





apache kafka
The title sounds cool, right? I know, but what is this distributed tracing? I had the same question when I was asked to set one up for a client.
吨他的标题听起来很酷吧? 我知道,但是这种分布式跟踪是什么? 当我被要求为客户设置一个时,我也有同样的问题。
让我们获得一些背景 (Let’s get some background)
Distributed tracing is a method used to debug, monitor, and troubleshoot applications built using modern distributed software architectures. The applications should be instrumented with the OpenTracing APIs* to identify an incoming request to pinpoint where failures occur and what causes poor performance.
分布式跟踪是一种用于调试,监视和故障排除使用现代分布式软件体系结构构建的应用程序的方法。 应使用OpenTracing API *对应用程序进行检测,以识别传入请求,以查明发生故障的位置以及导致性能下降的原因。
Jaeger is an OpenSource distributed tracing technology graduate by Cloud Native Computing Foundation (CNCF) used to monitor and troubleshoot microservice-based distributed systems for performance optimization, root cause analysis, service dependency analysis, and many more use cases. It comprises five components:
Jaeger是Cloud Native Computing Foundation(CNCF)毕业的一种开源分布式跟踪技术,用于监视和调试基于微服务的分布式系统,以进行性能优化,根本原因分析,服务依赖性分析以及更多用例。 它包括五个组成部分:
Client: A language-specific OpenTracing API that is implemented by instrumenting the applications
客户端:特定于语言的OpenTracing API,可通过对应用程序进行检测来实现
Agent: a network daemon that listens for spans** and sends it over to collectors
代理:一个网络守护程序,侦听跨度**并将其发送给收集器
Collector: Validates, indexes and stores the traces received from the agents
