





 本文对比了亚马逊的Textract服务与开源的Tesseract OCR在OCR(光学字符识别)和NLP(自然语言处理)应用中的表现。通过案例分析,探讨两者在文本提取和识别准确率上的差异。
本文对比了亚马逊的Textract服务与开源的Tesseract OCR在OCR(光学字符识别)和NLP(自然语言处理)应用中的表现。通过案例分析,探讨两者在文本提取和识别准确率上的差异。
textract
What is OCR anyway and why the buzz? Artificial Intelligence (AI) enables entities with Human Intelligence (us) process data at a large scale — faster and cheaper. Unarguably, a large portion of data is saved digitally- easy to read and analyze. However there is a significant portion of data that is stored in physical documents — both type written and hand-written. How to analyze this category of data. This is where fascinating technology of Optical Character Recognition (OCR) comes in. Using OCR you are able to convert documents into text format of data suitable for editing and searching. This is what OCR is able to do.
无论如何,OCR是什么?为什么嗡嗡声? 人工智能(AI)使具有人类智能(us)的实体能够更快,更便宜地大规模处理数据。 毫无疑问,很大一部分数据都是数字保存的,易于读取和分析。 但是,有很大一部分数据存储在物理文档中-包括书面形式和手写形式。 如何分析此类数据。 这就是引人入胜的光学字符识别(OCR)技术的来源。使用OCR,您可以将文档转换为适合编辑和搜索的数据文本格式。 这就是OCR能够做到的。

In the article we will focus on two well know OCR frameworks:
在本文中,我们将重点介绍两个众所周知的OCR框架:
Tesseract OCR — free software, released under the Apache License, Version 2.0 - development has been sponsored by Google since 2006.
Tesseract OCR是一种免费软件,根据Apache许可证2.0版发布,自2006年以来一直由Google赞助。
Amazon Textract OCR — fully managed service from Amazon, uses machine learning to automatically extract text and data
Amazon Textract OCR —来自Amazon的完全托管服务,使用机器学习自动提取文本和数据
We will compare the OCR capabilities of these two frameworks. Let's start by a simple image as below:
我们将比较这两个框架的OCR功能。 让我们从一个简单的图像开始,如下所示:

$ git clone https://github.com/mkukreja1/blogs.gitDownload and Install Notebook blogs/ocr/OCR.ipynb
下载并安装Notebook博客/ocr/OCR.ipynb
!pip install opencv-python
!pip install pytesseract
!pip install pyenchantimport cv2
import pytesseract
import re
from pytesseract import Outputimg_typewritten = cv2.imread('typewritten.jpg')
custom_config = r'--oem 3 --psm 6'
txt_typewritten=pytesseract.image_to_string(img_typewritten, config=custom_config)
print(txt_typewritten)OCR Output using Tesseract OCR:
使用Tesseract OCR的OCR输出:
BEST PICTURE FORD V FERRARITHE IRISHMANJOJO RABBITJOKERLITTLE WOMENMARRIAGE STORY1917ONCE UPON A TIME…IN HOLLYWOODPARASITE
最佳影片FORD V FERRARITHE IRISHMANJOJO RABBITJOKERLITTLE女子婚姻故事1917年一次…在好莱坞寄生虫中
OCR Output using Amazon Textract OCR:
使用Amazon Textract OCR的OCR输出:
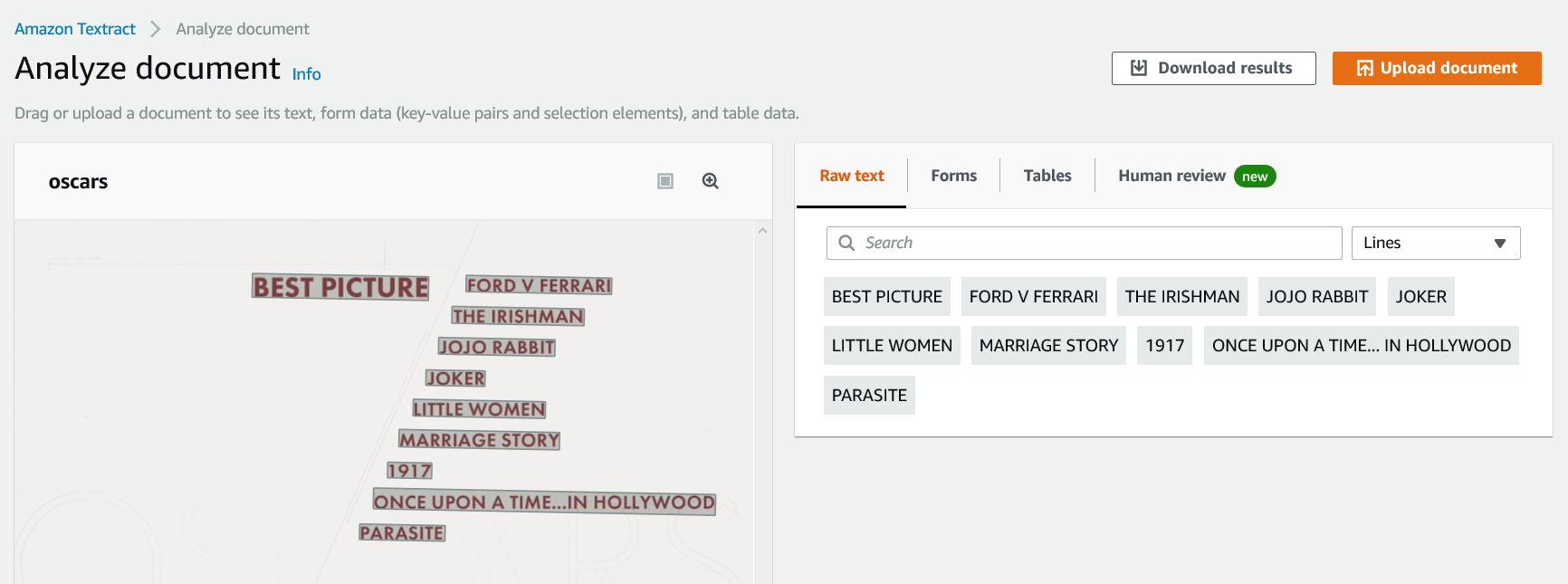
Both frameworks performed exactly the same. Lets see how handwritten text compares.
两个框架的执行情况完全相同。 让我们看一下手写文本的比较。

img_handwritten = cv2.imread('handwritten.jpg')
txt_handwritten=pytesseract.image_to_string(img_handwritten)
print(txt_handwritten)OCR Output using Tesseract OCR:
使用Tesseract OCR的OCR输出:
<>
<>
mhassadeyVWENS YEA) sore
mhassadeyVYENS YEA)疮
&&. a)OW!NS anéLp Real Estate Group
&&。 OW!NSanéLp房地产集团
RKSHIRE | AmbassadorH ATH. AWAY | Real EstatelomeServices
RKSHIRE | ATH大使。 离开房地产服务
Ky Ie,aa Nim So mul for meetWith me today | Ht wis qed CatchingWp and Vin glad 10 hear Mk Ke wellfor bu. | Lovie Brwoud 10 Seeing YouAA aiv Go| Cheers|
Ky Ie,aa Nim So mul今天与我见面| Ht wis qed CatchingWp和Vin很高兴10听到Mk Ke wellfor bu。 | Lovie Brwoud 10看到YouAA aiv Go | 干杯|
Megan Owens, Realtor 402–689–4984 www.ForSalebyMegan.
