





In this article, I want to present some findings in the field of social media mining, describing the implementation of a Word2Vec model applied to index an entire user base, providing a tool to find similarities and discover similar instances within a community.
在本文中,我想介绍社交媒体挖掘领域的一些发现,描述Word2Vec模型的实现,该模型可用于对整个用户群建立索引,提供查找相似之处和发现社区中相似实例的工具。
介绍: (Introduction:)
Although many different social media platforms already offer ways to discover similar user, this set of features are mainly built for the final user, meaning that the goal is to actually display them what they want to see and not users that are actually similar to them under a business point of view.
尽管许多不同的社交媒体平台已经提供了发现相似用户的方法,但是这组功能主要是为最终用户构建的,这意味着目标是实际显示他们想要看到的内容,而不是实际显示与他们相似的用户。商业角度。
Algorithms able to target similar users are used behind tools such as Facebook Ads, which gives the advertiser the possibility to target users that are similar to a specific set of conditions such as brands, tastes, or other demographics data.
能够针对相似用户的算法被用于诸如Facebook Ads之类的工具之后,这使广告商可以针对与特定条件集(例如品牌,品味或其他受众特征数据)相似的用户进行定位。
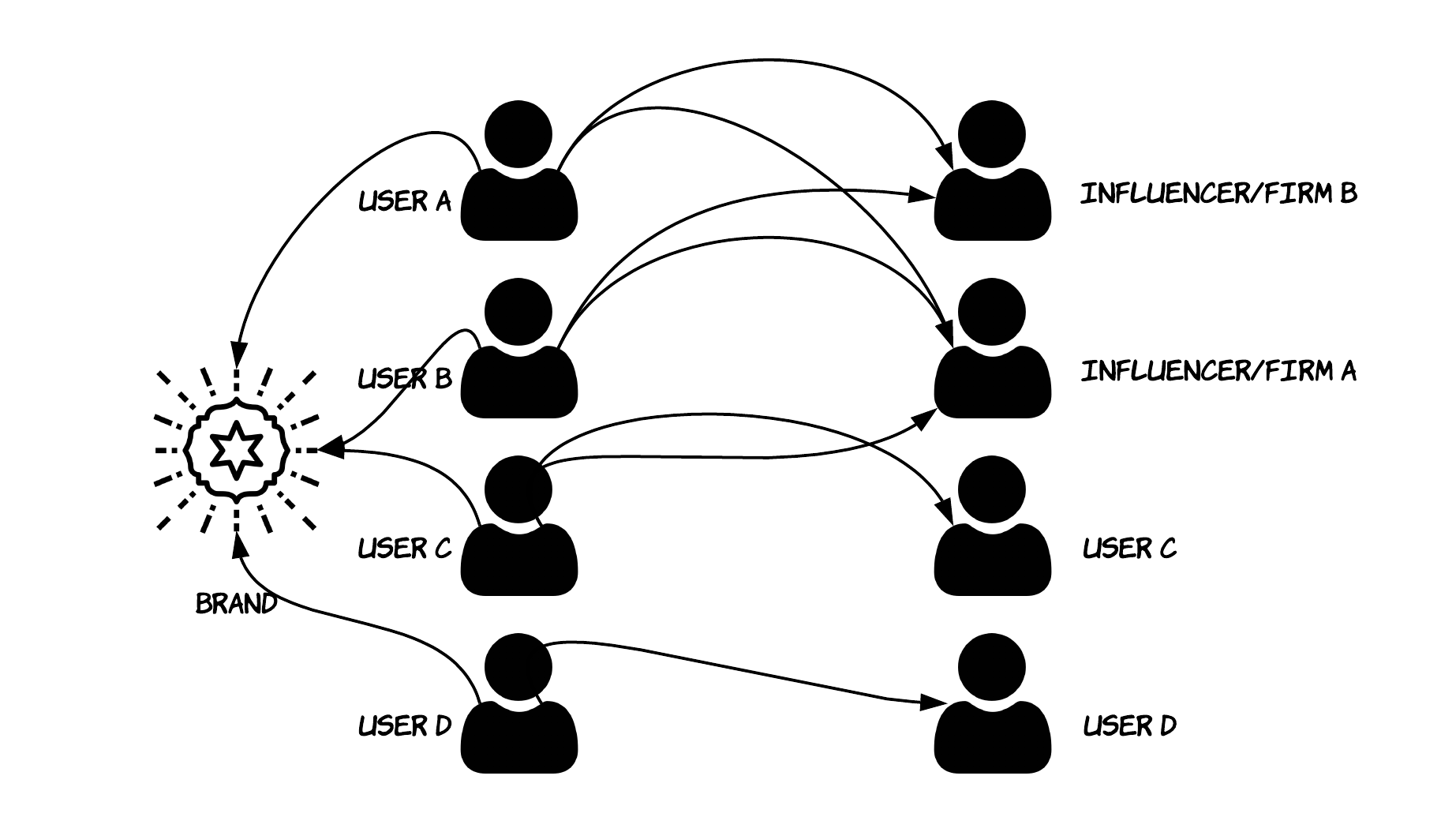
Let’s start with an example: we have a set of n users following a specific brand/profile. Each of those users can follow as well as n users. Often, inside a set of users that follow a specific brand, there are relationships among those users. Some users follow each other because they simply know each other, some other users follow a specific user since the latter is an “influencer”, some other users, among the same user base might follow a very well known brand.
