





 这篇博客是关于强化学习系列的第三部分,重点探讨非平稳环境。内容包括对非固定状态环境的理解,以及如何在这样的环境中进行有效的决策。通过实例和笔记本,读者可以深入学习如何应对不断变化的环境挑战。
这篇博客是关于强化学习系列的第三部分,重点探讨非平稳环境。内容包括对非固定状态环境的理解,以及如何在这样的环境中进行有效的决策。通过实例和笔记本,读者可以深入学习如何应对不断变化的环境挑战。
系列的链接:(Series’ Links:)
Non-Stationary | Notebook
非固定式| 笔记本
Welcome to the third entry of a series on Reinforcement Learning. On the previous article we explored the first on a series of many scenarios we’re going to tackle, the Multi-Armed Bandits. In this situation, we’re presented with an environment with a fixed number of actions, and are tasked on finding the action that yields the greatest reward. We presented some strategies, and measured their performance on this simple task.
欢迎来到强化学习系列的第三篇。 在上一篇文章中,我们探讨了我们要解决的许多场景中的第一个场景,即多武装土匪。 在这种情况下,我们将获得一个具有固定数量的动作的环境,并负责寻找产生最大回报的动作。 我们提出了一些策略,并评估了它们在此简单任务上的性能。
On this article, we’re going to modify the previously presented environment, and make it a little bit more dynamic. We will see how our previous strategies deal with non-stationary environments, and how we can do better.
在本文上,我们将修改先前介绍的环境,并使它更具动态性。 我们将看到我们以前的策略如何处理非平稳环境,以及我们如何做得更好。
固定与非固定: (Stationary vs. Non-Stationary:)
Last time we began our story on a Casino, filled with bandits at our disposal. Using this example, we built a simplified environment, and developed a strong strategy to obtain high rewards, the ɛ-greedy Agent. Using this strategy, we were able to find the best action given enough time, and therefore earn tons of reward. Our agent performed well because it had a good balance between exploring the environment and exploiting its knowledge. This balance allowed the agent to learn how the environment behaves, while also receiving high rewards along the way. But, there’s a small assumption our agent is doing to be able to behave so optimally, and that is that the environment is static, non-changing. What do we mean by this, and where is our agent making such assumption?
上次我们在赌场里开始我们的故事时,赌场里充斥着许多土匪。 使用此示例,我们构建了一个简化的环境,并制定了获得高回报的强大策略strategy-贪婪的Agent 。 使用这种策略,我们能够在足够的时间内找到最佳的操作,从而获得大量的回报。 我们的代理人之所以表现出色,是因为它在探索环境与开发知识之间取得了良好的平衡。 这种平衡使代理能够了解环境的行为方式,同时也能沿途获得丰厚的回报。 但是,有一个小小的假设,即我们的代理正在做才能使其表现得如此出色,那就是环境是静态的,不变的。 这是什么意思,我们的代理商在哪里做这样的假设?
固定式 (Stationary)
When we mention the word “stationary”, we’re talking about the underlying behavior of our environment. If you remember from last time, the environment is defined to have a set of actions that, upon interaction, yield a random reward. Even though the reward is random, they are generated from a central or mean value that every action has, which we called the true value. To see what I’m talking about, let’s have a look at one of the animated interactions we saw on the previous article.
