





益盟指标修改
For information about QOS+, a sister metric of the one described in this article, click here or scroll all the way to the bottom of this article.
有关QOS +的信息,QOS +是本文所述的一种度量标准, 请单击此处 或一直滚动到本文的底部。
Earlier this year, I created a model to try to quantify the quality of an MLB pitch. The idea was that each pitch can be given an expected run value based on its zone location, its release point, and some of its pitch characteristics. Though I was initially happy with the results of my metric (originally introduced here) and the subsequent analysis I was able to do (here, here, here, and here), I acknowledged that there was room to improve from a modeling standpoint.
今年早些时候,我创建了一个模型来尝试量化MLB音高的质量。 想法是,可以根据每个音高的区域位置,释放点和某些音高特性为其指定预期的运行值。 尽管我最初对度量标准的结果(最初在此处介绍)和我能够进行的后续分析( 此处 , 此处 , 此处和此处 )感到满意,但我承认从建模的角度来看还有改进的余地。
In the last few days, I decided to completely rebuild my pitch quality metric from the ground up using a much more statistically sound model building process. This article will describe that process in detail and be accompanied by my reproducible code, found here.
在过去的几天里,我决定使用更加统计上合理的模型构建过程完全重新构建我的音高质量指标。 本文将详细描述该过程,并附带可在此处找到的我的可复制代码。
题 (Question)
For this project, I began by asking
对于这个项目,我首先问
How many runs would we expect to be scored on each individual pitch of the 2020 season?
我们希望在2020赛季的每个球场上能获得多少分?
In order to answer this question, I decided to use the linear weights framework which gives every pitch outcome (ball, strike, single, home run, out, etc.) a run value based on how valuable that event has been in previous games. The idea is that pitchers who throw more pitches that are likely to get good outcomes (strikes and outs on balls in play) should be rewarded and pitchers who throw more pitches likely to lead to bad outcomes (balls and baserunners on balls in play) should be punished.
为了回答这个问题,我决定使用线性权重框架 ,该框架根据该事件在以前的比赛中的价值,为每个投球结果(球,击球,单打,本垒打,出局等)提供奔跑值。 这样做的想法是,应该对投出更多可能会产生良好结果的投手(在比赛中击球和出击)给予奖励,而投出更多可能会导致不良结果的投手(在比赛中的球和垒跑者)应该得到奖励。被惩罚。
以前的方法问题 (Previous Method Issues)
What was so wrong with the previous metric, Expected Run Value (xRV), that I had to change it? A few things. Firstly, it was made using a model called k-nearest neighbors which is rightfully known for not being a very rigorous with large, high dimensional models like this one. In that model, I used the 100 nearest neighbors, an arbitrary value that I chose for no particular reason. I did no feature selection and used only the eye test to evaluate whether the metric was good enough. I concluded that it was, and I was wrong as evidenced by its poor RMSE score (more on this later). It was a good first step but I knew I could do better, so I did. The result was an improved metric whose blueprint is contained entirely within this article.
以前的指标“期望运行价值(xRV)”有什么问题,我必须进行更改? 一些东西。 首先,它是使用称为k最近邻的模型制作的,该模型以像这样的大型高维模型不是很严格而闻名。 在该模型中,我使用了100个最近的邻居,这是我无故选择的任意值。 我没有选择功能,仅使用眼图测试来评估指标是否足够好。 我得出的结论是这样,并且我错了,如差的RMSE分数所证明的(稍后会对此进行更多介绍)。 这是很好的第一步,但我知道我可以做得更好,所以我做到了。 结果是改进了指标,其蓝图完全包含在本文中。
新方法 (New Method)
Before getting into the weeds, I want to give an overview of how this new metric, which I am calling Quality of Pitch (QOP for short), is calculated. I grouped every pitch of the season into one of 16 categories based on the pitcher handedness, batter handedness, and pitch type. I will go into details on these groups later. For each group, I made a separate Random Forest model on a subset of pitches from that category, confirmed the model was useful, and then applied that model to all the pitches in that category. Each pitch in the dataset was in only one category and thus only got predictions from one of the 16 models.