让我们从一个例子开始:我们有一组n用户遵循特定的品牌/配置文件。 这些用户中的每一个都可以跟随n用户。 通常,在遵循特定品牌的一组用户中,这些用户之间存在关系。 一些用户互相关注是因为他们彼此了解,而其他一些用户则是因为特定用户是“影响者”而已,因此在同一用户群中的其他一些用户可能会使用一个非常知名的品牌。
Having a “mapped” representation of a user base can help a business to answer different questions, among them:
对用户群进行“映射”表示可以帮助企业回答不同的问题,其中包括:
How can I find an influencer similar to
xyz?如何找到类似于
xyz的影响者?How much similar is user
xyzto userzyx?用户
xyz与用户zyx有多少相似之处?- Can I group my user base in specific groups without any additional data about the users? 是否可以在没有任何其他有关用户的数据的情况下将用户群分为特定的组?
- Which are the most influential people among my community? 我社区中最有影响力的人是谁?
策略: (The strategy:)
The main goal in this study is to create a numerical representation of each user inside a brand’s community, the data available consists of a list of usernames together with a list of profile each user follows:
这项研究的主要目标是为品牌社区中的每个用户创建一个数字表示,可用数据包括用户名列表以及每个用户的配置文件列表:
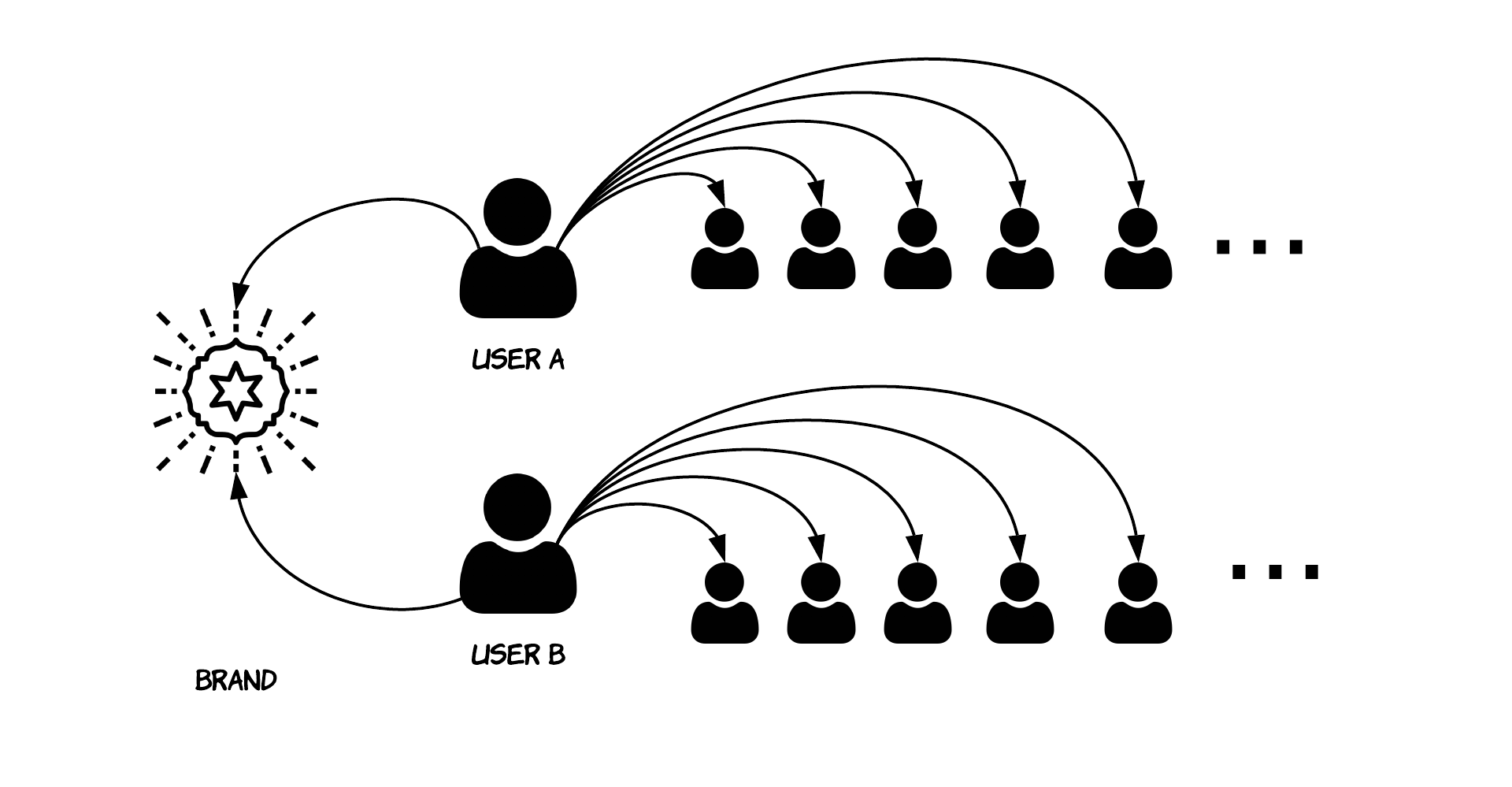
If it is possible to numerically represent users inside a space, it is also possible to compute operations between users, such as calculate similarity, discover clusters and trends among a community.
如果可以用数字表示一个空间内的用户,则还可以计算用户之间的操作,例如计算相似度,发现集群和社区中的趋势。
While in the phase of thinking how to tackle this challenge, the main idea that came in my mind was to treat each user as a different itemset, similarly to when to shop in a store: we have our shopping basket (social media profile) and we fill this basked with things we want; different shopper do the same with their shopping basked, hence analyzing those data can help understand pattern among customers.
