





 本文介绍了如何使用Python进行语义分析,特别是潜在语义分析(LSA),来发掘文档中的隐藏主题。通过这种方法,可以从文本数据中提取深层结构,帮助理解文本内容。
本文介绍了如何使用Python进行语义分析,特别是潜在语义分析(LSA),来发掘文档中的隐藏主题。通过这种方法,可以从文本数据中提取深层结构,帮助理解文本内容。
python语义分析
Discovering topics are very useful for various purposes such as for clustering documents, organizing online available content for information retrieval and recommendations. Various content providers and news agencies are using topic models for recommending articles to readers. Similarly recruiting firms are using in extracting job descriptions and mapping them with candidate skill set. If you see the data scientist job, which is all about extracting the ‘knowledge’ from a large amount of collected data. Mostly collected data is unstructured in nature. you need powerful tools and techniques to analyze and understand a large amount of unstructured data.
发现主题对于各种目的非常有用,例如用于将文档聚类,组织在线可用内容以进行信息检索和推荐。 各种内容提供商和新闻社都使用主题模型向读者推荐文章。 同样,招聘公司也正在使用中提取职位描述,并将其与候选技能集进行映射。 如果您看到数据科学家的工作,那就是从大量收集的数据中提取“知识”。 本质上,大多数收集的数据是非结构化的。 您需要强大的工具和技术来分析和理解大量的非结构化数据。
Topic modeling is a text mining technique that provides methods to identify co-occurring keywords to summarize large collections of textual information. It helps in discovering hidden topics in the document, annotate the documents with these topics, and organize a large amount of unstructured data.
主题建模是一种文本挖掘技术,它提供了一些方法来标识共同出现的关键字以汇总大量文本信息。 它有助于发现文档中的隐藏主题,使用这些主题对文档进行注释,以及组织大量非结构化数据。
In this tutorial, you will cover the following topics:
在本教程中,您将涵盖以下主题:
- What is Topic Modelling? 什么是主题建模?
- Comparison between text classification and topic modeling 文本分类和主题建模之间的比较
- Latent Semantic Analysis 潜在语义分析
- Implementing LSA in Python using Gensim 使用Gensim在Python中实现LSA
- Determine the optimum number of topics in a document 确定文档中的最佳主题数
- Pros and cons of LSA LSA的优缺点
- Use cases of Topic Modelling 主题建模的用例
- Conclusion 结论
For more such tutorials, projects, and courses visit DataCamp:
有关更多此类教程,项目和课程,请访问DataCamp :
主题建模 (Topic Modelling)
Topic Modelling automatically discovers the hidden themes from given documents. It is an unsupervised text analytics algorithm that is used for finding a group of words from the given document. These group of words represents a topic. There is a possibility that a single document can associate with multiple themes. for example, group words such as ‘patient’, ‘doctor’, ‘disease’, ‘cancer’, ad ‘health’ will represent the topic ‘healthcare’. Topic Modelling is a different game compared to rule-based text searching that uses regular expressions.
主题建模会自动发现给定文档中的隐藏主题。 它是一种无监督的文本分析算法,用于从给定文档中查找一组单词。 这些词组代表一个主题。 一个文档有可能与多个主题相关联。 例如,“患者”,“医生”,“疾病”,“癌症”,“健康”等组词将代表“医疗保健”主题。 与使用正则表达式的基于规则的文本搜索相比,主题建模是一种不同的游戏。
文本分类和主题建模之间的比较 (Comparison Between Text Classification and topic modeling)
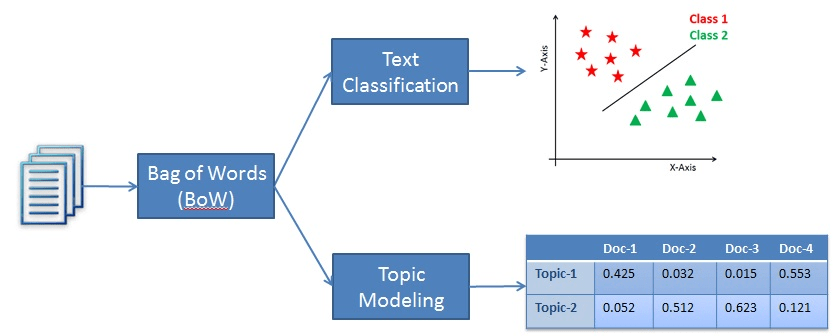
Text classification is a supervised machine learning problem, where a text document or article classified into a pre-defined set of classes. Topic modeling is the process of discovering groups of co-occurring words in text documents. These group co-occurring related words makes “topics”. It is a form of unsupervised learning so the set of possible topics are unknown. Topic modeling can be used to solve the text classification problem. Topic modeling will identify the topics presents in a document” while text classification classifies the text into a single class.