收集器:验证,索引和存储从代理收到的跟踪
Ingester: An integrated service between the Kafka topic and storage backend
接收器: Kafka主题和存储后端之间的集成服务
Query: a service to retrieve the traces*** from a storage backend and hosts a UI to display them
查询:从存储后端检索跟踪***并托管UI来显示跟踪的服务
* The OpenTracing API provides a standard, vendor-neutral framework for instrumentation. A developer can introduce a different distributed tracing system by simply changing the configuration of the Tracer in the code.
* OpenTracing API提供了一个标准的,与供应商无关的工具框架。 开发人员可以通过简单地在代码中更改Tracer的配置来引入不同的分布式跟踪系统。
** Span represents a single unit of work that includes the operation name, start time, and duration
** Span代表单个工作单元,包括操作名称,开始时间和持续时间
*** A trace is made up of one or more spans
***迹线由一个或多个跨度组成
今天的云中有什么?(What’s in the Cloud today?)
Now that we learned some Jaeger jargon let’s talk about this specific use case at play. The client I worked with had set up the entire Jaeger stack on Amazon Web Services (AWS) as follows:
现在,我们了解了一些Jaeger行话,下面我们来讨论这个特定的用例。 我与之合作的客户端已在Amazon Web Services(AWS)上设置了整个Jaeger堆栈,如下所示:
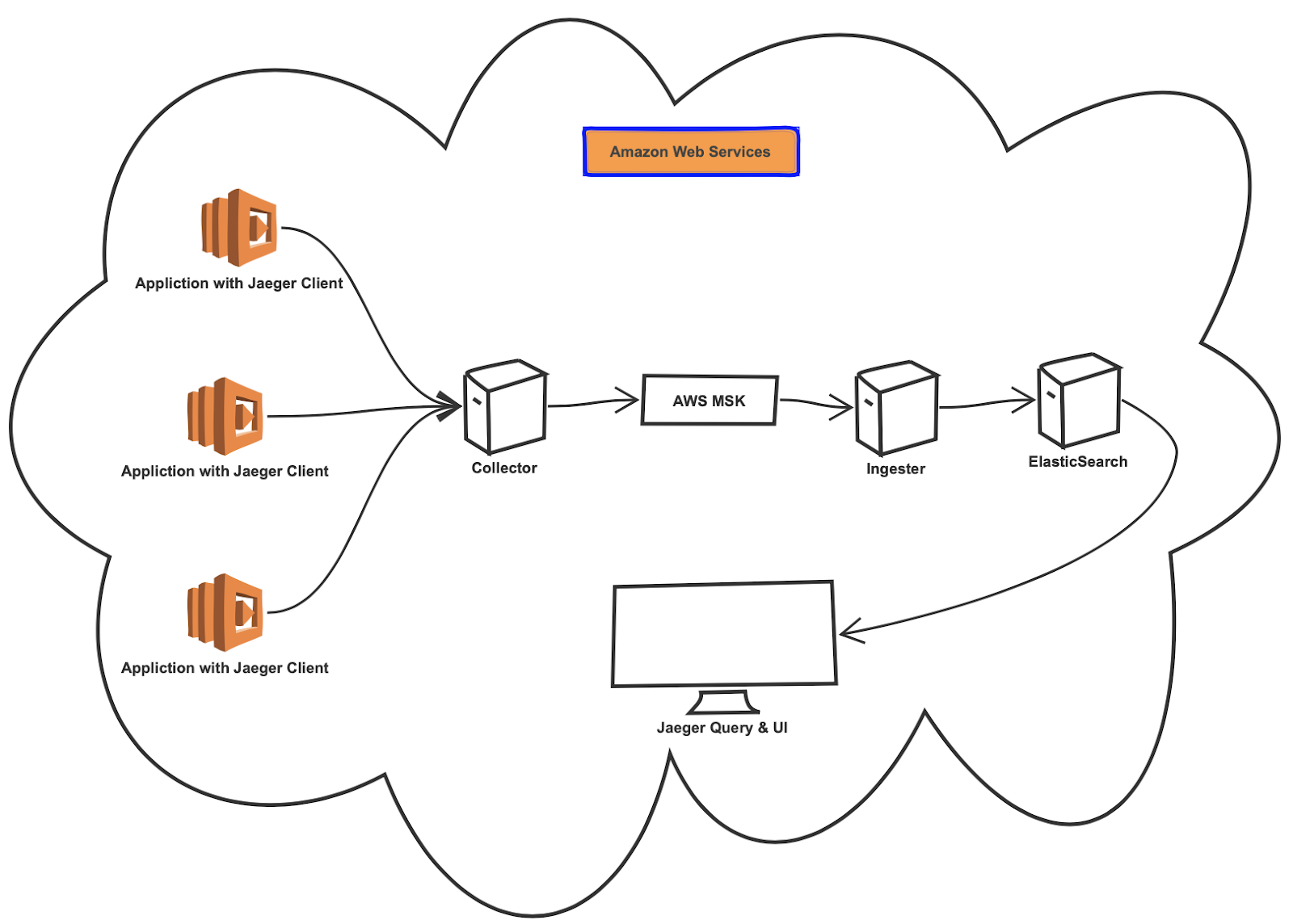
- Applications are instrumented with the Jaeger Clients (AWS Lambda Functions) to interact directly with the Jaeger collector to forward the spans 应用程序通过Jaeger客户端(AWS Lambda函数)进行检测,以直接与Jaeger收集器进行交互以转发跨度
- The Jaeger collector is deployed on an EC2 instance and configured with an AWS Managed Streaming for Apache Kafka (MSK) to validate, index and store the spansJaeger收集器部署在EC2实例上,并配置有适用于Apache Kafka(MSK)的AWS托管流,以验证,索引和存储跨度