在思考如何应对这一挑战的阶段,我想到的主要思想是将每个用户视为不同的项目集,类似于何时在商店购物:我们拥有购物篮(社交媒体资料),我们用我们想要的东西填充了它; 不同的购物者在购物时也会做同样的事情,因此分析这些数据可以帮助了解客户的模式。
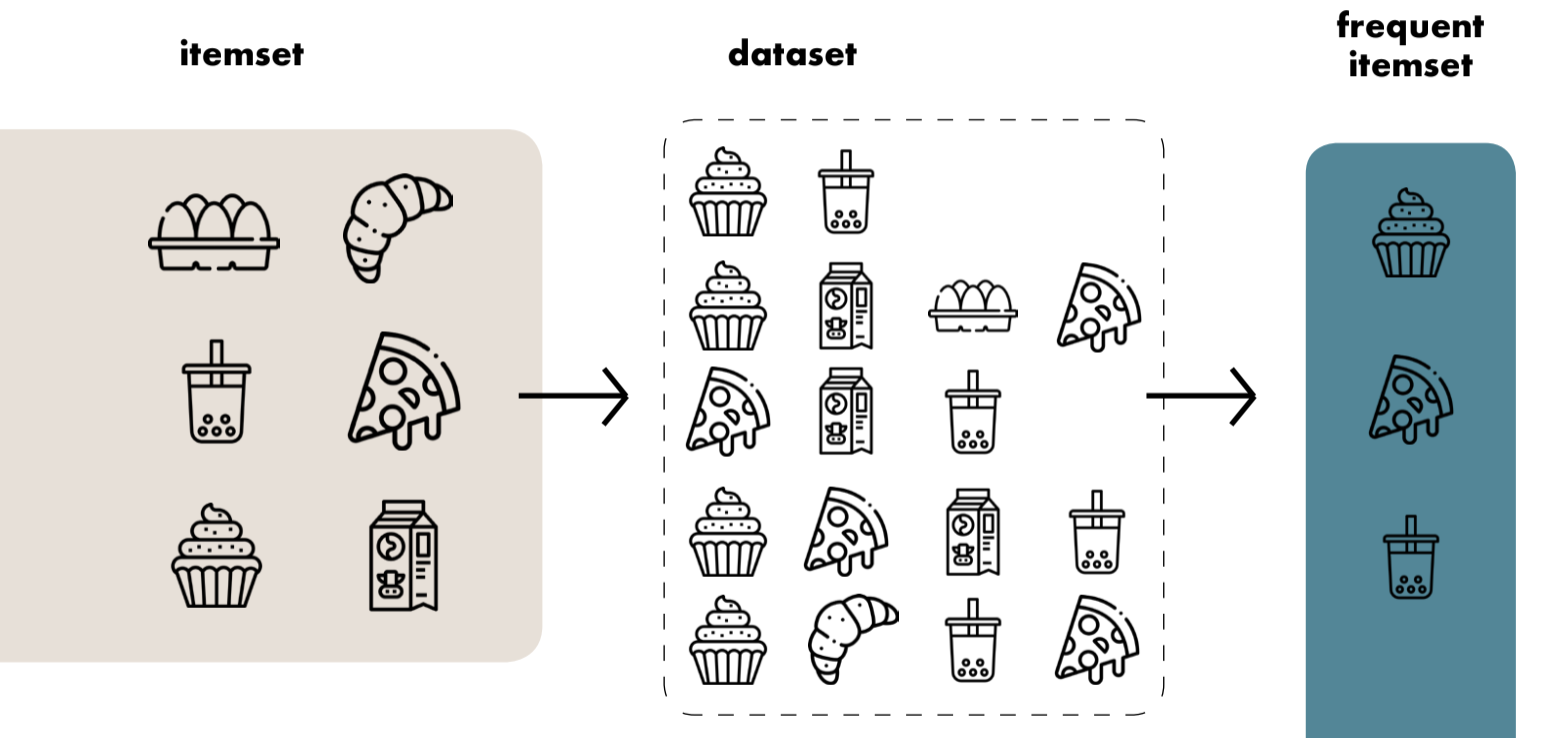
This kind of task can be accomplished by implementing an algorithm such as apriori. This family of algorithms is commonly used in frequent itemset mining, it is not a machine learning approach but it comes from a set of algorithms called association rule learning.
这种任务可以通过实现诸如apriori之类的算法来完成。 该算法家族通常用于频繁项集挖掘中,它不是机器学习方法,而是来自一组称为关联规则学习的算法。
The problem in this approach is that it does not give the possibility to measure the similarity between instances, since every instance in the dataset is not transformed into a mathematical representation, but only represented using two fancy metrics: confidence and lift.