在深入研究杂草之前,我想概述一下如何计算这个新指标(我称其为音高质量(简称QOP))。 我根据投手的惯用性,击球手的惯性和发球类型将赛季的每个发球分为16个类别之一。 稍后,我将详细介绍这些小组。 对于每个组,我针对该类别的音高子集制作了一个单独的“随机森林”模型,确认该模型有用,然后将该模型应用于该类别中的所有音高。 数据集中的每个音高仅属于一个类别,因此只能从16个模型之一中获得预测。
Finally, I brought the predictions from all 16 models back together and evaluated the quality of the model by Root Mean Squared Error (RMSE). The model showed significant improvement over the first iteration of this metric that I originally made back in March.
最后,我将所有16个模型的预测重新组合在一起,并通过均方根误差(RMSE)评估了模型的质量。 该模型相对于我最初在三月份进行的该指标的第一次迭代显示了显着的改进。
Into the weeds we go.
进入杂草我们去。
数据采集 (Data Acquisition)
All the data used for this project came from the publicly available BaseballSavant.com via Bill Petti’s baseballR package using the following function and parameters:
该项目使用的所有数据均来自Billballetti的balloonR软件包,使用以下功能和参数通过BaseballSavant.com公开提供:
data = scrape_statcast_savant(start_date = “2020–07–23”,
end_date = “2020–09–05”, player_type = “pitcher”)This method only tends to grab 40,000 pitches at a time, so I broke it up into more function calls with smaller date ranges and used the rbind() command to combine all of the dataframes into one.
该方法一次只能获取40,000个音高,因此我将其分解为多个具有较小日期范围的函数调用,并使用rbind()命令将所有数据帧组合为一个。
数据清理和功能创建 (Data Cleaning and Feature Creation)
This publicly available dataset unfortunately does not include the linear weight value of each event like I needed to answer my research question, so I calculated the linear weights from scratch. I am sure the linear weight values for 2020 exist somewhere else on the internet that I could go find and join into the dataset, but I already had the code from a previous project and I did not want to have to rely on any outside source for any part of this project except for the initial data acquisition. Fair warning that this code, which again can be found on my GitHub here, is a bit messy but ultimately does the job.
不幸的是,这个公开可用的数据集不包含每个事件的线性权重值,就像我回答研究问题所需要的那样,因此我从头开始计算了线性权重。 我确定2020年的线性权重值存在于互联网上的其他地方,我可以找到它并加入数据集,但是我已经有了上一个项目的代码,因此我不想依赖任何外部来源除初始数据采集外,该项目的任何部分。 公平的警告,该代码,这也可以在我的GitHub上找到这里 ,是一个有点乱,但最终做这项工作。
I want to note that I made the choice to assign pitches resulting in a strikeout with the same run value as a typical strike (not a strikeout) and pitches resulting in a walk were given the run value of a typical ball. Because this metric is meant to be context neutral and ball-strike count will not be a feature in this model, I felt this change was necessary both to make and to note here.
我想指出的是,我做出的选择是分配给三叉戟以与典型敲击(不是三叉戟)相同的奔跑值的音高,并且给导致步行的螺距赋予典型球的奔跑值。 由于此指标是上下文无关的,并且在此模型中不会增加打击次数,因此我觉得需要在此处进行更改并加以注意。
Once I had the linear weight value for every row in the data, I grouped all pitches into four pitch type groups according to the following table:
一旦获得了数据中每一行的线性权重值,便根据下表将所有音高分为四个音高类型组:
All pitches with other pitch types like Knuckleballs, Eephuses, etc. were deleted from the dataset. About 250 pitches were lost during this step leaving me with only about 170,000 remaining. (Note: the data used in this article is through games played on September 5th)
所有其他音高类型(例如指节球,以弗所等)的音高都将从数据集中删除。 在此步骤中丢失了大约250个音高,仅剩下剩余的170,000个。 (注意:本文使用的数据是通过9月5日玩的游戏得出的)
Finally, I created three new variables that quantified the velocity and movement difference between each Offspeed pitch and that pitcher’s average Fastball velocity and movement. I did this because I wanted the option to include these variables in my final model later on if they proved useful.
