





文本预处理方法
大纲(Outline)
Estimates state that 70%–85% of the world’s data is text (unstructured data) [1]. New deep learning language models (transformers) have caused explosive growth in industry applications [5,6.11].
估计表明,全球数据的70%–85%是文本(非结构化数据) [1] 。 新的深度学习语言模型(变压器)已引起行业应用的爆炸式增长[5,6.11] 。
This blog is not an article introducing you to Natural Language Processing. Instead, it assumes you are familiar with noise reduction and normalization of text. It covers text preprocessing up to producing tokens and lemmas from the text.
这不是一篇向您介绍自然语言处理的文章。 相反,它假定您熟悉降噪和文本规范化。 它涵盖了文本预处理,直至从文本产生标记和引理。
We stop at feeding the sequence of tokens into a Natural Language model.
我们停止将标记序列输入自然语言模型。
The feeding of that sequence of tokens into a Natural Language model to accomplish a specific model task is not covered here.
这里不介绍将令牌序列馈送到自然语言模型中以完成特定模型任务的过程。
In production-grade Natural Language Processing (NLP), what is covered in this blog is that fast text pre-processing (noise cleaning and normalization) is critical.
在 生产级自然语言处理(NLP ),此博客涵盖的内容是快速的文本预处理(噪声清除和归一化) 至关重要。
I discuss packages we use for production-level NLP;
我讨论了用于生产级NLP的软件包。
I detail the production-level NLP preprocessing text tasks with python code and packages;
我详细介绍了具有python代码和软件包的生产级NLP预处理文本任务;
Finally. I report benchmarks for NLP text pre-processing tasks;
最后。 我报告了NLP文本预处理任务的基准。
将NLP处理分为两个步骤 (Dividing NLP processing into two Steps)
We segment NLP into two major steps (for the convenience of this article):
我们将NLP分为两个主要步骤(为方便起见):
Text pre-processing into tokens. We clean (noise removal) and then normalize the text. The goal is to transform the text into a corpus that any NLP model can use. A goal is rarely achieved until the introduction of the transformer [2].
将文本预处理为令牌。 我们清洗(去除噪音),然后将文本标准化。 目的是将文本转换为任何NLP模型都可以使用的语料库。 在引入变压器之前很少达到目标[2] 。
A corpus is an input (text preprocessed into a sequence of tokens) into NLP models for training or prediction.
语料库是对NLP模型的输入(经过预处理的标记序列),用于训练或预测。
The rest of this article is devoted to noise removal text and normalization of text into tokens/lemmas (Step 1: text pre-processing).
本文的其余部分专门讨论噪声消除文本以及将文本规范化为标记/引理(步骤1:文本预处理)。
Noise removal deletes or transforms things in the text that degrade the NLP task model.
噪声消除会删除或转换文本中使NLP任务模型降级的内容。
Noise removal is usually an NLP task-dependent. For example, e-mail may or may not be removed if it is a text classification task or a text redaction task.
噪声消除通常取决于NLP任务。 例如,如果电子邮件是文本分类任务或文本编辑任务,则可能会或可能不会将其删除。
I show replacement or removal of the noise.
我表示已替换或消除了噪音。
Normalization of the corpus is transforming the text into a common form. The most frequent example is normalization by transforming all characters to lowercase.
语料库的规范化将文本转换为通用形式。 最常见的示例是通过将所有字符转换为小写字母进行规范化。
In follow-on blogs, we will cover different deep learning language models and Transformers (Steps 2-n) fed by the corpus token/lemma stream.
在后续博客中,我们将介绍由语料库标记/引理流提供的不同深度学习语言模型和Transformers(步骤2-n)。
NLP文本预处理包特征 (NLP Text Pre-Processing Package Factoids)
There are many NLP packages available. We use spaCy [2], textacy [4], Hugging Face transformers [5], and regex [7] in most of our NLP production applications. The following are some of the “factoids” we used in our decision process.
有许多可用的NLP软件包。 我们在大多数NLP生产应用程序中都使用spaCy [2],textacy [4],Hugging Face变形器[5]和regex [7] 。 以下是我们在决策过程中使用的一些“事实”。
Note: The following “factoids” may be biased. That is why we refer to them as “factoids.”
注意:以下“类事实”可能会有偏差。 这就是为什么我们称它们为“类固醇”。
NLTK [3]
NLTK [3]
NLTK is a string processing library. All the tools take strings as input and return strings or lists of strings as output [3].
NLTK是字符串处理库。 所有工具都将字符串作为输入,并将字符串或字符串列表作为输出[3] 。
NLTK is a good choice if you want to explore different NLP with a corpus whose length is less than a million words.
如果您要使用长度小于一百万个单词的语料库探索其他NLP ,则NLTK是一个不错的选择。
NLTK is a bad choice if you want to go into production with your NLP application [3].
如果您想将NLP应用程序投入生产,则NLTK是一个不好的选择[3]。
正则表达式 (Regex)
The use of regex is pervasive throughout our text-preprocessing code. Regex is a fast string processor. Regex, in various forms, has been around for over 50 years. Regex support is part of the standard library of Java and Python, and is built into the syntax of others, including Perl and ECMAScript (JavaScript);
在我们的文本预处理代码中,正则表达式的使用无处不在。 正则表达式是一种快速的字符串处理器。 各种形式的正则表达式已经存在了50多年。 Regex支持是Java和Python标准库的一部分,并内置于其他语法中,包括Perl和ECMAScript (JavaScript);
空间[2] (spaCy [2])
spaCy is a moderate choice if you want to research different NLP models with a corpus whose length is greater than a million words.
spaCy是一个温和的选择,如果你想用一个语料库,其长度比一万字更大,以研究不同NLP模型。
If you use a selection from spaCy [3], Hugging Face [5], fast.ai [13], and GPT-3 [6], then you are performing SOTA (state-of-the-art) research of different NLP models (my opinion at the time of writing this blog).
如果您使用spaCy [3] , Hugging Face [5] , fast.ai [13]和GPT-3 [6]中的选项,则您正在执行不同NLP的SOTA (最新技术)研究模型(我在撰写此博客时的看法)。
spaCy is a good choice if you want to go into production with your NLP application.
如果要使用NLP应用程序投入生产, spaCy是一个不错的选择。
spaCy is an NLP library implemented both in Python and Cython. Because of the Cython, parts of spaCy are faster than if implemented in Python [3];
spaCy是同时在Python和Cython中实现的NLP库。 由于使用了Cython, spaCy的某些部分比实施起来要快 在Python [3]中;
spacy is the fastest package, we know of, for NLP operations;
我们知道, spacy是最快的NLP操作包。
spacy is available for operating systems MS Windows, macOS, and Ubuntu [3];
spacy可用于MS Windows,macOS和Ubuntu [3]操作系统;
spaCy runs natively on Nvidia GPUs [3];
spaCy在Nvidia GPU上本地运行[3] ;
explosion/spaCy has 16,900 stars on Github (7/22/2020);
爆炸/ spaCy有Github上16900星(2020年7月22日);
spaCy has 138 public repository implementations on GitHub;
spaCy在GitHub上有138个公共存储库实现;
spaCy comes with pre-trained statistical models and word vectors;
spaCy带有预训练的统计模型和单词向量;
spaCy transforms text into document objects, vocabulary objects, word- token objects, and other useful objects resulting from parsing the text ;
spaCy将文本转换为文档对象,词汇对象,单词标记对象和其他因解析文本而产生的有用对象;
Doc class has several useful attributes and methods. Significantly, you can create new operations on these objects as well as extend a class with new attributes (adding to the spaCy pipeline);
Doc类具有几个有用的属性和方法。 重要的是,您可以在这些对象上创建新操作,以及使用新属性(添加到spaCy管道)扩展类。
spaCy features tokenization for 50+ languages;
spaCy具有针对50多种语言的标记化功能;

创建long_s练习文本字符串 (Creating long_s Practice Text String)
We create long_, a long string that has extra whitespace, emoji, email addresses, $ symbols, HTML tags, punctuation, and other text that may or may not be noise for the downstream NLP task and/or model.
