






MySQL索引模型
MySQL索引模型
1. 常见索引模型
1.1 什么是索引
MySQL索引原理及慢查询优化
索引是排好序的快速查找数据结构,索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql
有了这样的字典我们就可以避免全表扫描从而提高查找效率
优势
提高了数据检索的效率,降低了数据库的IO成本
降低了数据排序的成本,降低了CPU的消耗
劣势
实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引也要占用空间
少量数据,频繁增删改的数据以及很少使用的数据都不适合使用索引
虽然索引大大提高了查询速度,同时确会降低更新表的速度,因为每次更新要去改变索引信息
如果MySQL表过大就需要花费大量的时间研究建立最优秀的索引
1.2 常见的索引模型
1?? 哈希索引
在MySQL中,只有Memory引擎显式支持哈希索引,这也是Memory引擎表的默认索引类型
注意??
hash索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免对行的查找
hash索引不按索引值顺序存储,所以无法用于排序,在做区间查询等非等值查询的时候要把整个表遍历一遍,效率低
hash索引不支持部分索引列匹配查找,因为hash索引始终实用化索引列的全部内容来计算哈希值的
自适应hash索引
InnoDB引擎有一个特殊的功能叫做 自适应哈希索引(adaptivehash index)。
当InnoDB注意到某些索引值被使用得非常频繁时,它会在内存中基于B-Tree索引之上再创建一个哈希索引,这样就让B-Tree索引也具有哈希索引的一些优点,比如快速的哈希查找。 这是一个完全自动的、 内部的行为,用户无法控制或者配置,不过如果有必要, 完全可以关闭该功能。
2?? 搜索树
在二叉树搜索的时间复杂度是O(log(n)),当然为了维持 O(log(N)) 的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是 O(log(N))
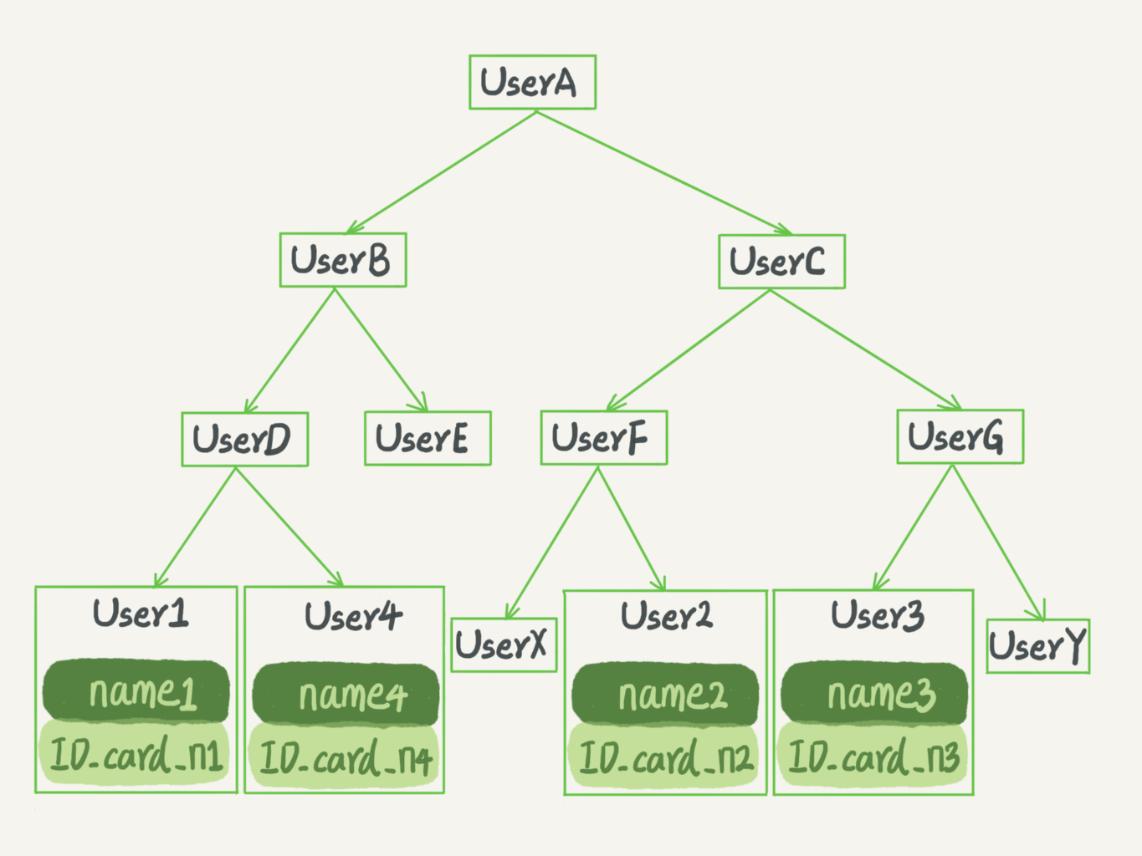
二叉树的搜索效率最高,但实际上大多数数据库存储都不使用二叉树
索引是存储在磁盘上的,当数据量较大的时候我们无法一次把索引都加载到内存,只能逐一加载索引树的每个节点,每个节点也不是顺序存放的,所以实际上是逐一加载每个磁盘页;
在最坏情况下,磁盘的io次数等于树的高度
频繁的io是阻碍提升性能的瓶颈
如何减少io次数
时间局部性原理:*假如你查询id为1的用户数据,过一段时间你还会查询id为1的数据,所以会将这部分数据缓存下来
空间局部性原理:*当你查询id为1的用户数据的时候,你有很大的概率会去查询id为2,3,4的用户的数据,所以会一次性的把id为1,2,3,4的数据都读到内存中去,这个最小的单位就是页
3?? B树
漫画算法 什么是B树
之所以不使用搜索树是因为他的高度太高导致io操作频繁,所以解决方法就是降低树的高度,把瘦高的树变得矮胖
B树又称为平衡多路查找树,即不止两个子树的查找树
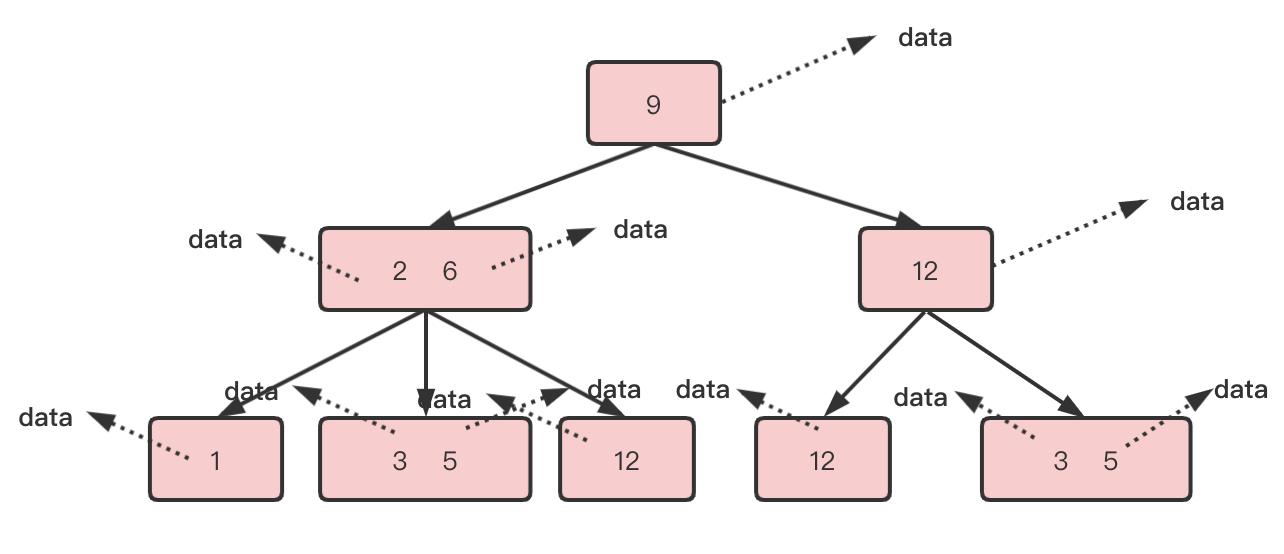
B树中所有节点都带有卫星数据,卫星数据指的是索引元素所指向的数据记录
4?? B+树
漫画:什么是B+树?
