




主题模型
顾名思义,主题模型用来探寻文本背后所隐藏的主题,也可以理解为一种段落语义的挖掘。相比于TF-IDF只能从个体词汇层面给予我们文本内容的提示,主题模型能够从更宏观的角度帮助我们快速捕捉文本的核心语义。
LDA建模思路
LDA是一种比较流行的主题模型,由吴恩达等人在2003年首次提出。它可以将文档集中每篇文章的主题以概率分布的形式给出,比如,我们可以从结果找选出概率最大的5个主题作为该文档的主题描述。下面我们来快速理解一下LDA的基本建模思路。(因为LDA背后涉及大量的数学知识,如果大家想对数学细节做更进一步的理解,可以阅读这篇文章以及这篇文章)
LDA假设我们生成某个文本的方式如下:
0.我们首先给定我们需要的topic数目K,并根据Poisson分布来采样确定文档长度N
1.从给定超参数𝛼(K维向量)的Dirichlet分布中得到θ,也就是当前文档主题的多项式分布的参数
2.for i in range(N):{
a)基于1中得到的以θ为参数的多项式分布采样得到一个topic z
b)基于采样得到的topic z对应的词分布(这里还需要通过给定超参数β的Dirichlet分布来得到词分布w,换句话说,词分布w由topic z以及超参数β共同决定)采样得到词w_i
}
补充说明:超参数β是一个V维的向量,其中V代表词汇表里所有词的个数。
这里再对上面的两个超参数做一些说明:
注意的是无论是𝛼或是β均为语料库级别的超参数,也就是对于语料库中的每一个文本都是一样的
𝛼可以理解为topic prior,当𝛼越小时(比如1),主题的分布越陡峭,反之当𝛼比较大时,各个主题的分布趋于平均,各个主题出现的概率比较均等。
β可以理解为word prior,当β越小时(比如0.01),词的分布越陡峭,也就是对于当前的topic,能够以比较高概率出现的词十分有限,topic-specific。
下面这张图清晰地呈现出上面我所说的文本生成步骤。
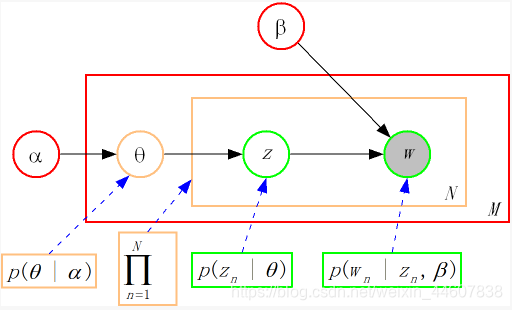
LDA模型训练
现在我们已经有了模型也有语料数据,接下来我们来考虑如何通过数据来训练我们的模型。首先我们来明确一下我们的训练目标,我们已知的是语料和先验超参数𝛼和β,需要求解的是主题分布θ和词分布w。
在求解LDA时,我们主要使用的两种方法是Gibbs Sampling和EM 算法。这里对Gibbs Sampling求解LDA做简单的介绍。
1.首先我们选择合适的主题数K,以及超参数𝛼和β。
2.对于语料库中的每一篇文档中的每一个词,随机赋予一个主题编号z。
3.重新扫描每一个词,根据Gibbs采样的条件概率公式p(zi=k|语料,z-i)来重新采样该词的主题编号,并将其更新到语料库中。
4.不断重复步骤3直到Gibbs采样收敛。
5.最后统计收敛后的语料库的主题情况,对于每个文档,统计该文档中每个词的主题,得到该文档的主题分布θ,统计语料库中每个词的主题,得到LDA每个主题的词分布w。
然后我们再来思考一下,当我们已经完成训练后,面对一篇新的文档时,如何得到该文档的主题分布呢?首先,考虑到我们的模型已定,则LDA各个主题的词分布已经确定,我们需要的只是文档的主题分布。算法如下
1.对于当前文档的每一个词,随机赋予一个主题编号z。
2.重新扫描当前文档,对于每一个词,采用Gibbs采样公式更新主题编号。
3.不断重复步骤2直到Gibbs采样收敛。
4.统计文档中各个词的主题情况,得到该文档的主题分布。
在使用Gibbs Sampling求解LDA模型时,最重要的是得到Gibbs采样的条件概率公式。关于如何推导以及具体的形式,大家可以参考这篇博文Gibbs采样算法求解LDA
关于如何使用EM算法求解,大家可以参考这篇文章变分推断EM算法求解LDA
LDA模型评估
现在我们已经完成了模型的构建以及训练,那么下一步当然是评估模型的效果。一个非常基本的思路就是拿我们训练好的LDA模型在其他文本集上来测试一下,来看一下得到的topic是否足够的self-explanatory。事实上利用python运行LDA模型(基于gensim库)得到的结果,其呈现形式是: 对于每一个topic, 都会产生一系列关键词并且赋予权重,用来代表这个指定的topic。一般我们会选概率最大的5个关键词作为这个topic的代表。现在我们假设我们就拿这5个词作为topic代表,那么在什么情况下,表示得到的结果足够好呢?非常符合直觉的想法是这5个词的语义足够接近,比如对于第一个topic, 5个词分别是 ‘BLEU, Bert, encoder, decoder, transformer’,那么我们能够比较清晰地推断出这个topic是关于机器翻译的。如果我们将其中一个词随机替换为一个外来词比如apple,那么从人类的理解中很容易把这个外来词从它们当中找出来,因为剩下词的语义足够接近或者语义足够连贯。那么现在的问题就是我们如何来量化这个所谓的语义连贯指标呢?
在Python中,gensim模块已经为我们提供了这个接口CoherenceModel。用来评估某个LDA模型的效果。事实上,这个指标是十分重要的,因为它可以帮助我们来选出最优的主题数K:通过比较不同K下模型在测试集上的topic coherence表现,我们可以选取最优的K。
关于topic coherence的具体计算过程,大致上可以分为以下四步:
1.Segmentation 2.Probability Estimation 3.Confirmation Measure 4.Aggregation
下面是原文中的概括性描述