梅根·欧文斯(Megan Owens),房地产经纪人402–689–4984 www.ForSalebyMegan 。
MMS
彩信
com
com
OCR Output using Amazon Textract OCR:
使用Amazon Textract OCR的OCR输出:
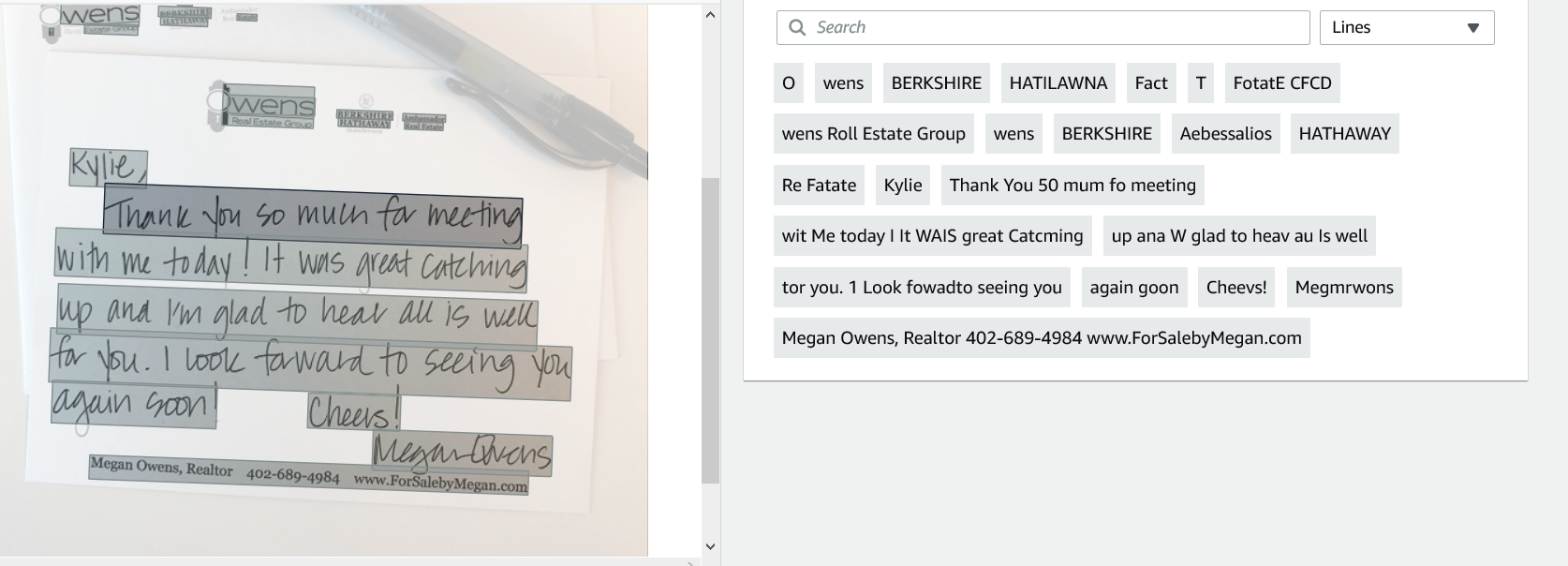
Amazon Textract OCR performed marginally better than Tesseract OCR for handwritten text.
Amazon Textract OCR在手写文本方面的表现略优于Tesseract OCR 。
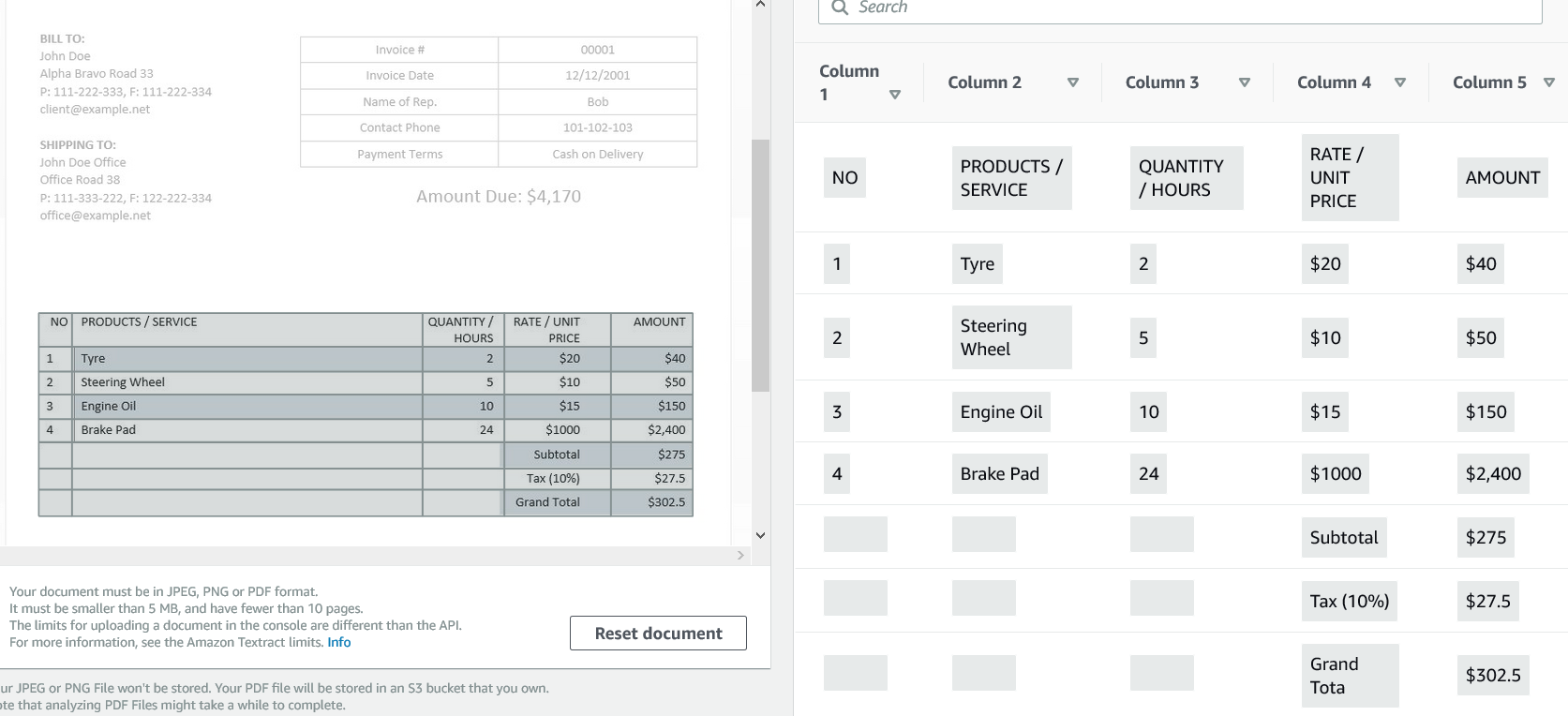
Now we will try a busy image.
现在,我们将尝试繁忙的图像。
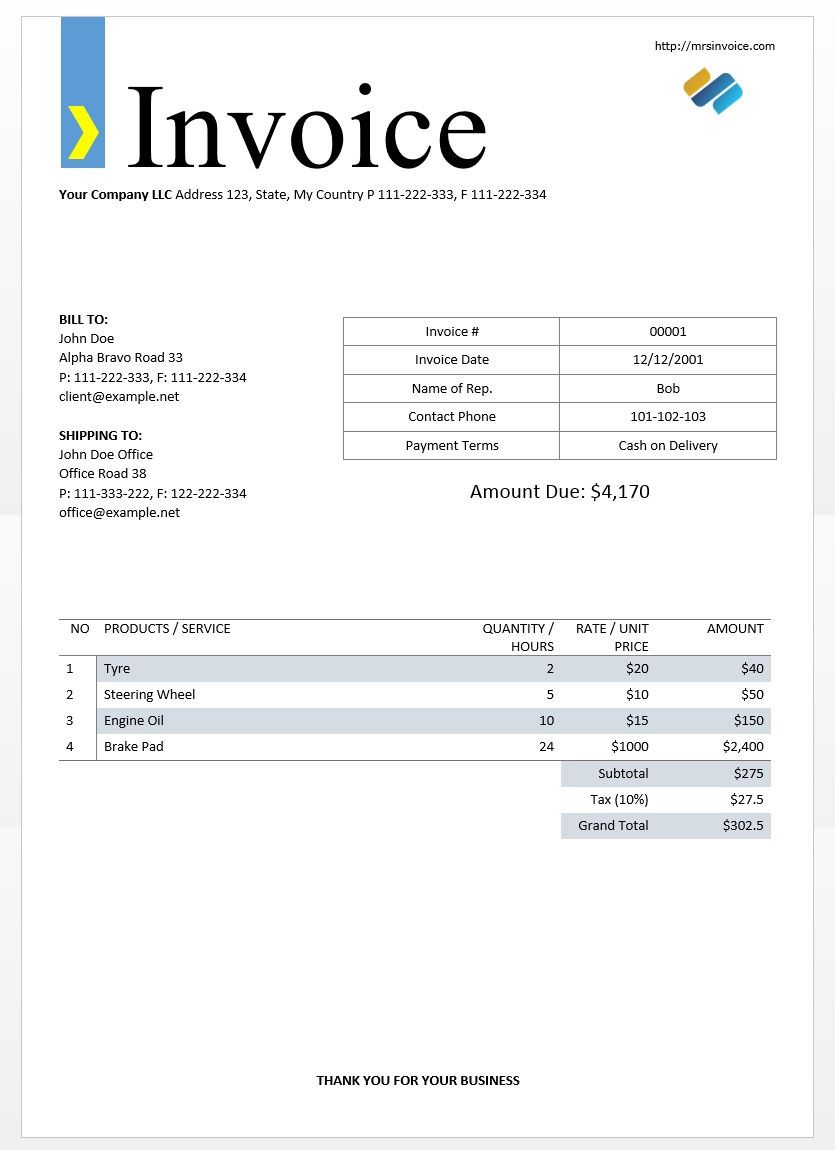
img_invoice = cv2.imread('invoice-sample.jpg')
custom_config = r'--oem 3 --psm 6'
txt_invoice=pytesseract.image_to_string(img_invoice, config=custom_config)
print(txt_invoice)OCR Output using Tesseract OCR:
使用Tesseract OCR的OCR输出:
http://mrsinvoice.comI 7Your Company LLC Address 123, State, My Country P 111–222–333, F 111–222–334BILL TO:P: 111–222–333, F: 111–222–334 a. zcient@eromplentContact Phone 101–102–103john Doe office ayment Terms ‘ash on DeliveryOffice Road 38P: 111–333–222, F: 122–222–334 Amount Due: $4,170office@example.netNO PRODUCTS / SERVICE QUANTITY / RATE / UNIT AMOUNTHOURS: PRICE1 aye 2 $20 $402 | Steering Wheel 5 $10 $503 | Engine oil 10 $15 $1504 | Brake Pad 24 $1000 $2,400Subtotal $275Tax (10%) $27.5Grand Total $302.5‘THANK YOU FOR YOUR BUSINESS
http://mrsinvoice.com I 7Your Company LLC地址123,State,My Country P 111–222–333,F 111–222–334BILL TO:P:111–222–333,F:111–222–334 a。 zcient @ eromplentContact电话101–102–103john Doe办公室付款条款'ash on DeliveryOffice Road 38P:111–333–222,F:122–222–334应付金额:$ 4,170 office@example.net没有产品/服务数量/价格/ UNIT AMOUNTHOURS:PRICE1 aye 2 $ 20 $ 402 | 方向盘5 $ 10 $ 503 | 机油10 $ 15 $ 1504 | 刹车片24 $ 1000 $ 2,400小计$ 275税(10%)$ 27.5总计$ 302.5'谢谢您的生意
OCR Output using Amazon Textract OCR:
使用Amazon Textract OCR的OCR输出:
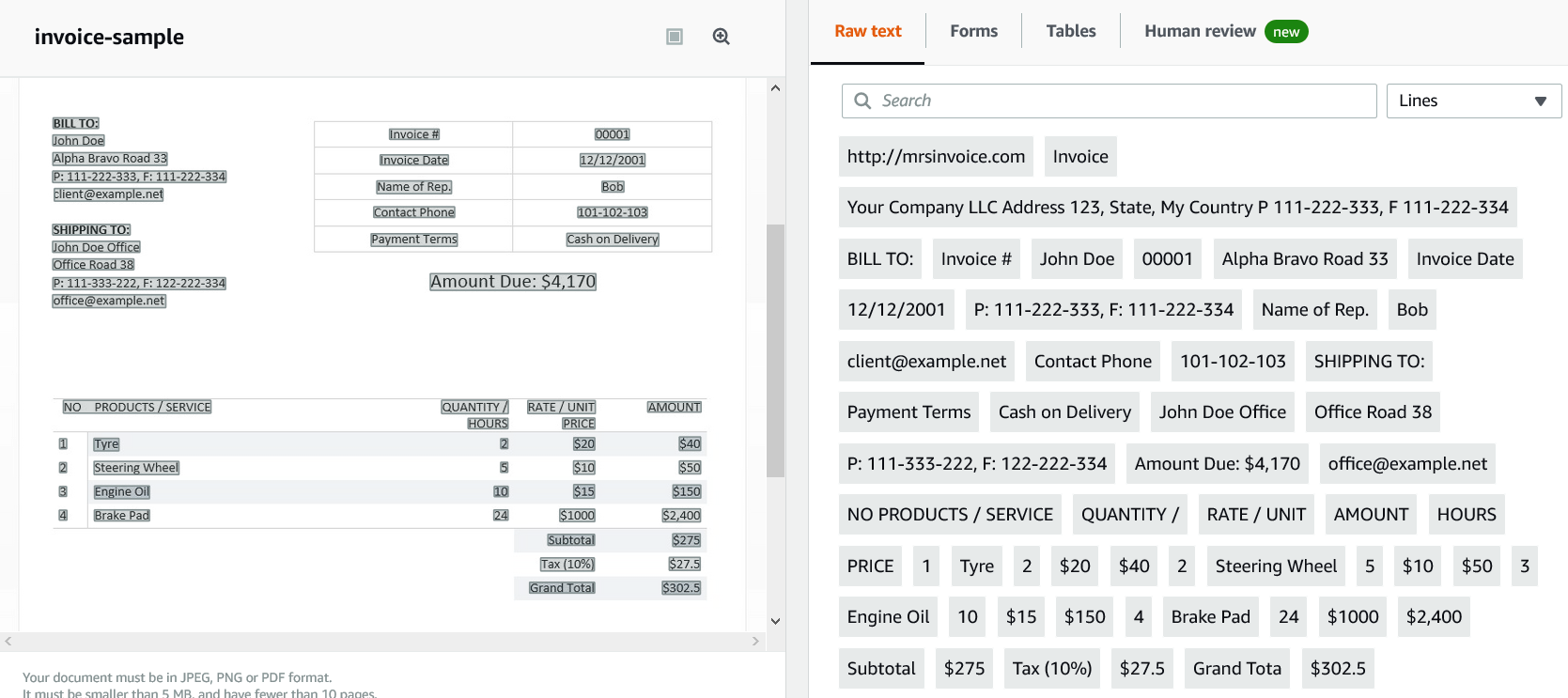
Amazon Textract identifies tables and forms in documents. This is neat.
Amazon Textract可以识别文档中的表格和表格。 这很整齐。
高级功能—拼写检查(Advanced Features — Spell Checking)
Results from an OCR scan are often fed into an NLP model. Therefore, it is important to have a high degree of accuracy of the resulting text. We can handle it two ways:
OCR扫描的结果通常被输入到NLP模型中。 因此,重要的是要高度保证结果文本的准确性。 我们可以通过两种方式处理它:
Pass every work through a spell-checker module like enchant
通过拼写检查器模块(如附魔)传递所有作品
Option 1 — if spell check failed — Mask/remove the word from the resulting text
选项1-如果拼写检查失败-从结果文本中屏蔽/删除单词
Option 2 — if spell check failed — Use spell-checker suggestions and edit the resulting text
选项2 –如果拼写检查失败–使用拼写检查器建议并编辑结果文本
Enchant module is very frequently used in Python to check the spelling of words based on dictionary. In addition to spell checking enchant can give suggestions to correct words.
Enchant模块在Python中非常常用,用于根据字典检查单词的拼写。 除拼写检查外,附魔还可以提供一些建议以纠正单词。
img = cv2.imread('invoice-sample.jpg')
text = pytesseract.image_to_data(img, output_type='data.frame')
text = text[text.conf != -1]
lines = text.groupby('block_num')['text'].apply(list)
print(lines[25])[‘‘THANK’, ‘YOU’, ‘FOR’, ‘YOUR’, ‘BUSINESS.’]
[ “谢谢” ,“您”,“支持”,“您的”,“业务”。]
Note that the first word seems to have an spelling issue.