我们创建long_ ,这是一个长字符串,其中包含额外的空格,表情符号,电子邮件地址,$符号,HTML标签,标点符号以及其他可能对下游NLP任务和/或模型long_文本。
MULPIPIER = int(3.8e3)
text_l = 300%time long_s = ':( 😻 😈 #google +1 608-444-0000 08-444-0004 608-444-00003 ext. 508 '
long_s += ' 888 eihtg DoD Fee https://medium.com/ #hash ## Document Title</title> '
long_s += ':( cat- \n nip'
long_s += ' immed- \n natedly <html><h2>2nd levelheading</h2></html> . , '
long_s += '# bhc@gmail.com f@z.yx can\'t Be a ckunk. $4 $123,456 won\'t seven '
long_s +=' $Shine $$beighty?$ '
long_s *= MULPIPIER
print('size: {:g} {}'.format(len(long_s),long_s[:text_l]))output =>
输出=>
CPU times: user 3 µs, sys: 1 µs, total: 4 µs
Wall time: 8.11 µs
size: 1.159e+06
:( 😻 😈 #google +1 608-444-0000 08-444-0004 608-444-00003 ext. 508 888 eihtg DoD Fee https://medium.com/ #hash ## Document Title</title> :( cat-
nip immed-
natedly <html><h2>2nd levelheading</h2></html> . , # bhc@gmail.com f@z.yx can't Be a ckunk. $4 $123,456 won't seven $Shine $$beighA string, long_s of 1.159 million characters is created in 8.11 µs.
在8.11 µs内创建了一个字符串, long_s为long_s万个字符。
Python String Corpus预处理步骤和基准 (Python String Corpus Pre-processing Step and Benchmarks)
All benchmarks are run within a Docker container on MacOS Version 14.0 (14.0).
所有基准测试均在MacOS 14.0(14.0)版的Docker容器中运行。
Model Name: Mac Pro
Processor Name: 12-Core Intel Xeon E5
Processor Speed: 2.7 GHz
Total Number of Cores: 24
L2 Cache (per Core): 256 KB
L3 Cache: 30 MB
Hyper-Threading Technology: EnabledMemory: 64 GBNote: Corpus/text pre-processing is dependent on the end-point NLP analysis task. Sentiment Analysis requires different corpus/text pre-processing steps than document redaction. The corpus/text pre-processing steps given here are for a range of NLP analysis tasks. Usually. a subset of the given corpus/text pre-processing steps is needed for each NLP task. Also, some of required corpus/text pre-processing steps may not be given here.
注意:语料库/文本预处理取决于端点NLP分析任务。 情感分析与文档编辑相比,需要不同的语料库/文本预处理步骤。 此处给出的语料库/文本预处理步骤适用于一系列NLP分析任务。 通常。 每个NLP任务都需要给定语料库/文本预处理步骤的子集。 同样,此处可能未提供某些所需的语料库/文本预处理步骤。
1. NLP文本预处理:替换Twitter哈希标签 (1. NLP text preprocessing: Replace Twitter Hash Tags)
from textacy.preprocessing.replace import replace_hashtags
%time text = replace_hashtags(long_s,replace_with= '_HASH_')
print('size: {:g} {}'.format(len(text),text[:text_l])))output =>
输出=>
CPU times: user 223 ms, sys: 66 µs, total: 223 ms
Wall time: 223 ms
size: 1.159e+06 :
( 😻 😈 _HASH_ +1 608-444-0000 08-444-0004 608-444-00003 ext. 508 888 eihtg DoD Fee https://medium.com/ _HASH_ ## Document Title</title> :( cat-
nip immed-
natedly <html><h2>2nd levelheading</h2></html> . , # bhc@gmail.com f@z.yx can't Be a ckunk. $4 $123,456 won't seven $Shine $$beighNotice that #google and #hash are swapped with_HASH_,and ##and _# are untouched. A million characters were processed in 200 ms. Fast enough for a big corpus of a billion characters (example: web server log).
注意#google和#hash被交换与_HASH_,以及##和_#是不变。 200毫秒内处理了100万个字符。 足够快,足以容纳十亿个字符的大型语料库(例如:Web服务器日志)。
2. NLP文本预处理:删除Twitter哈希标签 (2. NLP text preprocessing: Remove Twitter Hash Tags)
from textacy.preprocessing.replace import replace_hashtags
%time text = replace_hashtags(long_s,replace_with= '')
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 219 ms, sys: 0 ns, total: 219 ms
Wall time: 220 ms
size: 1.1134e+06 :( 😻 😈 +1 608-444-0000 08-444-0004 608-444-00003 ext. 508 888 eihtg DoD Fee https://medium.com/ ## Document Title</title> :( cat-
nip immed-
natedly <html><h2>2nd levelheading</h2></html> . , # bhc@gmail.com f@z.yx can't Be a ckunk. $4 $123,456 won't seven $Shine $$beighty?$ Notice that #google and #hash are removed and ##,and _# are untouched. A million characters were processed in 200 ms.
注意#google和#hash被删除, ##,和_#是不变。 200毫秒内处理了100万个字符。
3. NLP文本预处理:替换电话号码 (3. NLP text preprocessing: Replace Phone Numbers)
from textacy.preprocessing.replace import replace_phone_numbers
%time text = replace_phone_numbers(long_s,replace_with= '_PHONE_')
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 384 ms, sys: 1.59 ms, total: 386 ms
Wall time: 383 ms
size: 1.0792e+06
:( 😻 😈 _PHONE_ 08-_PHONE_ 608-444-00003 ext. 508 888 eihtg Notice phone number 08-444-0004 and 608-444-00003 ext. 508 were not transformed.
注意电话号码08-444-0004和608-444-00003 ext. 508 608-444-00003 ext. 508未进行转换。
4. NLP文本预处理:替换电话号码-更好 (4. NLP text preprocessing: Replace Phone Numbers - better)
RE_PHONE_NUMBER: Pattern = re.compile(
# core components of a phone number
r"(?:^|(?<=[^\w)]))(\+?1[ .-]?)?(\(?\d{2,3}\)?[ .-]?)?(\d{2,3}[ .-]?\d{2,5})"
# extensions, etc.
r"(\s?(?:ext\.?|[#x-])\s?\d{2,6})?(?:$|(?=\W))",
flags=re.UNICODE | re.IGNORECASE)text = RE_PHONE_NUMBER.sub('_PHoNE_', long_s)
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 353 ms, sys: 0 ns, total: 353 ms
Wall time: 350 ms
size: 1.0108e+06
:( 😻 😈 _PHoNE_ _PHoNE_ _PHoNE_ 888 eihtg DoD Fee https://medium.com/ ## Document Title</title> :( cat-
nip immed-
natedly <html><h2>2nd levelheading</h2></html> . , # bhc@gmail.com f@z.yx can't Be a ckunk. $4 $123,456 won't seven $Shine $$beighty?$Notice phone number 08-444-0004 and 608-444-00003 ext. 508 were transformed. A million characters were processed in 350 ms.
