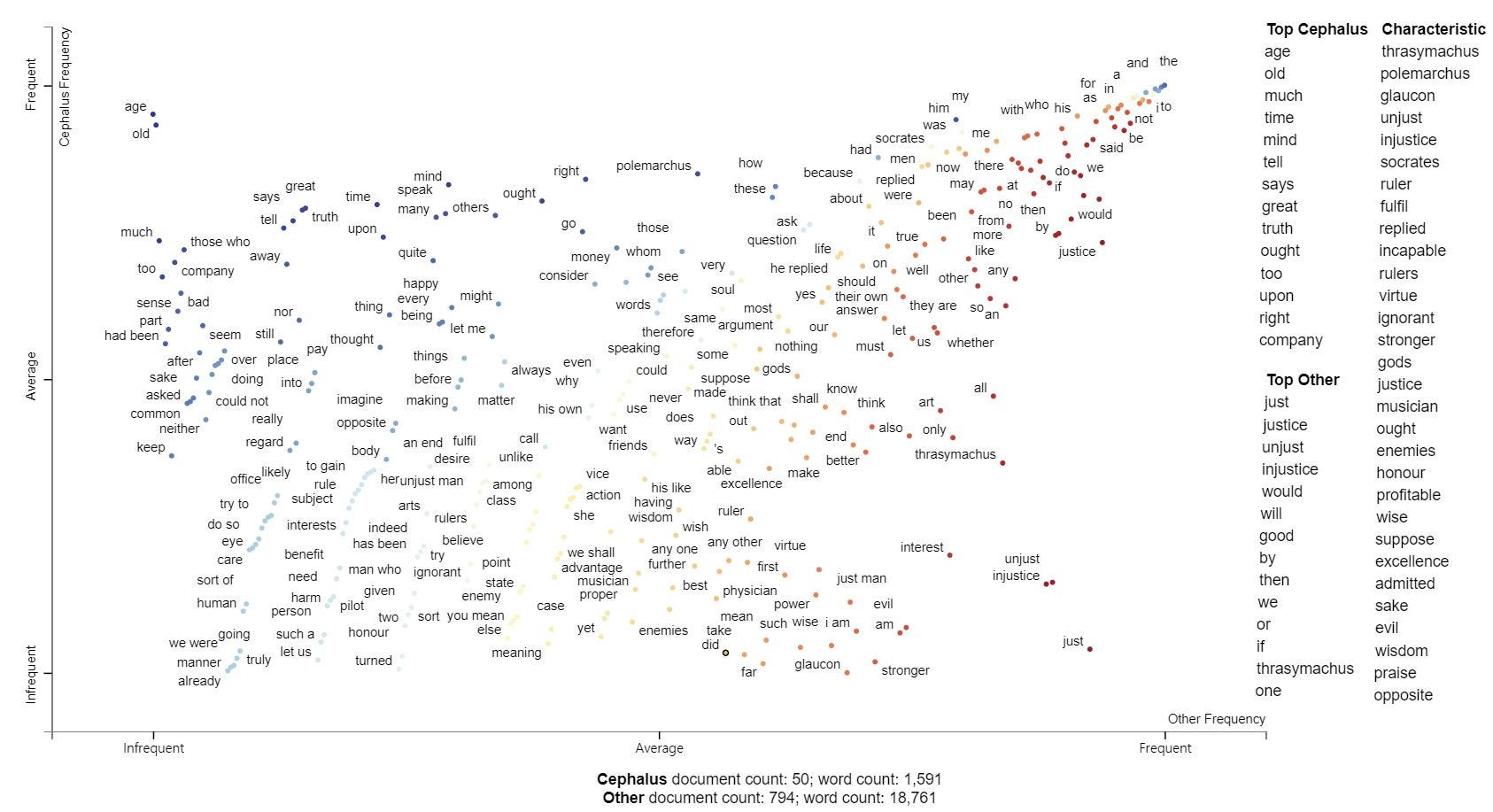
open("Dialogue_Sentiment.html", 'wb').write(html.encode('utf-8'))Using Scattertext’s term frequency visualization functionality, I examined which keywords were dominant in sentences of negative sentiment. The vertical axis represents the NEGATIVE class, and the horizontal axis, the NEUTRAL ones. As expected, the texts classified as NEGATIVE were mostly part of the arguments concerning the definitions of justice. They featured terms related to the discussions of different characters. ‘Old’ and ‘age’ characterized Cephalus, the elderly man of the house. ‘Enemy’ and ‘friend’ depicted Polemarchus’ tendency to distinguish allies from foes. ‘Rulers’, ‘advantage’, and ‘benefit’, are words often used by Thrasymachus, the sophist who believes in power, rather than virtue.