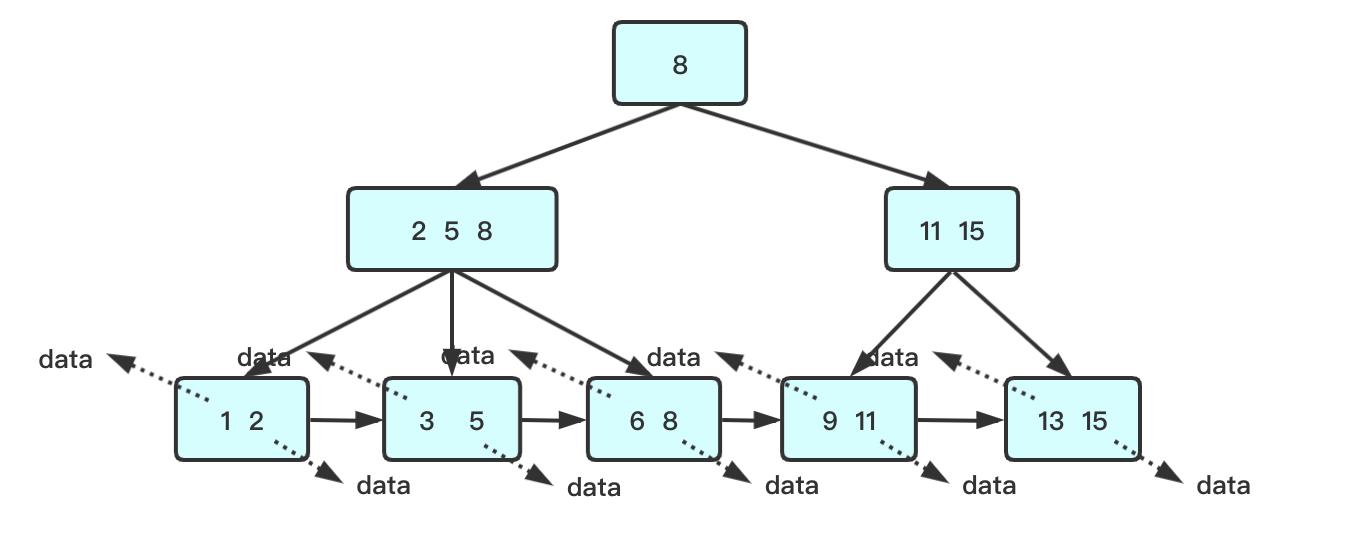
B+树只有叶子才带卫星数据,其他都只是索引,
B+树的优势:
由于B+树的中间节点不带卫星数据,所以单一节点能存储更多的元素,使得查询的IO次数更少
所有查询都要查找到叶子节点,查询性能稳定
所有叶子节点形成有序链表,便于范围查询
2. InnoDB 的索引模型 vs MyISM的索引模型
数据库文件存储是已页为存储单元的,一个页是8K(8192Byte),一个页就可以存放N行数据。我们常用的页类型就是数据页和索引页。一个页中除了存放基本数据之外还需要存放一些其他的数据,如页的信息、偏移量等