注意电话号码08-444-0004和608-444-00003 ext. 508 608-444-00003 ext. 508被改造。 在350毫秒内处理了100万个字符。
5. NLP文本预处理:删除电话号码 (5. NLP text preprocessing: Remove Phone Numbers)
Using the improved RE_PHONE_NUMBER pattern, we put '' in for 'PHoNE' to remove phone numbers from the corpus.
使用改进的RE_PHONE_NUMBER模式,我们在“ PHoNE'放入''以从语料库中删除电话号码。
text = RE_PHONE_NUMBER.sub('', long_s)
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 353 ms, sys: 459 µs, total: 353 ms
Wall time: 351 ms
size: 931000
:( 😻 😈 888 eihtg DoD Fee https://medium.com/ ## Document Title</title> :( cat-
nip immed-
natedly <html><h2>2nd levelheading</h2></html> . , # bhc@gmail.com f@z.yx can't Be a ckunk. $4 $123,456 won't seven $Shine $$beighty?$A million characters were processed in 375 ms.
在375毫秒内处理了100万个字符。
6. NLP文本预处理:删除HTML元数据 (6. NLP text preprocessing: Removing HTML metadata)
I admit removing HTML metadata is my favorite. Not because I like the task, but because I screen-scrape frequently. There is a lot of useful data that resides on an IBM mainframe, VAX-780 (huh?), or whatever terminal-emulation that results in an HTML-based report.
我承认删除HTML元数据是我的最爱。 不是因为我喜欢这项任务,而是因为我经常屏幕刮擦。 有许多有用的数据驻留在IBM大型机上, VAX-78 0(是吗?),或导致基于HTML的报告的任何终端仿真。
These techniques of web scraping of reports generate text that has HTML tags. HTML tags are considered noise typically as they are parts of the text with little or no value in the follow-on NLP task.
这些通过Web抓取报告的技术会生成带有HTML标签的文本。 HTML标签通常被认为是噪音,因为它们是文本的一部分,在后续的NLP任务中几乎没有价值。
Remember, we created a test string (long_s) a little over million characters long with some HTML tags. We remove the HTML tags using BeautifulSoup.
记住,我们创建了一个测试字符串( long_s ),它带有一些HTML标记,长度超过一百万个字符。 我们使用BeautifulSoup删除HTML标签。
from bs4 import BeautifulSoup
%time long_s = BeautifulSoup(long_s,'html.parser').get_text()
print('size: {:g} {}'.format(len(long_s),long_s[:text_l])))output =>
输出=>
CPU times: user 954 ms, sys: 17.7 ms, total: 971 ms
Wall time: 971 ms
size: 817000
:( 😻 😈 888 eihtg DoD Fee https://medium.com/ ## Document Title :( cat-
nip immed-
natedly 2nd levelheading The result is that BeautifulSoup is able to remove over 7,000 HTML tags in a million character corpus in one second. Scaling linearly, a billion character corpus, about 200 million word, or approximately 2000 books, would require about 200 seconds.
结果是BeautifulSoup能够在一秒钟内删除百万个字符集中的7,000多个HTML标签。 线性缩放,一个十亿个字符的语料库,大约2亿个单词,或大约2000本书,将需要大约200秒。
The rate for HTML tag removal byBeautifulSoup is about 0. 1 second per book. An acceptable rate for our production requirements.
BeautifulSoup清除HTML标签的速度约为每本书0. 1秒。 符合我们生产要求的价格。
I only benchmark BeautifulSoup. If you know of a competitive alternative method, please let me know.
我仅对BeautifulSoup基准测试。 如果您知道其他竞争方法,请告诉我。
Not: The compute times you get may be multiples of time longer or shorter if you are using the cloud or Spark.
否:如果您使用的是Cloud或Spark,那么您获得的计算时间可能是更长或更短的时间。
7. NLP文本预处理:替换货币符号 (7. NLP text preprocessing: Replace currency symbol)
The currency symbols “[$¢£¤¥ƒ֏؋৲৳૱௹฿៛ℳ元円圆圓﷼\u20A0-\u20C0] “ are replaced with _CUR_using the textacy package:
的货币符号“[$¢£¤¥ƒ֏؋৲৳૱௹฿៛ℳ元円圆圆﷼ \ u20A0- \ u20C0]“被替换_CUR_使用textacy包:
%time textr = textacy.preprocessing.replace.replace_currency_symbols(long_s)
print('size: {:g} {}'.format(len(textr),textr[:text_l]))output =>
输出=>
CPU times: user 31.2 ms, sys: 1.67 ms, total: 32.9 ms
Wall time: 33.7 ms
size: 908200
:( 😻 😈 888 eihtg DoD Fee https://medium.com/ ## Document Title :( cat-
nip immed-
natedly 2nd levelheading . , # bhc@gmail.com f@z.yx can't Be a ckunk. _CUR_4 _CUR_123,456 won't seven _CUR_Shine _CUR__CUR_beighty?_CUR_Note: The option textacy
replace_<something>enables you to specify the replacement text._CUR_is the default substitution text forreplace_currency_symbols.注意:选项textacy
replace_<something>使您可以指定替换文本。_CUR_是replace_currency_symbols.的默认替换文本replace_currency_symbols.
You may have the currency symbol $ in your text. In this case you can use a regex:
您的文本中可能包含货币符号$ 。 在这种情况下,您可以使用regex:
%time text = re.sub('\$', '_DOL_', long_s)
print('size: {:g} {}'.format(len(text),text[:250]))output =>
输出=>
CPU times: user 8.06 ms, sys: 0 ns, total: 8.06 ms
Wall time: 8.25 ms
size: 1.3262e+06
:( 😻 😈 #google +1 608-444-0000 08-444-0004 608-444-00003 ext. 508 888 eihtg DoD Fee https://medium.com/ #hash ## <html><title>Document Title</title></html> :( cat-
nip immed-
natedly <html><h2>2nd levelheading</h2></html> . , # bhc@gmail.com f@z.yx can't Be a ckunk. _DOL_4 _DOL_123,456 won't seven _DOL_Shine _DOL__DOL_beighty?_DOL_ :Note: All symbol $ in your text will be removed. Don't use if you have LaTex or any text where multiple symbol $ are used.
注意:文本中的所有符号$将被删除。 如果您有LaTex或使用多个符号$任何文本,则不要使用。
8. NLP文本预处理:替换URL字符串 (8. NLP text preprocessing: Replace URL String)
from textacy.preprocessing.replace import replace_urls
%time text = replace_urls(long_s,replace_with= '_URL_')
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 649 ms, sys: 112 µs, total: 649 ms
Wall time: 646 ms
size: 763800
:( 😻 😈 888 eihtg DoD Fee _URL_ ## Document Title :( 9. NLP文本预处理:删除URL字符串(9. NLP text preprocessing: Remove URL String)
from textacy.preprocessing.replace import replace_urls
%time text = replace_urls(long_s,replace_with= '')
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 633 ms, sys: 1.35 ms, total: 635 ms
Wall time: 630 ms
size: 744800
:( 😻 😈 888 eihtg DoD Fee ## Document Title :( The rate for URL replace or removal is about 4,000 URLs per 1 million characters per second. Fast enough for 10 books in a corpus.