这种方法的问题在于,它无法测量实例之间的相似性,因为数据集中的每个实例都不会转换为数学表示,而只能使用两个奇特的度量表示:置信度和提升。
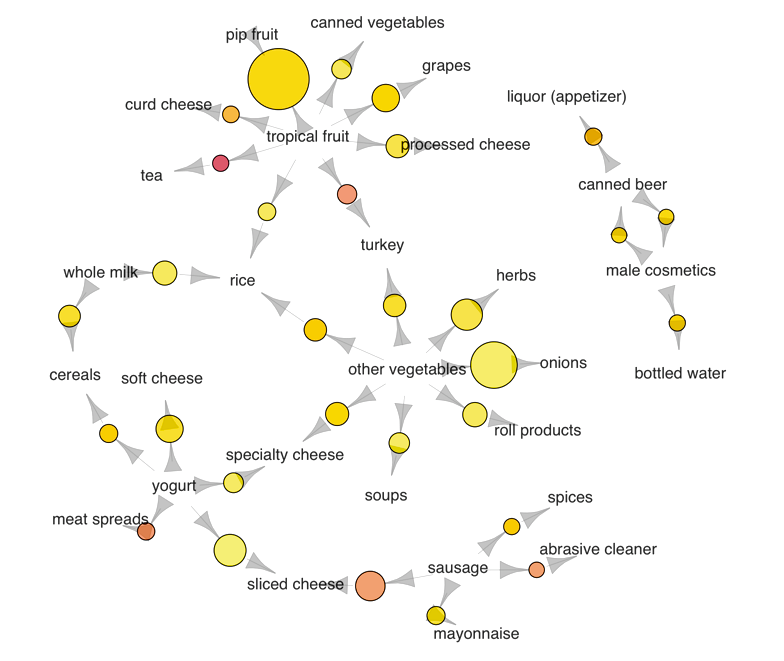
However, the cool thing about apriori is the possibility it gives to represent association rules with graph charts, very useful for evaluation and reporting purposes.
但是,关于apriori的最酷的事情是它提供了用图形图表表示关联规则的可能性,这对于评估和报告目的非常有用。
At that moment, it was necessary to take a step back and focus on the final goal: I need to find a way that lets me encode users in a mathematical way, preserving the relationships among them.
那时,有必要退后一步,专注于最终目标:我需要找到一种方法,让我以数学方式对用户进行编码,并保留他们之间的关系。
While taking this step back to analyze the situation at a macro level, I realized that the main issue in this is to “transform” usernames, into “numbers”, hence the question was clear: Which algorithm, model, or whatever lets you transform text to number?
在退一步来宏观分析情况时,我意识到其中的主要问题是将用户名“转换”为“数字”,因此问题很明显:哪种算法,模型或任何可让您转换的算法文字转数字?
Simultaneously, I realized there is already a very powerful tool called Tensorflow Embedding projector . It allows to project high dimensional data into a 3-dimensional space and automatically performs operations such as PCA (to reduce the number of dimensions) and calculates distances between vectors, hence it can display how much similar is a word to another.
同时,我意识到已经有一个非常强大的工具,称为Tensorflow嵌入式投影仪。 它允许将高维数据投影到3维空间中,并自动执行PCA之类的操作(以减少维数)并计算向量之间的距离,因此它可以显示一个单词与另一个单词的相似度。
实施: (The Implementation:)
The main idea was trying to train a Word2Vec model based on user-followers data to test if this model would be able to learn relationships among users.
主要思想是尝试根据用户关注者数据训练Word2Vec模型,以测试该模型是否能够了解用户之间的关系。
Word2Vec is a neural network that is able to generate a dense representation of words. This algorithm, more specifically an unsupervised learning algorithm, try to predict a word based on its neighbors, hence, in this case, the algorithm would predict a follower based on a user.
Word2Vec是一个神经网络,能够生成单词的密集表示。 该算法,更具体地说是无监督学习算法,试图基于单词的邻居来预测单词,因此,在这种情况下,该算法将根据用户来预测跟随者。
Word2Vec can be trained using mainly two different strategies: Skip-gram and CBOW.
可以使用两种主要策略来训练Word2Vec:Skip-gram和CBOW。
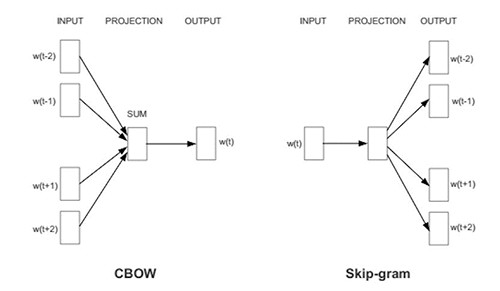
In CBOW a set of surrounding words (users) is combined to predict the word (user) in the middle. Oppositely, Skip-gram takes the word (users) in the middle to predict the context around.
在CBOW中,一组周围的单词(用户)被组合以预测中间的单词(用户)。 相反,Skip-gram在中间使用单词(用户)来预测周围的上下文。
To actually implement this, I choose to use Amazon SageMaker along with its Word2Vec implementation, called BlazingText.
要实际实现此功能,我选择使用Amazon SageMaker及其Word2Vec实现(称为BlazingText) 。
输入数据: (Input Data:)
The input data consists of a simple .txt file containing, for each user a comma-separated list of the profiles that particular user is following. The total size of the input data consists of around 5,2 million entries.
输入数据包含一个简单的.txt文件,其中包含每个用户的逗号分隔的特定用户所遵循的配置文件列表。 输入数据的总大小约为520万个条目。
培训阶段: (The training phase:)
The training is performed on a ml.c4.xlarge machine, using hyperparameters close to default, additionally, for budget reasons no hyperparameters optimization has been done.
训练是在ml.c4.xlarge机器上使用接近默认值的超参数执行的,此外,出于预算原因,尚未进行超参数优化。

As the training strategy skip-gram has been chosen, the training was done for five epochs, using a min_count of 100 users to predict the next one (somewhat a reasonable amount to understand which kind of profiles a user follows.), for each output vector I chose a size of 100 dimensions. The rest of the hyperparameters has been left default. For the complete list of available hyperparameters refer to the official documentation.