当我们提到“固定的”一词时,是在谈论我们环境的潜在行为。 如果您还记得上一次,则将环境定义为具有一组行为,这些行为在交互时会产生随机奖励。 即使奖励是随机的,它们也是根据每个动作所具有的中心值或平均值产生的,我们称其为真实值。 要了解我在说什么,让我们看一下在上一篇文章中看到的一种动画交互。
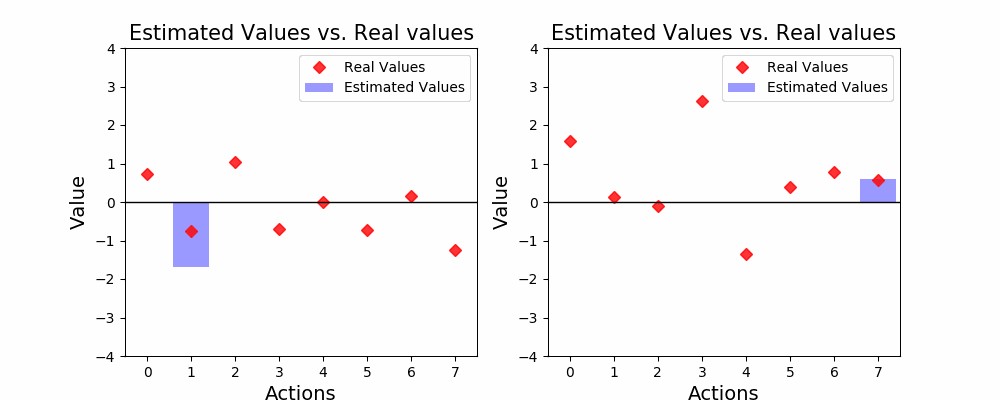
Observe how the true values (red dots) are static. Even though the environment generates random rewards, each action has a true expected value which is never-changing. This is a big assumption to make, and one that almost no valuable real-world scenario will follow. If, for example, our casino analogy was static, then casinos would be quickly out of business! So, how can we portray a more realistic scenario without making the problem that more complex?
观察真实值(红色点)是如何静态的。 即使环境产生随机的奖励,每个动作都具有真实的期望值,并且永远不变。 这是一个很大的假设,几乎没有任何有价值的现实情况会发生。 例如,如果我们的娱乐场比喻是静态的,那么娱乐场将很快倒闭! 那么,如何在不使问题变得更加复杂的情况下描绘出更加现实的情况呢?
非平稳 (Non-Stationary)
Making the multi-armed bandit scenario non-stationary is actually pretty simple, all we need to do is make sure the expected value for all our actions is always changing. Now, this change should not be completely erratic, since no strategy would be able to deal with a completely random scenario. Instead, we want the expected value to slowly drift away. This is so our agent can still consider previous experience meaningful for future decision-making. Here’s how we can implement such environment
实际上,使多武装匪徒的局势不稳定是很简单的,我们要做的就是确保我们所有行动的期望值始终在变化。 现在,此更改不应完全不稳定,因为没有任何策略能够处理完全随机的情况。 相反,我们希望期望值逐渐消失。 因此,我们的代理商仍可以将先前的经验视为对将来的决策有意义。 这是我们如何实现这种环境的方法
There are some subtle changes. Now, every time our agent interacts with the environment, the true value for each action changes by a small, random amount. How much it changes can be controlled when we create the environment. This is so we can experiment with it later on. How does the environment behave now? We can make the same visualization as before, but with our new environment. Since we’re not interested in the agent, we’re not going to plot its interaction (yet).
有一些细微的变化。 现在,每次我们的代理与环境互动时,每个动作的真实值都会以很小的随机量变化。 当我们创建环境时,可以控制多少变化。 这样我们以后就可以进行试验了。 现在的环境表现如何? 我们可以使用以前的环境进行与以前相同的可视化。 由于我们对代理不感兴趣,因此我们不会绘制其交互作用(尚未)。
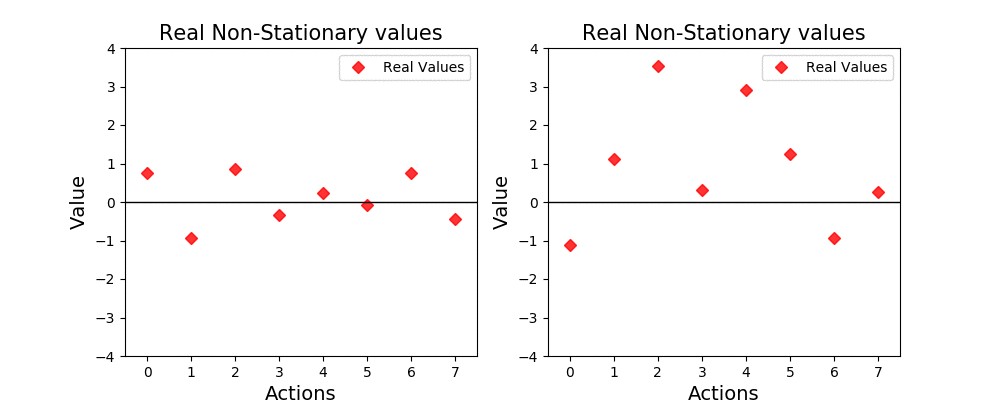
The previous plot was generated with a somewhat high amount of non-stationary for the sake of illustration. Note that on some instances the highest-valued action changes due to the random movements. Since we’re interested on an agent that behaves as optimally as possible, we would expect that the agent can observe this changes and act accordingly.