URL替换或删除的速度约为每秒每100万个字符4,000个URL。 足够快的语料库中的10本书。
10. NLP文本预处理:替换电子邮件字符串 (10. NLP text preprocessing: Replace E-mail string)
%time text = textacy.preprocessing.replace.replace_emails(long_s)
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 406 ms, sys: 125 µs, total: 406 ms
Wall time: 402 ms
size: 725800
:( 😻 😈 888 eihtg DoD Fee ## Document Title :( cat-
nip immed-
natedly 2nd levelheading . , # _EMAIL_ _EMAIL_ can't Be a ckunk. $4 $123,456 won't seven $Shine $$beighty?$ The rate for email reference replace is about 8,000 emails per 1.7 million characters per second. Fast enough for 17 books in a corpus.
电子邮件参考替换的速率约为每秒每170万个字符8,000封电子邮件。 足够快,足以在语料库中阅读17本书。
11. NLP文本预处理:删除电子邮件字符串 (11. NLP text pre-processing: Remove E-mail string)
from textacy.preprocessing.replace import replace_emails
%time text = textacy.preprocessing.replace.replace_emails(long_s,replace_with= '')
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 413 ms, sys: 1.68 ms, total: 415 ms
Wall time: 412 ms
size: 672600 :( 😻 😈 888 eihtg DoD Fee ## Document Title :( cat-
nip immed-
natedly 2nd levelheading . , # can't Be a ckunk. $4 $123,456 won't seven $Shine $$beighty?$ The rate for email reference removal is about 8,000 emails per 1.1 million characters per second. Fast enough for 11 books in a corpus.
电子邮件参考删除的速率约为每秒每110万个字符8,000封电子邮件。 足够快的语料库中的11本书。
12. NLP文本预处理:normalize_hyphenated_words (12. NLP text preprocessing: normalize_hyphenated_words)
from textacy.preprocessing.normalize import normalize_hyphenated_words
%time long_s = normalize_hyphenated_words(long_s)
print('size: {:g} {}'.format(len(long_s),long_s[:text_l])))output =>
输出=>
CPU times: user 186 ms, sys: 4.58 ms, total: 191 ms
Wall time: 190 ms
size: 642200 :
( 😻 😈 888 eihtg DoD Fee ## Document Title :( catnip immednatedlyApproximately 8,000 hyphenated-words, cat — nip and immed- iately (mispelled) were corrected in a corpus of 640,000 characters in 190 ms or abouut 3 million per second.
在190毫秒或每秒3百万左右的速度下,以640,000个字符的语料库纠正了大约8,000个immed- iately , cat — nip和immed- iately (拼写错误)。
13. NLP文本预处理:将所有字符转换为小写 (13. NLP text preprocessing: Convert all characters to lower case)
### - **all characters to lower case;**
%time long_s = long_s.lower()
print('size: {:g} {}'.format(len(long_s),long_s[:text_l]))output =>
输出=>
CPU times: user 4.82 ms, sys: 953 µs, total: 5.77 ms
Wall time: 5.97 ms
size: 642200
:( 😻 😈 888 eihtg dod fee ## document title :( catnip immednatedly 2nd levelheading . , # can't be a ckunk. $4 $123,456 won't seven $shine $$beighty?$I only benchmark the .lower Python function. The rate for lower case transformation by.lower() of a Python string of a million characters is about 6 ms. A rate that far exceeds our production rate requirements.
我仅对.lower Python函数进行基准测试。 .lower()对一百万个字符的Python字符串进行小写转换的速率约为6毫秒。 生产率远远超过我们的生产率要求。
14. NLP文本预处理:空格删除 (14. NLP text preprocessing: Whitespace Removal)
%time text = re.sub(' +', ' ', long_s)
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 44.9 ms, sys: 2.89 ms, total: 47.8 ms
Wall time: 47.8 ms
size: 570000
:( 😻 😈 888 eihtg dod fee ## document title :( catnip immednatedly 2nd levelheading . , # can't be a ckunk. $4 $123,456 won't seven $shine $$beighty?$The rate is about 0.1 seconds for 1 million characters.
一百万个字符的速度约为0.1秒。
15. NLP文本预处理:空格删除(速度较慢) (15. NLP text preprocessing: Whitespace Removal (slower))
from textacy.preprocessing.normalize import normalize_whitespace
%time text= normalize_whitespace(long_s)
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 199 ms, sys: 3.06 ms, total: 203 ms
Wall time: 201 ms
size: 569999
:( 😻 😈 888 eihtg dod fee ## document title :( catnip immednatedly 2nd levelheading . , # can't be a ckunk. $4 $123,456 won't seven $shine $$beighty?$normalize_whitespce is 5x slower but more general. For safety in production, we use normalize_whitespce.To date, we do not think we had any problems with faster regex.
normalize_whitespce慢5倍,但更通用。 为了安全生产,我们使用normalize_whitespce. 迄今为止,我们认为更快的regex.没有任何问题regex.
16. NLP文本预处理:删除标点符号 (16. NLP text preprocessing: Remove Punctuation)
from textacy.preprocessing.remove import remove_punctuation
%time text = remove_punctuation(long_s, marks=',.#$?')
print('size: {:g} {}'.format(len(text),text[:text_l]))output =>
输出=>
CPU times: user 34.5 ms, sys: 4.82 ms, total: 39.3 ms
Wall time: 39.3 ms
size: 558599
:( 😻 😈 888 eihtg dod fee document title :( catnip immednatedly 2nd levelheading can't be a ckunk 4 123 456 won't seven shine beighty空间 (spaCy)
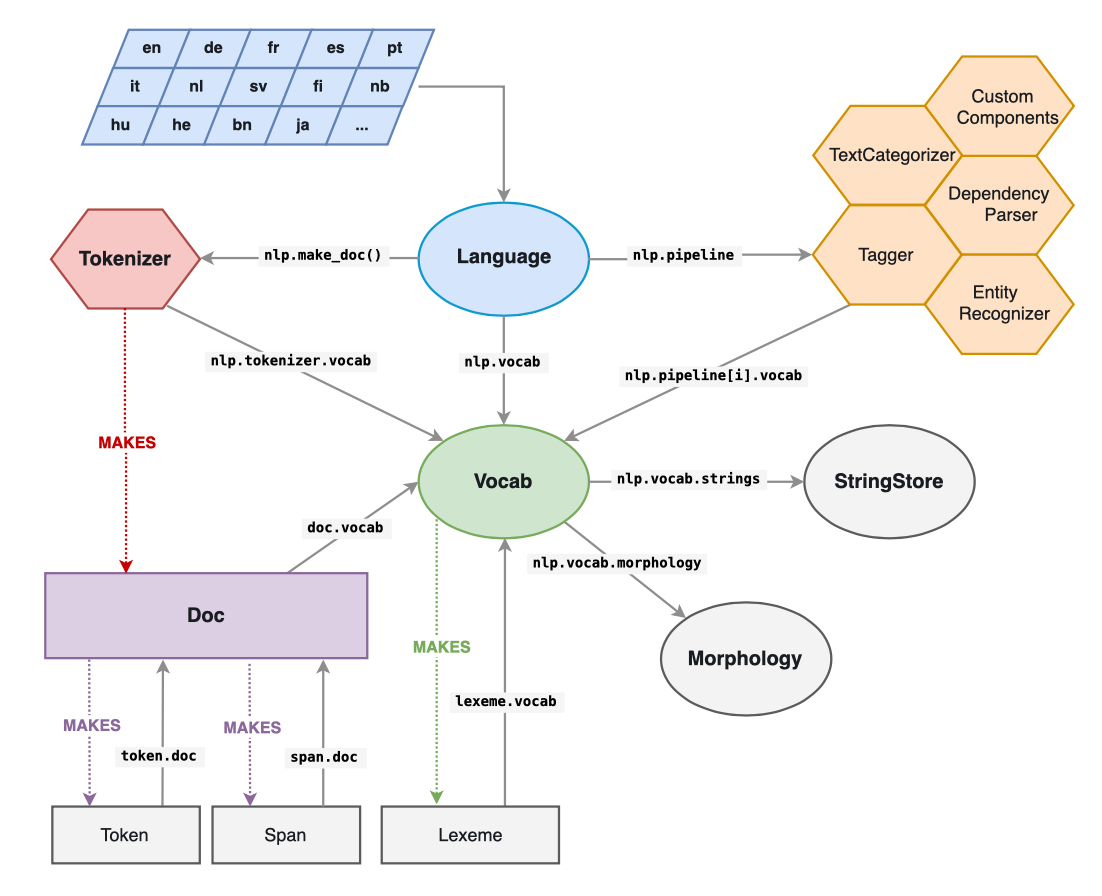
创建spaCy管道和文档 (Creating the spaCy pipeline and Doc)
In order to text pre-process with spaCy, we transform the text into a corpus Doc object. We can then use the sequence of word tokens objects of which a Doc object consists. Each token consists of attributes (discussed above) that we use later in this article to pre-process the corpus.
