





aws terraform
Infrastructure as code (e.g. Terraform) will become the fundamental backbone of a wide range of companies spanning across multiple sectors in the coming years.
未来几年,基础架构即代码(例如Terraform )将成为跨多个领域的众多公司的基本骨干。
The fundamental principle is that running the code deploys cloud infrastructure. This allows entire IT business solutions to be deployed at the click of a button. It also allows anyone to deploy a tool to analyse your favorite songs on Spotify.
基本原则是运行代码可部署云基础架构。 只需单击一个按钮,即可部署整个IT业务解决方案。 它还允许任何人部署工具来分析您在Spotify上喜欢的歌曲。
If you’re already familiar with Terraform and Python — the final solution can be found here and this is its architecture:
如果您已经熟悉Terraform和Python,则可以在这里找到最终的解决方案,它是其体系结构:
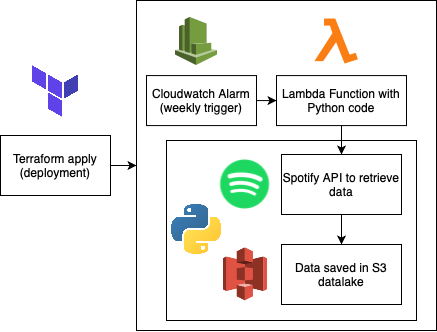
The rest of this article aims to explain how to use this repo to create your own AWS data lake for Spotify data at a high level, it is written to help you run a project like this yourself.
本文的其余部分旨在说明如何使用此存储库为高级别的Spotify数据创建您自己的AWS数据湖,旨在帮助您自己运行这样的项目。
If you’re more interested in seeing the analysis that I conducted with this data then check out my other article here:
如果您对查看我对这些数据进行的分析更感兴趣,请在此处查看我的其他文章:
Please send me any questions if anything doesn’t make sense.
如果有任何问题,请给我发送任何问题。
0. Pre-requisitesMake sure that you’ve got Python and Terraform installed correctly onto your machine. You can check if they’re correctly installed by running the following commands on a terminal:
0.先决条件确保已在计算机上正确安装了Python和Terraform 。 您可以通过在终端上运行以下命令来检查它们是否正确安装:
python -Vterraform -versionYou expect to see the respective version numbers of the software that you have installed.
您希望看到已安装软件的相应版本号。
You’ll also need an AWS account, if you haven’t got one already then you’re eligible for a one year ‘free-tier’ account. This account lets you access to some of AWS’s most popular features for free. You’ll still have to put in your credit / debit card information as it is possible to exceed your ‘free-tier limits’, make sure you keep an eye out for infinite loops and avoid them as much as you can, otherwise this could lead to a very costly mistake (I’ve seen people make $10,000 mistakes)!
您还需要一个AWS账户,如果您还没有一个AWS账户,那么您就有资格使用一年的“免费套餐”账户。 通过此帐户,您可以免费访问AWS最受欢迎的一些功能。 您仍然必须输入信用卡/借记卡信息,因为这有可能超过您的“免费套餐限制”,请确保留意无限循环并尽可能避免循环,否则可能会导致非常昂贵的错误(我见过人们犯了10,000美元的错误)!