- The Jaeger Ingester was set up on an EC2 instance to read the spans from AWS Kafka and write it to the Elastic Search to view them on the Jaeger UIJaeger Ingester是在EC2实例上设置的,以从AWS Kafka读取跨度并将其写入弹性搜索以在Jaeger UI上查看它们
要求(The Requirement)
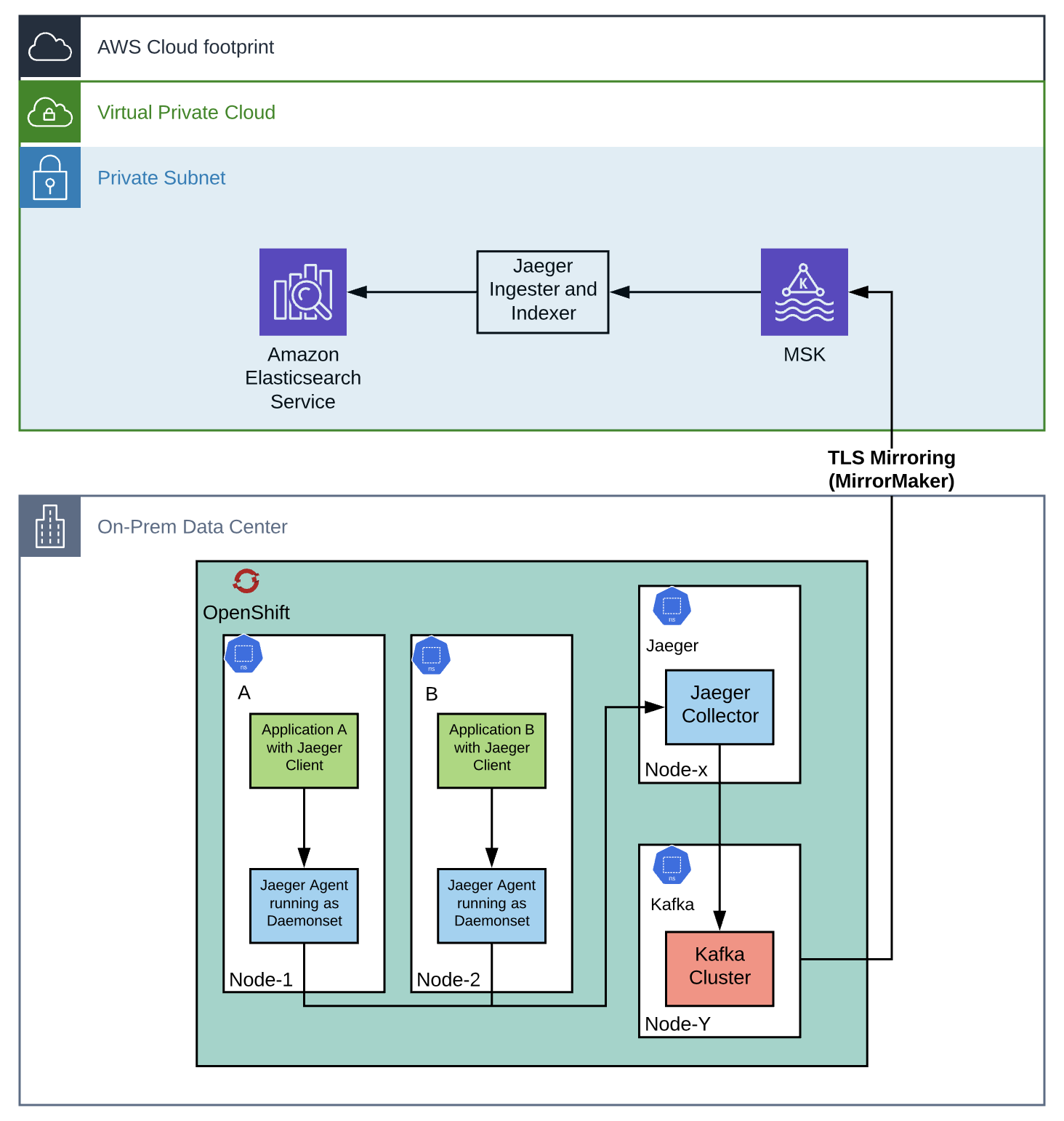
It seems like everything is in place, right? No! Here comes the tricky part; the client has planned to implement distributed tracing (Jaeger) for the mission-critical applications running on an On-Prem OpenShift cluster for analytics, visualization, and reporting.
一切似乎都准备就绪,对吧? 没有! 棘手的部分到了。 客户已计划为在本地OpenShift集群上运行的任务关键型应用程序实施分布式跟踪(Jaeger),以进行分析,可视化和报告。
Given the requirements, the initial plan was to send the traces directly from agents (on OpenShift cluster) to the collector (on AWS).
鉴于需求,最初的计划是将跟踪直接从代理(在OpenShift集群上)发送到收集器(在AWS上)。
Sounded pretty straight forward at first glance, but a wrench was thrown in as I realized the data transfer between On-Prem applications and AWS has to be secure. I also found that there wasn’t enough bandwidth to send real-time span data from the Jaeger agent (on OpenShift cluster) to the Jaeger collector (on AWS). If the spans are backed up, the agents will drop the spans and the whole purpose will be defeated. Even though Jaeger supports gRPC TLS communication between the agent and the collector, bandwidth was a primary concern.