选择了训练策略跳跃图后,对每个输出进行了五个时期的训练,使用min_count个100个用户来预测下一个(对于了解用户遵循哪种类型的配置,这是一个合理的数量)。向量我选择了100个尺寸的尺寸。 其余的超参数已保留为默认值。 有关可用超参数的完整列表,请参考官方文档。
The training phase took around 9 hours.
培训阶段耗时约9个小时。
评价: (Evaluation:)
Understanding the correct way to evaluate this model is something that goes outside the scope of this article, however, a couple of interesting points surged:
理解评估此模型的正确方法超出了本文的范围,但是,提出了两个有趣的观点:
- Since the task consists of mapping all users inside a community, there is not training and test set for this application, paradoxically I am looking for a perfect overfit of the data. 由于该任务包括映射社区内的所有用户,因此没有针对该应用程序的培训和测试集,反而是我正在寻找数据的完美拟合。
The Word2Vec model does take into account the order in which words appear. This is something useless in this task, that is why a
window_sizeof 100 has been specified, in order to give a pre-context to the model to help predict the next followers.Word2Vec模型确实考虑了单词出现的顺序。 这在此任务中没有用,这就是为什么将
window_size指定为100的原因,以便为模型提供前置上下文,以帮助预测下一个关注者。
Once the training complete I ended up with a huge .tar.gz model, once uncompressed there are 2 files: vectors.txt and vectorz.bin which are perfectly compatible with the keyedvectors format provided by gensim .
一旦训练完成我结束了一个巨大的.tar.gz模型,解压后有两个文件: vectors.txt和vectorz.bin这是与完美兼容keyedvectors格式提供gensim 。
Reading the vectors using gensim is as easy and followers, moreover, we can do some manual test on the model using the most_similar method:
使用gensim读取向量非常容易,并且容易gensim关注,此外,我们可以使用most_similar方法对模型进行一些手动测试:
from gensim.models import KeyedVectorsword_vectors = KeyedVectors.load_word2vec_format(‘vectors.txt’, binary=False)To get an idea of how much precise and how good the model can understand differences between entities, especially when the difference is very subtle I decided to pick 2 well-known brands, Zara and Louis Vuitton.
为了了解模型可以理解实体之间差异的精确度和良好程度,特别是当差异非常微妙时,我决定选择两个知名品牌,Zara和Louis Vuitton。
Zara is a fast-fashion retailer while Louis Vuitton is (still) considered a French fashion house and luxury goods company.
Zara是一家快时尚零售商,而Louis Vuitton(至今)仍被视为法国时装公司和奢侈品公司。
Here the most common entities for each of them:
这里是每个实体最常见的实体:
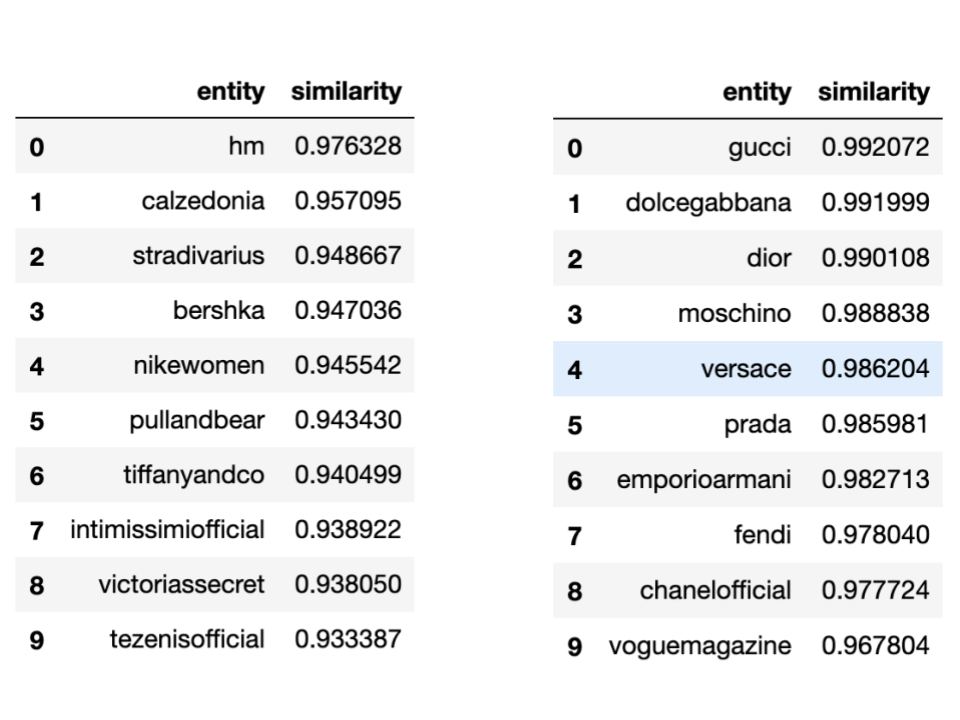
From the above results, it seems that the model is able to differentiate between some Luxury and Fas Fashion brands, returning results that actually make sense.