最后,我创建了三个新变量,用于量化每个Offspeed音高与该投手的平均Fastball速度和运动之间的速度和运动差异。 之所以这样做,是因为我希望以后可以选择将这些变量包括在最终模型中,如果它们确实有用的话。
特征选择和重要性 (Feature Selection and Importance)
Like I said earlier, this metric is really a combination of 16 different Random Forest models. Every pitch thrown in 2020 fell into one of 16 categories, shown here:
就像我之前说的,该指标实际上是16种不同的随机森林模型的组合。 到2020年,每个投掷球都属于16个类别之一,如下所示:
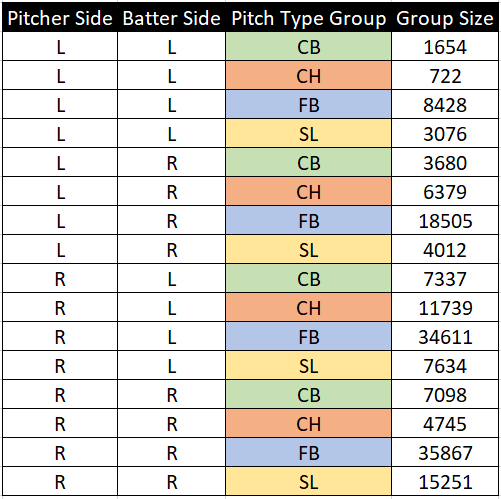
Although I am creating 16 total models, there will only be two model equations: one for Fastballs and one for Offspeed pitches.
尽管我总共创建了16个模型,但只有两个模型方程式:一个用于Fastballs,一个用于Offspeed pitch。
快球功能选择 (Fastball Feature Selection)
After subsetting down to just Right vs. Right Fastballs and taking a random sample of 10% of this data, I ran the Boruta feature selection algorithm with all possible features. (Using all the data would take far too long and would yield similar results, so I used this smaller subset instead.) Boruta is a tree-based algorithm that is especially well-suited for feature selection in Random Forest models.
将子集分解为“ Right vs. Right Fastballs”并随机抽取此数据的10%后,我运行了具有所有可能特征的Boruta特征选择算法。 (使用所有数据会花费太长时间,并且会产生相似的结果,因此我改用了这个较小的子集。)Boruta是一种基于树的算法,特别适合于随机森林模型中的特征选择。
library(Boruta)Boruta_FS <- Boruta(lin_weight ~ release_speed + release_pos_x + release_pos_y + release_pos_z + pfx_x + pfx_z + plate_x + plate_z + balls + strikes + outs_when_up + release_spin_rate,
data = rr_fb_data_sampled)print(Boruta_FS)The algorithm found all the above variables to be significant at the 0.01 level except for balls, strikes, and outs in the inning which makes sense due to my context neutral method of calculating linear weights, the response variable.
该算法发现上述所有变量在0.01级别上都很重要,除了局中的球,打击和出局外,这是有道理的,这归功于我计算线性权重的上下文中性方法,即响应变量。
So the features in my final Fastball model are pitch velocity, release point, spin rate, and plate location. Because I am using Random Forests, I don’t need to worry about potential covariance between features like movement and spin rate. Here are the final features in the model, sorted by their importance to the prediction of linear weight run value according to Boruta.
因此,我最终的Fastball模型中的特征是俯仰速度,释放点,旋转速度和板位置。 因为我使用的是“随机森林”,所以无需担心运动和旋转速度等要素之间的潜在协方差。 这是模型的最终特征,根据对Boruta而言,它们对预测线性权重运行值的重要性进行排序。
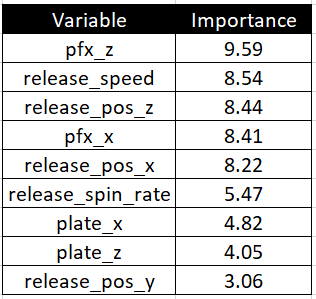
In plain language, these are the variables in order that are most important for the quality of Fastballs. Vertical movement being #1, velocity being #2, and extension being #3 should not be a surprise and definitely passes the smell test.
用通俗易懂的语言讲,这些是对快速球质量最重要的顺序变量。 垂直移动为#1,速度为#2,延伸为#3不足为奇,并且绝对可以通过气味测试。
For the Offspeed model, I followed a very similar procedure, subsetting down to a random 10% of Right vs Right Offspeed pitches for feature selection purposes. I used Boruta again with the same potential features, but this time also included the variables I created earlier: the velocity and movement differences between each pitch and the pitcher’s typical Fastball.