使用Scattertext的术语频率可视化功能,我检查了在否定情绪句子中占主导地位的关键字。 垂直轴代表负类,水平轴代表中性类。 不出所料,被归类为“消极”的文本大部分是关于正义定义的论点的一部分。 他们的特色是与讨论不同角色有关的术语。 塞弗勒斯(Cephalus)是房子的老人,具有“老”和“年龄”的特征。 “敌人 ”和“朋友”描绘了波勒玛古鲁斯区分盟友和敌人的倾向。 “统治者”,“ 优势”和“效益”,是经常使用的斯拉斯马科斯,谁相信权力,而不是凭借着智者的话。

Judging from the abundant negativity within those dialogues, it seems that the various ideals of these characters were in direct conflict with Plato’s conception of justice. This is understandable as the purpose of Plato’s Republic was to radically transform conventional philosophy. Considering this context, I believe that the key players and their values identified by sentiment analysis; Cephalus, Polemarchus, and Thrasymachus; represent the traditional Athenian sources of authority. Therefore, Socrates’ process of disproving the suggested notions of justice could represent Plato’s attempt to exile traditional Athenian values from his philosophical odyssey towards justice.
从这些对话中大量的否定性来看,这些人物的各种理想似乎与柏拉图的正义观念直接冲突。 这是可以理解的,因为柏拉图共和国的目的是从根本上改变传统哲学。 考虑到这种情况,我认为通过情感分析可以确定关键参与者及其价值。 头颅,脊柱前肌和咽喉; 代表传统的雅典权威。 因此,苏格拉底反驳建议的正义概念的过程可能表示柏拉图试图将传统的雅典价值观从他的哲学旅程中流向正义。
To analyze the conflicting philosophies further, I manually assigned the name of the dominant speaker in the paragraph as a label to each sentence and visualized the dominant terms in each character’s dialogues.
为了进一步分析冲突的哲学,我手动将段落中占主导地位的发言人的名字分配给每个句子的标签,并在每个角色的对话中可视化占主导地位的术语。
Cephalus,常规 (Cephalus, the Conventional)
import spacy
import scattertext as st
import pandas as pd
dialogue_df = pd.read_csv('/mnt/d/nemo/philosophy_analysis/Plato/Plato\'s Republic/Plato\'s Republic - Book I - II/data/dialouge_data.csv', index_col=0)
nlp = spacy.load('en')
corpus = st.CorpusFromPandas(dialogue_df, category_col='speaker', text_col='text', nlp=nlp).build()
html = st.produce_scattertext_explorer(corpus, category='Thrasymachus',
category_name='Thrasymachus',
not_category_name='Other',
width_in_pixels=1000,
metadata=dialogue_df['speaker'])
open("Dialogue_Thrasymachus.html", 'wb').write(html.encode('utf-8'))The first subject of scrutiny is Cephalus, an elder who lives a moderate life owing to the wealth he has accumulated over the years. He is the owner of the household where Socrates’ inquiries take place. To Cephalus, justice is paying back what is owed, such as making sacrifices to the gods. The keywords dominating his dialogues are ‘old’ and ‘age’, which depicts Cephalus’ characteristics. Arguably, old age is the motivation behind Cephalus’ tendencies to serve the Homeric gods, since ageing would naturally induce the fear of death and afterlife.
审查的第一个对象是塞弗勒斯(Cephalus),他是长者,由于他多年来积累的财富而过着适度的生活。 他是进行苏格拉底询问的家庭的所有者。 对于Cephalus来说,正义正在偿还所欠的款项,例如向众神作出牺牲。 在他的对话中占主导地位的关键词是“老”和“年龄” ,这代表了凯法卢斯的特征。 可以说,老年是塞弗勒斯为荷马神服务的倾向的动力,因为衰老自然会引起人们对死亡和来世的恐惧。
Also, the term ‘money’ seems to describe the householder’s interest in bodily pleasures, as that is the subject he mainly discusses in The Republic. Judging from these aspects, Cephalus is the very embodiment of the convention, the everyman who’s main passion is money, and the comforts it brings. Not necessarily an immoral man, but certainly not a remarkable one.