文本分类是有监督的机器学习问题,其中文本文档或文章分类为一组预定义的类。 主题建模是在文本文档中发现多组共同出现的单词的过程。 这些组共同出现的相关单词构成“主题”。 这是无监督学习的一种形式,因此可能的主题集是未知的。 主题建模可用于解决文本分类问题。 主题建模将识别文档中存在的主题”,而文本分类将文本分类为一个类。
潜在语义分析 (Latent Semantic Analysis)
LSA (Latent Semantic Analysis) also known as LSI (Latent Semantic Index) LSA uses a bag of word(BoW) model, which results in the term-document matrix (occurrence of terms in a document). rows represent terms and columns represent documents.LSA learns latent topics by performing a matrix decomposition on the document-term matrix using Singular value decomposition. LSA is typically used as a dimension reduction or noise-reducing technique.
LSA(潜在语义分析)也称为LSI(潜在语义索引)LSA使用单词袋(BoW)模型,这会生成术语文档矩阵(文档中术语的出现)。 行代表术语,列代表文档。LSA通过使用奇异值分解对文档术语矩阵执行矩阵分解来学习潜在主题。 LSA通常用作降维或降噪技术。

奇异值分解(SVD) (Singular Value Decomposition(SVD))
SVD is a matrix factorization method that represents a matrix in the product of two matrices. It offers various useful applications in signal processing, psychology, sociology, climate, and atmospheric science, statistics, and astronomy.
SVD是一种矩阵分解方法,表示两个矩阵乘积中的一个矩阵。 它在信号处理,心理学,社会学,气候和大气科学,统计和天文学方面提供了各种有用的应用程序。

- M is an m×m matrix M是一个m×m矩阵
- U is a m×n left singular matrix U是am×n左奇异矩阵
- Σ is a n×n diagonal matrix with non-negative real numbers. Σ是具有非负实数的x×对角矩阵。
- V is a m×n right singular matrix V是am×n右奇异矩阵
- V* is n×m matrix, which is the transpose of the V. V *是n×m矩阵,是V的转置。
Identity matrix: It is a square matrix in which all the elements of the principal diagonal are ones and all other elements are zeros.
单位矩阵:这是一个方矩阵,其中主对角线的所有元素均为1,所有其他元素均为0。
Diagonal Matrix: It is a matrix in which the entries other than the main diagonal are all zero.
对角矩阵:这是一个矩阵,其中除主对角线以外的所有条目均为零。
Singular Matrix: A matrix is singular if its determinant is 0.or A square matrix that does not have a matrix inverse.
奇异矩阵:如果矩阵的行列式为0,则为奇异矩阵;或者不具有矩阵逆的方矩阵。
确定最佳主题数 (Determining the optimum number of topics)
What is the best way to determine k (number of topics) in topic modeling? Identify the optimum number of topics in a given corpus text is a challenging task. We can use the following options for determining the optimum number of topics:
确定主题建模中的k(主题数)的最佳方法是什么? 在给定的语料库文本中确定最佳主题数是一项艰巨的任务。 我们可以使用以下选项来确定最佳主题数:
- One way to determine the optimum number of topics is to consider each topic as a cluster and find out the effectiveness of a cluster using the Silhouette coefficient. 确定最佳主题数的一种方法是将每个主题视为一个聚类,并使用Silhouette系数找出聚类的有效性。
- The topic coherence measure is a realistic measure for identifying the number of topics. 主题连贯性度量是用于识别主题数量的现实度量。
Topic Coherence measure is a widely used metric to evaluate topic models. It uses the latent variable models. Each generated topic has a list of words. In topic coherence measure, you will find the average/median of pairwise word similarity scores of the words in a topic. The high value of the topic coherence score model will be considered as a good topic model.
