





aws mongodb
Expedia Group Tech-软件 (Expedia Group Tech — Software)
Setting up a distributed database cluster requires careful consideration of many key aspects, including resiliency. In this post, I’ll explain how we (Praveer Gupta and I) set up a MongoDB cluster that is resilient to failure of the underlying hosts.
设置分布式数据库集群需要仔细考虑许多关键方面,包括弹性。 在这篇文章中,我将解释我们( Praveer Gupta和我)如何建立一个MongoDB集群,该集群可以抵抗基础主机的故障。
为什么需要自动修复? (Why is Auto-Healing required?)
If you want to set up a database cluster in AWS, using EC2 instances is a popular way of doing so. But these instances are ephemeral and are occasionally lost or need to be replaced due to:
如果要在AWS中设置数据库集群,则使用EC2实例是一种流行的方式。 但是这些实例属于临时实例,有时会因以下原因而丢失或需要更换:
- Planned maintenance like OS/AMI upgrades, capacity changes, etc. 计划内的维护,例如OS / AMI升级,容量更改等。
- Unplanned activities like instance termination by AWS to handle degraded performance/failed hardware 计划外活动,例如由AWS终止实例以处理性能下降/硬件故障
Restoring the database to its original state under both these scenarios involves considerable manual effort and sensitive operations. Hence, a setup that heals/recovers from such failures automatically, would save time and prevent errors. The same setup would also decrease the effort required in performing planned maintenance.
在这两种情况下,将数据库还原到原始状态都需要大量的人工和敏感的操作。 因此,自动修复/从此类故障中恢复的设置将节省时间并避免错误。 相同的设置还将减少执行计划内维护所需的工作量。

有什么可能呢? (What makes it possible?)
All distributed databases and cloud providers provide somewhat similar features, hence it’s possible to use this approach to implement auto-healing for different distributed databases across multiple cloud providers.
所有分布式数据库和云提供商都提供了一些相似的功能,因此可以使用此方法为多个云提供商中的不同分布式数据库实现自动修复。
This section lists the features of MongoDB and AWS that we exploited. How they are used is detailed in the following sections.
本节列出了我们利用的MongoDB和AWS的功能。 以下各节详细介绍了如何使用它们。
MongoDB功能 (MongoDB features)
- MongoDB servers in a replica set (RS) replicate data among themselves to provide redundancy. In the event of a server getting reconnected after being disconnected for some time, the replica set is able to detect how far behind the server is and automatically sync the remaining data. 副本集(RS)中的MongoDB服务器之间相互复制数据以提供冗余。 如果在断开连接一段时间后重新连接服务器,则副本集能够检测到服务器落后多远并自动同步剩余数据。
- Each individual shard/partition can be set up as a replica set. Network partitioning in one shard’s RS does not impact any other shard. 每个单独的分片/分区都可以设置为副本集。 一个分片的RS中的网络分区不会影响任何其他分片。
AWS功能 (AWS Features)
- Elastic Block Store (EBS) provides a way to segregate data from compute. Termination protection on EBS volumes prevents them from getting deleted when the instance they are attached to gets terminated. 弹性块存储(EBS)提供了一种从计算中分离数据的方法。 EBS卷上的终止保护可防止在它们附加到的实例终止时将其删除。
- If an autoscaling group spans multiple Availability Zones (AZs), AWS ensures uniform distribution of servers across all of them. This means that a replacement for a server in uswest2-a is also launched in uswest2-a. 如果一个自动扩展组跨越多个可用区(AZ),则AWS确保在所有可用区中统一分配服务器。 这意味着在uswest2-a中也将启动uswest2-a中服务器的替代产品。
- Route53 is a DNS service. We create an A record having the hostname and IP address in Route 53 for each server in the cluster. Route53是DNS服务。 我们在路由53中为群集中的每个服务器创建一个具有主机名和IP地址的A记录。
- Tagging provides a simple way to associate properties with resources, which can also be used to identify those resources. 标记提供了一种简单的方法来将属性与资源相关联,也可以用来标识那些资源。

