





kafka分布式
Nowadays, cloud solutions are gaining popularity day after day among giant companies that once relied on on-premise infrastructures and high-performance computer architectures, also known as mainframe-based systems. This trend was first boosted by big tech companies, especially the ones defined as FAAMG companies. With that mindset in mind, I’ve decided to create an article exploring some of the underlining benefits of event-based distributed systems using Kafka as the main message broker against classical monolithic applications and mainframe systems.
如今,云解决方案在曾经依赖于内部部署基础架构和高性能计算机体系结构(也称为基于大型机的系统)的巨型公司中日渐流行。 这种趋势首先由大型科技公司推动,尤其是那些定义为FAAMG公司的公司 。 考虑到这种思维方式,我决定创建一篇文章,探讨使用Kafka作为主要消息代理(针对经典的单片应用程序和大型机系统)的基于事件的分布式系统的一些突出优点。
For this post, I’ve created a quick tutorial using two Spring Boot Java microservices, Docker, Schema Registry, and Kafka. I also included some of the history behind computing systems.
在本文中,我使用两个Spring Boot Java微服务,Docker,Schema Registry和Kafka创建了一个快速教程。 我还介绍了计算系统背后的一些历史。
大公司为何将其堆栈转换为云计算? (Why are big companies switching their stack towards cloud computing?)
The mainframe is, without question, one the most reliable, performant, and cost-efficient machines ever created by humans. No matter your arguments against it, we have to acknowledge its importance, especially during the 1980s until the beginning of the twenty-one century.
毫无疑问, 大型机是人类创造的最可靠,性能最高且最具成本效益的机器之一。 无论您是否反对它,我们都必须承认它的重要性,尤其是在1980年代直到二十一世纪初。
With the advance of technology over the last years, however, this power was surpassed by many supercomputers using concurrent systems, and by new distributed solutions using several replicas of a given service in a scalable manner.
但是,随着近几年技术的进步,许多使用并发系统的超级计算机以及使用可扩展方式使用给定服务的多个副本的新分布式解决方案都超越了这种能力。
Companies with massive market cap and unlimited tech budgets were committed to building their systems using mainframes in the past, especially when we’re talking about the finance industry. After it all, its huge upfront cost wasn’t an issue at all. Take the largest financial institutions for instance. The massive majority of them were mainframe-powered institutions until the early 2000s.
市值巨大且技术预算无限制的公司过去致力于使用大型机来构建系统,尤其是在我们谈论金融行业时。 毕竟,其巨大的前期成本根本不是问题。 以最大的金融机构为例。 直到2000年代初期,它们中的绝大多数都是大型机驱动的机构。
It wasn't until the launch of companies like Amazon Web Services in 2006 that this scenario would drastically change. Since then, most of the banks, governmental institutions, air travel companies, and so many others want to ride this wave of cloud computing. No company wants to miss this boat of modern software architectures.
直到2006年像Amazon Web Services这样的公司成立时,这种情况才发生了巨大变化。 从那时起,大多数银行,政府机构,航空旅行公司以及许多其他公司都希望驾驭这一波云计算浪潮。 没有公司会想念这艘现代软件架构的船。
When it comes to the different cloud architectures we have nowadays, async architecture stands out as one of the future replacements for traditional software designs. Some of the reasons that this will be the future of large-scale systems are highlighted below.
当涉及到当今我们拥有的不同云架构时,异步架构将成为传统软件设计的未来替代品之一。 下面重点介绍一些将成为大型系统未来的原因。
1-费用 (1 — Cost)
There is no question that cloud-based solutions are cheaper for start-up and medium companies than mainframe software. So, how about 100,000+ employees corporations like banks? And companies that have already robust and reliable mainframe systems? To answer these questions, we have to see the big picture here. In the long run, sure, the cost of distributed systems is lower than paying for MIPS (millions of instructions per second) in a mainframe architecture.
毫无疑问,对于初创和中型公司而言,基于云的解决方案比大型机软件便宜。 那么,像银行这样的100,000多个员工公司呢? 那些已经拥有强大而可靠的大型机系统的公司呢? 要回答这些问题,我们必须在这里看到大局。 从长远来看,可以肯定的是,分布式系统的成本要比大型机体系结构中的MIPS(每秒数百万条指令)支付的成本低。
On the other hand, the upfront cost in terms of creating the platform itself and the infrastructure required to support business-related services can be quite expensive. Even though it is a long shot, once they have this up and running, the cost will be drastically reduced over time. Overall, the cost of these systems is lower than the mainframe systems.