主题一致性度量是一种广泛用于评估主题模型的度量。 它使用潜在变量模型。 每个生成的主题都有一个单词列表。 在主题连贯性度量中,您将找到主题中单词的成对单词相似性得分的平均值/中位数。 主题连贯性评分模型的高价值将被视为良好的主题模型。
使用Gensim实施LSA (Implementing LSA using Gensim)
导入所需的库 (Import the required library)
#import modulesimport os.pathfrom gensim import corporafrom gensim.models import LsiModelfrom nltk.tokenize import RegexpTokenizerfrom nltk.corpus import stopwordsfrom nltk.stem.porter import PorterStemmerfrom gensim.models.coherencemodel import CoherenceModelimport matplotlib.pyplot as plt加载数据中 (Loading Data)
Let’s first create a data load function for loading articles.csv. You can download data from the following link:
首先,我们创建一个数据加载函数来加载article.csv。 您可以从以下链接下载数据:
def load_data(path,file_name):
"""
Input : path and file_name
Purpose: loading text file
Output : list of paragraphs/documents and
title(initial 100 words considred as title of document)
"""
documents_list = []
titles=[]
with open( os.path.join(path, file_name) ,"r") as fin:
for line in fin.readlines():
text = line.strip()
documents_list.append(text)
print("Total Number of Documents:",len(documents_list))
titles.append( text[0:min(len(text),100)] )
return documents_list,titles预处理数据 (Preprocessing Data)
After data loading function, you need to preprocess the text. The following steps are taken to preprocess the text:
加载数据后,需要对文本进行预处理。 采取以下步骤对文本进行预处理:
- Tokenize the text articles 标记文本文章
- Remove stop words 删除停用词
- Perform stemming on text article 对文本文章执行词干
def preprocess_data(doc_set):
"""
Input : docuemnt list
Purpose: preprocess text (tokenize, removing stopwords, and stemming)
Output : preprocessed text
"""
# initialize regex tokenizer
tokenizer = RegexpTokenizer(r'\w+')
# create English stop words list
en_stop = set(stopwords.words('english'))
# Create p_stemmer of class PorterStemmer
p_stemmer = PorterStemmer()
# list for tokenized documents in loop
texts = []
# loop through document list
for i in doc_set:
# clean and tokenize document string
raw = i.lower()
tokens = tokenizer.tokenize(raw)
# remove stop words from tokens
stopped_tokens = [i for i in tokens if not i in en_stop]
# stem tokens
stemmed_tokens = [p_stemmer.stem(i) for i in stopped_tokens]
# add tokens to list
texts.append(stemmed_tokens)
return textsThe next step is to prepare the corpus. Here, you need to create a document term matrix and dictionary of terms.
下一步是准备语料库。 在这里,您需要创建一个文档术语矩阵和术语词典。
def prepare_corpus(doc_clean):
"""
Input : clean document
Purpose: create term dictionary of our courpus and Converting list of documents (corpus) into Document Term Matrix
Output : term dictionary and Document Term Matrix
"""
# Creating the term dictionary of our courpus, where every unique term is assigned an index. dictionary = corpora.Dictionary(doc_clean)
dictionary = corpora.Dictionary(doc_clean)
# Converting list of documents (corpus) into Document Term Matrix using dictionary prepared above.
doc_term_matrix = [dictionary.doc2bow(doc) for doc in doc_clean]
# generate LDA model
return dictionary,doc_term_matrix使用Gensim创建LSA模型 (Create an LSA model using Gensim)
After corpus creation, you can generate a model using LSA.