如何实现自我修复? (How is auto healing achieved?)
The solution is presented here in three sections: The first two sections show how we set up the cluster topology across EC2 instances and then configure each instance. The last section details how auto recovery is achieved and how we reduced the recovery time.
这里分三部分介绍了该解决方案:前两部分展示了我们如何跨EC2实例设置集群拓扑,然后配置每个实例。 最后一部分详细介绍了如何实现自动恢复以及如何减少恢复时间。
集群拓扑设置 (Cluster topology setup)
We used AWS CloudFormation to provision EC2 instances. The same may be achieved through other solutions like Terraform.
我们使用AWS CloudFormation设置EC2实例。 可以通过其他解决方案(例如Terraform)来实现相同的目的。
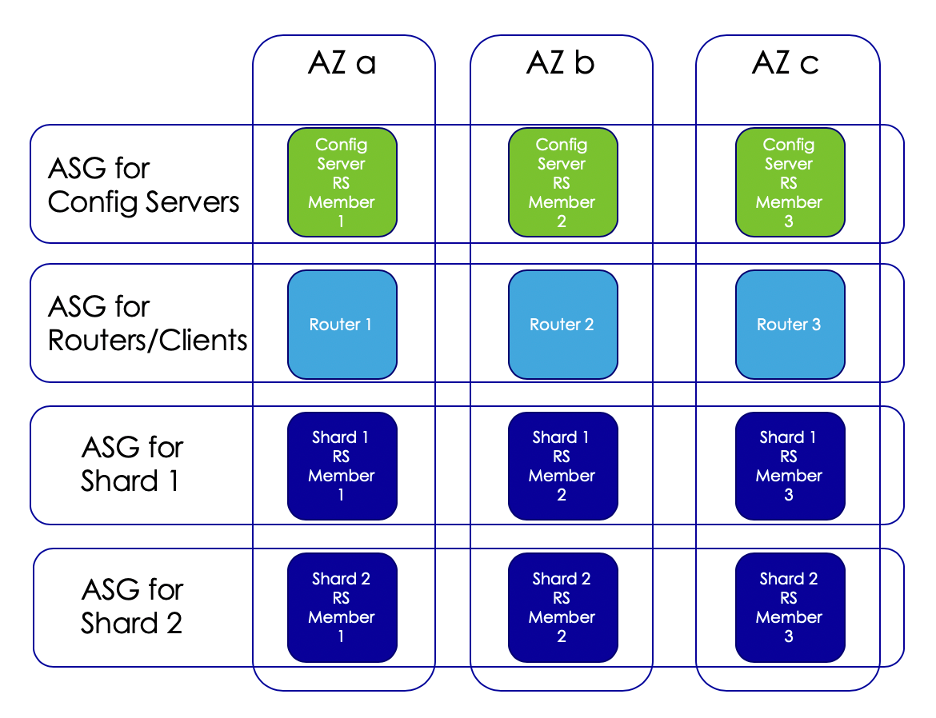
- We set up a sharded cluster with 2 shards (each as a replica set with 3 members), a config server replica set of 3 members and 3 router servers. 我们设置了一个包含2个分片的分片群集(每个分片作为具有3个成员的副本集),由3个成员和3个路由器服务器组成的配置服务器副本集。
- Each of these have their own Autoscaling Groups and Launch Configurations. The min and max value in each ASG were set to 3. Hence when an instance gets terminated, its replacement is brought up by AWS Autoscaling. 它们每个都有自己的自动缩放组和启动配置。 每个ASG中的最小值和最大值均设置为3。因此,当实例终止时,其替换将由AWS Autoscaling提出。
- Each of the 3 servers in the ASGs are set up in a different Availability Zone (AZ) (uswest2-a, b and c). ASG中的3台服务器中的每台都在不同的可用区(AZ)(uswest2-a,b和c)中设置。
MongoDB流程设置 (MongoDB process setup)
Once an EC2 instance is launched (either when the cluster is first set up or during a replacement instance launch), the following workflow configures the instance.
一旦启动EC2实例(在首次设置集群时或在启动替换实例时),以下工作流程将配置该实例。
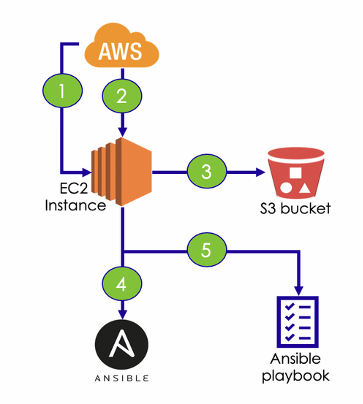
- AWS creates the EC2 instance. AWS创建EC2实例。
AWS calls the initialization lifecycle hook (
UserDatascript in the Launch config)AWS调用初始化生命周期挂钩(Launch配置中的
UserData脚本)- The hook downloads a bootstrap script stored on S3. 挂钩下载存储在S3上的引导脚本。
The bootstrap script installs Ansible and its dependencies.
引导脚本将安装Ansible及其依赖项。
- The bootstrap script configures the instance by running the Ansible playbook in local mode. 引导脚本通过在本地模式下运行Ansible剧本来配置实例。
Further points to note:
其他注意事项:
- Instance configuration and MongoDB process setup is done by the Ansible playbook that we wrote. 实例配置和MongoDB流程设置由我们编写的Ansible剧本完成。
- Each Launch Configuration passes its details like shard name, etc. as parameters to the bootstrap script, which are then used in the Ansible playbook. 每个启动配置将其详细信息(如碎片名称等)作为参数传递给引导脚本,然后在Ansible剧本中使用。
Another automation framework, or even shell scripts, could also be used to achieve the same results.
另一个自动化框架,甚至shell脚本,也可以用来实现相同的结果。
把它放在一起 (Putting it together)
Due to the arrangement of our topology and the fact that AWS autoscaling launches a replacement in the same AZ as the original, any newly launched server knows its coordinates in the cluster. By coordinates, I mean which Shard and Availability Zone it belongs to. How this information is used is mentioned below.
由于拓扑的安排以及AWS自动缩放功能在与原始AZ相同的可用区中启动替换的事实,因此任何新启动的服务器都知道其在集群中的坐标。 通过坐标,我的意思是它属于哪个碎片和可用区。 下面提到如何使用此信息。
The hostname of each server is updated by the Ansible playbook using its coordinates. For example, a member of the first shard(srs0) in uswest2a is named like mongo_srs0_uswest2a. The EBS volumes attached to the instance are also tagged using these coordinates.