另一方面,就创建平台本身和支持与业务相关的服务所需的基础结构而言,前期成本可能非常昂贵。 即使是很长的路要走,一旦他们启动并运行,成本将随着时间的推移而大大降低。 总体而言,这些系统的成本低于大型机系统。
When we talk about monolithic systems, many similarities are shared with mainframe platforms. Comparing it with microservices, we see the opposite direction for the cost. In other words, the long term cost is way higher than creating and deploying several microservices. This is true because we can split the features in a way in which business value is deployed into production constantly with microservices. This cannot be achieved if developers spend months to ship a single application, which is true for monolithic software since they requite way more time to be developed.
当我们谈论整体系统时 ,大型机平台有许多相似之处。 与微服务进行比较,我们看到了相反的成本方向。 换句话说,长期成本比创建和部署多个微服务要高得多。 这是事实,因为我们可以通过微服务不断地将业务价值部署到生产中的方式来拆分功能。 如果开发人员花几个月的时间来发布单个应用程序,这是无法实现的,这对于单片软件是正确的,因为他们需要更多的时间来开发。
2-劳动 (2 — Labor)
Now we’re entering an interesting topic here. Back in the 1990s, COBOL was a real thing. Colleges and universities across the planet had this component on their curriculum as it was in high demand in the market at the time. This scenario shifted by the beginning of the 2000s when new programming languages were emerging as replacements for mainframe systems. In the present time, thousands upon thousands of new graduates enter the market every single year with well-trained skills in software development and cloud computing.
现在我们在这里输入一个有趣的话题。 早在1990年代,COBOL是真实的东西。 由于当时市场需求旺盛,地球上的各大高校都将其包含在课程中。 这种情况在2000年代初发生了变化,当时出现了新的编程语言来代替大型机系统。 目前,每年都有成千上万的新毕业生进入市场,他们拥有软件开发和云计算方面训练有素的技能。
Those companies, which once relied on COBOL developers, had to adapt to this new normal. In summary, there are way more cloud professionals than mainframe specialists worldwide. To add no this, many of today's COBOL programmers are now retiring, and we are expected to have a shortage of these professionals in the near future.
这些曾经依靠COBOL开发人员的公司不得不适应这一新标准。 总而言之,全球范围内云专业人员的数量超过大型机专家的数量。 除此之外,当今许多COBOL程序员现在都将退休,我们预计在不久的将来将缺少这些专业人员 。
3-敏捷 (3 — Agility)
This is perhaps one of the main advantages of having a distributed architecture based on microservices with async communication. The reason for that is because developing and deploying small features in a microservice platform is faster than developing a new subprogram or routine on a mainframe. In completed automated cloud systems, agile teams are able to deploy features into production in matters of hours if not minutes.
这也许是具有基于微服务和异步通信的分布式体系结构的主要优势之一。 这样做的原因是因为在微服务平台上开发和部署小功能比在大型机上开发新的子程序或例程要快。 在完整的自动化云系统中,敏捷团队能够在数小时甚至数分钟内将功能部署到生产中。
4-独立 (4 — Independency)
No company wants to have one supplier only in the supply chain, especially when it involves the core service of this company: software. This is the case of the majority of companies that rely on mainframes. IBM dominates this market, accounting for more than 90% of all mainframes in the world. Public cloud providers, in contrast, are competing against each other in a healthy way causing the price to drop significantly in the last five years or so.
没有公司希望仅在供应链中拥有一个供应商,尤其是当涉及该公司的核心服务:软件时。 大多数依赖大型机的公司就是这种情况。 IBM主导了这一市场,占全球所有大型机的90%以上。 相反,公共云提供商正在以健康的方式相互竞争,导致价格在过去五年左右的时间内大幅下降。
Even if the company decides to have its own datacenter, which happens sometimes, it would have no ties to a specific supplier since the market is diversified in this field.
即使该公司决定拥有自己的数据中心(有时会发生这种情况),但由于该领域的市场多样化,因此它与特定的供应商也没有任何关系。
5—复杂性 (5— Complexity)
Finally, when big companies migrate their backend infrastructure to the cloud using distributed systems, they can develop complex backend services in a timely way. What I mean is that many of the operations that are performed by the frontend services can now be completely coded in the backend. This is true because most of the time when they use only mainframe computers, they cannot complete operations like image analysis using artificial intelligence, for example, inside the mainframe architecture.
最后,当大公司使用分布式系统将其后端基础架构迁移到云时,他们可以及时开发复杂的后端服务。 我的意思是,前端服务执行的许多操作现在都可以在后端中完全编码。 之所以如此,是因为在大多数情况下,当他们仅使用大型机时,便无法在大型机体系结构内完成诸如使用人工智能进行图像分析之类的操作。
As a consequence, most of the time companies use the frontend to do these operations, or even specific services to provide that. When a microservice architecture is chosen, in contrast, this operation can be achieved without any major technical barriers.