乍一看听起来挺直截了当,但是当我意识到On-Prem应用程序和AWS之间的数据传输必须安全时,却一掷千金。 我还发现,没有足够的带宽将实时跨度数据从Jaeger代理(在OpenShift集群上)发送到Jaeger收集器(在AWS上)。 如果备份了跨度,则代理将放弃跨度,并且整个目标将失败。 即使Jaeger支持代理与收集器之间的gRPC TLS通信,带宽也是首要考虑的问题。
白板会议 (Whiteboard Session)
With the bandwidth and security in transit issues, I had to go back to the drawing board and come up with a solution to address these two significant areas:
考虑到传输中的带宽和安全性,我不得不回到制图板上,想出解决以下两个重要领域的解决方案:
On-Prem Data retention in case of connectivity issues or data queuing due to bandwidth limitations
由于带宽限制而出现连接问题或数据排队时的本地数据保留
Network bandwidth limitation between On-Prem Openshift Cluster and AWS
本地Openshift群集和AWS之间的网络带宽限制
After hours of brainstorming, I came up with the following: well, to start off with,
经过数小时的头脑风暴,我想到了以下几点:首先,
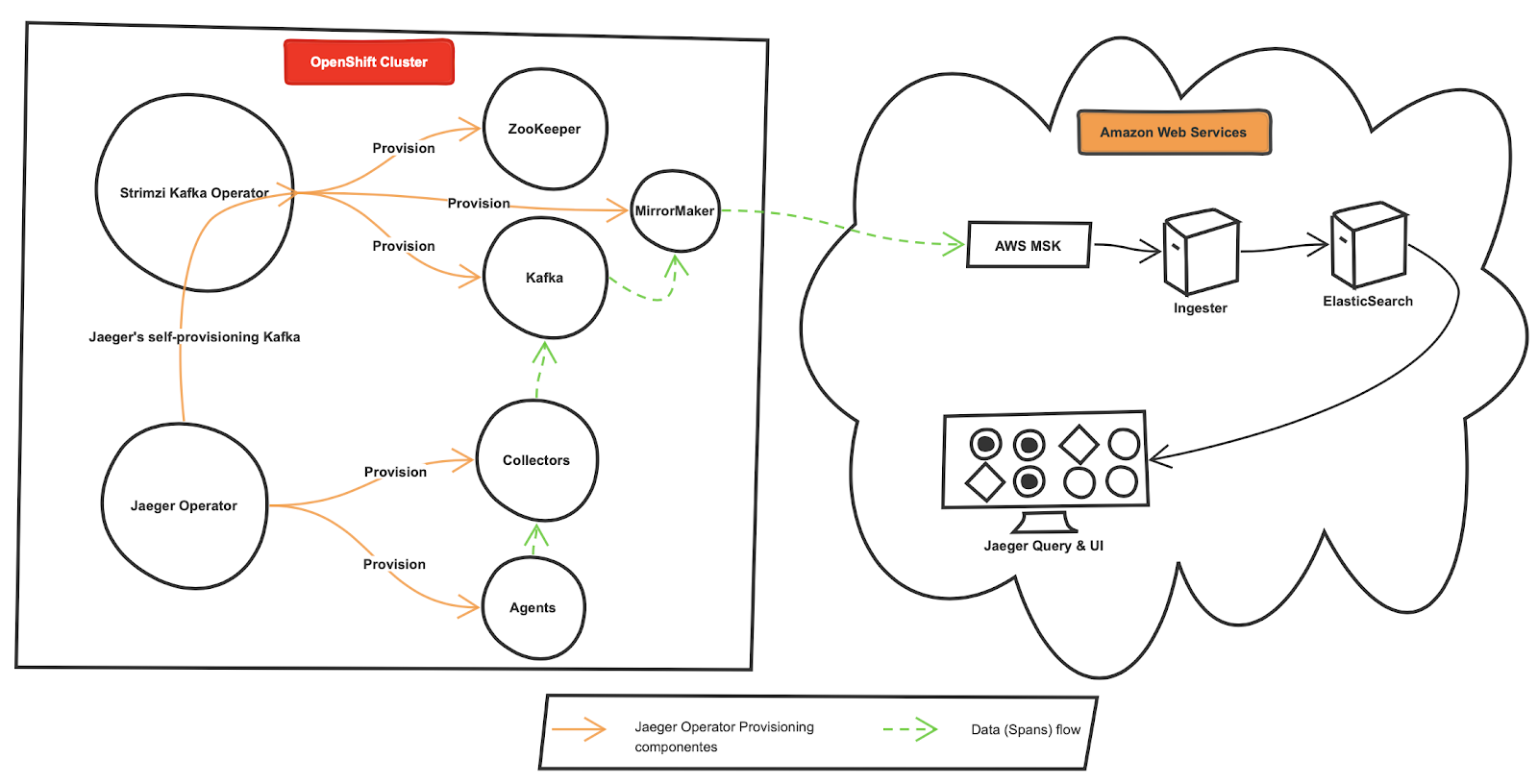
- Ensure the version compatibility between Jaeger, Kafka, and MirrorMaker 确保Jaeger,Kafka和MirrorMaker之间的版本兼容性
- Install Jaeger components (only collector & agent) using it’s OpenShift Operator使用OpenShift运算符安装Jaeger组件(仅收集器和代理)
- Leverage the self-provision option in the Jaeger OpenShift Operator to auto-install the Kafka cluster(ZooKeeper, Kafka and MirrorMaker) by using a Strimzi Kafka Kubernetes Operator 利用Jaeger OpenShift Operator中的自我配置选项通过使用Strimzi Kafka Kubernetes Operator自动安装Kafka集群(ZooKeeper,Kafka和MirrorMaker)
- Use MirrorMaker Kubernetes object provided by Strimizi Kafka Kubernetes Operator to replicate the OpenShift Kafka cluster events to the AWS MSK cluster 使用Strimizi Kafka Kubernetes Operator提供的MirrorMaker Kubernetes对象将OpenShift Kafka集群事件复制到AWS MSK集群
Note: It’s worth noting that the Jaeger collector or agent is not designed to handle the load when backed up by the spans, but a Kafka cluster can be used as a streaming service between the Jaeger collector and backend storage (DB) to offload the span data.