对于Offspeed模型,我遵循一个非常类似的过程,将子集随机分为10%的Right vs Right Offspeed音高,以用于功能选择。 我再次使用具有相同潜在特征的Boruta,但是这次还包含了我之前创建的变量:每个音高与投手的典型Fastball之间的速度和运动差异。
Boruta_OS <- Boruta(lin_weight ~ release_speed + release_pos_x + release_pos_y + release_pos_z + pfx_x + pfx_z + plate_x + plate_z + balls + strikes + outs_when_up + release_spin_rate + velo_diff + hmov_diff + vmov_diff, data = rr_os_data_sampled)print(Boruta_OS)Here are the results:
结果如下:
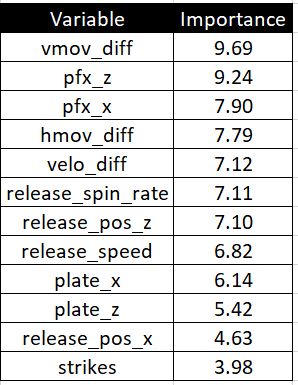
I have a decision to make. Keep the raw velocity and movement values or use those based off of a pitcher’s Fastball? This table shows that it does not really matter which one we chose as both sets of variables have very similar importance scores. For that reason, I am just going to use the variables containing raw values. Personal preference choice here but again, it shouldn’t impact the accuracy of the metric much at all compared to the alternative.
我有一个决定。 保持原始速度和运动值,还是使用基于投手Fastball的速度和运动值? 该表表明,选择哪一个变量并不重要,因为两组变量的重要性得分非常相似。 因此,我将使用包含原始值的变量。 这里的个人偏好选择,但再次重申,与其他选择相比,它根本不会对指标的准确性产生太大影响。
Also, even though Boruta found strikes to be significantly important, I am going to exclude this variable because it does not really make sense in our context neutral situation, in my opinion. So the final variables for the Offspeed equation are…
另外,即使Boruta发现罢工非常重要,但我还是要排除此变量,因为在我看来,在我们的中性背景下,它实际上没有意义。 因此,Offspeed方程的最终变量是…
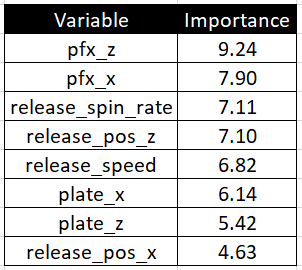
…the same as the variables in the Fastball equation with the exception of release extension. Nice that it worked out that way. Notice the difference in the order of variable importance though. Movement appears to be the most important feature of an Offspeed pitch by far, which again makes sense (especially since this mixes Changeups, Sliders, and Curveballs all together).
…除了发布扩展外,与Fastball方程中的变量相同。 很高兴以这种方式解决了。 请注意,尽管变量重要性顺序不同。 到目前为止,运动似乎是Offspeed音调最重要的功能,这又是有道理的(尤其是因为这将Changeups,Sliders和Curveballs混合在一起)。
模型验证与评估 (Model Validation and Evaluation)
As keen observers pointed out, I did absolutely no validation of my original pitch quality model, which is an issue! How did I know if it was good? I pretty much didn’t. I’m not making that mistake again! Looking back, the RMSE of my previous metric was 0.21. This is bad considering 0.21 was the standard deviation of the response column, linear weight. I am looking to improve upon that number with a smaller final RMSE with this new metric.
正如敏锐的观察者所指出的,我绝对没有验证我原来的音高质量模型,这是一个问题! 我怎么知道这是否好? 我几乎没有。 我不会再犯那个错误了! 回顾过去,我之前的指标的RMSE为0.21。 考虑到0.21是响应列的标准偏差(线性权重),这很糟糕。 我希望通过这项新指标来以较小的最终RMSE来改善这一数字。
To validate this metric, I used a methodology I had never used before which involved nesting of models within a dataframe to train and test all of my 16 models at once. I borrowed heavily from this StackOverflow post and my version of the code can be seen on my GitHub here.
为了验证该指标,我使用了以前从未使用过的方法,该方法涉及在数据框中嵌套模型以一次训练和测试所有16个模型。 我从这个StackOverflow帖子中大量借用了我的代码版本,可以在我的GitHub上看到 。
As is customary, I trained each model with 70% of the data and applied it to the other 30%, my test set.