为了说明起见,先前的图以一定量的非平稳生成。 请注意,在某些情况下,价值最高的动作会因随机移动而发生变化。 由于我们对一个行为尽可能最佳的代理感兴趣,因此我们希望该代理可以观察到这种变化并采取相应的行动。
目前表现 (Current Performance)
Having declared our new environment, let’s see how the ɛ-greedy Agent performs here. Knowing that our agent has room for exploration, it should only be a matter of time before the agent notices that the environment changed.
声明了我们的新环境后,让我们看看ɛ-贪婪特工在这里的表现。 知道我们的代理商有探索的余地,代理商注意到环境已经改变只是时间问题。
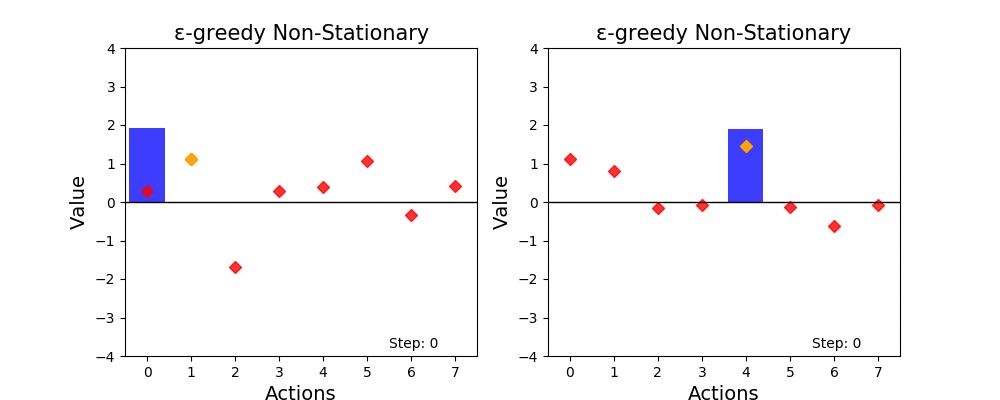
To make visualization clearer, I’ve added some colors to show which is the action with the greatest value (orange dot) and which action the agent considers to be best (blue bar). For this animations, the amount of elapsed time was extended to 800 steps. At first, the agents are able to rapidly adapt to changes in the environment, but after a while, the estimated values stagnate, and tend to move slow. This makes it hard to catch up to changes in the future, and causes the agent to stay on a sub-optimal action for longer. As always, let’s plot the optimality of this strategy by averaging the performance of many experiments.