另外, “金钱”一词似乎描述了住户对身体愉悦的兴趣,因为这是他在《共和国》中主要讨论的主题。 从这些方面来看,Cephalus正是公约的体现,每个人的主要激情在于金钱及其带来的舒适感。 不一定是不道德的人,但肯定不是杰出的人。
In light of this context, it becomes clear why Cephalus is excluded from the dialogue so early on. After being refuted by Socrates, Cephalus immediately excuses himself from the discussions. I believe that this scene could be interpreted as Socrates’ act of banishing the traditional Athenian values from his symposium.
鉴于这种情况,很清楚为什么这么早就将凯法卢斯排除在对话之外。 在被苏格拉底拒绝之后,塞弗勒斯立即成为讨论的原谅。 我认为,这一场景可以解释为苏格拉底从他的座谈会中驱逐了传统的雅典价值观的行为。
忠诚的波兰女皇 (Polemarchus, the Loyal)

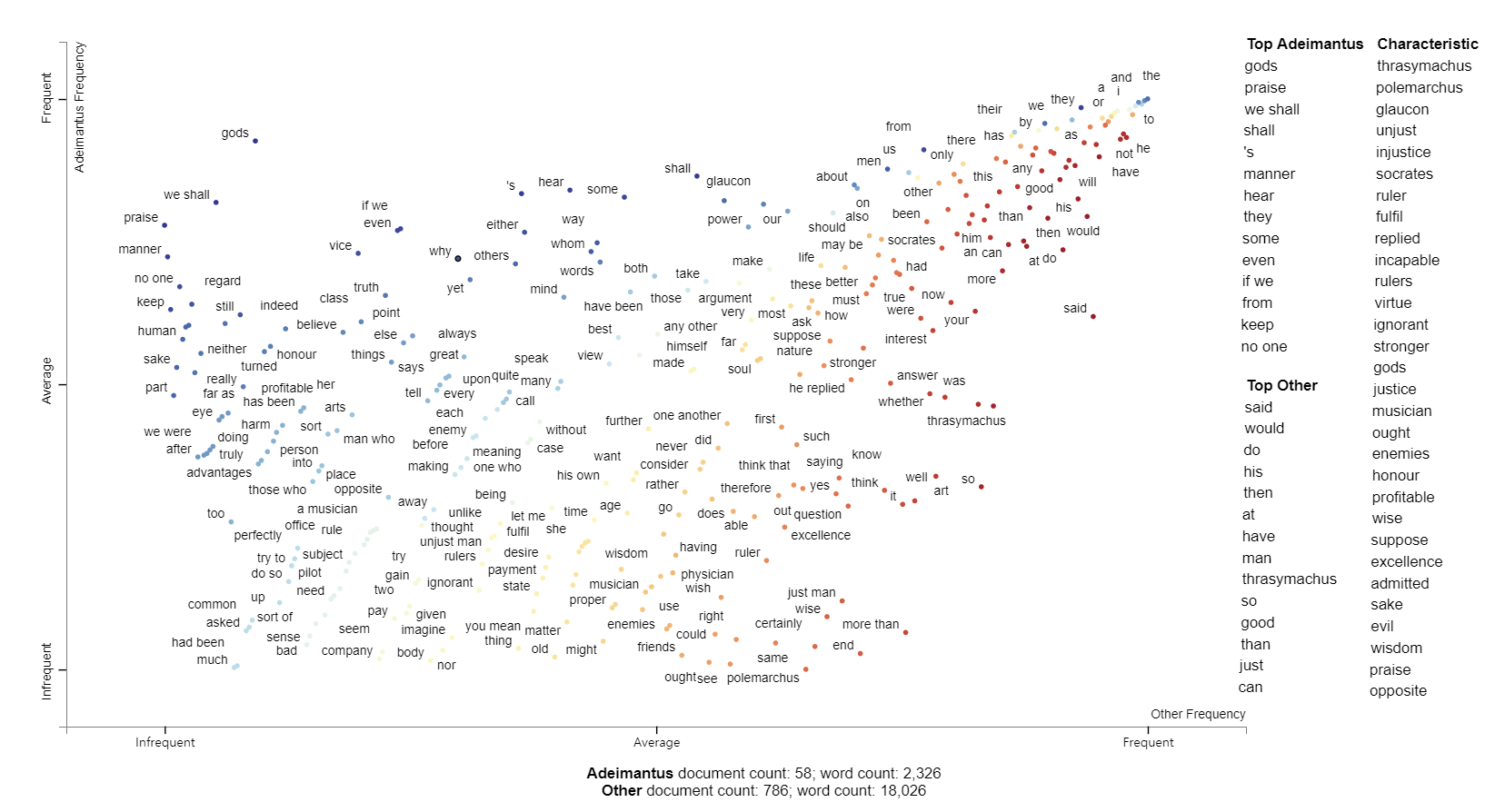
After Cephalus is chased away, the conversation then moves on to his son, the war-like Polemarchus. Unlike his father, who focused mainly on physical pleasures, Polemarchus shows himself concerned with defending the honour and safety of the polis. To Polimarchus, justice is doing good to friends and harm to enemies. The visualization keywords such as ‘friend’, ‘enemies’, and ‘harm’ depict this interpretation of justice as loyalty to one’s own.