按照惯例,我用70%的数据训练每个模型,并将其应用于其他30%的测试集。
Fastball Training and Validating
快球训练和验证
#Fastball Training and Validating
fbs_predictions <- fb_nested %>%
mutate(my_model = map(myorigdata, rf_model_fb))%>%
full_join(new_fb_nested, by = c("p_throws", "stand", "grouped_pitch_type"))%>%
mutate(my_new_pred = map2(my_model, mynewdata, predict))%>%
select(p_throws,stand,grouped_pitch_type, mynewdata, my_new_pred)%>%
unnest(c(mynewdata, my_new_pred))%>%
rename(preds = my_new_pred)rmse(fbs_predictions$preds, fbs_predictions$lin_weight)Offspeed Training and Validating
超速训练和验证
os_predictions <- os_nested %>%
mutate(my_model = map(myorigdata, rf_model_os))%>%
full_join(new_os_nested, by = c("p_throws", "stand", "grouped_pitch_type"))%>%
mutate(my_new_pred = map2(my_model, mynewdata, predict))%>%
select(p_throws,stand,grouped_pitch_type, mynewdata, my_new_pred)%>%
unnest(c(mynewdata, my_new_pred))%>%
rename(preds = my_new_pred)rmse(os_predictions$preds, os_predictions$lin_weight)My validation RMSE for the Fastball models was 0.105 and the validation RMSE for the Offspeed models was 0.099, which are both much better than I expected and a sign that this metric could be a real improvement over my previous metric in terms of accuracy and predictive power.
我对Fastball模型的验证RMSE为0.105,对于Offspeed模型的验证RMSE为0.099,均好于我的预期,这表明该指标在准确性和预测能力方面可能比我以前的指标有了真正的提高。
Knowing what we know about the model’s performance on the validation set, I feel comfortable applying these models to every pitch in 2020 so far. In doing this, I am giving every pitch in 2020 its expected run value.
知道我们对验证集上模型性能的了解后,我很高兴将这些模型应用到2020年为止的每个时机。 为此,我将为2020年的每个沥青提供预期的运行价值。
When I do this and combine the predictions, my final overall RMSE is 0.145, a massive improvement upon the 0.21 RMSE of my previous metric!
当我这样做并结合预测时,我的最终总RMSE为0.145,与之前指标的0.21 RMSE相比有了很大的提高!
I can confidently say that this model outperforms my previous pitch quality model in its quantification of the expected run values of MLB pitches.
我可以自信地说,在对MLB音高的预期运行值进行量化方面,该模型优于我以前的音高质量模型。
局限性 (Limitations)
I want to reiterate the purpose and capabilities of this model in order to shed some light on its flaws. As George Box’s saying goes, “all models are wrong, but some are useful.” This model assigns a value to each pitch in the 2020 MLB season based on the likelihood of outcomes for that pitch in a vacuum. Though it appears to do that fairly well, this metric does not account for
我想重申此模型的目的和功能,以便阐明其缺陷。 就像乔治·伯克(George Box)所说的那样,“所有模型都是错误的,但有些模型是有用的。” 该模型根据在真空中该球场产生结果的可能性,为2020 MLB赛季的每个球场分配一个值。 尽管看起来效果不错,但该指标并未说明
- Pitch sequencing, the effect of previous pitches on the current pitch 音高排序,先前音高对当前音高的影响
- Strengths and weaknesses of the opposing batter 对立面的优势和劣势
- Game situation (score, inning, pitch count) 比赛情况(得分,局数,投球数)
- At bat situation (count, baserunners, number of outs) 在蝙蝠的情况下(计数,跑垒员,出局次数)
As with any model, understanding the limitations and appropriate use cases is as important as understanding the mechanics of the model itself. Perhaps in future iterations some of these features could be integrated into the model and could potentially improve its performance.
与任何模型一样,理解限制和适当的用例与理解模型本身的机制同样重要。 也许在将来的迭代中,其中一些功能可能会集成到模型中,并可能改善其性能。
结果 (Results)
Unlike some of my past articles, which have included full breakdowns of the results of the previous pitch quality model, I am going to keep this section brief so that the focus will remain on the process of this metric’s creation and not argument about its final leaderboard.
与我过去的一些文章(其中包括以前的音高质量模型的结果的完整细目)不同,我将在本节中保持简短,以便将重点放在该指标的创建过程上,而不是对其最终排行榜的争论。
With that being said, here are a few interesting insights from the model. Keep in mind, all units on QOP are “expected runs prevented per 100 pitches” and that all leaderboards are accurate through games played on September 5th.