从以上结果来看,该模型似乎能够区分某些Luxury品牌和Fas Fashion品牌,并返回实际有意义的结果。
Let’s try it with something different, this time tacking two musicians that belongs to two completely different genres, Lady Gaga and Solomun:
让我们尝试一些不同的方法,这次是为属于两种完全不同流派的两位音乐家,Lady Gaga和Solomun增添魅力:
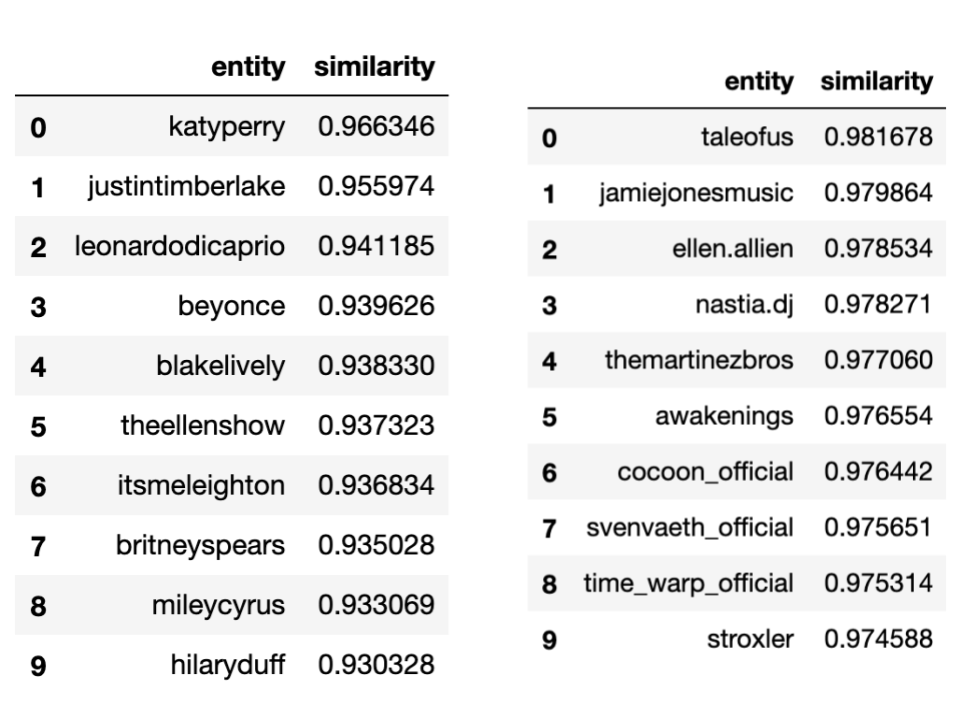
Surprisingly, the model also learned vectors for different musicians, being able to return different pop/commercial artists for Lady Gaga and more Techno artists for Solomun.
令人惊讶的是,该模型还为不同的音乐家学习了矢量,从而能够为Lady Gaga返回不同的流行/商业艺术家,为Solomun返回更多的Techno艺术家。
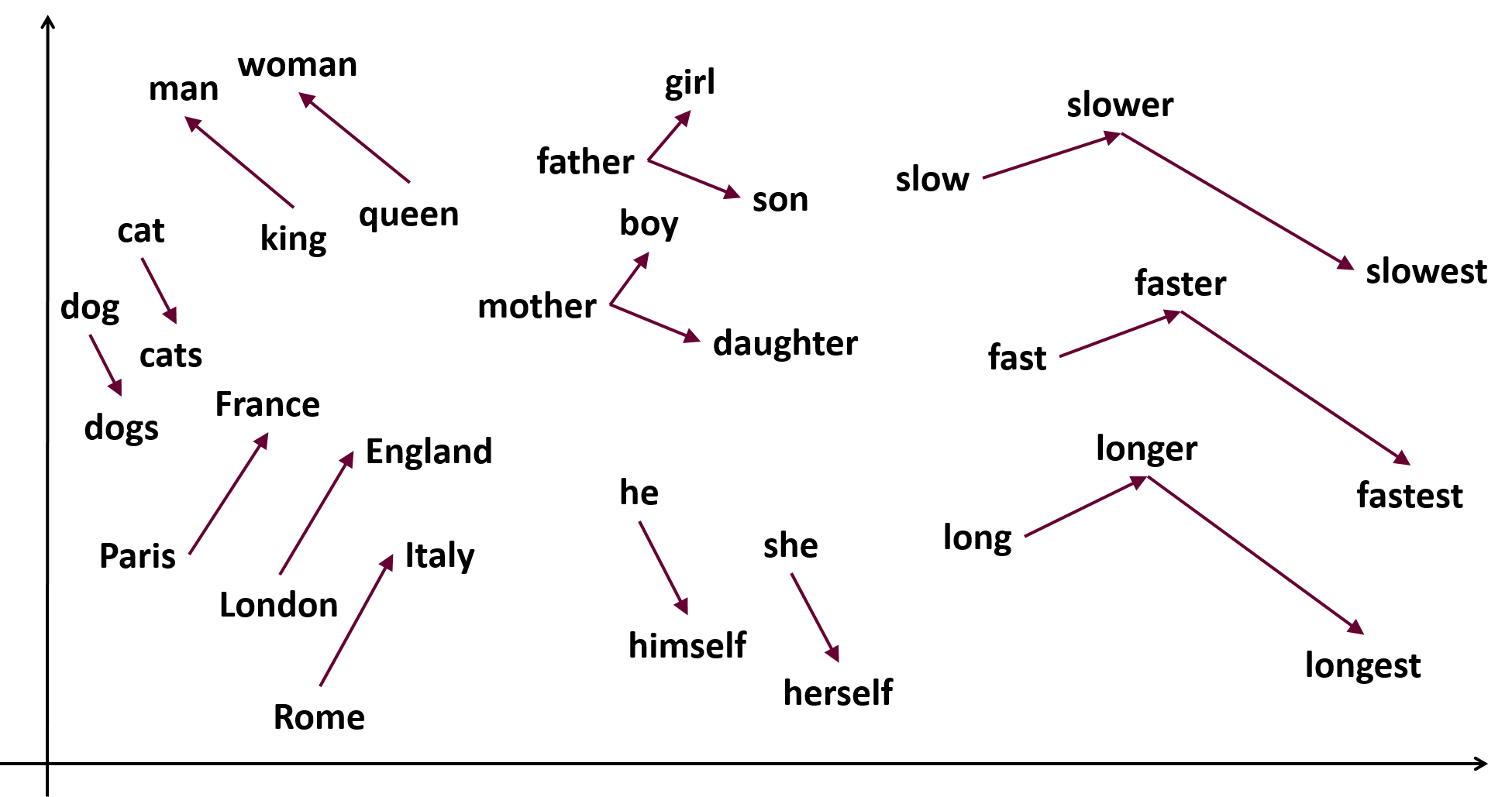
Going back to the interesting graph visualization mentioned before it is now also possible to do it: the model generates a 100-dimension vector for each entity, in order to plot it on a 2-D space is necessary to reduce the dimension, one way to achieve this is to use scikit-learn TSNE class which converts converting similarities between data points to join probabilities. Another way could be to compute a PCA.