为了使用spaCy对文本进行预处理,我们将文本转换为语料库Doc对象。 然后,我们可以使用由Doc对象组成的单词标记对象的序列。 每个标记都包含属性(上面已讨论过),我们将在本文后面使用这些属性来预处理语料库。
Our text pre-processing end goal (usually) is to produce tokens that feed into our NLP models.
我们的文本预处理最终目标(通常)是产生可馈入我们的NLP模型的令牌。
spaCy reverses the stream of pre-processing text and then transforming text into tokens. spaCy creates a Doc of tokens. You then pre-process the tokens by their attributes.
spaCy反转预处理文本流,然后将文本转换为令牌。 spaCy创建令牌文档。 然后,您可以根据标记的属性对其进行预处理。
The result is that parsing text into a Doc object is where the majority of computation lies. As we will see, pre-processing the sequence of tokens by their attributes is fast.
结果是,将文本解析为Doc对象是大多数计算的基础。 正如我们将看到的,通过标记的属性对标记序列进行预处理非常快。
在spaCy管道中添加表情符号清理 (Adding emoji cleaning in the spaCy pipeline)
import en_core_web_lg
nlp = en_core_web_lg.load()do = nlp.disable_pipes(["tagger", "parser"])
%time emoji = Emoji(nlp)
nlp.max_length = len(long_s) + 10
%time nlp.add_pipe(emoji, first=True)
%time long_s_doc = nlp(long_s)
print('size: {:g} {}'.format(len(long_s_doc),long_s_doc[:text_l]))output =>
输出=>
CPU times: user 303 ms, sys: 22.6 ms, total: 326 ms
Wall time: 326 ms
CPU times: user 23 µs, sys: 0 ns, total: 23 µs
Wall time: 26.7 µs
CPU times: user 7.22 s, sys: 1.89 s, total: 9.11 s
Wall time: 9.12 s
size: 129199
:( 😻 😈 888 eihtg dod fee document title :( catnip immednatedly 2nd levelheading can't be a ckunk 4 123 456 won't seven shine beightyCreating the token sequence required at 14,000 tokens per second. We will quite a speedup when we use NVIDIA gpu.
创建每秒需要14,000个令牌的令牌序列。 当我们使用NVIDIA gpu时,我们会大大提高速度。
nlp.pipe_namesoutput =>['emoji', 'ner']Note: The tokenizer is a “special” component and isn’t part of the regular pipeline. It also doesn’t show up in
nlp.pipe_names. The reason is that there can only be one tokenizer, and while all other pipeline components take aDocand return it, the tokenizer takes a string of text and turns it into aDoc. You can still customize the tokenizer. You can either create your ownTokenizerclass from scratch, or even replace it with an entirely custom function.注意:分词器是一个“特殊”组件,不是常规管道的一部分。 它也不会显示在
nlp.pipe_names。 原因是只能有一个令牌生成器,而所有其他管道组件都需要一个Doc并将其返回,而令牌生成器需要一个文本字符串并将其转换为Doc。 您仍然可以自定义令牌生成器。 您可以从头开始创建自己的Tokenizer类,甚至可以将其替换为完全自定义的函数。
文档令牌预处理的spacy令牌属性 (spacy Token Attributes for Doc Token Preprocessing)
As we saw earlier, spaCy provides convenience methods for many other pre-processing tasks. It turns — for example, to remove stop words you can reference the .is_stop attribute.
如前所述, spaCy为许多其他预处理任务提供了便利的方法。 .is_stop您了-例如,要删除停用词,您可以引用.is_stop属性。
dir(token[0])output=>'ancestors',
'check_flag',
'children',
'cluster',
'conjuncts',
'dep',
'dep_',
'doc',
'ent_id',
'ent_id_',
'ent_iob',
'ent_iob_',
'ent_kb_id',
'ent_kb_id_',
'ent_type',
'ent_type_',
'get_extension',
'has_extension',
'has_vector',
'head',
'i',
'idx',
'is_alpha',
'is_ancestor',
'is_ascii',
'is_bracket',
'is_currency',
'is_digit',
'is_left_punct',
'is_lower',
'is_oov',
'is_punct',
'is_quote',
'is_right_punct',
'is_sent_end',
'is_sent_start',
'is_space',
'is_stop',
'is_title',
'is_upper',
'lang',
'lang_',
'left_edge',
'lefts',
'lemma',
'lemma_',
'lex_id',
'like_email',
'like_num',
'like_url',
'lower',
'lower_',
'morph',
'n_lefts',
'n_rights',
'nbor',
'norm',
'norm_',
'orth',
'orth_',
'pos',
'pos_',
'prefix',
'prefix_',
'prob',
'rank',
'remove_extension',
'right_edge',
'rights',
'sent',
'sent_start',
'sentiment',
'set_extension',
'shape',
'shape_',
'similarity',
'string',
'subtree',
'suffix',
'suffix_',
'tag',
'tag_',
'tensor',
'text',
'text_with_ws',
'vector',
'vector_norm',
'vocab',
'whitespace_']Attributes added by emoji and new.
emoji和new.属性new.
dir(long_s_doc[0]._)output =>['emoji_desc',
'get',
'has',
'is_emoji',
'set',
'trf_alignment',
'trf_all_attentions',
'trf_all_hidden_states',
'trf_d_all_attentions',
'trf_d_all_hidden_states',
'trf_d_last_hidden_state',
'trf_d_pooler_output',
'trf_end',
'trf_last_hidden_state',
'trf_pooler_output',
'trf_separator',
'trf_start',
'trf_word_pieces',
'trf_word_pieces_'I show spaCy performing preprocessing that results in a Python string corpus. The corpus is used to create a new sequence of spaCy tokens (Doc).
我展示了spaCy执行预处理会生成Python字符串语料库。 语料库用于创建新的spaCy令牌序列( Doc )。
There is a faster way to accomplish spaCy preprocessing with spaCy pipeline extensions [2], which I show in an upcoming blog.
使用spaCy管道扩展[2]可以更快地完成spaCy预处理,我将在即将发表的博客中介绍该方法。
17. EMOJI情绪评分 (17. EMOJI Sentiment Score)
EMOJI Sentiment Score is not a text preprocessor in the classic sense.
EMOJI情感评分不是经典意义上的文本预处理器。
However, we find that emoji almost always is the dominating text in a document.