话虽如此,以下是该模型的一些有趣见解。 请记住,QOP上的所有单元都是“每100个步距可防止出现预期的奔跑”,并且所有排行榜在9月5日的比赛中都是准确的。
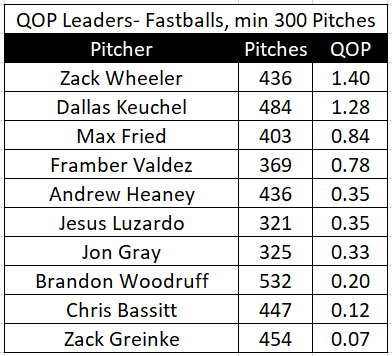
Fastball QOP Leaders so far in 2020
2020年迄今的快速球QOP领导者
Changeup QOP Leaders so far in 2020
2020年迄今的QOP领导者变更

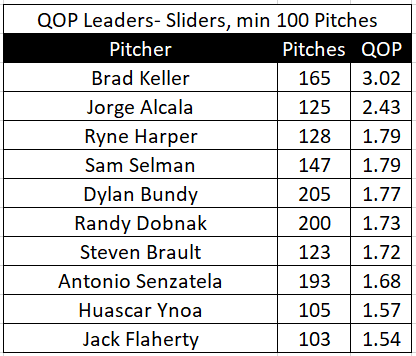
Slider QOP Leaders so far in 2020
2020年迄今的滑块QOP领导者
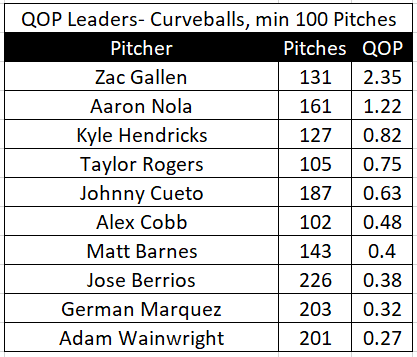
Curveball QOP Leaders so far in 2020
2020年至今的Curveball QOP领导者
Writing this up and making the code public was really important to me and kind of put a bookend on my very active summer of research. I hope someone will be able to take this and improve upon it in order to further the understanding of the game of baseball in the public sphere!
编写这些文件并使代码公开对我来说确实很重要,并且在我非常活跃的研究暑假上也颇有建树。 我希望有人能够接受并改进它,以便进一步了解公共领域的棒球比赛!
As always, thanks for reading and if you have any questions, feedback, or dream job offers 😅, please let me know on Twitter @Moore_Stats!
与往常一样,感谢您的阅读,如果您有任何疑问,反馈或理想的工作机会offers,请在Twitter @Moore_Stats上告诉我!
QOS +详细信息 (QOS+ Details)
Quality of Stuff+ (QOS+ for short) is very closely related to the metric outlined in this article, QOP. I collaborated on this metric with Eno Sarris of The Athletic for his biweekly Stuff & Command article.
Stuff +(简称QOS +)的质量与本文QOP中概述的度量标准密切相关。 我与The Athletic的Eno Sarris合作进行了这项指标评估,在他每两周的Stuff&Command文章中。
Here are the relevant differences between QOS+ and QOP:
以下是QOS +和QOP之间的相关区别:
- QOS+ does not include plate location as a feature in its Fastball or Offspeed model equations so as to isolate the effect of a pitcher’s “stuff” on the expected run values of his pitches QOS +在其Fastball或Offspeed模型方程式中不包括板位置作为功能,以便隔离投手的“材料”对其投球的预期游程值的影响
- QOS+ uses velocity and movement values relative to the pitcher’s typical Fastball in its Offspeed model QOS +在Offspeed模型中使用相对于投手典型Fastball的速度和运动值
- QOS+ is scaled differently than QOP with 100 being league average and 110 being one standard deviation better than league average QOS +与QOP的缩放比例不同,其中100为联盟平均值,而110为优于联盟平均值的一个标准差
The leaderboards of QOS+ and QOP are expected to be different with the QOS+ leaderboard giving more preference to pitchers with good “stuff” than QOP which also accounts for pitchers’ command.
预计QOS +和QOP的排行榜会有所不同,因为QOS +排行榜将优先考虑具有“东西”的投手,而不是QOP,QOP也是投手的命令。
翻译自: https://towardsdatascience.com/revamping-my-pitch-quality-metric-66cb2dbe8d8a
益盟指标修改















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









