







提到消息中间件,Kafka是我们经常提及的,不过消息中间件的属性只能说是它的基础属性之一,如果你去看官网的简介,会称其为分布式事件流平台,事件流的处理才是它最核心的特点;在我看来,Kafka应该是目前性能最高的开源的事件流平台了,很多开发者可能只是使用了Kafka的Produce和Consume接口来进行消息流的应用,其实它的Connect和Stream API是真正能体现Kafka在流处理上的优势的特性。
Kafka的历史
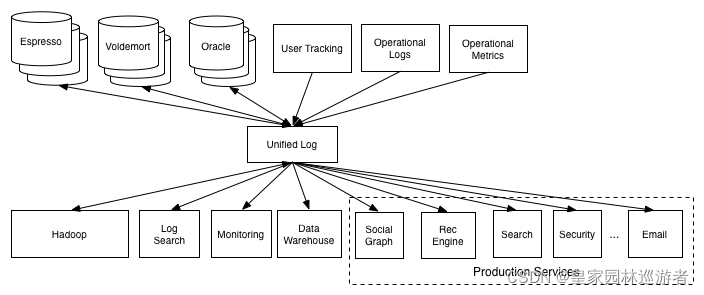
很多时候优秀的开源项目并不是作者突发奇想地写出来的,而是由实际的业务需求推动后逐步完善的。按照维基百科的介绍,在Kafka正式成为一个开源项目前,它的原型来自LinkedIn公司内部的数据中间件系统(大概在2011年),当时开发该系统的工程师们感觉它的设计理念可以适用于很多业务场景,于是重构之后正式开源化。其中一个工程师Jay Kreps在他的博客 The Log: What every software engineer should know about real-time data’s unifying abstraction 中详细叙述了Kafka的由来、设计思想和技术细节;通过他的叙述我们可以知道,当时在LinkedLin的软件系统中,一个最大的痛点是存在很多不同类型的数据源和数据处理子系统,而这些子系统和数据源之间存在极为混乱的数据流交互,因此他们设计了一个基于日志的高性能中间件来进行解耦,这就是Kafka原型最初的设计背景。Kafka这个名字也是Jay Kreps取的,来自于小说家弗兰茨·卡夫卡的名字,就是那个著名的《变形记》的作者
一开始,Kafka是以Apache基金会的名义进行开源的,所以称之为Apache Kafka; 因为这个项目非常火热,并且具有非常大的扩展空间,一家名为Confluent的公司以Apache Kafka为基础组件,扩展了许多其他的功能组件,并称之为Confluent Kafka,可以看成是Apache Kafka的扩展版本,当然这里面某些组件是收费的。为啥这家公司能有能力推出这个加强版,是因为Apache Kafka的大部分的核心贡献者都在这个公司!不太确定是不是这些贡献者创建的这个公司
Apache Kafka 和 Confluent Kafka


如果你去Google搜索Kafka,首先搜出的结果都是Confluent Kafka,而非Apache Kafka,这可能会给初学者带来一些困惑。正如上面所说的Apache Kafka和Confluent Kafka的历史,Confluent Kafka是Confluent公司基于Apache Kafka推出的组件库,Apache Kafka包括的基础组件,也是Confluent Kafka的基本组件,其代码其实就是一样的。下面这张从官网保存的示意图展示了两者的关系,也展示了Confluent Kafka所包含的组件类型,和外部系统的整合关系