注意:值得注意的是, Jaeger收集器或代理程序并非设计为在通过跨度备份时处理负载,但是Kafka集群可以用作Jaeger收集器与后端存储(DB)之间的流服务以减轻跨度的负担数据。
Note: To leverage the self-provisioning Kafka cluster option in Jaeger, a Strimiz Operator must be deployed in the OpenShift cluster before the Jaeger Openshift Operator deployment.
注意:要利用Jaeger中的自配置Kafka集群选项,必须在部署Jaeger Openshift Operator之前在OpenShift集群中部署Strimiz Operator。
研发部 (R & D)
To prove the findings in the whiteboard session (Figure 2), I started with our in-house OpenShift cluster and an AWS MSK cluster to test the use case and understand the nuances in the process,
为了证明白板会话中的发现(图2 ) ,我从内部OpenShift集群和AWS MSK集群开始,以测试用例并了解流程中的细微差别,
试错 (Trial & Error)
When the Jaeger Openshift Operator is deployed with a self-provision Kafka cluster, it deployed the following:
当Jaeger Openshift Operator与自配置Kafka集群一起部署时,它会部署以下内容:
- Four components of Jaeger (agent, collector, ingester, and query) Jaeger的四个组成部分(代理,收集器,ingester和查询)
- A Kafka Cluster using Strimizi Operator 使用Strimizi运算符的Kafka集群
- Backend storage (ElasticSearch)后端存储(ElasticSearch)
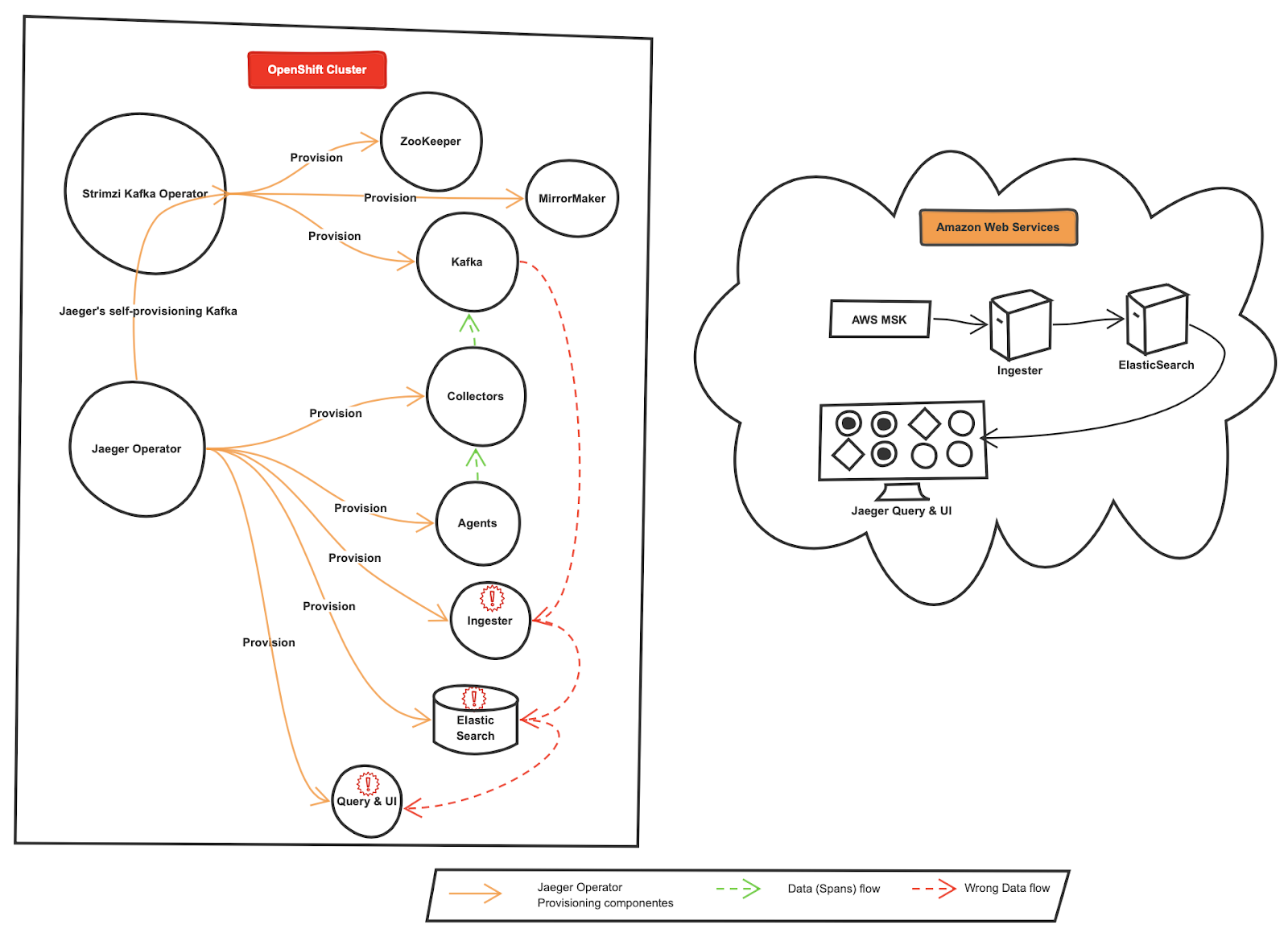
As per the design (Figure 2), I only needed the Jaeger agent, collector and a Kafka cluster, but I realized that there is no option in Jaeger Openshift Operator to enable or disable the backend storage such as Cassandra or ElasticSearch, ingester, or the query components (Figure 3).