创建语料库后,您可以使用LSA生成模型。
def create_gensim_lsa_model(doc_clean,number_of_topics,words):
"""
Input : clean document, number of topics and number of words associated with each topic
Purpose: create LSA model using gensim
Output : return LSA model
"""
dictionary,doc_term_matrix=prepare_corpus(doc_clean)
# generate LSA model
lsamodel = LsiModel(doc_term_matrix, num_topics=number_of_topics, id2word = dictionary) # train model
print(lsamodel.print_topics(num_topics=number_of_topics, num_words=words))
return lsamodel确定主题数 (Determine the number of topics)
Another extra step needs to taken to optimize results by identifying the optimum number of topics. Here, you will generate a coherence score to determine an optimum number of topics.
需要通过确定最佳主题数来采取另一个额外步骤来优化结果。 在这里,您将生成一个连贯分数来确定最佳主题数。
def compute_coherence_values(dictionary, doc_term_matrix, doc_clean, stop, start=2, step=3):
"""
Input : dictionary : Gensim dictionary
corpus : Gensim corpus
texts : List of input texts
stop : Max num of topics
purpose : Compute c_v coherence for various number of topics
Output : model_list : List of LSA topic models
coherence_values : Coherence values corresponding to the LDA model with respective number of topics
"""
coherence_values = []
model_list = []
for num_topics in range(start, stop, step):
# generate LSA model
model = LsiModel(doc_term_matrix, num_topics=number_of_topics, id2word = dictionary) # train model
model_list.append(model)
coherencemodel = CoherenceModel(model=model, texts=doc_clean, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_valuesLet’s plot coherence score values
让我们绘制连贯性得分值
def plot_graph(doc_clean,start, stop, step):
dictionary,doc_term_matrix=prepare_corpus(doc_clean)
model_list, coherence_values = compute_coherence_values(dictionary, doc_term_matrix,doc_clean,
stop, start, step)
# Show graph
x = range(start, stop, step)
plt.plot(x, coherence_values)
plt.xlabel("Number of Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence_values"), loc='best')
plt.show()start,stop,step=2,12,1plot_graph(clean_text,start,stop,step)
You can easily evaluate this graph. Here, you have a number of topics on the X-axis and a coherence score on the Y-axis. The number of topics 7 has the highest coherence score, so the optimum number of topics is 7.
您可以轻松评估此图。 在这里,您在X轴上有很多主题,在Y轴上有一个连贯性得分。 主题数7具有最高的连贯性得分,因此最佳主题数是7。
运行以上所有功能 (Run all the above functions)
# LSA Model
number_of_topics=7
words=10
document_list,titles=load_data("","articles.txt")
clean_text=preprocess_data(document_list)
model=create_gensim_lsa_model(clean_text,number_of_topics,words)Output:Total Number of Documents: 4551