回到前面提到的有趣的图形可视化,现在也可以做到这一点:该模型为每个实体生成一个100维向量,以便将其绘制在二维空间上以减小尺寸,这是一种方法要实现这一点,可以使用scikit-learn TSNE类,该类将数据点之间的转换相似性转换为连接概率。 另一种方法是计算PCA 。
The following plot consists of the 300 most common vectors visualized using TSNE and matplotlib:
下图包含使用TSNE和matplotlib可视化的300个最常见的向量:

It is evident that some clusters of data are present, meaning that the model successfully learned similarities across entities. For example, on the top-left corner, we can see some retail brands while on the bottom-right corner celebrities and some musicians.
显然存在一些数据簇,这意味着该模型成功地学习了跨实体的相似性。 例如,在左上角,我们可以看到一些零售品牌,而在右下角,则可以看到名人和音乐家。
Finally, we can also export computed vectors and metadata into .tsv format, making it readable for another tool previously mentioned: Tensroflow Embedding Projector.
最后,我们还可以将计算出的向量和元数据导出为.tsv格式,使其对于前面提到的另一种工具可读: Tensroflow Embedding Projector 。
The advantage here is that the embedding projector can compute different types of dimensionality reduction, giving the user the possibility to experiment with a few algorithms. Moreover, it is as simple as exporting the whole vectors and metadata from the Word2Vec model to the embedding projector and just load those files. A simple tutorial on how to do it can be found here.
这样做的好处是,嵌入式投影仪可以计算不同类型的降维,从而使用户可以尝试几种算法。 此外,这就像将整个矢量和元数据从Word2Vec模型导出到嵌入式投影仪并仅加载这些文件一样简单。 有关如何执行此操作的简单教程,请参见此处。
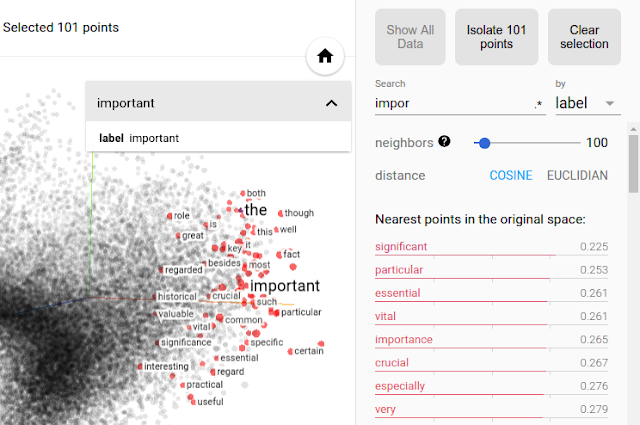
The following picture shows a 3-D PCA computed via the embedding projectors, the highlighted words represent the nearest points to the point labeled with “chanelofficial”.