按照设计(图2 ) ,我只需要Jaeger代理,收集器和Kafka集群,但是我意识到Jaeger Openshift Operator中没有选项来启用或禁用Cassandra或ElasticSearch,ingester或查询组件(图3 ) 。
改造 (Alteration)
To overcome the above challenge, instead of using the Jaeger OpenShift Operator, I created the required Jaeger components (collector and agent) as raw Kubernetes YAML files:
为了克服上述挑战,我没有使用Jaeger OpenShift运算符,而是将所需的Jaeger组件(收集器和代理)创建为原始Kubernetes YAML文件:
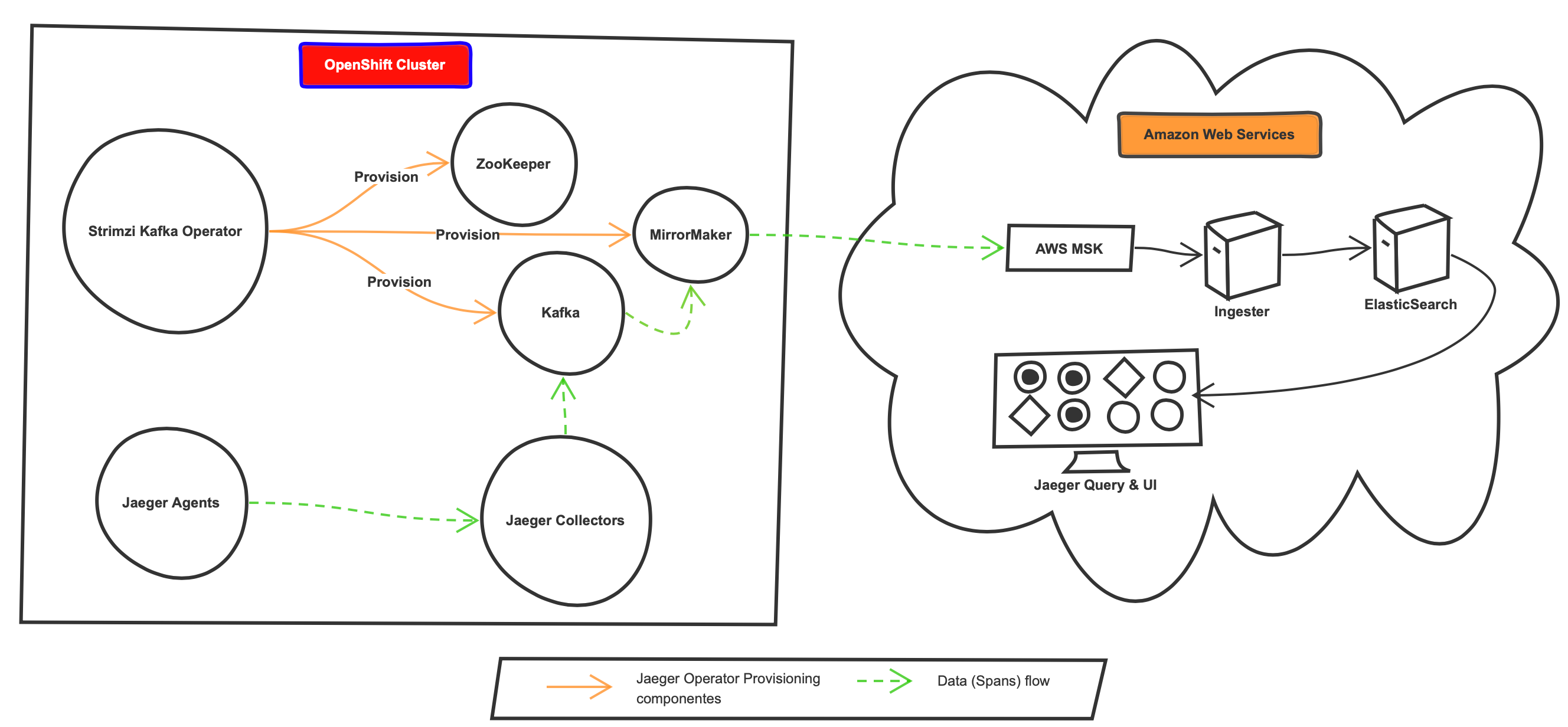
- Collector has the Kubernetes Deployment, ConfigMap, and a Service YAML files 收集器具有Kubernetes部署,ConfigMap和Service YAML文件
- The agent has the Kubernetes Daemonset as it needs to run on every node in the OpenShift cluster and a Service YAML files该代理具有Kubernetes守护程序集,因为它需要在OpenShift集群中的每个节点上运行,并具有Service YAML文件
For the Kafka cluster, I used the Strimizi Kafka Kubernetes Operator to deploy a simple Kafka cluster and a Kafka topic.