赶走了Cephalus之后,谈话又转到了他的儿子,即战争似的Polemarchus。 与他的父亲主要专注于身体愉悦不同,波勒玛古斯表现出对捍卫大都会的荣誉和安全的关注。 对Polimarchus而言,正义对朋友有益,对敌人有害。 诸如“朋友” , “敌人”和“伤害”之类的可视化关键字将这种对正义的解释描述为对自己的忠诚。
Interestingly, both Cephalus and Polemarchus seem to embody the heroic virtues, a set of aristocratic values depicted by Greek heroes in epic poems such as The Iliad and The Odyssey. Mythological heroes such as Agamemnon, Achilles, and Odysseus strive to achieve wealth, status, and honour rather than moral order. Owing to these tendencies, I believe that the characters Cephalus and Polemarchus represent the Homeric values of traditional Athenian culture. Perhaps Plato is attacking the authority of poets such as Homer and Hesiod by refuting conceptions of justice based on their philosophies. In short, Plato is seeking the good life based on moral wisdom that is superior to mere heroic glory.
有趣的是,凯法卢斯(Cephalus)和波拉玛古斯(Polemarchus)似乎都体现了英勇美德,这是希腊英雄在史诗《伊利亚特》和《奥德赛》中所描绘的一系列贵族价值观。 阿伽门农,阿喀琉斯和奥德修斯等神话英雄努力争取财富,地位和荣誉,而不是道德秩序。 由于这些趋势,我相信Cephalus和Polemarchus这两个字符代表了传统雅典文化的荷马价值观。 也许柏拉图通过驳斥基于其哲学的正义观念来攻击荷马和赫希德等诗人的权威。 简而言之,柏拉图基于道德智慧寻求超越单纯英雄荣耀的美好生活。
蓟马 (Thrasymachus, the Amoral)

Among the various ideas presented by characters in Republic I~II, Thrasymachus’ conception of justice is perhaps the most nihilistic. The visualization keywords ‘ruler’, ‘interest’, and ‘stronger’ represent the sophist’s views on morality; that justice is nothing but the advantage of the stronger. In other words, he believes that there is no objective moral truth and the so-called ethical norms are established in a way that would only serve the ruler’s interest.
在共和国的一到二代人物提出的各种观念中,Thrasymachus的正义观念也许是最虚无的。 可视化关键字“ ruler” , “ interest”和“ stronger”表示苏菲派对道德的看法。 正义不过是强者的优势。 换句话说,他认为没有客观的道德真理,所谓的道德规范是以只会为统治者的利益服务的方式建立的。
This tendency to reject the existence of objective truth is a reference to the Sophists, the educators hired to tutor the wealthy on the skills of rhetoric. Since Athenian democracy usually gave power to those who are skilled at persuading the masses, rhetoric became an essential requirement for gaining political advantage in the public sphere. Similar to excluding the Homeric values from his discussions, Plato also seems to be criticizing the Sophists exploiting logic as a mere tool for high status, and furthermore, the flawed Athenian democracy that gave rise to such culture.