但是,我们发现表情符号几乎总是文档中的主要文字。
For example, two similar phrases from legal notes e-mail with opposite sentiment.
例如,法律注释电子邮件中的两个相似短语具有相反的情感。
The client was challenging. :(The client was difficult. :)We calcuate only emoji when present in a note or e-mail.
当出现在便笺或电子邮件中时,我们仅计算表情符号。
%time scl = [EMOJI_TO_SENTIMENT_VALUE[token.text] for token in long_s_doc if (token.text in EMOJI_TO_SENTIMENT_VALUE)]
len(scl), sum(scl), sum(scl)/len(scl)output =>
输出=>
CPU times: user 179 ms, sys: 0 ns, total: 179 ms
Wall time: 178 ms
(15200, 1090.7019922523152, 0.07175671001659968)The sentiment was 0.07 (neutral) for 0.5 million character "note" with 15,200 emojis and emojicons in 178 ms. A fast sentiment analysis calculation!
50万个字符“音符”在178毫秒内具有15200个表情符号和表情符号,情绪为0.07(中性)。 快速的情绪分析计算!
18. NLP文本预处理:删除表情符号 (18. NLP text preprocessing: Removing emoji)
You can remove emoji using spaCy pipeline add-on
您可以使用spaCy管道附件删除表情符号
%time long_s_doc_no_emojicon = [token for token in long_s_doc if token._.is_emoji == False]
print('size: {:g} {}'.format(len(long_s_doc_no_emojicon),long_s_doc_no_emojicon[:int(text_l/5)]))output =>
输出=>
CPU times: user 837 ms, sys: 4.98 ms, total: 842 ms
Wall time: 841 ms
size: 121599
[:(, 888, eihtg, dod, fee, , document, title, :(, catnip, immednatedly, 2nd, levelheading, , ca, n't, be, a, ckunk, , 4, , 123, 456, wo, n't, seven, , shine, , beighty, , :(, 888, eihtg, dod, fee, , document, title, :(, catnip, immednatedly, 2nd, levelheading, , ca, n't, be, a, ckunk, , 4, , 123, 456, wo, n't, seven, , shine, , beighty, , :(, 888, eihtg, dod, fee, ]The emoji spacy pipeline addition detected the emojicons, 😻 😈, but missed :) and :(.
表情符号spacy管道添加检测到表情符号😻😈,但未包括:) and :(.
19. NLP文本预处理:删除表情符号(更好) (19. NLP text pre-processing: Removing emoji (better))
We developed EMOJI_TO_PHRASEto detect the emojicons, 😻 😈, and emoji, such as :) and :(. and removed them [8,9].
我们开发了EMOJI_TO_PHRASE来检测表情符号,😻和表情符号,例如:) and :(.并删除它们[8,9] 。
%time text = [token.text if (token.text in EMOJI_TO_PHRASE) == False \
else '' for token in long_s_doc]
%time long_s = ' '.join(text)
print('size: {:g} {}'.format(len(long_s),long_s[:text_l]))output =>
输出=>
CPU times: user 242 ms, sys: 3.76 ms, total: 245 ms
Wall time: 245 ms
CPU times: user 3.37 ms, sys: 73 µs, total: 3.45 ms
Wall time: 3.46 ms
size: 569997
888 eihtg dod fee document title catnip immednatedly 2nd levelheading ca n't be a ckunk 4 123 456 wo n't seven shine beighty 888 eihtg dod fee document title catnip immednatedly 2nd levelheading ca n't be a ckunk 4 123 456 wo n't seven shine beighty 888 eihtg dod fee document title catnip imm20. NLP文本预处理:用短语替换表情符号 (20. NLP text pre-processing: Replace emojis with a phrase)
We can translate emojicon into a natural language phrase.
我们可以将表情符号翻译成自然语言短语。
%time text = [token.text if token._.is_emoji == False else token._.emoji_desc for token in long_s_doc]
%time long_s = ' '.join(text)
print('size: {:g} {}'.format(len(long_s),long_s[:250]))output =>
输出=>
CPU times: user 1.07 s, sys: 7.54 ms, total: 1.07 s
Wall time: 1.07 s
CPU times: user 3.78 ms, sys: 0 ns, total: 3.78 ms
Wall time: 3.79 ms
size: 794197
:( smiling cat face with heart-eyes smiling face with horns 888 eihtg dod fee document title :( catnip immednatedly 2nd levelheading ca n't be a ckunk 4 123 456 wo n't seven shine beighty The emoji spaCy pipeline addition detected the emojicons, 😻 😈, but missed :) and :(.
表情符号空间管道添加功能检测到了表情符号😻 ,但未包括:) and :(.
21. NLP文本预处理:用一个短语替换表情符号(更好) (21. NLP text pre-processing: Replace emojis with a phrase (better))
We can translate emojicons into a natural language phrase.
我们可以将表情符号翻译成自然语言短语。
%time text = [token.text if (token.text in EMOJI_TO_PHRASE) == False \
else EMOJI_TO_PHRASE[token.text] for token in long_s_doc]
%time long_s = ' '.join(text)
print('size: {:g} {}'.format(len(long_s),long_s[:text_l]))output =>
输出=>
CPU times: user 251 ms, sys: 5.57 ms, total: 256 ms
Wall time: 255 ms
CPU times: user 3.54 ms, sys: 91 µs, total: 3.63 ms
Wall time: 3.64 ms
size: 904397
FROWNING FACE SMILING CAT FACE WITH HEART-SHAPED EYES SMILING FACE WITH HORNS 888 eihtg dod fee document title FROWNING FACE catnip immednatedly 2nd levelheading ca n't be a ckunk 4 123 456 wo n't seven shine beighty FROWNING FACAgain. EMOJI_TO_PHRASE detected the emojicons, 😻 😈, and emoji, such as :) and :(. and substituted a phrase.
再次。 EMOJI_TO_PHRASE检测到表情符号,cons和表情符号,例如:) and :(.并替换了一个短语。
22. NLP文本预处理:正确的拼写 (22. NLP text preprocessing: Correct Spelling)
We will use symspell for spelling correction [14].
我们将使用symspell进行拼写更正[14] 。
SymSpell, based on the Symmetric Delete spelling correction algorithm, just took 0.000033 seconds (edit distance 2) and 0.000180 seconds (edit distance 3) on an old MacBook Pro [14].
基于对称删除拼写校正算法的SymSpell就采用了 在旧版MacBook Pro [14]上为0.000033秒(编辑距离2)和0.000180秒(编辑距离3) 。
%time sym_spell_setup()
%time tk = [check_spelling(token.text) for token in long_s_doc[0:99999]]
%time long_s = ' '.join(tk)
print('size: {:g} {}'.format(len(long_s),long_s[:250]))output =>
输出=>
CPU times: user 5.22 s, sys: 132 ms, total: 5.35 s
Wall time: 5.36 s
CPU times: user 25 s, sys: 12.9 ms, total: 25 s
Wall time: 25.1 s
CPU times: user 3.37 ms, sys: 42 µs, total: 3.41 ms
Wall time: 3.42 ms
size: 528259 FROWNING FACE SMILING CAT FACE WITH HEART a SHAPED EYES SMILING FACE WITH HORNS 888 eight do fee document title FROWNING FACE catnip immediately and levelheading a not be a chunk a of 123 456 to not seven of shine of eightySpell correction was accomplished for immednatedly, ckunk and beight. Correcting mis-spelled words is our largest computation. It required 30 seconds for 0.8 million characters.
immednatedly, ckunk就完成了拼写纠正immednatedly, ckunk和beight. 纠正拼写错误的单词是我们最大的计算。 80万个字符需要30秒。
23. NLP文本预处理:替换货币符号( spaCy ) (23. NLP text preprocessing: Replacing Currency Symbol (spaCy))
%time token = [token.text if token.is_currency == False else '_CUR_' for token in long_s_doc]
%time long_s = ' '.join(token)
print('size: {:g} {}'.format(len(long_s),long_s[:text_l]))aaNote: spacy removes all punctuation including
:)emoji and emoticon. You can protect the emoticon with:注意: spacy删除所有标点符号,包括
:)表情符号和表情符号。 您可以使用以下方法保护表情符号:
%time long_s_doc = [token for token in long_s_doc if token.is_punct == False or token._.is_emoji == True]
print('size: {:g} {}'.format(len(long_s_doc),long_s_doc[:50]))However, replace_currency_symbolsand regex ignore context and replace any currency symbol. You may have multiple use of $ in your text and thus can not ignore context. In this case you can use spaCy.
