





 探讨了在设备上进行AI和机器学习模型训练的前景,分析了算法、硬件和理论研究的最新进展,以及面临的挑战。文章强调了在资源受限环境下,设备级学习的重要性,以及为实现这一目标所需的创新。
探讨了在设备上进行AI和机器学习模型训练的前景,分析了算法、硬件和理论研究的最新进展,以及面临的挑战。文章强调了在资源受限环境下,设备级学习的重要性,以及为实现这一目标所需的创新。
神码ai人工智能写作机器人
A brief overview of the state-of-the-art in training ML models on devices. For a more comprehensive survey, read our full paper on this topic.
关于在设备上训练ML模型的最新技术的简要概述。 要进行更全面的调查,请阅读 有关此主题的完整论文 。
We are surrounded by smart devices: from mobile phones and watches to glasses, jewelry, and even clothes. But while these devices are small and powerful, they are merely the tip of a computing iceberg that starts at your fingertips and ends in giant data and compute centers across the world. Data is transmitted from devices to the cloud where it is used to train models that are then transmitted back to be deployed back on the device. Unless used for learning simple concepts like wake words or recognizing your face to unlock your phone, machine learning is computationally expensive and data has no choice but to travel these thousands of miles before it can be turned into useful information.
智能设备包围着我们 :从手机和手表到眼镜,珠宝,甚至衣服。 但是,尽管这些设备体积小巧,功能强大,但它们仅是计算冰山的一角,它触手可及,并遍布全球的巨型数据和计算中心。 数据从设备传输到云,在云中用于训练模型,然后将模型传输回去再部署回设备上。 除非用于学习诸如唤醒单词之类的简单概念或识别您的面部以解锁手机,否则机器学习在计算上是昂贵的,数据别无选择,只能经过数千英里才能转化为有用的信息。
This journey from device to data center and back to device has its drawbacks. The privacy and security of user data is probably the most obvious as this data needs to be transmitted to the cloud and stored there, most often, indefinitely. Transmission of user data is open to interference and capture, and stored data leaves open the possibility of unauthorized access. But there are other significant drawbacks. Cloud-based AI and ML models have higher latencies, cost more to implement, lack autonomy, and, depending on the frequency of model updates, are often less personalized.
从设备到数据中心再回到设备的过程有其缺点。 用户数据的隐私性和安全性可能是最明显的,因为该数据需要无限期地传输到云并存储在云中。 用户数据的传输容易受到干扰和捕获,存储的数据使未经授权的访问成为可能。 但是还有其他重大缺陷。 基于云的AI和ML模型具有更高的延迟,更高的实现成本,缺乏自治性,并且根据模型更新的频率,通常不那么个性化。
As devices become more powerful, it becomes possible to address the drawbacks of the cloud model by moving some or all of the model development onto the device itself. This transfer of model development on to the device is usually referred to as Edge Learning or On-device Learning. The biggest roadblock to doing Edge Learning is model training which is the most computationally expensive part of the model development process especially in the age of deep learning. Speeding up training is possible either by adding more resources to the device or using these resources more effectively or some combination of the two.
随着设备功能越来越强大,可以通过将部分或全部模型开发移至设备本身来解决云模型的缺点。 将模型开发转移到设备上的过程通常称为边缘学习或设备上学习。 进行边缘学习的最大障碍是模型训练,这是模型开发过程中计算上最昂贵的部分,尤其是在深度学习时代。 通过向设备添加更多资源或更有效地使用这些资源或两者的某种组合,可以加快培训速度。
This transfer of model development on to the device is usually referred to as Edge Learning or On-device Learning.
将模型开发转移到设备上的过程通常称为边缘学习或设备上学习。

Fig 1 gives a hierarchical view of the ways to improve model training on devices. On the left are the hardware approaches that work with the actual chipsets. Fundamental research in this area aims at improving existing chip design (by developing chips with more compute and memory, and lower power consumption and footprint) or developing new designs with novel architectures that speed up model training. While hardware research is a fruitful avenue for improving on-device learning, it is an expensive process that requires large capital expenditure to build laboratories and fabrication facilities, and usually involves long timescales for development.
