






 bigbird丁鹏Last year, BERT was released by researchers at Google, which proved to be one of the efficient and most effective algorithm changes since RankBrain. Looking at the initial results, BigBird is...
bigbird丁鹏Last year, BERT was released by researchers at Google, which proved to be one of the efficient and most effective algorithm changes since RankBrain. Looking at the initial results, BigBird is...
bigbird丁鹏
Last year, BERT was released by researchers at Google, which proved to be one of the efficient and most effective algorithm changes since RankBrain. Looking at the initial results, BigBird is showing similar signs!
去年,BERT被Google研究人员发布,这被证明是自RankBrain以来最有效,最有效的算法更改之一。 观察初步结果,BigBird表现出相似的迹象!
In this article, I’ve covered:
在本文中,我介绍了:
- A brief overview of Transformers-based Models, 基于变压器的模型的简要概述,
- Limitations of Transformers-based Models, 基于变压器的模型的局限性
- What is BigBird, and 什么是BigBird,以及
- Potential applications of BigBird. BigBird的潜在应用。
Let’s begin!
让我们开始!
基于变压器的模型的简要概述 (A Brief Overview of Transformers-Based Models)
Natural Language Processing (NLP) has improved quite drastically over the past few years and Transformers-based Models have a significant role to play in this. Still, there is a lot to uncover.
在过去的几年中,自然语言处理(NLP)取得了巨大的进步,基于变压器的模型在其中发挥着重要作用。 尽管如此,仍有很多发现。
Transformers — a Natural Language Processing Model launched in 2017, are primarily known for increasing the efficiency of handling & comprehending sequential data for tasks like text translation & summarization.
变形金刚—一种于2017年推出的自然语言处理模型,主要以提高处理和理解诸如文本翻译和摘要之类的任务的顺序数据的效率而闻名。
Unlike Recurrent Neural Networks (RNNs) that process the beginning of input before its ending, Transformers can parallelly process input and thus, significantly reduce the complexity of computation.
与递归神经网络(RNN)在输入结束之前处理输入的开始不同,变形金刚可以并行处理输入,因此可以显着降低计算的复杂性。
BERT, one of the biggest milestone achievements in NLP, is an open-sourced Transformers-based Model. A paper introducing BERT, like BigBird, was published by Google Researchers on 11th October 2018.
BERT是NLP的最大里程碑成就之一,它是一个基于Transformers的开源模型。 Google研究人员于2018年10月11日发表了一篇介绍BERT的论文 ,例如BigBird。
Bidirectional Encoder Representations from Transformers (BERT) is one of the advanced Transformers-based models. It is pre-trained on a huge amount of data (pre-training data sets) with BERT-Large trained on over 2500 million words.
变压器的双向编码器表示(BERT)是基于变压器的高级模型之一。 它经过大量数据的预训练(预训练数据集),而BERT-Large则接受了超过25亿个单词的训练。
Having said that, BERT, being open-sourced, allowed anyone to create their own question answering system. This too contributed to its wide popularity.
话虽如此,BERT是开源的,它允许任何人创建自己的问题回答系统。 这也为它的广泛普及做出了贡献。
But BERT is not the only contextual pre-trained model. It is, however, deeply bidirectional, unlike other models. This is also one of the reasons for its success and diverse applications.
但是BERT并不是唯一的上下文预训练模型。 但是,它是双向的,与其他模型不同。 这也是其成功和多样化应用的原因之一。
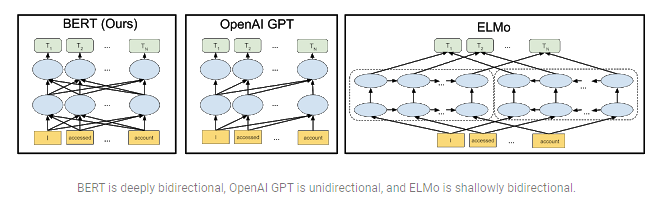
The results of this pre-trained model are definitely impressive. It was successfully adopted for many sequence-based tasks such as summarization, translation, etc. Even Google adopted BERT for understanding the search queries of
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2371
2371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