为了使可视化更加清晰,我添加了一些颜色以显示哪个是具有最大价值的操作(橙色点)以及代理认为是最佳的操作(蓝色条)。 对于此动画,经过时间量已扩展到800步。 最初,代理可以快速适应环境的变化,但是过一会儿,估计值将停滞不前,并且趋向于缓慢移动。 这使得很难适应将来的变化,并使代理在次优操作中停留的时间更长。 与往常一样,让我们通过平均许多实验的性能来绘制该策略的最优性。
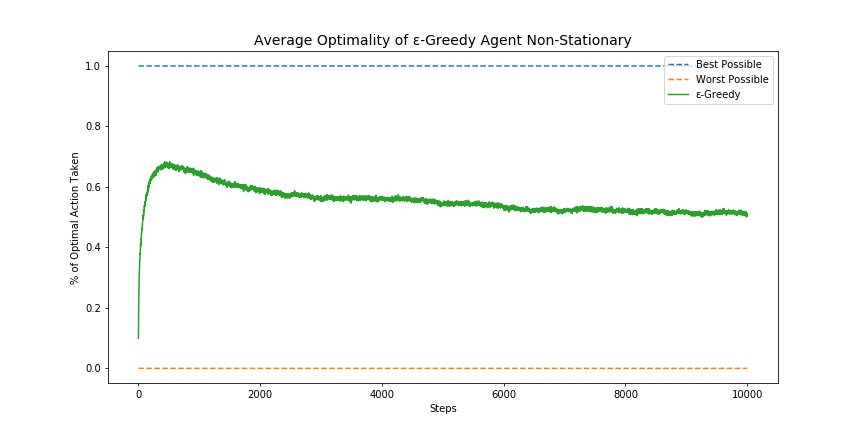
As we can see, at first our agent rapidly adapts to the environment, but as more time goes on, its performance starts to decrease. Even though our agent is always gathering experience, and is always exploring the environment, it seems like it can’t handle a dynamic world. How can we ensure that our agent will adapt to changes even further in the future?
如我们所见,起初我们的代理Swift适应环境,但是随着时间的流逝,其性能开始下降。 即使我们的代理商一直在收集经验,并且一直在探索环境,但似乎无法应对动态世界。 我们如何确保我们的代理商在未来会更适应变化?
更新规则问题 (The Update Rule Problem)
Going back to the previous article, we exposed a way in which we can easily evaluate how valuable it is to take an action on the multi-armed bandit scenario. This evaluation was done using a basic average, which would converge to the expected value of the action after a given time. If you’ve ever dealt with taking averages, you should know that the more items you add up to the operation, the more robust the result is. Let’s say we want to take the average of a list of three values:
回到上一篇文章,我们介绍了一种方法,可以轻松地评估对多臂匪徒案采取行动的价值。 该评估是使用基本平均值进行的,该平均值会在给定时间后收敛到该操作的预期值。 如果您曾经处理过取平均值,那么您应该知道,加到运算中的项目越多,结果就越可靠。 假设我们要取三个值的平均值:
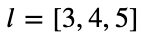
Then the average would equal 4. Given such a small list, a change on any of the inputs will vary the resulting average by some amount.
那么平均值将等于4 。 鉴于清单如此之小,任何输入的变化都会使所得平均值有所不同。
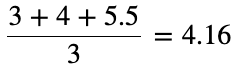
If we instead use a larger list of values, then the same change in the input will cause a smaller variation on the output.
如果改用较大的值列表,则输入中的相同更改将导致输出中的较小变化。
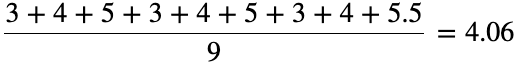
To sum up, the more information we have to calculate the average, the less prone the result is to outliers or variations. This effect can also be seen in the Incremental Average Update Rule we implemented previously:
总而言之,我们需要更多的信息来计算平均值,结果越不容易出现异常值或变异。 在我们之前实现的“增量平均更新规则”中也可以看到这种效果:

The expression of 1/n causes the same effect, given that as n gets larger, then the Q value changes less and less. This is what causes our agent to stagnate. Once enough experience has been collected, it’s very hard to make our agent adapt and change its mind.To fix this, we must modify the update rule, so that later experience isn’t discarded or ignored.
假设随着n变大,则Q值的变化越来越小, 1 / n的表达式会产生相同的效果。 这就是导致我们的代理停滞不前的原因。 一旦收集到足够的经验,就很难使我们的代理适应和改变主意。要解决此问题,我们必须修改更新规则,以免以后的经验被舍弃或忽略。
通用更新规则 (The General Update Rule)
Those that have some experience or knowledge with Machine Learning in general might have already seen a pattern behind the update rule presented above. If you haven’t, let me give a brief explanation:
那些总体上具有一定机器学习经验或知识的人可能已经看到了上面介绍的更新规则的模式。 如果您还没有,请允许我简要说明一下:
Generally, for a Machine Learning model to learn, we use a measure called the Error or Loss function. This measurement determines how off our model’s performance is compared to the expected results. To improve our model, we update its parameters by moving them against the error. How much should we move or modify our parameters? That’s determined by the learning rate. Here’s an overly simplified demonstration of the above statement.
