






In the last few years, web scraping has been one of my day to day and frequently needed tasks. I was wondering if I can make it smart and automatic to save lots of time. So I made AutoScraper!
在过去的几年中,Web抓取一直是我的日常工作之一,也是经常需要执行的任务。 我想知道是否可以使其变得智能且自动以节省大量时间。 所以我做了AutoScraper!
The project code is available here. It became the number one trending project on Github.
项目代码可在此处获得 。 它成为Github上排名第一的趋势项目。
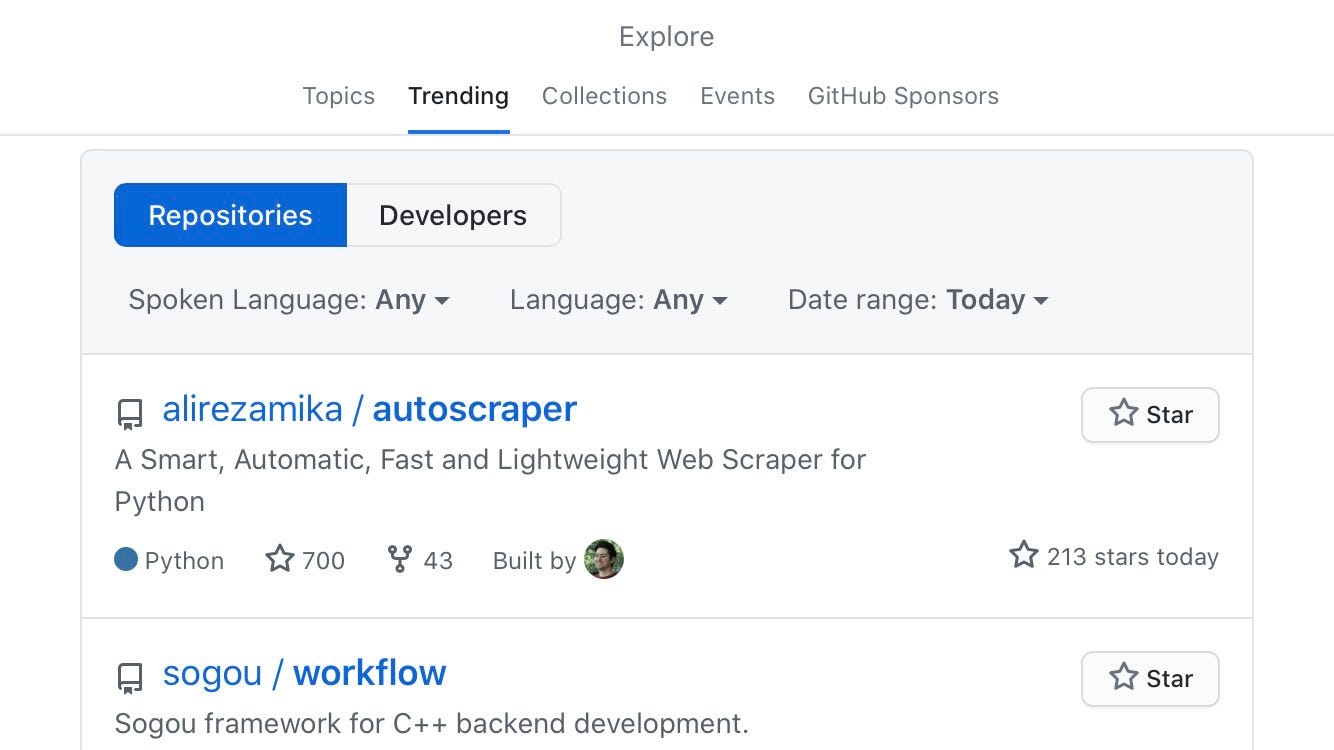
This project is made for automatic web scraping to make scraping easy. It gets a URL or the HTML content of a web page and a list of sample data that we want to scrape from that page. This data can be text, URL, or any HTML tag value of that page. It learns the scraping rules and returns similar elements. Then you can use this learned object with new URLs to get similar content or the exact same element of those new pages.
该项目专为自动刮刮而设计,使刮刮变得容易。 它
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