这种拒绝客观真理存在的倾向是对苏菲派的一种参考,索菲派是受雇为富人提供修辞技巧辅导的教育家。 由于雅典民主通常将权力赋予那些有能力说服群众的人,所以言辞成为在公共领域获得政治优势的必要条件。 类似于柏拉图在他的讨论中排除了荷马的价值观,柏拉图似乎也批评索菲斯主义者将逻辑仅当作获得高地位的工具,而且,有缺陷的雅典民主制度孕育了这种文化。
Glaucon和Adeimantus的挑战 (The Challenge of Glaucon and Adeimantus)

After Socrates disproves the conventional definitions of justice, the brothers Glaucon and Adeimantus challenges Socrates to present his own opinion on the matter. As characterized by the keywords ‘sake’ and ‘praise’, it is not enough for the brothers just to show that regarding justice as a means is wrong; they want to hear justice praised for its own sake.
在苏格拉底反对正义的传统定义之后,格劳Kong(Glaucon)和阿德曼特(Adeimantus)兄弟挑战苏格拉底就此事发表自己的看法。 以“ 缘故 ”和“ 赞美 ”为关键词,仅仅兄弟们就表明,将正义视为手段是错误的,这还不够。 他们想听到正义为自己而受到赞扬。
Glaucon goes on to demonstrate his inquiry by referring to the myth of Gyges and his magic ring. Owing to the ring that grants the power of invisibility to its bearer, Gyges is able to commit a series of heinous misdeeds and get away with it. Glaucon presents the question, “if one has the power to escape punishment, then what reason is left for him to pursue justice?” The word ‘Gyges’ isn’t explicitly displayed in the visualization results, but the term ‘power’ represents this story.
Glaucon继续通过提及Gyges神话和他的魔戒来证明他的询问。 由于赋予了其持有者隐形能力的那枚戒指,吉格斯能够犯下一系列令人发指的不法行为并摆脱它。 Glaucon提出了一个问题:“如果一个人有逃避惩罚的权力,那么他有什么理由去寻求正义呢?” 可视化结果中未明确显示“ Gyges”一词,但“ power ”一词代表了这个故事。
So, what is Socrates’ answer to this dilemma? Furthermore, through what means can society control those with such power? These questions pave the way to The Republic’s dialogue about Plato’s ideas of moral values and social mechanisms that could enforce them.
那么,苏格拉底对这个难题的回答是什么? 此外,社会可以通过什么方式控制有这种权力的人? 这些问题为共和国就柏拉图的道德价值观和可以实施道德观念的社会机制的对话铺平了道路。
我的想法 (My Thoughts)
I believe that my attempts at applying sentiment analysis to analyzing The Republic were quite successful. The detection of negative sentiments within the debates involving traditional values especially provided valuable insights into the nature of political philosophy. As the sentiment analysis result inform us, The Republic I~II mainly focuses on rejecting conventional ideas. While negativity rises due to these processes, this phenomenon is essential to paving the way for the establishment of Socratic values. Similar to Plato, almost every great thinkers, from Marx to Confucious, intended their ideas to become the cure for the fundamental problems dominating their respective eras. In Plato’s case, he was trying to replace the superficial and theatrical elements of Athenian culture with his thoughts on the moral truth. In short, this experience has led me to conclude that sentiment analysis could be of great assistance in pinpointing the conflict of ideologies within philosophical discussions and identifying the context of the emergence of one’s philosophy.
我相信我在将情感分析应用于分析《共和国》方面的尝试非常成功。 在涉及传统价值的辩论中发现负面情绪尤其为了解政治哲学的性质提供了宝贵的见解。 从情感分析结果可以看出,共和国I〜II主要集中于拒绝传统观念。 尽管消极情绪由于这些过程而上升,但这种现象对于为建立苏格拉底价值观铺平道路至关重要。 与柏拉图相似,从马克思到Kong子,几乎每一个伟大的思想家都希望他们的思想成为解决统治各自时代的基本问题的良方。 在柏拉图的案例中,他试图用他对道德真理的思想来代替雅典文化的表面和戏剧元素。 简而言之,这种经验使我得出结论,情感分析在指出哲学讨论中的意识形态冲突以及确定一个人的哲学出现的上下文方面可能会提供很大的帮助。
Tune in for further analyses of The Republic. Articles on Book II~V are scheduled for next week.
收看进一步分析《共和国》。 第二至第五卷的文章计划于下周发布。
Click here for the entire source code, and click here for my video on the subjects discussed in this article.

















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