通常,对于要学习的机器学习模型,我们使用一种称为错误或损失函数的度量。 此度量确定将我们模型的性能与预期结果进行比较的程度。 为了改进我们的模型,我们通过针对误差移动参数来更新其参数。 我们应该移动或修改多少参数? 这取决于学习率。 这是上述声明的过度简化的演示。
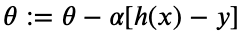
Looks familiar, right? h(x) represents the output of our model, while α represents the learning rate. This is a grossly simplified version of Gradient Descent, which is the standard method for improving a model in most machine learning tasks. If interested on this topic, I think this is a great article about Gradient Descent.
看起来很熟悉吧? h(x)代表模型的输出,而α代表学习率。 这是Gradient Descent的简化版本,它是在大多数机器学习任务中改进模型的标准方法。 如果对此主题感兴趣,我认为这是一篇有关Gradient Descent的好文章。
Comparing the incremental average update rule and gradient descent, our intuition would say that 1/n is equivalent to the learning rate α, and that would be correct. We can therefore modify the update rule we use to a more generalized version.
比较增量平均更新规则和梯度下降,我们的直觉会说1 / n等于学习率α ,这是正确的。 因此,我们可以将我们使用的更新规则修改为更通用的版本。
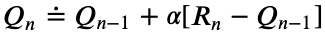
What does this do? Well, now we can define α to be anything other than 1/n. Using a constant for the learning rate is a simple but effective method used in other machine learning paradigms, and so we could try it as well here. Let’s implement our new agent!
这是做什么的? 好了,现在我们可以将α定义为1 / n以外的任何值。 使用常数作为学习速率是一种在其他机器学习范例中使用的简单但有效的方法,因此我们在这里也可以尝试使用。 让我们实施我们的新代理!
We’re basing our new implementation on the ɛ-greedy Agent. There are some minor changes. First, we’re adding a new parameter called ss_func, which allows us to change the step-size function if desired. By default, this function returns a value of 0.1, which will be the constant step-size used here. Also, at the time of updating the estimates, we execute the ss_func function, and use the return value as our step size. Just to make things clear, the next line of code would be equivalent to declaring an ɛ-greedy Agent using this new implementation.
我们将新的实现基于ɛ-贪婪代理。 有一些小的变化。 首先,我们添加了一个名为ss_func的新参数,该参数允许我们根据需要更改步长函数。 默认情况下,此函数返回值0.1,这将是此处使用的恒定步长。 另外,在更新估算值时,我们执行ss_func函数,并将返回值用作步长。 为了清楚起见,下一行代码等效于使用此新实现声明一个ɛ-贪婪的Agent。
Let’s see how this new agent performs on our dynamic multi-armed bandit scenario, compared to the previous ɛ-greedy strategy.
与以前的this-贪婪策略相比,让我们看一下这个新代理在动态多臂强盗案中的表现。
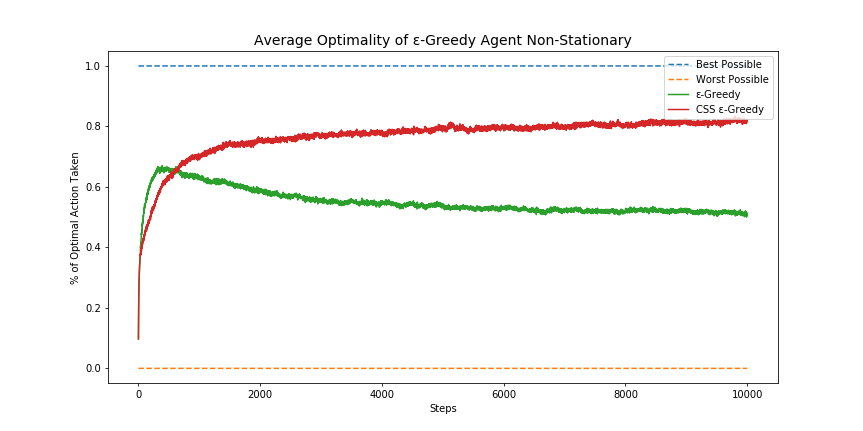
And just like that, our agent is now capable of adapting to a dynamic world! By using a constant step-size (or learning rate), the agent will no longer stagnate. Instead, every new experience is valued the same, and so it’s possible to overcome previous experiences with new knowledge.
