





 本文探讨了数据库扩展的两种主要方式——横向扩展和纵向扩展,并提供了5种不同的解决方案,帮助应对日益增长的数据存储和处理需求。内容源于对原英文文章的翻译,旨在为读者提供数据库扩展的深入理解。
本文探讨了数据库扩展的两种主要方式——横向扩展和纵向扩展,并提供了5种不同的解决方案,帮助应对日益增长的数据存储和处理需求。内容源于对原英文文章的翻译,旨在为读者提供数据库扩展的深入理解。
横向扩展 纵向扩展 数据库
重点 (Top highlight)
If your application is experiencing load problems, time to bring out the champagne! Your web-app must be pretty successful to get to this stage. You’ve reached the capacity number of users that your application is able to handle, things are beginning to slow down and error out. Network requests start timing out, database queries are taking a while to execute, pages are loading slowly. Congratulations — your app is ready to scale! Time to put that champagne down though… You need to handle these growing pains before your users leave your app for that annoying competitor copying your idea.
如果您的应用程序遇到负载问题,请抽出香槟! 您的网络应用必须非常成功才能进入这一阶段。 您已经达到了应用程序可以处理的用户数量,事情开始变慢并且出错。 网络请求开始超时,数据库查询执行需要一段时间,页面加载缓慢。 恭喜!您的应用已准备好进行扩展! 不过,该花点时间喝香槟了……在您的用户离开您的应用之前,您需要应对这些不断增长的痛苦,以吸引那些讨厌的竞争对手复制您的想法。
扩展成本 (The Costs Of Scaling)
Before you start vertically, horizontally and inside-out* sharding your database, an important principle should be kept in mind. You shouldn’t implement premature optimisations or attempt to scale your app before it’s actually needed. Implementing scaling solutions introduces the following complexities:
在垂直,水平和由内而外*分割数据库之前,应牢记一个重要原则。 您不应该实施过早的优化或尝试在实际需要之前扩展应用程序。 实施伸缩解决方案带来以下复杂性:
- Adding new features takes longer 添加新功能需要更长的时间
- The system becomes more complex with more pieces and variables involved 系统变得越来越复杂,涉及更多的零件和变量
- Code can be more difficult to test 代码可能更难测试
- Finding and resolving bugs becomes harder 查找和解决错误变得更加困难
You should only accept these trade-offs if your app is at capacity. Keep the system simple, don’t introduce scaling complexities unless it’s warranted.
仅当您的应用程序已满负荷运行时,才应接受这些折衷。 保持系统简单,除非有保证,否则不要引入扩展复杂性。
*inside-out database sharding is not a real solution. The point is there is a spectrum of scaling solutions, don’t implement them unless you need to!
*由内而外的数据库分片不是真正的解决方案。 关键是存在一系列扩展解决方案,除非需要,否则不要实施它们!

使用指标查找瓶颈 (Finding Bottlenecks Using Metrics)
Every application/system is different, to determine which scaling solution to implement you must first determine where the bottleneck is. Time to check your resource monitoring system or create one if you haven’t already. No matter the stack you are working with there will be tools available for monitoring your resources. If you’re running on any of the leading IaaS (Infrastructure as a Service) providers such as AWS, Microsoft Azure and GCP, there are great application performance management tools out of the box to choose from.
每个应用程序/系统都不同,要确定实施哪种扩展解决方案,您必须首先确定瓶颈在哪里。 是时候检查您的资源监视系统,或者如果尚未创建一个。 无论您使用的堆栈如何,都有可用的工具来监视您的资源。 如果您在任何领先的IaaS(基础设施即服务)提供商(例如AWS,Microsoft Azure和GCP)上运行,则都有出色的应用程序性能管理工具可供选择。
These tools illustrate the performance of your resources through graphs and other data visualisation methods. Use these graphs to look for spikes or flat tops. These commonly imply that a resource was overwhelmed or at capacity and was not able to handle new operations. If nothing is apparently at capacity, but your app seems to be running slow, try sprinkling logs throughout heavily used operations. Check the logs for resources that take a long time to load over the network, there could be another server such as a third-party API or your database server introducing delays. You should be hosting your database on another server, if that’s the case then you should also check your resource monitoring for that machine.
