





dataloader
Since its release in 2015, GraphQL, which was developed by Facebook, is predicted to be the most advanced technology that will replace the role of REST API to communicate between client and server. According to the official documentation, GraphQL is a query language for the API and runtime for fulfilling user requests. GraphQL provides a complete and understandable description and documentation of data in the API, giving clients the freedom to only request the data they need, making it easier to develop the API over time, making it a powerful development tool.
自2015年发布以来,由Facebook开发的GraphQL预计将成为最先进的技术,它将取代REST API的功能以在客户端和服务器之间进行通信。 根据官方文档, GraphQL是API和运行时的查询语言,用于满足用户请求。 GraphQL提供了API中数据的完整且易于理解的描述和文档,使客户可以自由地仅请求所需的数据,从而使随时间推移开发API变得更加容易,使其成为功能强大的开发工具。
Dataloader itself, according to its official documentation, is called “a generic utility to be used as part of your application’s data fetching layer to provide a simplified and consistent API over various remote data sources such as databases or web services via batching and caching”. Dataloader is also a library developed by Facebook. Although it can be used in other conditions, Dataloader is generally used in conjunction with GraphQL to handle multiple requests to the database (N+1 problem).
根据其官方文档,Dataloader本身被称为“ 一个通用实用程序 ,它将用作应用程序数据获取层的一部分,以通过批处理和缓存在各种远程数据源(例如数据库或Web服务)上提供简化且一致的API ”。 Dataloader也是Facebook开发的一个库。 尽管可以在其他条件下使用它,但Dataloader通常与GraphQL结合使用以处理对数据库的多个请求(N + 1问题)。
After a while of use, we started to notice that Dataloader doesn’t have a built-in API for pagination. Then, how do we solve it? Do we really need pagination?
使用一段时间后,我们开始注意到Dataloader没有内置的分页API。 那么,我们该如何解决呢? 我们真的需要分页吗?
骇客! (Let’s hack!)
ERD (ERD)
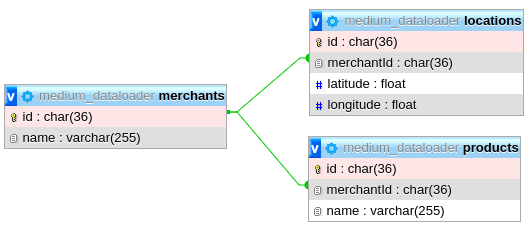
We will build an e-commerce platform where each merchants will have one locations (one-to-one) and will have many products (one-to-many). The ERD scheme can be seen as follows.
我们将建立一个电子商务平台,每个merchants将拥有一个locations (一对一),并拥有许多products (一对多)。 ERD方案可以如下所示。
GraphQL模式 (GraphQL Schema)
After defining the ERD, next, we will define the schema. Here is a pre-designed GraphQL schema (without pagination).
在定义了ERD之后,接下来,我们将定义模式。 这是一个预先设计的GraphQL模式(无分页)。
GraphQL解析器 (GraphQL Resolver)
And also, the resolver itself (without pagination).
而且,解析器本身(无分页)。
GraphQL实例和数据加载器 (GraphQL Instance and Dataloader)
To initiate a Dataloader instance on every request and also for convenience, I place it in the GraphQL context.
为了在每个请求上都启动一个Dataloader实例,并且为了方便起见,我将其放在GraphQL上下文中。
The code snippet above is a typical example of using a Dataloader. We have a schema relation where the location and products fields return all data related to merchants.
上面的代码段是使用Dataloader的典型示例。 我们有一个架构关系,其中“ location和“ products字段返回与merchants有关的所有数据。
The problem arises when a merchant has a lot of products. Let’s say merchant A has 1000 products. Returning 1000 products at once is not a good idea. Besides having problems with memory consumption, the bandwidth to be taken will also be large.
当merchant有很多products时,就会出现问题。 假设商家A有1000种products 。 一次返回1000个products不是一个好主意。 除了存在存储器消耗问题之外,要占用的带宽也将很大。
解决方案? 分页! (The solution? Pagination!)
A common technique for handling large data is to use pagination. And yes, we need that to work with Dataloader. Generally, to use pagination, the client must send some supporting input variables such as limit, offset, orderBy, sortBy, and search. Let’s implement it!