就像这样,我们的代理商现在能够适应动态世界! 通过使用恒定的步长(或学习率),代理将不再停滞。 取而代之的是,每一个新的经验都具有相同的价值,因此可以通过新知识来克服以前的经验。
步长参数: (The Step Size Parameter:)
As a final note, I want to briefly go into understanding this new parameter α, how it behaves and what values are reasonable for it. We’ve already seen that a value of 0.1 gave great results on this scenario, but how would it behave with other values?
最后一点,我想简要地了解一下这个新参数α ,它的行为以及适合它的值。 我们已经看到,在这种情况下,值为0.1会产生很好的结果,但是它将与其他值一起表现如何?
The step-size parameter can be considered as a measurement of confidence in new knowledge. A high value for α is analogous to saying that we trust our recent experience to be a good representation of the problem at hand. As such, the step-size parameter should lie between 0 and 1, where 1 is total confidence and 0 is no confidence on how representative the previous interaction is towards understanding the underlying problem. Let’s see how this two values affect the learning outcome.
步长参数可以视为对新知识的信心的度量。 α的高值类似于说我们相信我们最近的经验可以很好地表示当前问题。 这样,步长参数应介于0和1之间,其中1是总置信度,0是关于先前交互作用对理解潜在问题的代表性的置信度。 让我们看看这两个值如何影响学习成果。
A confidence of 1 would turn our update rule into this:
置信度为1会使我们的更新规则变为:

Here, we’re basically saying that our estimates should equal the reward recently obtained, disregarding any previous experience. This would only work if we know (or are really confident) that the reward we receive is deterministic and stationary. Since this is not the case in the real world (because interactions are usually stochastic, and the ones that aren’t don’t usually require learning algorithms), a value of 1 for the step-size should not be considered.
在这里,我们基本上是在说,我们的估算值应该等于最近获得的报酬,而不考虑以前的经验。 仅当我们知道(或非常有信心)我们收到的奖励是确定性的和固定的,这才行得通。 由于在现实世界中并非如此(因为交互通常是随机的,而那些通常不需要学习算法的交互),步长的取值为1。
A confidence of 0 would cancel out the update part of our update rule:
置信度为0会取消我们更新规则的更新部分:
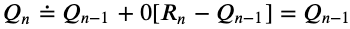
With a step-size of zero, we’re removing the possibility for our agent to learn from experience. For this reason, a constant step-size of 0 is meaningless for Reinforcement Learning.
步长为零,我们消除了代理商从经验中学习的可能性。 因此,对于增强学习而言,恒定的步长为0毫无意义。
As for other values inside the range of 0 and 1, they determine how quickly or slowly our agent responds to variance, and how fast it would converge. Values close to 1 would quickly update the estimated values, and try to keep up with changes in the environment, but it would also be susceptible to noise. On the other hand, small values would take longer to converge, and react slower to a dynamic environment. Let’s compare some values on this scenario.