这些工具通过图形和其他数据可视化方法说明了资源的性能。 使用这些图表查找尖峰或平顶。 这些通常意味着资源不堪重负或已满负荷,并且无法处理新的操作。 如果显然没有什么容量,但是您的应用程序似乎运行缓慢,请尝试在频繁使用的操作中分散日志。 检查日志中是否需要花费很长时间才能通过网络加载资源,可能是其他服务器(例如第三方API)或您的数据库服务器引入了延迟。 您应该将数据库托管在另一台服务器上,如果是这种情况,那么还应该检查该机器的资源监视。
By thinking about how your application is used by your users and thinking logically about the errors or cracks beginning to show, determining where the bottleneck is can be pretty straight forward. Let’s take Twitter for example, this particular platform is mostly used to read and write tweets. If Twitter’s monitoring services indicated a heavy load on their databases relating to these actions, it would make sense for their team to start optimising that area of the platform. In this article, we will be diving into database scaling solutions, which is usually the first point of failure. If you aren’t already familiar with systems design, I have a brief article that will introduce you to the topic. I recommend getting an understanding of systems design before implementing scaling solutions.
通过考虑用户如何使用您的应用程序,以及从逻辑上考虑开始显示的错误或裂缝,确定瓶颈在哪里很简单。 让我们以Twitter为例,这个特定的平台主要用于读写推文。 如果Twitter的监视服务表明与这些操作有关的数据库负担沉重,则对他们的团队而言,开始优化平台的这一区域将是有意义的。 在本文中,我们将深入研究数据库扩展解决方案,这通常是失败的第一点。 如果您还不熟悉系统设计,那么我有一篇简短的文章将向您介绍该主题。 我建议在实施扩展解决方案之前对系统设计有所了解。

从鸟瞰视角扩展应用程序 (Scaling an App From a Birdseye View)
Now that we’ve got a good sense of what/where the problems/bottlenecks are, we can start implementing solutions to address these issues. Remember, simplicity is key, we want to always try to avoid introducing unnecessary complexities.
现在我们对问题/瓶颈所在/位置有一个很好的了解,我们可以开始实施解决方案来解决这些问题。 记住,简单是关键,我们要始终避免引入不必要的复杂性。
The high-level goal of scaling solutions is to have the stack do less work for the application’s most common requests or effectively distribute the workload that can’t be eliminated across multiple resources. The way that scaling techniques do this usually translates into one or more of the following:
扩展解决方案的高级目标是使堆栈减少应用程序最常见请求的工作,或者有效地分配无法在多个资源之间消除的工作负载。 缩放技术执行此操作的方式通常会转换为以下一项或多项:
- Reusing data the app has already looked up 重用应用程序已查找的数据
- Eliminating requests from the client for data the app already possesses 消除了客户端对应用程序已经拥有的数据的请求
- Storing results of common operations in order to reduce repeating computations 存储常用操作的结果,以减少重复计算
- Avoiding complex operations in the request-response cycle 在请求-响应周期中避免复杂的操作
Many scaling techniques boil down to some form of caching. In the past, memory was expensive and scarce; nowadays it’s inexpensive to add it to servers. Memory is many orders of magnitude faster to access data compared to disk or the network; in this era where users have a plethora of choices, coupled with our minimal attention span, speed and performance are paramount to your application’s survival.
许多扩展技术可以归结为某种形式的缓存。 过去,记忆是昂贵而稀缺的。 如今,将其添加到服务器是很便宜的。 与磁盘或网络相比,内存访问数据的速度要快许多个数量级。 在这个用户有太多选择的时代,再加上我们的关注范围最小,速度和性能对您的应用程序的生存至关重要。
数据库扩展解决方案 (Database Scaling Solutions)
缓存数据库查询 (Cache Database Queries)
Caching database queries is one of the simplest improvements you can make to handle database load. Usually an application will have a handful of queries that make up the majority of the requests made. Rather than making a round trip over the network each time for that data, it can simply be cached in memory on the webserver. The first request will fetch data from the database and cache the results on the server, future requests just read from the cache. This results in increased performance as the data spends less time traveling through the network and is closer to the client. It also results in more of the database server’s resources being available as significant workload is distributed to the cache system. As well as increased availability, if the database is unavailable, the cache can still provide continuous service to the application, making the system more resilient to failures. There are a lot of tools that you can use to run an analysis on database query logs, so you can see which queries are taking the longest to complete and which queries are run most frequently.