[(0, '0.361*"trump" + 0.272*"say" + 0.233*"said" + 0.166*"would" + 0.160*"clinton" + 0.140*"peopl" + 0.136*"one" + 0.126*"campaign" + 0.123*"year" + 0.110*"time"'), (1, '-0.389*"citi" + -0.370*"v" + -0.356*"h" + -0.355*"2016" + -0.354*"2017" + -0.164*"unit" + -0.159*"west" + -0.157*"manchest" + -0.116*"apr" + -0.112*"dec"'), (2, '0.612*"trump" + 0.264*"clinton" + -0.261*"eu" + -0.148*"say" + -0.137*"would" + 0.135*"donald" + -0.134*"leav" + -0.134*"uk" + 0.119*"republican" + -0.110*"cameron"'), (3, '-0.400*"min" + 0.261*"eu" + -0.183*"goal" + -0.152*"ball" + -0.132*"play" + 0.128*"said" + 0.128*"say" + -0.126*"leagu" + 0.122*"leav" + -0.122*"game"'), (4, '0.404*"bank" + -0.305*"eu" + -0.290*"min" + 0.189*"year" + -0.164*"leav" + -0.153*"cameron" + 0.143*"market" + 0.140*"rate" + -0.139*"vote" + -0.133*"say"'), (5, '0.310*"bank" + -0.307*"say" + -0.221*"peopl" + 0.203*"trump" + 0.166*"1" + 0.164*"min" + 0.163*"0" + 0.152*"eu" + 0.152*"market" + -0.138*"like"'), (6, '0.570*"say" + 0.237*"min" + -0.170*"vote" + 0.158*"govern" + -0.154*"poll" + 0.122*"tax" + 0.115*"statement" + 0.115*"bank" + 0.112*"budget" + -0.108*"one"')]Topic-1: “trump”, “say”, “said”, “would”, “clinton”, “peopl”, “one”, “campaign”,”year”,”time”’ (US Presidential Elections)
主题-1 :“王牌”,“说”,“说”,“将”,“克林顿”,“人”,“一个”,“竞选”,“年”,“时间”'( 美国总统选举 )
Topic-2: “citi”, “v”, “h”, “2016”, “2017”,”unit”, “west”, “manchest”, ”apr” ,”dec”’(English Premier League)
主题2 :“ citi”,“ v”,“ h”,“ 2016”,“ 2017”,“ unit”,“ west”,“ manchest”,“ apr”,“ dec”'( 英超 )
Topic-3: “trump”,”clinton”, “eu”,”say”,”would”,”donald”,”leav”,”uk” , ”republican” ,”cameron”(US Presidential Elections, Brexit)
主题三 :“王牌”,“克林顿”,“欧盟”,“说”,“将”,“唐纳德”,“利夫”,“英国”,“共和党人”,“卡梅伦”( 美国总统大选,英国退欧 )
Topic-4: “min”,”eu”,”goal”,”ball”,”play”,”said”,”say”,”leagu”,”leav”, ”game”(English Premier League)
主题4 :“最小”,“欧盟”,“目标”,“球”,“比赛”,“说”,“说”,“利古”,“离开”,“比赛”( 英超 )
Topic-5: “bank”,”eu”,”min”,”year”,”leav”,”cameron”,”market”,”rate”, ”vote”,”say” (Brexit and Market Condition)
议题5 :“银行”,“欧盟”,“最低”,“年”,“最低”,“喀麦隆”,“市场”,“利率”,“投票”,“说”( 英国脱欧和市场状况 )
Topic-6: “bank”,”say”,”peopl”,”trump”,”1" ,”min” ,”eu”,”market” , ”like”(Plitical situations and market conditions)
主题六 :“银行”,“说”,“人”,“王牌”,“ 1”,“最小”,“欧盟”,“市场”,“喜欢”( 政治情况和市场条件 )
Topic-7: “say”,”min”,”vote”,”govern”,”poll”,”tax”,”statement”, ”bank”,”budget”,”one”(US Presidential Elections and Financial Planning)
主题7 :“说”,“最小”,“投票”,“政府”,“民意测验”,“税”,“声明”,“银行”,“预算”,“一个”( 美国总统选举和财务计划 )
Here, 7 Topics were discovered using Latent Semantic Analysis. Some of them are overlapping topics. For Capturing multiple meanings with higher accuracy we need to try LDA( latent Dirichlet allocation). I will leave this as an exercise for you, try it out using Gensim, and share your views.
在这里,使用潜在语义分析发现了7个主题。 其中一些是重叠的主题。 为了更准确地捕获多个含义,我们需要尝试使用LDA(潜在Dirichlet分配)。 我将把它留给您练习,使用Gensim进行尝试,并分享您的观点。
LSA的优缺点 (Pros and Cons of LSA)
LSA algorithm is the simplest method that is easy to understand and implement. It also offers better results compared to the vector space model. It is faster compared to other available algorithms because it involves document term matrix decomposition only.