至于0到1范围内的其他值,它们确定了我们的代理对方差的响应速度或速度,以及收敛的速度。 接近1的值将快速更新估计值,并试图跟上环境的变化,但也会受到噪声的影响。 另一方面,较小的值将花费较长的时间才能收敛,并且对动态环境的React较慢。 让我们比较这种情况下的一些值。
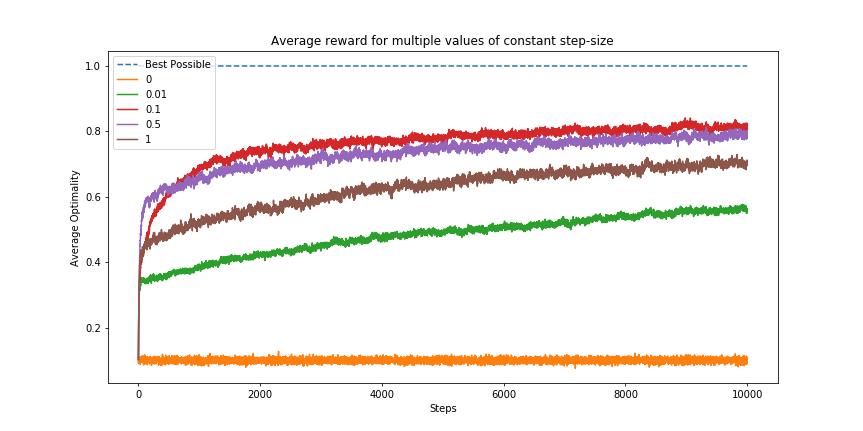
As predicted, the extremes are not well suited for the problem, low values converge slower and higher values converge faster. Different to other fields of Machine Learning, in which the learning-rate or step-size affects mostly convergence time and accuracy towards optimal results, in Reinforcement Learning the step-size is tightly linked to how dynamic the environment is. A really dynamic world (one that changes often and rapidly) would require high values for our step size, or else our agent will simply not be fast enough to keep up with the variability of the world.
正如预测的那样,极端值不适用于此问题,低值收敛较慢,而较高值收敛较快。 与机器学习的其他领域不同,在机器学习的其他领域中,学习速率或步长大小主要影响收敛时间和朝向最佳结果的准确性,在强化学习中,步长大小与环境的动态性紧密相关。 一个真正动态的世界(一个经常快速变化的世界)将需要我们步长的高价值,否则我们的代理人将不够快以跟上世界的变化性。
结语 (Wrap Up)
In this article we covered the idea of non-stationary, and implemented it onto the Multi-Armed Bandit scenario.We then explored how our previous contestant, the ɛ-greedy Agent, performed in this new situation, and exposed what made it behave sub-optimally. Then, by borrowing some concepts from other machine learning areas, we defined a new way of evaluating our actions. This new update rule allowed for a constant step-size, which was key to solve the problem of non-stationary. Lastly, a brief explanation of how the step-size parameter affects the learning outcome was demonstrated.
在本文中,我们讨论了非平稳的想法,并将其应用于多武装强盗场景中,然后探讨了我们的前参赛者ɛ-贪婪特工在这种新情况下的表现,并揭示了使它表现不佳的原因-最佳。 然后,通过借鉴其他机器学习领域的一些概念,我们定义了一种评估行动的新方法。 这个新的更新规则允许恒定的步长,这是解决非平稳问题的关键。 最后,简要说明了步长参数如何影响学习结果。
This article was intended to touch on a few topics that were too long to be added to the previous one, but that still had enough value to be presented on the series. The Generalized Update Rule will play a role later on, and for that reason it had to be covered. With this, we can say goodbye to the Multi-Armed Bandit, and start touching on other topics. Next article will cover Markov Decision Processes (MDPs) and build the foundation for the famous Bellman Equation. These two concepts are the backbone of Reinforcement Learning, and understanding them could literally change for perspective of the world. See you then!
本文旨在介绍一些主题,这些主题太长了,无法添加到上一个主题中,但是仍然具有足够的价值,可以在本系列中进行介绍。 通用更新规则将在稍后发挥作用,因此必须将其涵盖在内。 这样,我们就可以告别多武装强盗,并开始涉及其他话题。 下一篇文章将介绍马尔可夫决策过程(MDP),并为著名的Bellman方程式奠定基础。 这两个概念是强化学习的基础,对它们的理解从字面上看可能会因世界的观点而改变。 回头见!
系列的链接: (Series’ Links:)
Non-Stationary | Notebook
非固定式| 笔记本


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