对于Kafka集群,我使用Strimizi Kafka Kubernetes Operator部署了一个简单的Kafka集群和一个Kafka主题。
Before deploying the Jaeger’s agent and collector to the OpenShift cluster using the raw Kubernetes YAML files, I set the backend storage type to Kafka with the Kafka Brokers and Kafka topic information in the Jaeger collector’s Kubernetes Deployment YAML file.
在使用原始Kubernetes YAML文件将Jaeger的代理和收集器部署到OpenShift集群之前,我将Jaeger收集器的Kubernetes部署YAML文件中的Kafka Brokers和Kafka主题信息设置为后端存储类型为Kafka。
你好世界跨越 (Hello World Spans)
Now that the architecture is altered (Figure 4), I wanted to make sure that Jaeger collector can forward the spans to the Kafka cluster. I created and deployed a sample Python application instrumented with the Jaeger client libraries to the OpenShift cluster.
现在已经更改了架构(图4 ) ,我想确保Jaeger收集器可以将范围转发到Kafka集群。 我创建了一个带有Jaeger客户端库的示例Python应用程序并将其部署到OpenShift集群中。
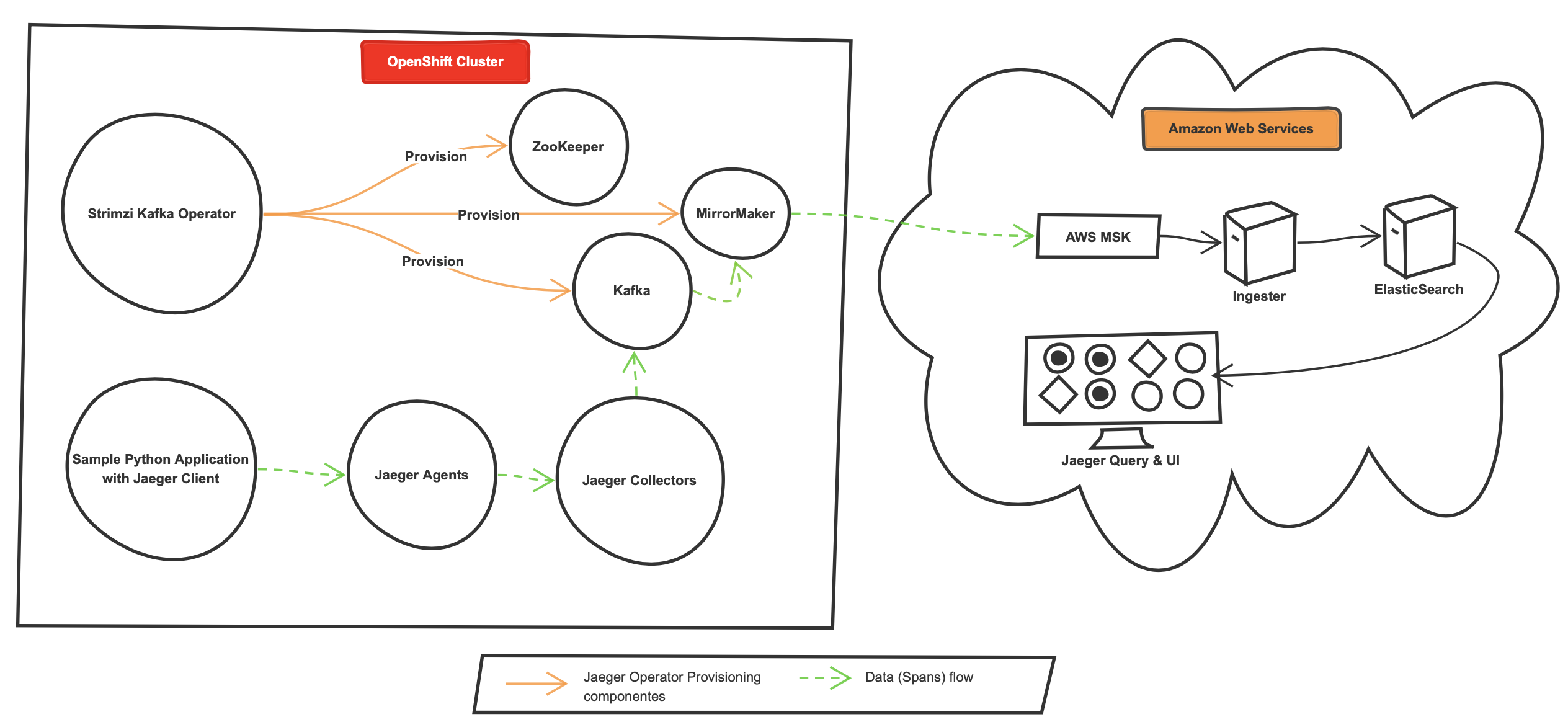
On the Jaeger side of the house, the agent was able to listen and batch the spans, the collector was receiving the spans from the agent. On the Kafka side of the house, the spans were actively streamed into the Kafka topic.
在房屋的Jaeger一侧,代理商能够收听并批量处理跨度,而收集者正在从代理商那里接收跨度。 在房子的卡夫卡一侧,跨度活跃地流到了卡夫卡主题中。
At this point, I confirmed that Jaeger successfully communicated and forward the spans to the Kafka.
在这一点上,我确认Jaeger已成功通信并将跨度转发给Kafka。
复写 (Replication)
Now to replicate the spans from the OpenShift Kafka topic to AWS MSK’s topic, I used the Strimizi Kafka Kubernetes Operator’s MirrorMaker. MirrorMaker is one of Kafka’s features used to replicate the events between multiple Kafka instances.
现在,要复制从OpenShift Kafka主题到AWS MSK主题的跨度,我使用了Strimizi Kafka Kubernetes Operator的MirrorMaker。 MirrorMaker是Kafka的功能之一,用于在多个Kafka实例之间复制事件。