缓存数据库查询是您可以处理数据库负载的最简单的改进之一。 通常,一个应用程序将具有少数查询,这些查询构成了大多数请求。 不必每次都在网络上对该数据进行往返,而是可以将其简单地缓存在Web服务器的内存中。 第一个请求将从数据库中获取数据,并将结果缓存在服务器上,以后的请求仅从缓存中读取。 由于数据花费在网络上的时间更少,并且距离客户端更近,因此可以提高性能。 由于大量的工作负载分配给了缓存系统,因此还导致更多的数据库服务器资源可用。 除了提高可用性之外,如果数据库不可用,则高速缓存仍然可以为应用程序提供连续服务,从而使系统对故障的恢复能力更强。 您可以使用许多工具对数据库查询日志进行分析,因此您可以查看哪些查询花费的时间最长,哪些查询运行的频率最高。
Obviously, data that’s cached can become ‘stale’ or out of date quite quickly. You will have to be mindful of which data you chose to cache and how long for. For example, an online newspaper would have a new daily newspaper every 24 hours, rather than requesting that data from the database every time a user hits the site, they can cache that data on the webserver for 24 hours and serve it straight from the server. Product or business requirements will dictate what can and can’t be cached.
显然,缓存的数据会很快变得“陈旧”或过时。 您将必须记住选择缓存的数据以及存储的时间。 例如,在线报纸每24小时就会有一份新的日报,而不是每次用户访问该网站时都从数据库中请求该数据,而是可以将这些数据在Web服务器上缓存24小时并直接从服务器提供该数据。 。 产品或业务需求将决定哪些内容可以缓存,哪些内容不能缓存。

数据库索引 (Database Indexes)
Database indexing is a technique that improves the speed of data retrieval operations on a database table. Indexes are used to quickly locate data without having to search every row in a table every time the table is accessed. Usually, the data structure for a database index will be a binary search tree. This allows the time complexity of accessing the data to be lowered from linear time O(n) to logarithmic time Olog(n).
数据库索引是一种提高数据库表上数据检索操作速度的技术。 索引用于快速定位数据,而不必每次访问表时都在表中搜索每一行。 通常,数据库索引的数据结构将是二进制搜索树。 这使得访问数据的时间复杂度从线性时间O(n)降低到对数时间Olog(n)。
Depending on the number of rows in a table this can save significant amounts of time off queries that use the indexed column. For example, if you had 10,000 users and your application has profile pages that look up a user by their username, an un-indexed query would examine every single row in the users table until it finds the profile that matches the username passed into the query. That could take up to 10,000 row examinations O(n). By creating an index for the “username” column, the database could pull out that row under logarithmic time complexity (Olog(n)). In this case, the maximum number of row examinations would be 14 instead of 10,000!
根据表中的行数,这可以节省使用索引列的查询的大量时间。 例如,如果您有10,000个用户,并且您的应用程序具有配置文件页面,该页面按用户名查找用户,则未编制索引的查询将检查users表中的每一行,直到找到与传递给查询的用户名匹配的配置文件为止。 。 这可能需要多达10,000个行检查O(n)。 通过为“用户名”列创建索引,数据库可以在对数时间复杂度(Olog(n))下提取该行。 在这种情况下,行检查的最大数量将是14,而不是10,000!
Effective indexing reduces the load on the database by increasing efficiency, this also provides significant performance boosts leading to better user experience. Creating an index does add another set of data to be stored on the database, so careful judgment must be exercised when deciding what fields to index. Even with the existing storage space used, indexing tends to be well worth it, especially in modern-day development where memory is cheap and performance is integral to survival.
有效的索引编制通过提高效率来减轻数据库的负载,这还可以显着提高性能,从而带来更好的用户体验。 创建索引确实会添加另一组要存储在数据库中的数据,因此在确定要索引的字段时必须谨慎判断。 即使使用了现有的存储空间,索引也还是很值得的,尤其是在现代开发中,内存便宜且性能是生存不可或缺的一部分。
Time complexity and data structures were mentioned a bit in this section, but not thoroughly explained. If you’re interested in learning about or want to brush up on your understanding of time complexities and data structures, the articles linked above are fantastic resources!