2.1 MyISM的索引模型
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址
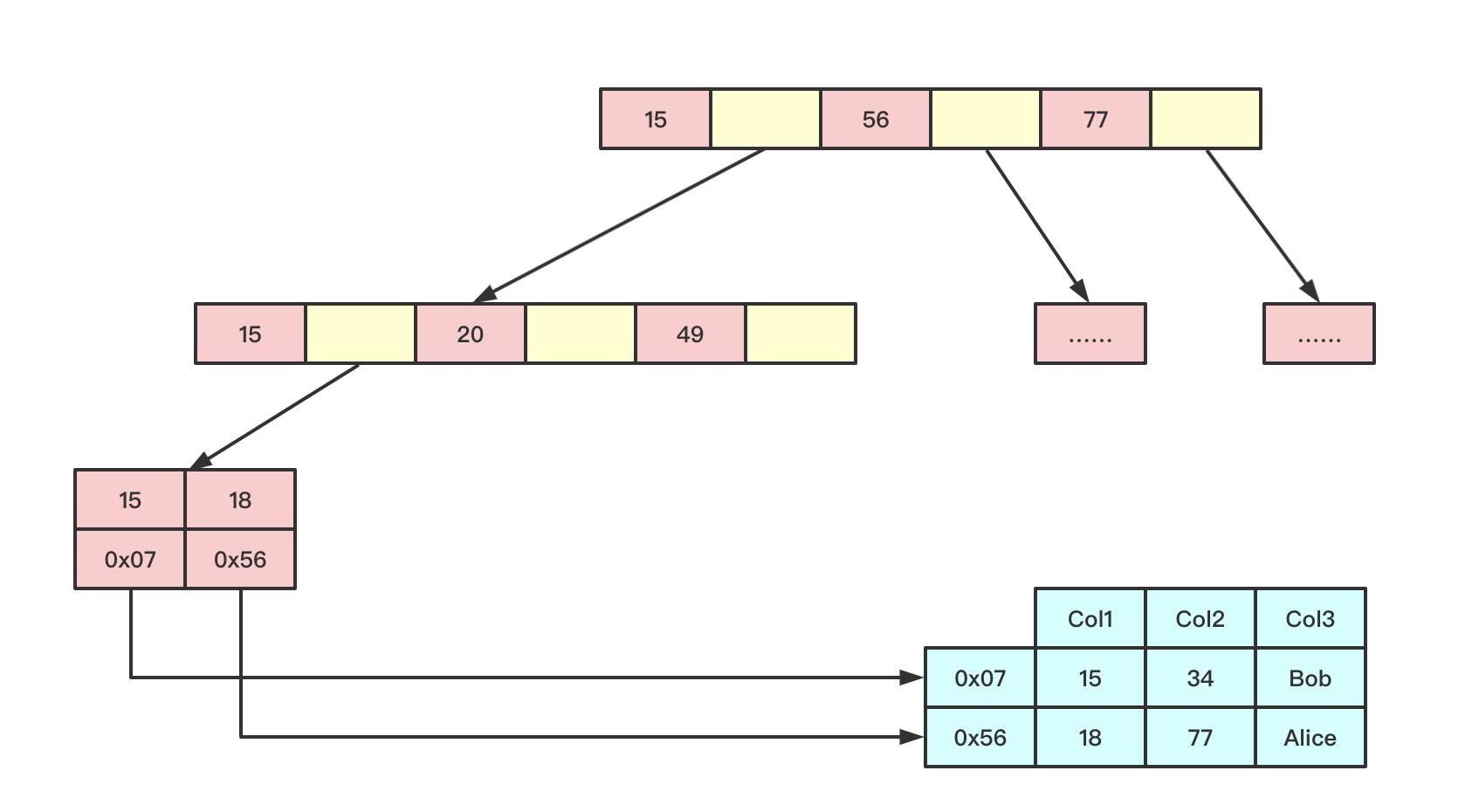
2.2 InnoDB索引实现
InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同
InnoDB的数据文件本身就是索引文件,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