但是, replace_currency_symbols和regex会忽略上下文并替换任何货币符号。 您可能在文本中多次使用$ ,因此不能忽略上下文。 在这种情况下,您可以使用spaCy 。
%time tk = [token.text if token.is_currency == False else '_CUR_' for token in long_s_doc]
%time long_s = ' '.join(tk)
print('size: {:g} {}'.format(len(long_s),long_s[:250]))output =>
输出=>
CPU times: user 366 ms, sys: 13.9 ms, total: 380 ms
Wall time: 381 ms
CPU times: user 9.7 ms, sys: 0 ns, total: 9.7 ms
Wall time: 9.57 ms
size: 1.692e+06 😻 👍 🏿 < title > Document Title</title > :( < html><h2>2nd levelheading</h2></html > bhc@gmail.com f@z.y a$@ ca n't bc$$ ef$4 5 66 _CUR_ wo nt seven eihtg _CUR_ nine _CUR_ _CUR_ zer$ 😻 👍 🏿 < title > Document Title</title > :( < html><h2>2nd leve24. NLP文本预处理:删除电子邮件地址(spacy) (24. NLP text preprocessing: Removing e-mail address (spacy))
%time tokens = [token for token in long_s_doc if not token.like_email]
print('size: {:g} {}'.format(len(tokens),tokens[:int(text_l/3)]))output =>
输出=>
CPU times: user 52.7 ms, sys: 3.09 ms, total: 55.8 ms
Wall time: 54.8 ms
size: 99999About 0.06 second for 1 million characters.
100万个字符约0.06秒。
25. NLP文本预处理:删除空格和标点符号( spaCy ) (25. NLP text preprocessing: Remove whitespace and punctuation (spaCy))
%time tokens = [token.text for token in long_s_doc if (token.pos_ not in ['SPACE','PUNCT'])]
%time text = ' '.join(tokens)
print('size: {:g} {}'.format(len(text),text[:text_l]))26. NLP文本预处理:删除停用词 (26. NLP text preprocessing: Removing stop-words)
NLP models (ex: logistic regression and transformers) and NLP tasks (Sentiment Analysis) continue to be added. Some benefit from stopword removal, and some will not. [2]
继续添加NLP模型(例如:逻辑回归和变换器)和NLP任务(情感分析) 。 有些受益于停用词删除功能,有些则不会。 [2]
Note: We now only use different deep learning language models (transformers) and do not remove stopwords.
注意:我们现在仅使用不同的深度学习语言模型(变压器),并且不删除停用词。
%time tokens = [token.text for token in long_s_doc if token.is_stop == False]
%time long_s = ' '.join(tokens)
print('size: {:g} {}'.format(len(long_s),long_s[:text_l]))27. NLP文本预处理:合法化 (27. NLP text pre-processing: Lemmatization)
Lemmatization looks beyond word reduction and considers a language’s full vocabulary to apply a morphological analysis to words.
词法化超越了词的减少,并考虑了语言的全部词汇来对词进行形态分析。
Lemmatization looks at the surrounding text to determine a given word’s part of speech. It does not categorize phrases.
词法化处理会查看周围的文本,以确定给定单词的词性。 它不对短语进行分类。
%time tokens = [token.lemma_ for token in long_s_doc]
%time long_s = ' '.join(tokens)
print('size: {:g} {}'.format(len(long_s),long_s[:text_l]))output =>
输出=>
CPU times: user 366 ms, sys: 13.9 ms, total: 380 ms
Wall time: 381 ms
CPU times: user 9.7 ms, sys: 0 ns, total: 9.7 ms
Wall time: 9.57 ms
size: 1.692e+06 😻 👍 🏿 < title > Document Title</title > :( < html><h2>2nd levelheading</h2></html > bhc@gmail.com f@z.y a$@ ca n't bc$$ ef$4 5 66 _CUR_ wo nt seven eihtg _CUR_ nine _CUR_ _CUR_ zer$ 😻 👍 🏿 < title > Document Title</title > :( < html><h2>2nd leveNote: Spacy does not have stemming. You can add if it is you want. Stemming does not work as well as Lemmazatation because Stemming does not consider context [2] (Why some researcher considers spacy “opinionated”).
注意:Spacy没有词根。 您可以根据需要添加。 词干不如Lemmazatation发挥作用,因为词干没有考虑上下文[2](为什么有些研究人员认为spacy是“有条件的” )。
Note: If you do not know what is Stemming, you can still be on the Survivor show. (my opinion)
注意:如果您不知道什么是“阻止”,则仍然可以在Survivor节目中。 (我的意见)
结论 (Conclusion)
Whatever the NLP task, you need to clean (pre-process) the data (text) into a corpus (document or set of documents) before it is input into any NLP model.
无论执行什么NLP任务,您都需要先将数据(文本)清理(预处理)为一个语料库(文档或文档集),然后再将其输入到任何NLP模型中。
I adopt a text pre-processing framework that has three major categories of NLP text pre-processing:
我采用了文本预处理框架,该框架具有NLP文本预处理的三个主要类别:
Noise Removal
噪音消除
- Transform Unicode characters into text characters.将Unicode字符转换为文本字符。
convert a document image into segmented image parts and text snippets [10];
将文档图像转换为分段的图像部分和文本片段[10] ;
- extract data from a database and transform into words; 从数据库中提取数据并转换为单词;
- remove markup and metadata in HTML, XML, JSON, .md, etc.; 删除HTML,XML,JSON,.md等中的标记和元数据;
- remove extra whitespaces; 删除多余的空格;
- remove emoji or convert emoji into phases; 删除表情符号或将表情符号转换为阶段;
- Remove or convert currency symbol, URLs, email addresses, phone numbers, hashtags, other identifying tokens; 删除或转换货币符号,URL,电子邮件地址,电话号码,主题标签,其他识别标记;
The correct mis-spelling of words (tokens); [7]
正确拼写单词(标记); [7]
- Remove remaining unwanted punctuation; 删除剩余的不需要的标点符号;
- … …
2. Tokenization
2.标记化
- They are splitting strings of text into smaller pieces, or “tokens.” Paragraphs segment into sentences, and sentences tokenize into words. 他们将文本字符串分成较小的部分或“标记”。 段落分段为句子,句子标记为单词。
3. Normalization
3.归一化
- Change all characters to lower case;将所有字符更改为小写;
- Remove English stop words, or whatever language the text is in; 删除英语停用词或文本使用的任何语言;
- Perform Lemmatization or Stemming. 执行拔除或阻止。
Note: The tasks listed in Noise Removal and Normalization can move back and forth. The categorical assignment is for explanatory convenience.