1. Spotify & SpotipyGenerate a Spotify access token on the Spotify dashboard and make a note of the credentials. Install the Spotipy library onto your python environment using:
1. Spotify和Spotipy 在Spotify仪表板上生成Spotify访问令牌并记下凭据。 使用以下命令将Spotipy库安装到您的python环境中:
pip install spotipyThis lightweight library makes obtaining the data much simpler by simplifying the API endpoints and providing more options to browse the data.
这个轻量级的库通过简化API端点并提供更多浏览数据的选项,使获取数据变得更加简单。
Once installed, add your ID and Secret from Spotify into your environment variables with the names SPOTIPY_CLIENT_ID and SPOTIPY_CLIENT_SECRET respectively. Then create an authenticated object to begin exploring the data:
安装完成后,将Spotify的ID和Secret添加到名称分别为SPOTIPY_CLIENT_ID和SPOTIPY_CLIENT_SECRET的环境变量中。 然后创建一个经过身份验证的对象以开始探索数据:
spotipy_object = spotipy.Spotify(client_credentials_manager=spotipy.oauth2.SpotifyClientCredentials())2. Create an extract functionIdentify the question that you’re trying to answer with the data you’ll be gathering. My question was “are rap albums getting shorter?” and the data points I need to answer that question are:
2.创建提取功能使用收集的数据来确定您要回答的问题。 我的问题是“说唱专辑越来越短吗?” 我需要回答的数据点是:
- Album Length 专辑长度
- Year Released发行年份
- Album Name专辑名称
- Artist艺术家
I needed to gather data from a reputable rap playlist, so I chose to gather the data from Spotify’s Rap Caviar playlist (followed by 13m fans).
我需要从一个有名的说唱播放列表中收集数据,所以我选择从Spotify的Rap Caviar播放列表中收集数据(随后有1300万粉丝)。
This playlist has new songs added to it weekly that are hand-picked by the curators at Spotify. To build a Python dictionary of the length of all of the albums released by all artists in this playlist:
该播放列表每周都会添加新歌曲,这些新歌曲由Spotify的策展人亲自挑选。 要构建此播放列表中所有歌手发行的所有专辑的长度的Python字典,请执行以下操作:
# For all of their albums
for album in artists_albums['items']:
album_data = spotipy_object.album(album['uri'])
# For every song in the album
album_length_ms = 0
for song in album_data['tracks']['items']:
album_length_ms = song['duration_ms'] + album_length_ms
writer.writerow({'Year Released': album_data['release_date'],
'Album Length': album_length_ms,
'Album Name': album_data['name'],
'Artist': album_data['artists'][0]['name']})3. Terraform Deployment into AWSPlace the Terraform code for this project in a ‘.tf’ folder and run the ‘aws_architecture_plan.sh’ after changing the relevant path locations. This script creates a ‘payload’ that becomes the lambda function.
3. Terraform部署到AWS中将该项目的Terraform代码放置在“ .tf”文件夹中,并在更改相关路径位置后运行“ aws_architecture_plan.sh”。 该脚本创建了一个“有效负载”,成为lambda函数。
Make sure that terraform is ‘initialised’ by running:
通过运行以下命令确保terraform已“初始化”:
terraform initThis command creates the Terraform working directory which contains some configuration files. An important file to note here is the statefile. The statefile keeps a record of what your cloud infrastructure in JSON format, whenever you run Terraform code it will compare what you want to deploy to the most up to date statefile available.
此命令将创建Terraform工作目录,其中包含一些配置文件。 这里要注意的重要文件是statefile 。 状态文件以JSON格式记录您的云基础架构的内容,每当您运行Terraform代码时,它都会将您要部署的内容与最新的可用状态文件进行比较。
Then you can double check what you’re about to deploy by using:
然后,您可以使用以下方法再次检查您将要部署的内容:
terraform planWhich will output exactly what changes are about to be made to your infrastructure.
它将确切输出将对您的基础架构进行哪些更改。
Finally, when you’re happy with the output from the above command you can deploy the cloud infrastructure using:
最后,当您对上述命令的输出感到满意时,可以使用以下方法部署云基础架构:
terraform applyThis will build the Lambda function, the Cloudwatch alarm and all of the relevant IAM roles. All that’s left is to do is to set up an S3 bucket for your data to be saved in every week.
这将构建Lambda函数, Cloudwatch警报以及所有相关的IAM角色。 剩下要做的就是设置一个S3存储桶,以便每周保存一次数据。
4. Pulling the data for analysisNow your data is being saved to S3 you can setup a Glue Crawler and use Athena to query all of your data in your new data lake! If you want to get all of the data you can just run:
4.提取数据进行分析现在,您的数据已保存到S3,您可以设置一个Glue Crawler并使用Athena来查询新数据湖中的所有数据! 如果要获取所有数据,则可以运行:
select * from spotify_analysis.spotify_analysis_dataAnd save the .csv of the Athena results from your designated S3 bucket.
Now that you’ve got your data you’re ready to analyse it! There are a set of scripts here that I used to create my visualisations in my ‘Rap Albums are Getting Shorter’ article if you need some inspiration on where to get started.
现在,您已经拥有了数据,就可以进行分析了! 有一组脚本在这里,我用我的“创建我的可视化说唱专辑越来越短”的文章,如果您需要在何处着手一些启示。
SummaryUsing Terraform allows anyone to set up their own cloud infrastructure empire within minutes.
概要使用Terraform,任何人都可以在几分钟内建立自己的云基础设施帝国。
This article demonstrates how Terraform can be applied to automatically extract data from Spotify. Once you’ve got your data then you can use it to answer all sorts of questions about your favorite artists!
本文演示了如何将Terraform应用于自动从Spotify提取数据。 获得数据后,您就可以用它来回答有关您最喜欢的艺术家的各种问题!
aws terraform















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