结果,大多数时候公司会使用前端来执行这些操作,甚至使用特定的服务来提供这些操作。 相反,当选择微服务架构时,可以在没有任何主要技术障碍的情况下实现此操作。
卡夫卡 (Kafka)
Now that we’ve talked about the importance of having a complete distributed platform, let’s talk about the types of open-source solutions available to support such design. The Apache Kafka is one of the most popular message broker components used for managing and orchestrating messages. With last than 10 years of existence, Kafka has become a key component in almost all large-scale and cloud-based architectures.
既然我们已经讨论了拥有一个完整的分布式平台的重要性,那么让我们来谈谈可用于支持这种设计的开源解决方案的类型。 Apache Kafka是用于管理和编排消息的最流行的消息代理组件之一。 已有10多年的历史了,Kafka已成为几乎所有大型和基于云的体系结构中的关键组件。
Long story short, Kafka is used as a message exchange by microservices, services, ou third-party applications, like Hadoop, for data analysis.
长话短说,Kafka被微服务,服务或第三方应用程序(如Hadoop )用作消息交换以进行数据分析。

架构注册表 (Schema Registry)
The integrity and control of the data that is being produced and consumed through Kafka are made by the Schema Registry. All the governance, rules, and structure are defined in an Avro file, and the Schema Registry makes sure only messages that are in line with these standards are allowed on Kafka.
通过Kafka生成和使用的数据的完整性和控制权由Schema Registry进行 。 所有治理,规则和结构都在Avro文件中定义,并且Schema Registry确保在Kafka上仅允许符合这些标准的消息。
码头工人 (Docker)
Most of the public cloud providers do offer KaaS (Kafka As A Service) option, like EKS, and there are companies like Confluent that provides customer support for on-premise data centers as well.
大多数公共云供应商的报价做卡斯(卡夫卡即服务)选项,如EKS ,还有像企业合流 ,提供客户内部部署的数据中心支持。
When developing microservices with Kafka and Schema Registry, most of the time we need to run these components locally to test our software. This is one of the main reasons why we use Docker(one of many, of course). With Docker Compose we are able to run several containers in our personal computer, allowing us to run Kafka and Schema Registry simultaneously.
在使用Kafka和Schema Registry开发微服务时,大多数时候我们需要在本地运行这些组件以测试我们的软件。 这是我们使用Docker的主要原因之一(当然是众多原因之一)。 使用Docker Compose,我们能够在个人计算机中运行多个容器 ,从而使我们能够同时运行Kafka和Schema Registry。
In order to do so, we need to create a file named Dockfile with the following images:
为此,我们需要使用以下图像创建一个名为Dockfile的文件:
FROM confluentinc/cp-kafka-connect:5.1.2 ENV CONNECT_PLUGIN_PATH="/usr/share/java,/usr/share/confluent-hub-components" RUN confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:latestNext, we’ll create our docker compose file named docker-compose.yml
接下来,我们将创建名为docker-compose.yml的docker compose文件。
---
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:5.1.2
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-enterprise-kafka:5.1.2
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:9092
CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper:2181
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
schema-registry:
image: confluentinc/cp-schema-registry:5.1.2
hostname: schema-registry
container_name: schema-registry
depends_on:
- zookeeper
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper:2181'
rest-proxy:
image: confluentinc/cp-kafka-rest:5.1.2
depends_on:
- zookeeper
- broker
- schema-registry
ports:
- 8082:8082
hostname: rest-proxy
container_name: rest-proxy
environment:
KAFKA_REST_HOST_NAME: rest-proxy
KAFKA_REST_BOOTSTRAP_SERVERS: 'broker:9092'
KAFKA_REST_LISTENERS: "http://0.0.0.0:8082"
KAFKA_REST_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'Finally, let’s launch our containers locally.
最后,让我们在本地启动容器。
$ docker-compose upWhen we perform the command docker ps -a, we can see our containers up and running.
当我们执行命令docker ps -a时 ,我们可以看到我们的容器正在运行。

If you prefer, I have included this code on my GitHub.
如果您愿意,我已经在GitHub中包含了此代码。
Alternatively, you can also run Kafka and Schema Registry embedded using this awesome Java component developed by Marcos Vallim.
另外,您也可以使用Marcos Vallim开发的这个很棒的Java组件运行嵌入的Kafka和Schema Registry。
Spring Boot微服务 (Spring Boot Microservices)
Now is time to create our microservices. The idea here is to create two microservices in Java. The one named kafka-holder will contain an API endpoint that performs a payment. Once it receives this HTTP request, it will send an Avro event to Kafka and wait for the response.