注意:“噪声消除和归一化”中列出的任务可以来回移动。 类别分配是为了便于说明。
Note: We do not remove stop-words anymore. We found that our current NLP models have higher F1 scores when we leave in stop-words.
注意:我们不再删除停用词。 我们发现,当我们留下停用词时,我们当前的NLP模型具有更高的F1分数。
Note: Stop-word removal is expensive computationally. We found the best way to achieve faster stop-word removal was not to do it.
注意:去除停用词在计算上是昂贵的。 我们发现最好的方法是更快地删除停用词。
Note: We saw no significant change in Deep Learning NLP models’ speed with or without stop-word removal.
注意:无论是否移除停用词,我们都没有发现深度学习NLP模型的速度发生重大变化。
Note: The Noise Removal and Normalization lists are not exhaustive. These are some of the tasks I have encountered.
注意:“噪波消除”和“归一化”列表并不详尽。 这些是我遇到的一些任务。
Note: The latest NLP Deep Learning models are more accurate than older models. However, Deep Learning models can be impractically slow to train and are still too slow for prediction. We show in a follow-on article how we speed-up such models for production.
注意:最新的NLP深度学习模型比旧模型更准确。 但是,深度学习模型的训练可能不切实际,并且仍然太慢而无法预测。 我们在后续文章中展示了如何加快此类模型的生产速度。
Note: Stemming algorithms drop off the end of the beginning of the word, a list of common prefixes and suffixes to create a base root word.
注意:词干提取算法会在单词开头,一系列常见前缀和后缀的末尾添加单词,以创建基本词根。
Note: Lemmatization uses linguistic knowledge bases to get the correct roots of words. Lemmatization performs morphological analysis of each word, which requires the overhead of creating a linguistic knowledge base for each language.
注意:词法化使用语言知识库来获取单词的正确词根。 词法化对每个单词进行形态分析,这需要为每种语言创建语言知识库的开销。
Note: Stemming is faster than lemmatization.
注意:词干比词条去除更快。
Note: Intuitively and in practice, lemmatization yields better results than stemming in an NLP Deep Learning model. Stemming generally reduces precision accuracy and increases recall accuracy because it injects semi-random noise when wrong.
注意:从直觉上和实践中,与在NLP深度学习模型中进行茎粗化相比,进行词根粗化可获得更好的结果。 阻止通常会降低精度,并提高查全率,因为错误时会注入半随机噪声。
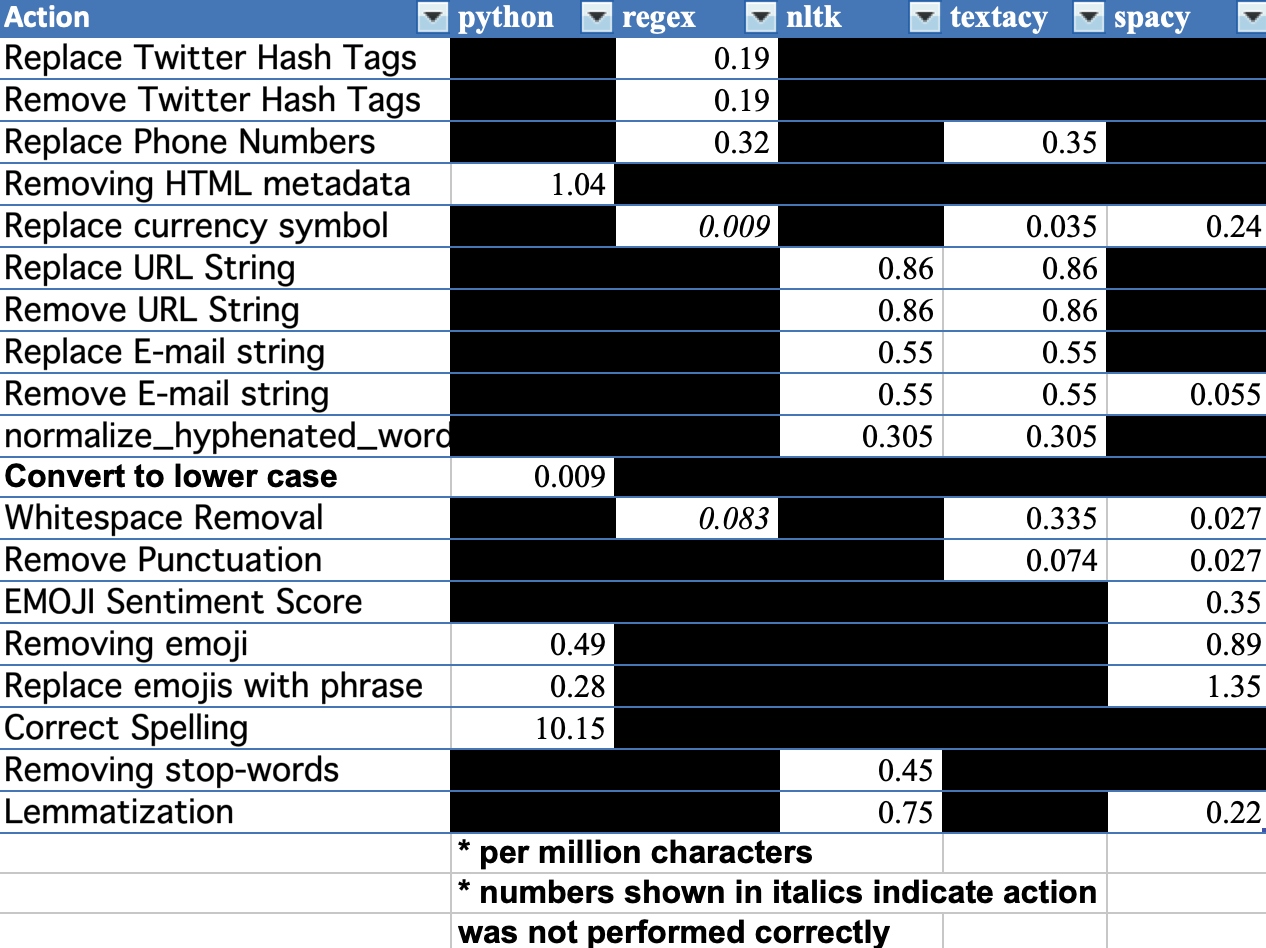
Our unique implementations, spaCy, and textacy are our current choice for short text preprocessing production fast to use. If you don’t mind the big gap in performance, I would recommend using it for production purposes, over NLTK’s implementation of Stanford’s NER.
我们独特的实现,spaCy和textacy是我们当前选择的,可快速使用的短文本预处理产品。 如果您不介意性能上的巨大差异,我建议将其用于生产目的,而不是NLTK实施斯坦福大学NER的目的。
In the next blogs, We see how performance changes using multi-processing, multithreading, Nvidia GPUs, and pySpark. Also, I will write about how and why our implementations, such as EMOJI_TO_PHRASEand EMOJI_TO_SENTIMENT_VALUEand or how to add emoji, emoticon, or any Unicode symbol.
在接下来的博客中,我们将看到如何使用多处理,多线程, Nvidia GPU和pySpark来改变性能。 另外,我将写关于我们的实现方式和方式(例如EMOJI_TO_PHRASE和EMOJI_TO_SENTIMENT_VALUE以及如何添加表情符号,表情符号或任何Unicode符号的文章。
文本预处理方法














 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}