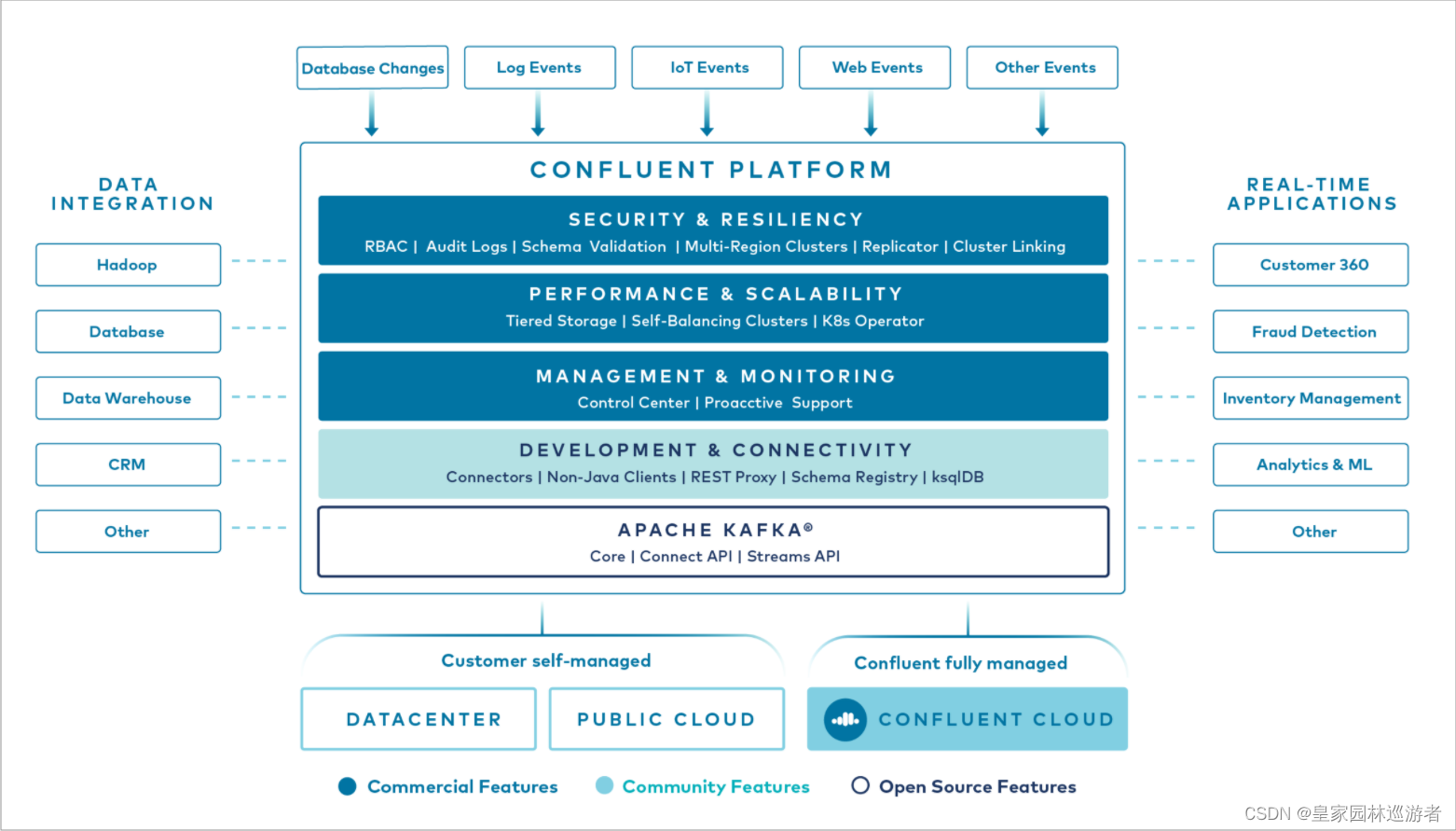
Confluent Kafka是Confluent公司推出的,所以包含了非开源组件或服务,不过不用太担心,Apache Kafka的组件,仍然是随意使用的,只有部分组件才是遵循商业许可证的。事实上,Confluent Kafka制定了两种License:Community和Commercially。Community就是社区版,基本等同于Apache 2.0;Commercially则是商业版。可以在Confluent Kafka的官方问答中查看具体信息(Confluent Community License FAQ)
对于想要查看文档的初学者来说,推荐还是直接看Confluent Kafka的官方文档,虽然说Apache Kafka和Confluent Kafka是并存的状态,它们各自的文档都被持续维护,但是Confluent Kafka的官方文档更加详细,新手教程更多。
Apache Kafka的官方文档地址: Apache Kafka Documentation
Confluent Kafka的官方文档地址: Confluent Kafka Documentation
Kafka和Zookeeper
在安装和配置Kafka环境时,你会发现Zookeeper模块是必需的核心模块。Kafka最开始就是设计为分布式系统的,不过这个项目本身要处理的核心问题是基于日志模型的数据流,至于集群内节点的管理则直接使用了Zookeeper这个项目。这一设计其实存在某些问题,尤其当Kafka这个项目变得越来越大,甚至扩展出商用组件的时候,因为这两个项目都是面向分布式的,各自的系统设计又有很大区别,对开发和维护者来说,两个系统存在功能冗余;对使用者来说,则需要额外学习Zookeeper的知识体系。Kafka的贡献者们也早就意识到这个问题,从Apache Kafka 2.8版本开始,他们开始尝试去除掉对Zookeeper的依赖,改为开发Kafka自身的集群元数据管理模块,不过目前这一设计还不完善。你可以在这篇博客中查看细节: Removing the Apache ZooKeeper Dependency
总之,目前要搭建一个Kafka环境,还是绕不开Zookeeper的
搭建一个Kafka环境
现在让我们先搭建一个单节点的Kafka环境。
一种简单的方案是按照Apache Kafka的Quick Start文档,直接下载Apache Kafka的文件包,本质上Apache Kafka的各个模块其实就是运行这个文件包内的不同执行程序。不过这种安装方式太过朴素,我们后续还得自己动手完善环境,比如得自己创建服务执行脚本,把文件包内的Zookeeper和Kafka打包成自启动服务。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 8545
8545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