录,而其他节点不会保存完整的数据记录,仅仅保存索引(和指向下一层的指针)
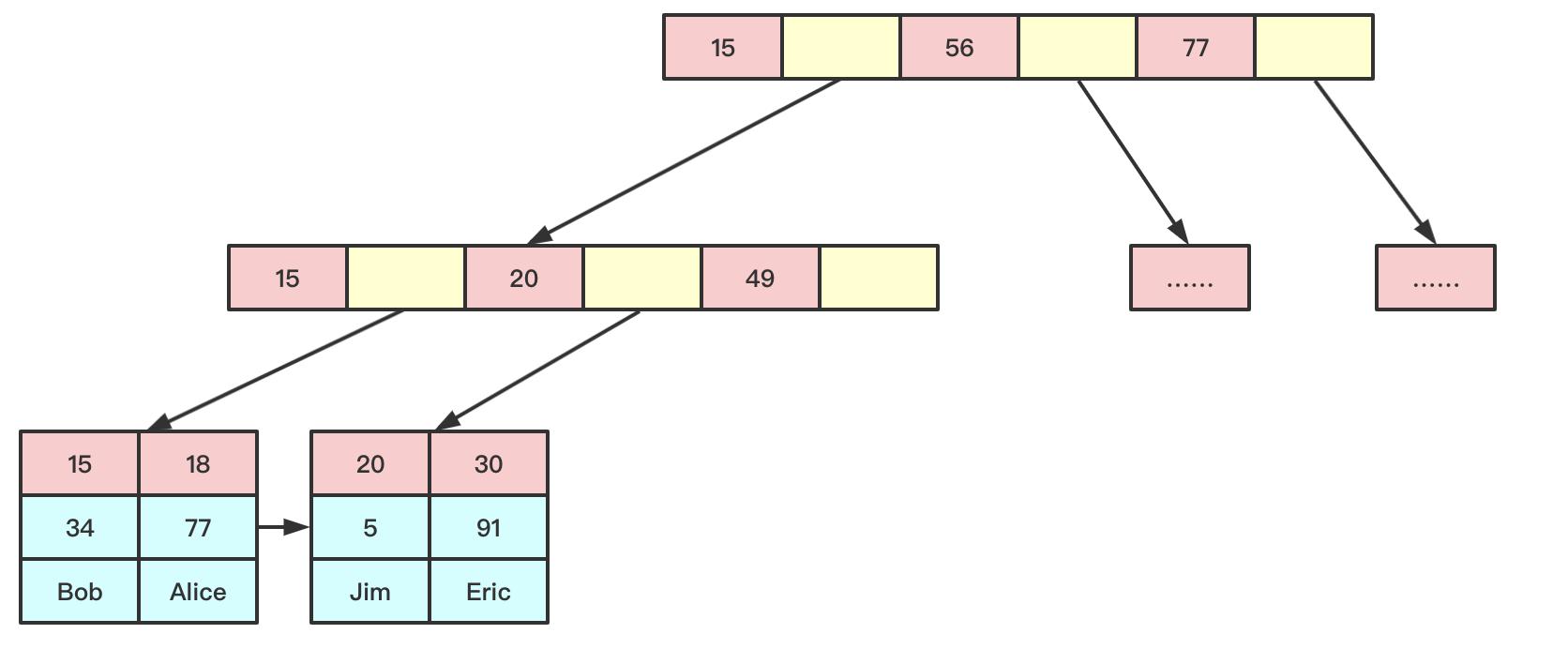
对于主键索引,索引的key是数据表的主键
对于辅助索引data域存储相应记录主键的值而不是地址,正是以为如此才不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大

用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效
3. 聚簇索引 vs 非聚簇索引