在本节中略微提到了时间复杂度和数据结构,但没有进行详尽的解释。 如果您有兴趣学习或希望进一步了解时间复杂性和数据结构 ,那么上面链接的文章是绝妙的资源!
会话存储 (Session Storage)
A lot of applications handle sessions by storing a session ID in a cookie, then storing the actual data for the key/value pair of every session in a table on the database. This can become a tremendous amount of reading and writing to your database. If your database is getting overwhelmed with session data, it’d be a good idea to rethink how and where you’re storing that data.
许多应用程序通过将会话ID存储在cookie中,然后将每个会话的键/值对的实际数据存储在数据库表中来处理会话。 这可能会成为对数据库的大量读取和写入。 如果数据库中的会话数据不堪重负,那么最好重新考虑如何以及在何处存储该数据。
Moving session data to an in-memory caching tool like redis or memcached can be a good option. This will remove the load of the session data from your database and also increase the speed of access since in-memory is faster than persistent disk storage which most databases use. However, since in-memory is volatile memory, there is a risk of losing all of the session data if the caching system goes offline.
将会话数据移动到内存中的缓存工具(例如redis或memcached)可能是一个不错的选择。 由于内存中的内存比大多数数据库使用的持久性磁盘存储要快,因此这将减轻数据库中会话数据的负担,并提高访问速度。 但是,由于内存是易失性内存,因此如果缓存系统脱机,则存在丢失所有会话数据的风险。
You could also consider changing your session implementation to storing the session information in the cookie itself, which will move your means of maintaining session state off the server and onto the client instead. JWT’s are the most popular implementation for this pattern. This will alleviate your database of all the session data and remove the dependency of server-side sessions, although it introduces its own sets of challenges.
您还可以考虑更改会话实现,以将会话信息存储在cookie本身中,这将使您保持会话状态的方式从服务器移到客户端。 JWT是此模式最流行的实现。 这将减轻数据库中所有会话数据的负担,并消除服务器端会话的依赖性,尽管这会带来一系列挑战。
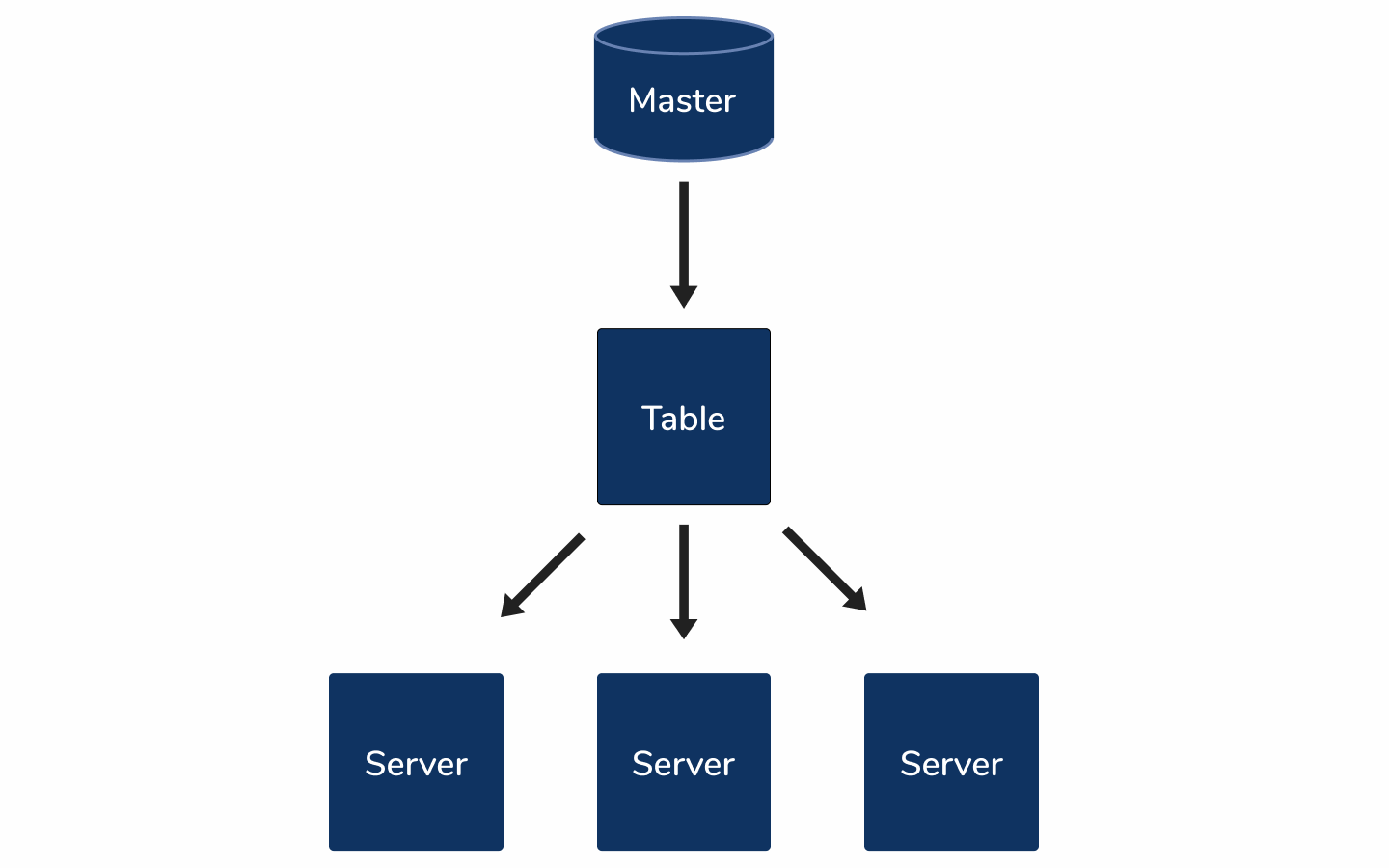
主从复制 (Master Slave Replication)
If your database is still under too much load from reads even after caching common queries, creating efficient indexes, and handling session storage, replication may be the next best stone to turn.
如果即使在缓存通用查询,创建有效索引以及处理会话存储之后,数据库仍然承受着来自读取的过多负载,那么复制可能是下一个最佳选择。