处理大数据的常用技术是使用分页。 是的,我们需要它与Dataloader配合使用。 通常,要使用分页,客户端必须发送一些支持的输入变量,例如limit , offset , orderBy , sortBy和search 。 让我们实现它!
After defining the pagination input, then, we have to pass the pagination argument to the Dataloader. We can do this together with the argument id of the load method. However, in my opinion, this is “messy” and breaks the principle of using arguments in the Dataloader. So, instead of calling the Dataloader instance, I call a function that has a pagination argument by returning the Dataloader instance.
在定义了分页输入之后,我们必须将分页参数传递给Dataloader。 我们可以将其与load方法的参数id一起执行。 但是,我认为这是“混乱的”,并且破坏了在Dataloader中使用参数的原理。 因此,我不调用Dataloader实例,而是通过返回Dataloader实例来调用具有分页参数的函数。
After passing the pagination arguments to the Dataloader, are we done? Not yet. The next challenge is how we do one request to the database and get all the data we need. Do we need additional libraries? No. We only need to use a query that is rarely used, namely UNION. A union is great for the use of intersecting data by returning only unique data. So it can reduce memory consumption. An example of using union on Knex is as follows.
将分页参数传递给Dataloader之后,我们完成了吗? 还没。 下一个挑战是我们如何对数据库发出一个请求并获取所需的所有数据。 我们是否需要其他库? 不需要。我们只需要使用很少使用的查询,即UNION 。 联合非常适合通过仅返回唯一数据来使用相交数据。 因此可以减少内存消耗。 在Knex上使用并集的示例如下。
Then, we need to update our resolvers either.
然后,我们需要更新解析器。
To understand how this loader works, take a look at the illustration below.
要了解此装载机的工作原理,请看下面的插图。
>> merchantIds = ["0713c0b4-a068-4909-b851-a4fcdad4d111", "3ec5d4f6-1459-4fcc-990a-3791bad34843"]>> (SELECT * FROM products WHERE `merchantId` = "0713c0b4-a068-4909-b851-a4fcdad4d111" ORDER BY `name` ASC LIMIT 0,10) UNION (SELECT * FROM products WHERE `merchantId` = "3ec5d4f6-1459-4fcc-990a-3791bad34843" ORDER BY `name` ASC LIMIT 0,10)<< [{"id":"98bfa6a5-5558-4d21-9c6c-db5d6267acc4","name":"Kecap Bango 400ml","merchantId":"0713c0b4-a068-4909-b851-a4fcdad4d111"}, ..., {"id":"9d44ca99-6f87-41c0-bf70-bc50db3d2707","name":"Apple iPhone 11 Pro","merchantId":"3ec5d4f6-1459-4fcc-990a-3791bad34843"}, ...]And that’s all. Now we can paginate the products field instead of returning all its data. How? Easy right?
就这样。 现在,我们可以对products字段进行分页,而不必返回其所有数据。 怎么样? 容易吧?
If you are asking, why should I declare the Dataloader instance in a variable first instead of returning it right away like the snippet below?
如果您要问,为什么我应该先在变量中声明Dataloader实例,而不是像下面的代码片段一样立即返回它?
The purpose of calling the Dataloader on the relations defined on the resolver is to batch each request, then request collectively in the same instance. If we initiate a new instance on each request, the result will be the same without using the Dataloader. Maybe you should try it yourself so you can get a better understand of this concept.
在解析器上定义的关系上调用Dataloader的目的是批处理每个请求,然后在同一实例中共同请求。 如果我们在每个请求上启动一个新实例,则不使用Dataloader的结果将是相同的。 也许您应该自己尝试一下,以便对这个概念有更好的了解。
That’s all I can share with you this time. Hopefully, this article can help you if you face the same problem. Next, I’ll write about Dataloader's ambiguity and how to solve it. So, until next time :wave:
这次我可以与您分享。 如果您遇到相同的问题,希望本文对您有所帮助。 接下来,我将介绍Dataloader的歧义以及如何解决它。 所以,直到下一次:wave:
翻译自: https://medium.com/@alfari/how-do-i-make-pagination-with-graphql-dataloader-78c1afa8fdcf
dataloader















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