在具体的计算过程中,作者提出了一些非常漂亮的想法,比如在confirmation measure时,避免直接计算两个词的共现概率,而是采用文本中的其他词y来间接度量x和z的语义相关性,避免x和z在语义上相互支撑但是却没有在一篇文档中共同出现导致measure underestimation 的情况。具体的话,希望大家还是去阅读一下原paper来加深对topic coherence的理解。
基于Amazon Reviews的LDA实战
说了这么多,接下来我们就开始实战。用到的语料库是Amazon上的关于食品的reviews。整个数据集还是蛮大的,我从中选取5个年份2004,2006,2008,2010,2012,每个年份选取20000条评论作为语料。目标是通过主题模型来比较5个年份里评论中隐含的主题的差异并希望获得某些insights。OK,我们开始!
1.导入一些基础包
import pandas as pd
import string
import spacy
import os
import re
from nltk.corpus import stopwords
stop=set(stopwords.words('english'))
nlp=spacy.load('en')
2.文本预处理
data=pd.read_csv('Reviews_food.csv')
limit=20000
data_2012=data[1342972224<data.Time][:limit]
data_2010=data[(data.Time>1326497472)&(data.Time<1334734848)][:limit]
data_2008=data[(data.Time>1310022720)&(data.Time<1318260096)][:limit]
data_2006=data[(data.Time>1293547968)&(data.Time<1301785344)][:limit]
data_2004=data[(data.Time>1277073216)&(data.Time<1285310592)][:limit]
def preprocess(text):
text=re.sub(r"i'm","i am",text)
text=re.sub(r"I'm","I am",text)
text=re.sub(r"he's","he is",text)
text=re.sub(r"He's","He is",text)
text=re.sub(r"she's","she is",text)
text=re.sub(r"SHe's","She is",text)
text=re.sub(r"that's","that is",text)
text=re.sub(r"this's","this is",text)
text=re.sub(r"it's","it is",text)
text=re.sub(r"here's","here is",text)
text=re.sub(r"what's","what is",text)
text=re.sub(r"where's","where is",text)
text=re.sub(r"who's","who is",text)
text=re.sub(r"how's","how is",text)
text=re.sub(r"let's","let us",text)
text=re.sub(r"That's","That is",text)
text=re.sub(r"This's","This is",text)
text=re.sub(r"It's","It is",text)
text=re.sub(r"Here's","Here is",text)
text=re.sub(r"What's","What is",text)
text=re.sub(r"Where's","Where is",text)
text=re.sub(r"Who's","Who is",text)
text=re.sub(r"How's","How is",text)
text=re.sub(r"Let's","Let us" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2188
2188





 到【灌水乐园】发言
到【灌水乐园】发言