下图显示了通过嵌入式投影仪计算出的3-D PCA,突出显示的单词表示最接近标记为“ chanofofficial”的点。
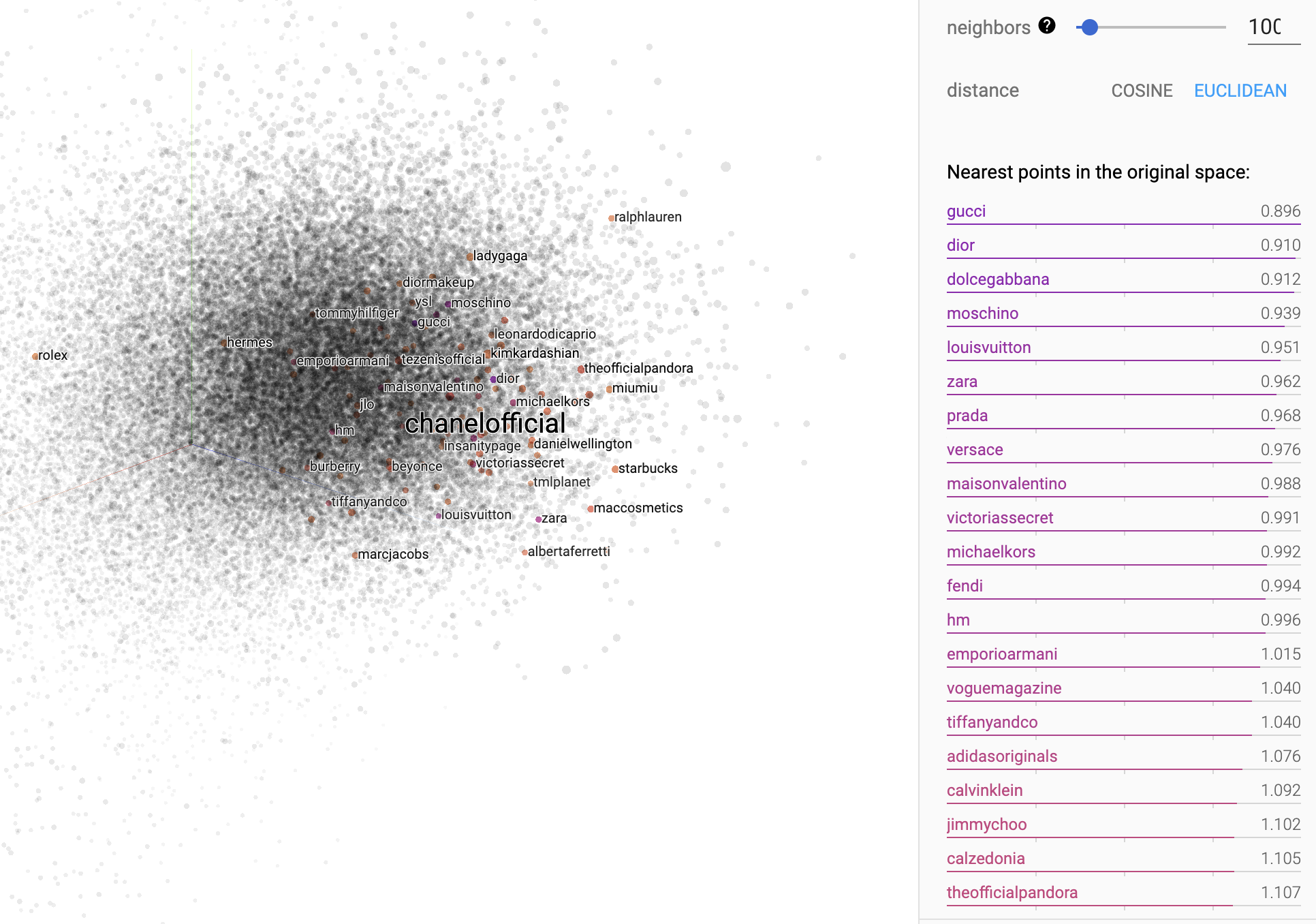
Another example, using “bmw” as a search query and the mythical dark mode:
另一个示例,使用“ bmw”作为搜索查询并使用了神秘的暗模式:

It is possible to see how in both examples the search query returned values that make sense in the context, in addition, comparing the values from the 2-D dimensionality reduction and the 3-D generated by the embedding projector, the latter one seems to be less “categorical” and more inclusive, returning entities that aren’t strictly part of the same category (Ex. Zara and h&m) but more opened toward a different idea of similarity (Ex. Mercedes and Rolex).
可以看到在两个示例中搜索查询如何返回在上下文中有意义的值,此外,还比较了二维降维和嵌入投影仪生成的3-D中的值,后者似乎可以不再是“分类”的,而是更具包容性的,返回的实体并非严格属于同一类别(例如Zara和h&m),但更倾向于不同的相似性概念(例如Mercedes和Rolex)。
结论: (Conclusion:)
At the end of this study some considerations can be made: the initial goal to provide a system able to identify similarities between entities seems to be fulfilled, however, the idea on how much one thing is similar to another is only something subjective or domain-oriented, for example, the similarity between two brands in the same domain could be distorted by the presence of other brands operating in completely different domains. Similarly to how the arithmetic means could be misleading the many outliers are in the sample.
在研究结束时,可以考虑一些问题:提供一个能够识别实体之间相似性的系统的最初目标似乎已经实现,但是,关于一件事物与另一事物相似的想法仅仅是主观的或领域明确的。举例来说,如果同一品牌的定位相同,则同一领域中两个品牌之间的相似性可能会因在完全不同的领域中运营的其他品牌的存在而失真。 与算术手段可能会引起误解的相似,样本中存在许多离群值。
One more consideration is the way the Word2Vec model has been used in this context: vectorizing an entire dataset like the one in this study is helpful as a way to index instances in the dataset, meaning that a new entity (also known as out of vocabulary token) could be positioned vectorized and positioned in the space if, and only if the whole training process is repeated.
需要进一步考虑的是在这种情况下使用Word2Vec模型的方式:矢量化整个数据集(如本研究中的数据集)有助于索引数据集中的实例,这意味着一个新实体(也称为词汇量不足)只有在重复整个训练过程的情况下,才能将其矢量化并放置在空间中。
For those reasons, I consider this tool more like an indexer, useful for a brand to discover similar instances in the user base. An example could be when looking for an influencer in the community, the brand manager could have an idea or know some users which could be good, however, a tool like this one could help managers to find other similar users on their community, which thanks to this algorithm have been indexed.
出于这些原因,我认为该工具更像是索引器,对于品牌在用户群中发现相似实例很有用。 例如,在社区中寻找有影响力的人时,品牌经理可能有一个想法或认识一些可能很好的用户,但是,像这样的工具可以帮助经理在他们的社区中找到其他类似的用户,这非常感谢该算法已被索引。
翻译自: https://towardsdatascience.com/social-media-embeddings-using-word2vec-clustering-users-b7c458be7b85















 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