现在是时候创建我们的微服务了。 这里的想法是用Java创建两个微服务。 一个名为kafka-holder的人将包含一个执行付款的API端点。 收到此HTTP请求后,它将向Kafka发送一个Avro事件,并等待响应。
The service kafka-service will then consume this message from Kafka, process the payment, and produce a new event stating whether the payment was processed or not.
然后,服务kafka-service将使用来自Kafka的此消息,处理付款,并产生一个新事件,说明是否已处理付款。
The Avro event for the payment request is defined below.
付款请求的Avro事件定义如下。
{
"namespace": "com.jaimedantas",
"type": "record",
"name": "Payment",
"fields": [
{"name": "id", "type": "string"},
{"name": "amount", "type": "double"}
]
}The architecture created here uses Kafka and Schema Registry to orchestrate the messages.
此处创建的体系结构使用Kafka和架构注册表来协调消息。
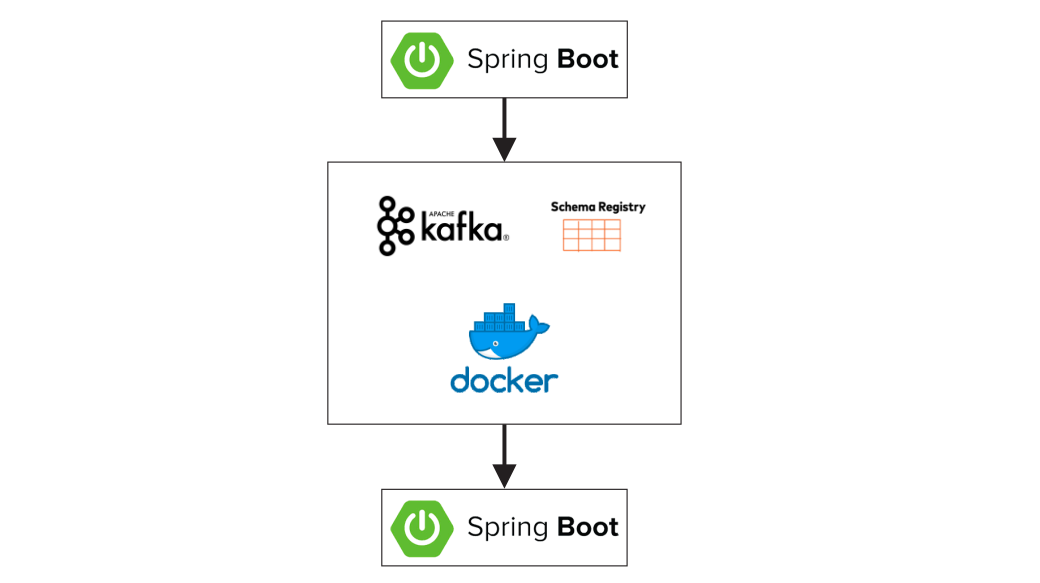
Note that both applications are consumers and producers simultaneously. By doing this approach, we can scale up and down our microservices individually. This guarantee we are now wasting any resources, and we are using our money where we really need to.
请注意,这两个应用程序同时是消费者和生产者。 通过这种方法,我们可以分别扩展和缩减微服务。 这保证了我们现在正在浪费任何资源,我们在真正需要的地方使用了我们的钱。
Another advantage this architecture brings is the fact that no message is lost in case of any downtime of a given microservice. This is counting that we will have DLQ (Dead Letters Queues) and a good resilience solution in our project though.
该体系结构带来的另一个优势是,在给定的微服务出现任何停机的情况下,不会丢失任何消息。 这是指我们的项目中将拥有DLQ(死信队列)和良好的弹性解决方案。
In case we need to find out what happened to a given transaction, we also can check the Kafka broker and find this specific event there.
万一我们需要找出给定交易发生了什么,我们还可以检查Kafka经纪人并在那里找到此特定事件。
This post presented some general overview of the history of computer power and software development over the last decades. It also showed some key benefits of using distributed solutions when dealing with a large number of services and data.
这篇文章简要介绍了过去几十年中计算机功能和软件开发的历史。 它还显示了在处理大量服务和数据时使用分布式解决方案的一些关键优势。
I hope this article helped you understand why this trend of cloud computing and event-based systems came to stay, and why it will replace most of the ancient mainframe systems in the long term.
我希望本文能帮助您理解为什么云计算和基于事件的系统的这种趋势会持续存在,以及从长期来看为什么它将取代大多数古老的大型机系统。
If you have any questions, please feel free to drop a comment.
如有任何疑问,请随时发表评论。
Thanks for reading it!
感谢您阅读!
kafka分布式















 5161
5161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