LSA算法是最容易理解和实现的最简单方法。 与向量空间模型相比,它还提供了更好的结果。 与其他可用算法相比,它更快,因为它仅涉及文档术语矩阵分解。
The latent topic dimension depends upon the rank of the matrix so we can’t extend that limit. LSA decomposed matrix is a highly dense matrix so It is difficult to index individual dimensions. LSA unable to capture the multiple meanings of words. It is not easier to implement compared to LDA( latent Dirichlet allocation). It offers lower accuracy than LDA.
潜在主题的维度取决于矩阵的等级,因此我们无法扩展该限制。 LSA分解矩阵是高度密集的矩阵,因此很难为各个维度建立索引。 LSA无法捕获单词的多种含义。 与LDA(潜在Dirichlet分配)相比,实现起来并不容易。 它提供的精度低于LDA。
主题建模的用例 (Use-Cases of Topic Modelling)
Simple applications in which this technique is used are documented clustering in text analysis, recommender systems, and information retrieval. More detailed use-cases of topic modeling are:
使用此技术的简单应用程序是文本分析,推荐系统和信息检索中记录的群集。 主题建模的更详细用例是:
- Resume Summarization: It can help recruiters to evaluate resumes by a quick glance. They can reduce the effort in filtering a pile of resumes. 简历概述:它可以帮助招聘人员快速浏览简历。 他们可以减少筛选一堆简历的工作量。
- Search Engine Optimization: online articles, blogs, and documents can be tag easily by identifying the topics and associated keywords, which can improve optimize search results. 搜索引擎优化:通过识别主题和关联的关键字,可以轻松标记在线文章,博客和文档,从而可以优化搜索结果。
- Recommender System Optimization: recommender systems act as an information filter and advisor according to the user profile and previous history. It can help us to discover unvisited relevant content based on past visits. 推荐系统优化:推荐系统根据用户个人资料和以前的历史记录充当信息过滤器和顾问。 它可以帮助我们根据过去的访问来发现未访问的相关内容。
- Improving Customer Support: Discovering relevant topics and associated keywords in customer complaints and feedback for example product and service specifications, department, and branch details. Such information helps the company to directly rotated the complaint in the respective department. 改善客户支持:发现客户投诉和反馈中的相关主题和关联的关键字,例如产品和服务规格,部门和分支机构的详细信息。 此类信息有助于公司直接在相应部门中轮换投诉。
- In the healthcare industry, topic modeling can help us to extract useful and valuable information from unstructured medical reports. This information can be used for the patient’s treatment and medical science research purposes. 在医疗保健行业中,主题建模可以帮助我们从非结构化医疗报告中提取有用和有价值的信息。 该信息可用于患者的治疗和医学科学研究目的。
结论 (Conclusion)
In this tutorial, you covered a lot of details about Topic Modeling. you have learned what is the Topic Modeling, what is Latent Semantic Analysis, how to build respective models, how topics generated using LSA. Also, you covered some basic concepts such as the Singular Value Decomposition, topic coherence score.
在本教程中,您涵盖了有关主题建模的许多详细信息。 您已经了解了什么是主题建模,什么是潜在语义分析,如何构建各自的模型,如何使用LSA生成主题。 此外,您还介绍了一些基本概念,例如奇异值分解,主题一致性得分。
Hopefully, you can now utilize topic modeling to analyze your own datasets. Thanks for reading this tutorial!
希望您现在可以利用主题建模来分析自己的数据集。 感谢您阅读本教程!
For more such tutorials, projects, and courses visit DataCamp:
有关更多此类教程,项目和课程,请访问DataCamp :
Originally published at https://www.datacamp.com/community/tutorials/discovering-hidden-topics-python
最初发布在https://www.datacamp.com/community/tutorials/discovering-hidden-topics-python
Reach out to me on Linkedin: https://www.linkedin.com/in/avinash-navlani/
在Linkedin上与我联系: https : //www.linkedin.com/in/avinash-navlani/
python语义分析















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