聚簇索引和非聚簇索引(通俗易懂 言简意赅) - 创天创世纪 - 博客园
3.1 聚簇索引
数据和索引存储到一起,找到索引就获取到了数据,Innobd中的主键索引是一种聚簇索引
聚簇索引是唯一的,因为无法同时把数据行存放在两个不同的地方;InnoDB一定会有一个聚簇索引来保存数据。非聚簇索引一定存储有聚簇索引的列值
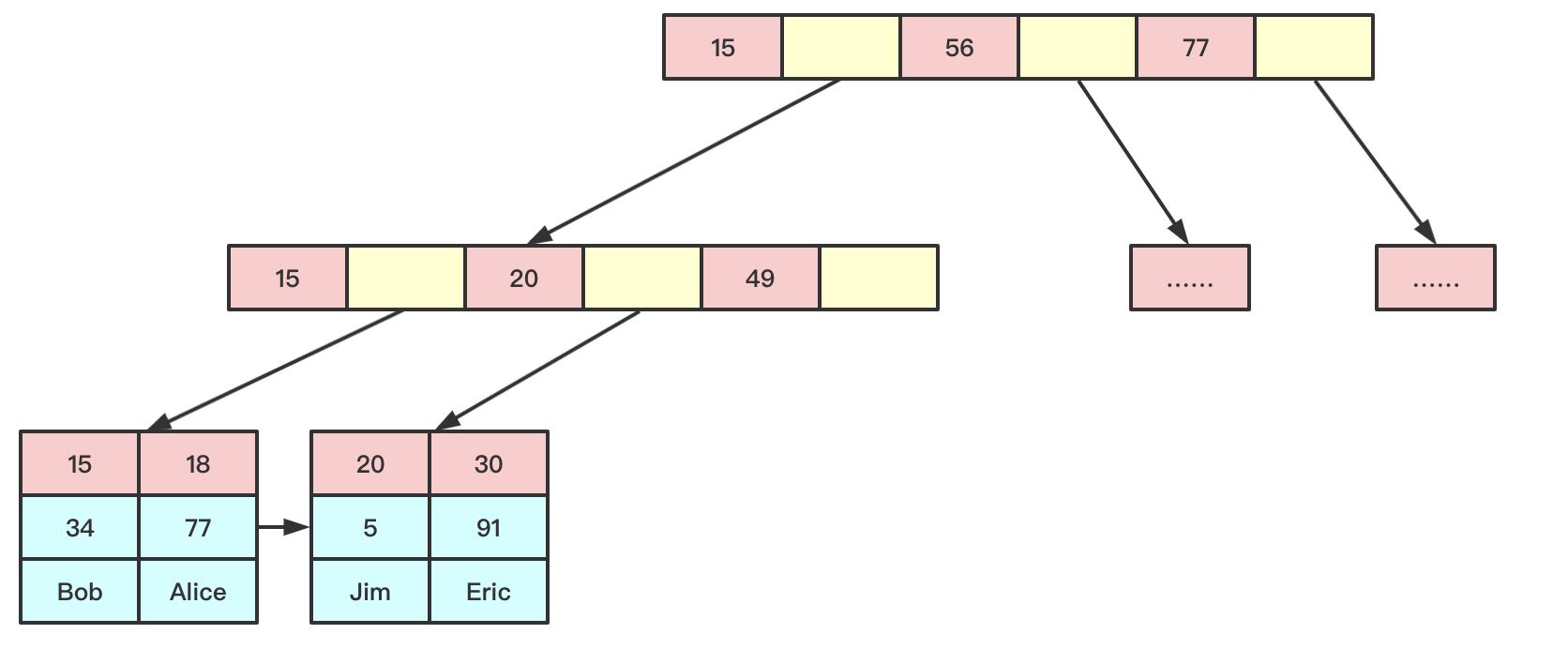
InnoDB聚簇索引选择顺序:
默认选择主键来聚簇数据
没有主键,选择唯一的非空索引;
都没有,则隐式定义一个主键;
优点:
数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
聚簇索引对于主键的排序查找和范围查找速度非常快
缺点:
插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
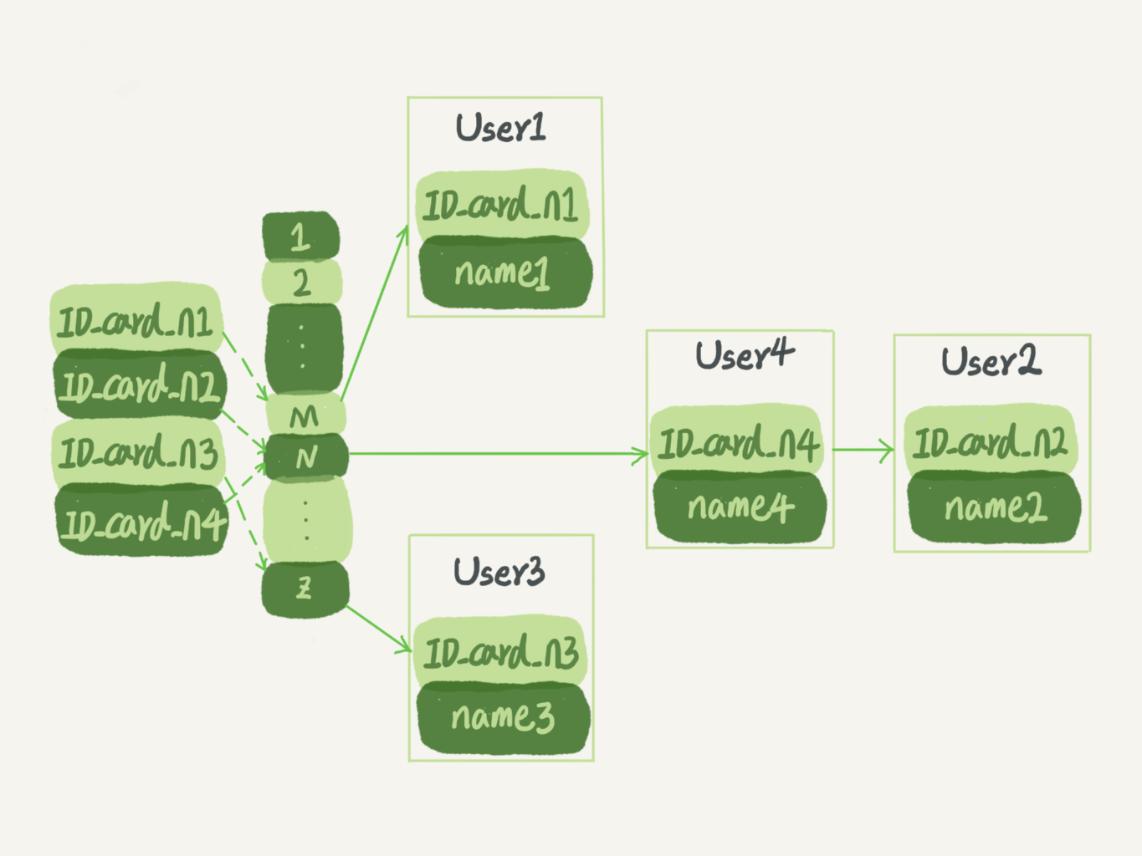
二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据
对于第三点,在innidb中使用自适应hash索引解决:
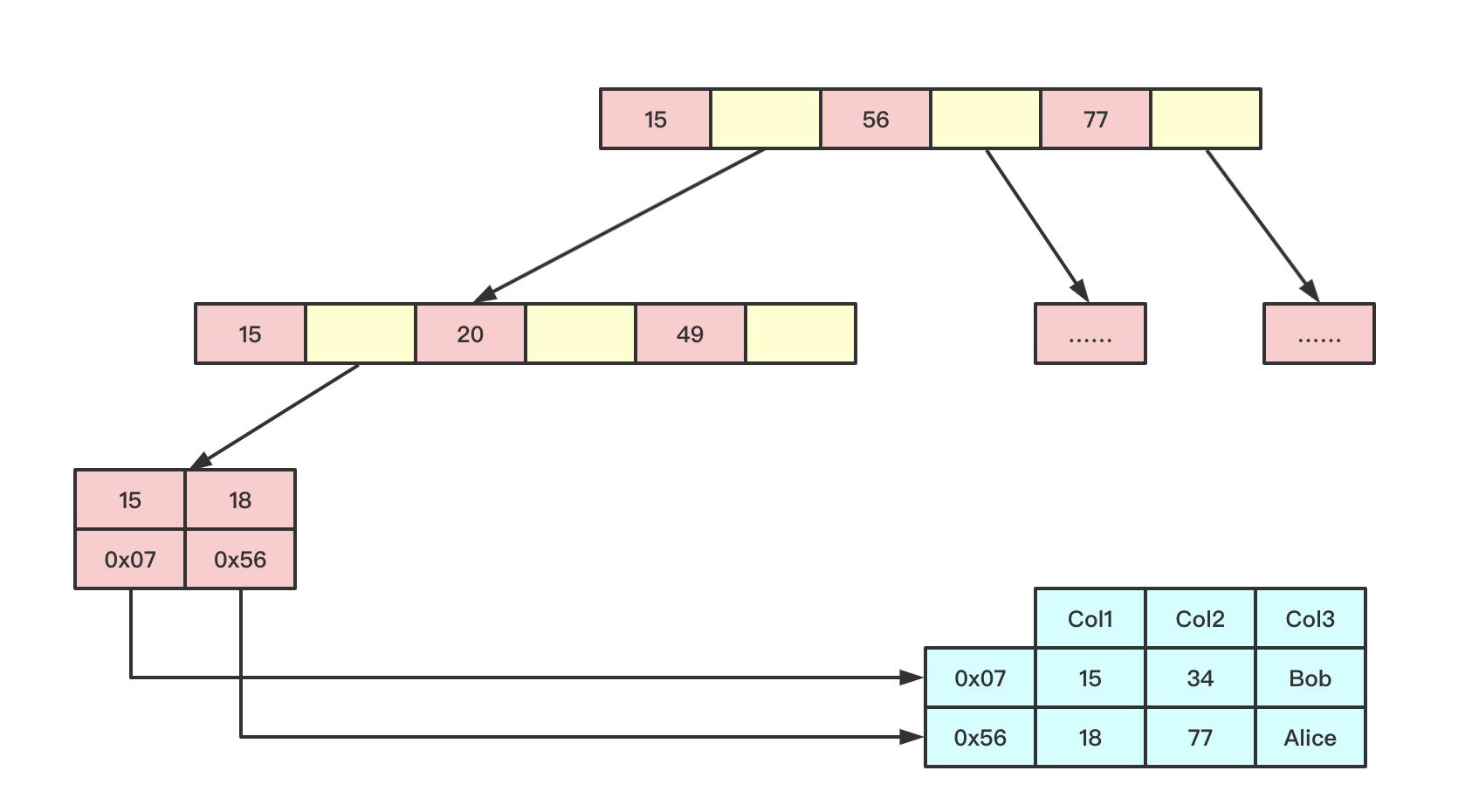
3.2 非聚簇索引
数据存储和索引分开,叶子节点存储对应的行,需要二次查找,通常称为[二级索引]或[辅助索引]
比如对于Innodb辅助索引的叶子节点并不包含行记录的全部数据,叶子节点除了包含键值外,还包含了相应行数据的聚簇索引键
对于myism是在叶子结点记录数据地址
MySQL索引模型相关教程














 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