I configured the MirrorMaker Kubernetes YAML file with the consumer (OpenShift Kafka) and producer (AWS MSK) clusters information and deployed it to the OpenShift cluster (Figure 5).
我使用使用者(OpenShift Kafka)和生产者(AWS MSK)集群信息配置MirrorMaker Kubernetes YAML文件,并将其部署到OpenShift集群(图5 ) 。
VOILA, It worked! I was able to read the sample Python application’s spans in the AWS’s MSK topics events.
VOILA,成功了! 我能够在AWS的MSK主题事件中阅读示例Python应用程序的范围。
终极素描 (The Ultimate Sketch)
Following the alterations through the trial and error phase, here is the final design
在尝试和错误阶段进行更改之后,这是最终设计
结束 (The End)
To rephrase my journey, I started with the Jaeger OpenShift and Strimzi Kafka Kubernetes Operators. Still, after the R&D and alterations to the initial sketch, I wind up with raw Kubernetes YAML files for Jaeger components and Strimzi Kafka Kubernetes Operators for Kafka cluster.
为了重述我的旅程,我从Jaeger OpenShift和Strimzi Kafka Kubernetes Operators开始。 尽管如此,在进行了研发和对初始草图的更改之后,我最终获得了Jaeger组件的原始Kubernetes YAML文件和Kafka集群的Strimzi Kafka Kubernetes Operators。
With the ultimate sketch, I wrap up the distributed tracing in a hybrid cloud using Apache Kafka blog without compromising the On-Prem Data retention and Network bandwidth limitation concerns.
利用最终的草图,我使用Apache Kafka博客将分布式跟踪包裹在混合云中,而不会影响内部数据保留和网络带宽限制问题。
I’m always up for a discussion; leave a comment below!!
我总是在讨论。 在下面发表评论!
Well, that’s it for now. See you again!
好吧,仅此而已。 再见!
Happy Tracing 🚀🚀
快乐追踪🚀🚀
翻译自: https://medium.com/@suryalolla/distributed-tracing-on-hybrid-cloud-using-apache-kafka-a29f46e895a1
apache kafka














 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}