Ansible剧本使用其坐标更新每个服务器的主机名。 例如,uswest2a中第一个分片(srs0)的成员的名称类似于mongo_srs0_uswest2a 。 附加到实例的EBS卷也使用这些坐标进行标记。
- The Ansible playbook also updates the server’s IP address in its A record in Route53. The config for each RS contains host names of its members, rather than their IPs, and any replacement server gets automatically added to the relevant RS without manual intervention. Ansible剧本还在Route53的A记录中更新服务器的IP地址。 每个RS的配置都包含其成员的主机名,而不是其IP,并且任何替换服务器都会自动添加到相关RS中,而无需人工干预。
- Because we use MongoDB replica sets, MongoDB does the job of replicating missing data in the newly added instance. Once the sync completes, the instance starts to function as expected. 由于我们使用MongoDB副本集,因此MongoDB可以在新添加的实例中复制丢失的数据。 同步完成后,实例将开始按预期运行。
- In the extremely unlikely event that all 3 members of a replica set get terminated simultaneously, EBS termination protection ensures that the data is not lost, and the cluster can restore to a last known good state. Not using EBS volumes (with termination protection) would have resulted in loss of data. 万一复制集的所有3个成员都同时终止,这种极不可能的情况是,EBS终止保护可确保数据不会丢失,并且群集可以恢复到最后一个已知的良好状态。 不使用EBS卷(具有终止保护)将导致数据丢失。
Speeding up the auto healing process
加快自动修复过程
Since the replacement server launched by Autoscaling has a new EBS volume attached, MongoDB needs to perform a full sync to replicate data onto it. This process is slow and used to take ~4 hours in our case.
由于由Autoscaling启动的替代服务器附加了新的EBS卷,因此MongoDB需要执行完全同步以将数据复制到该卷上。 在我们的情况下,此过程很慢,大约需要4个小时。
An optimisation we used is to preserve the data of the server that died, so that only the delta needs to be re-synced on the replacement server and the process can complete in a few minutes.
我们使用的一种优化方法是保留死掉的服务器的数据,以便仅增量服务器需要在替换服务器上重新同步,并且该过程可以在几分钟内完成。
We achieved this by finding the EBS volumes that were attached to the terminated instance (using its tags) and attaching them to the new instance before starting the MongoDB process there. The volumes created with the new instance are deleted. Thus, when the new server joins the RS, only the delta gets synced. This logic is also part of the Ansible playbook.
通过找到附加到终止实例的EBS卷(使用其标签)并将它们附加到新实例,然后在该处开始MongoDB流程,我们实现了这一点。 使用新实例创建的卷将被删除。 因此,当新服务器加入RS时,仅增量被同步。 这个逻辑也是Ansible剧本的一部分。

证明在布丁里 (The proof is in the pudding)
We deployed this solution about 18 months ago. In that time, we’ve had approximately 6 instance failures in our cluster. Our deployment was able to handle all of these with ZERO downtime, ZERO data loss and ZERO manual intervention.
我们大约在18个月前部署了该解决方案。 那时,我们的集群中大约有6个实例故障。 我们的部署能够通过零停机,零数据丢失和零人工干预来处理所有这些问题。
We were also able to downscale the original EBS volumes since they were over-provisioned. We simply updated CloudFormation with the new EBS size, and terminated the instances one by one, until the entire fleet was replaced. This too incurred no downtime.
由于原始EBS的数量过多,我们也可以缩小它们的数量。 我们只是使用新的EBS大小更新了CloudFormation,并逐个终止了实例,直到替换了整个机队。 这也不会造成停机。
翻译自: https://medium.com/expedia-group-tech/auto-healing-mongodb-cluster-in-aws-abb22c4d7d0
aws mongodb














 5042
5042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