请注意,第一个单词似乎存在拼写问题。
import enchant
dict_check = enchant.Dict("en_US")for word in lines[25]:
if (dict_check.check(word)):
print(word+ ' - Dictionary Check Valid')
else:
print(word+ ' - Dictionary Check Valid Invalid')
print('Valid Suggestions')
print(dict_check.suggest(word))‘THANK — Dictionary Check Valid InvalidValid Suggestions[‘THANK’]YOU — Dictionary Check ValidFOR — Dictionary Check ValidYOUR — Dictionary Check ValidBUSINESS. — Dictionary Check Valid
'谢谢-字典检查Valid InvalidValid建议['THANK']您-字典检查ValidFOR-字典检查ValidYOUR-字典检查ValidBUSINESS。 —字典检查有效
Note that enchant found the first word invalid and was able to provide a alternative suggestion.
请注意,附魔发现第一个单词无效,并能够提供其他建议。
对NLP使用正则表达式 (Using Regular Expressions for NLP)
My early days in IT (almost 25 years ago) were filled with ups and downs. One day I would learn something new and feel on top of the world. Other days not so much. I remember the day when my manager asked me to work on a pattern-matching problem. I had to do the pattern-matching over data in Oracle. Since I had never done this before, I request him for pointers. The answer I got was was “This can be very easily done using REGEX”. I was a good follower, except there was nothing easy about using REGEX pattern matching). It took me a while to realize that my manager was kidding.
我在IT领域的初期(将近25年前)经历了风风雨雨。 有一天,我会学到一些新东西,并在世界之巅感到满意。 其他日子没有那么多。 我记得那天有一天我的经理要求我研究模式匹配问题。 我必须对Oracle中的数据进行模式匹配。 由于我以前从未做过此事,因此我要求他提供指示。 我得到的答案是“使用REGEX可以很容易地做到这一点”。 我是一个很好的追随者,除了使用REGEX模式匹配并不容易。 我花了一段时间才意识到我的经理在开玩笑。
I still fear using REGEX but can’t escape it…..it still is widely used in Data Science especially NLP. Learning REGEX takes time. I have frequently used websites like https://regex101.com/ for practice.
我仍然担心使用REGEX,但无法逃脱.....它仍然广泛用于数据科学,尤其是NLP。 学习REGEX需要时间。 我经常使用https://regex101.com/这样的网站进行练习。
For example if you want to extract all date fields from a document.
例如,如果要从文档中提取所有日期字段。
d = pytesseract.image_to_data(img, output_type=Output.DICT)
keys = list(d.keys())date_pattern = '^(0[1-9]|[12][0-9]|3[01])/(0[1-9]|1[012])/(19|20)\d\d$'n_boxes = len(d['text'])
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
if re.match(date_pattern, d['text'][i]):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
img_date = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
print(d['text'][i])Output: 12/12/2001
输出:12/12/2001
You may even highlight the date fields in a given document
您甚至可以突出显示给定文档中的日期字段
cv2.imwrite('aimg_date.png', img_date)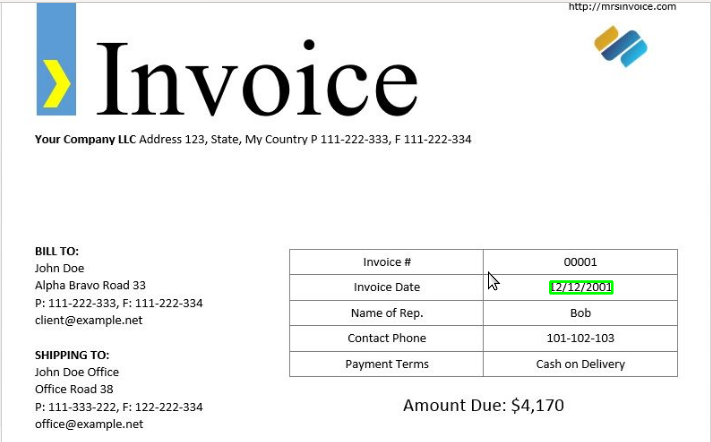
I hope this article was helpful in kick-starting your OCR and NLP knowledge. Topics like these are covered as part of the AWS Big Data Analytics course offered by Datafence Cloud Academy. The course is taught online by myself on weekends.
我希望本文对启动您的OCR和NLP知识有所帮助。 这些主题是Datafence Cloud Academy提供的AWS Big Data Analytics课程的一部分。 该课程由我本人在周末在线上教。
textract

















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