With master-slave replication, you have a single database that you write to. It is cloned into several (as many as you need) slave databases that you read from, with each slave database sitting on another machine* (refer to the diagram below). This takes the reading load off the master database and distributes it across multiple servers. This model also improves the performance of writes as the master database is dedicated to writes, whilst dramatically increasing read speed and reducing latency as slave databases are spread across different regions.
使用主从复制,您可以写入一个数据库。 它被克隆到您读取的几个(根据需要)从数据库中,每个从数据库都位于另一台计算机上*(请参见下图)。 这样可以减轻读取主数据库的负担,并将其分配到多个服务器上。 由于主数据库专用于写入,因此该模型还提高了写入性能,同时由于从属数据库分布在不同区域,因此大大提高了读取速度并减少了延迟。

Since each slave database is on another machine, writes to the master database need to propagate through to the slaves which can lead to inconsistent data. If you need to immediately read the data written to the database, say you are updating a profile and want it rendered immediately, you can opt to read from the master database. Slave-master replication is an incredibly powerful scaling solution, but it comes with its fair share of complexities. It’d be wise to implement this solution after exhausting simpler solutions and ensuring effective optimisations within the application.
由于每个从数据库都在另一台计算机上,因此对主数据库的写入需要传播到从数据库,这可能导致数据不一致。 如果您需要立即读取写入数据库的数据,例如您正在更新配置文件并希望立即呈现它,则可以选择从master数据库读取。 从属主复制是一个非常强大的扩展解决方案,但是它具有相当多的复杂性。 在用完更简单的解决方案并确保应用程序内的有效优化之后,实施此解决方案是明智的。
*This architectural pattern is more commonly known as master-slave replication, but it’s a term that has received criticism over the years and is in the process of being replaced throughout the tech community.
*这种体系结构模式通常被称为主从复制,但是这个术语多年来受到批评,并且正在整个技术社区中被替换。
数据库分片 (Database Sharding)
Most of these scaling solutions so far have focused on reducing load through managing the reads to the database. Database sharding is a horizontal scaling solution to manage load by managing reads and writes to the database. It’s an architectural pattern involving a process of splitting up (partitioning) the master database into multiple databases (shards), which are faster and easier to manage.
到目前为止,这些扩展解决方案中的大多数都集中在通过管理对数据库的读取来减轻负载。 数据库分片是一种水平扩展解决方案,可通过管理对数据库的读写来管理负载。 这是一种体系结构模式,涉及将主数据库分割(分区)为多个数据库(分片)的过程,这些数据库可以更快,更容易管理。
There are two types of database sharding techniques — vertical sharding and horizontal sharding (refer to the diagrams below). With horizontal partitioning, tables are taken and put on different machines with each table having identical columns, but distinct rows. Vertical partitioning is more complex, involving splitting one table across multiple machines. A table is separated out and put into new, distinct tables. The data held in one vertical partition is independent of the data in all others, each table holds both distinct rows and columns.
数据库分片技术有两种类型:垂直分片和水平分片(请参见下图)。 使用水平分区时,将表取出并放在不同的机器上,每个表具有相同的列,但行不同。 垂直分区更为复杂,涉及在多台计算机上拆分一个表。 一个表被分离出来并放入新的不同表中。 一个垂直分区中保存的数据独立于所有其他分区中的数据,每个表都包含不同的行和列。

Both sharding techniques facilitate horizontal scaling, also known as ‘scaling out’, which enables the practice of adding more machines to a system in order to distribute/spread the load. Horizontal scaling is often contrasted with vertical scaling, also known as ‘scaling up’, which involves upgrading the hardware of an existing server. Scaling up for a database is relatively simple, although any non-distributed database will have its limits in terms of computing power and storage, so having the freedom to scale out makes your system far more flexible.
两种分片技术都有助于水平扩展,也称为“向外扩展”,这使您可以在系统中添加更多机器,以便分配/分散负载。 水平扩展通常与垂直扩展(也称为“向上扩展”)形成对比,后者涉及升级现有服务器的硬件。 扩展数据库相对简单,尽管任何非分布式数据库在计算能力和存储方面都有其局限性,因此可以自由扩展可以使您的系统更加灵活。
A sharded database architecture can also significantly increase the speed of your application’s queries, as well as providing increased resilience to failures. When submitting a query on an unsharded database, it may have to search every row in the table which can be prohibitively slow. Alternatively, by sharding one table into multiple tables, queries have to go over much fewer records to return results. Since each of those tables is on a separate server, the impact of a server becoming unavailable is mitigated. With a sharded database, the impact of an outage will likely affect only a single shard, compared with an unsharded database where an outage has the potential to make an entire application unavailable.
分片的数据库体系结构还可以显着提高应用程序查询的速度,并提供增强的故障恢复能力。 在未分片的数据库上提交查询时,它可能不得不搜索表中的每一行,这可能会非常慢。 另外,通过将一个表拆分为多个表,查询必须遍历更少的记录才能返回结果。 由于每个表都在单独的服务器上,因此减轻了服务器不可用带来的影响。 对于分片的数据库,与未分片的数据库相比,中断的影响很可能只影响单个分片,而未分片的数据库则有可能使整个应用程序不可用。
Having a sharded database architecture provides some pretty massive benefits, however, it is complex and has a high implementation and maintenance cost. This is definitely an option you’d want to consider after exhausting other scaling solutions as the ramifications of ineffective implementation can be quite severe.
具有分片的数据库体系结构可带来一些巨大的好处,但是,它很复杂并且实现和维护成本很高。 在用完其他扩展解决方案之后,这绝对是您要考虑的一个选项,因为无效实施的后果可能非常严重。
结论 (Conclusion)
Congratulations, your app has now got the appropriate solutions in place to effectively handle database load and scale with your app’s success! Not quite time to celebrate just yet though… An effectively scaled server is integral to a performant and reliable application. In the near future, I will be releasing an article covering server and client scaling solutions 🚀
恭喜,您的应用程序现在已经有了适当的解决方案,可以有效地处理数据库负载并随着应用程序的成功进行扩展! 尽管还没有足够的时间来庆祝……有效扩展的服务器是高性能和可靠应用程序不可或缺的一部分。 在不久的将来,我将发布一篇有关服务器和客户端扩展解决方案的文章🚀
Thanks for reading ❤️ I hope there were gems in this article for you 💎
感谢您阅读❤️我希望这篇文章能为您提供一些💎
翻译自: https://medium.com/swlh/5-database-scaling-solutions-you-need-to-know-e307570efb72
横向扩展 纵向扩展 数据库















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