图1给出了改进设备模型训练的方法的分层视图。 左侧是与实际芯片组配合使用的硬件方法。 该领域的基础研究旨在改进现有芯片设计(通过开发具有更多计算和内存以及更低功耗和占用空间的芯片)或开发具有新颖架构的新设计来加快模型训练的速度。 虽然硬件研究是改善设备上学习的有效途径,但它是一个昂贵的过程,需要大量资本支出来建立实验室和制造设施,并且通常涉及较长的开发时间。
Software approaches encompass a large part of current work in this field. Every machine learning algorithm depends on a small set of computing libraries for efficient execution of a few key operations (such as Multiply-Add in the case of neural networks). The libraries that support these operations are the interface between the hardware and the algorithms and allow for algorithm development that is not based on any specific hardware architecture. However, these libraries are heavily tuned to the unique aspects of the hardware on which the operations are executed. This dependency limits the amount of improvement that can be gained by new libraries. The algorithms part of software approaches gets the most attention when it comes to improving ML on the edge as it involves the development and improvement of the machine learning algorithms themselves.
软件方法涵盖了该领域当前的大部分工作。 每种机器学习算法都依赖于一小组计算库来有效执行一些关键操作(例如在神经网络的情况下为乘加)。 支持这些操作的库是硬件和算法之间的接口,并允许不基于任何特定硬件体系结构的算法开发。 但是,这些库在很大程度上针对执行操作的硬件的独特方面进行了调整。 这种依赖性限制了新库可以实现的改进量。 当涉及到边缘机器学习的改进时,软件方法的算法部分将引起最多的关注,因为它涉及机器学习算法本身的开发和改进。
Finally, theoretical approaches help direct new research on ML algorithms. These approaches improve our understanding of existing techniques and their generalizability to new problems, environments, and hardware.
最后,理论方法有助于指导有关ML算法的新研究。 这些方法提高了我们对现有技术的理解以及它们对新问题,环境和硬件的一般性。
This article focuses on developments in algorithms and theoretical approaches. While hardware and computing libraries are equally important, given the long lead times for novel hardware and the interdependency between hardware and libraries, the state-of-the-art changes faster in the algorithms and theoretical spaces.
本文重点介绍算法和理论方法的发展。 尽管硬件和计算库同等重要,但鉴于新型硬件的交货时间较长以及硬件和库之间的相互依赖关系,最新技术在算法和理论空间方面的变化更快。
演算法 (Algorithms)
Most of the work in on-device ML has been on deploying models. Deployment focuses on improving model size and inference speed using techniques like model quantization and model compression. For training models on devices, there needs to be advances in areas such as model optimization and Hyperparameter Optimization (HPO). But, advances in these fields improve accuracy and the rate of convergence, often at the expense of compute and memory usage. To improve model training on devices, it is important to have training techniques that are aware of the resource constraints under which these techniques will be run.
设备上ML的大部分工作都是在部署模型上进行的。 部署着重于使用模型量化和模型压缩等技术来提高模型大小和推理速度。 对于在设备上训练模型,需要在模型优化和超参数优化(HPO)等领域取得进步。 但是,这些领域的进步通常会以计算和内存使用为代价,提高准确性和收敛速度。 为了改善设备上的模型训练,重要的是要有训练技术,这些训练技术应知道将在这些资源下运行这些资源。
To improve model training on devices, it is important to have training techniques that are aware of the resource constraints under which these techniques will be run.
为了改善设备上的模型训练,重要的是要有训练技术,这些训练技术应知道将在这些资源下运行这些资源。
The mainstream approach to doing such resource-aware model training is to design ML algorithms that satisfy a surrogate software-centric resource constraint instead of a standard loss function. Such surrogate measures are designed to approximate the hardware constraints through asymptotic analysis, resource profiling, or resource modeling. For a given software-centric resource constraint, state-of-art algorithm designs adopt one of the following approaches:
进行这种资源感知模型训练的主流方法是设计满足替代软件中心资源约束而不是标准损失函数的ML算法。 此类替代措施旨在通过渐近分析,资源配置文件或资源建模来近似估计硬件约束。 对于给定的以软件为中心的资源约束,最新的算法设计采用以下方法之一:
Lightweight ML Algorithms — Existing algorithms, such as linear/logistic regression or SVMs, have low resource footprints and need no additional modifications for resource constrained model building. This low footprint makes these techniques an easy and obvious starting point for building resource-constrained learning models. However, in cases where the available device’s resources are smaller than the resource footprint of the selected lightweight algorithm, this approach will fail. Additionally, in many cases, lightweight ML algorithms result in models with low complexity that may fail to fully capture the underlying process resulting in underfitting and poor performance.
轻量级ML算法 -现有的算法(例如线性/逻辑回归或SVM)具有较低的资源占用量,并且无需进行其他修改即可构建资源受限的模型。 这种低占用空间使这些技术成为构建资源受限的学习模型的简单而明显的起点。 但是,如果可用设备的资源小于所选轻量算法的资源占用量,则此方法将失败。 此外,在许多情况下,轻量级ML算法导致模型的复杂度较低,可能无法完全捕获基础过程,从而导致拟合不足和性能不佳。
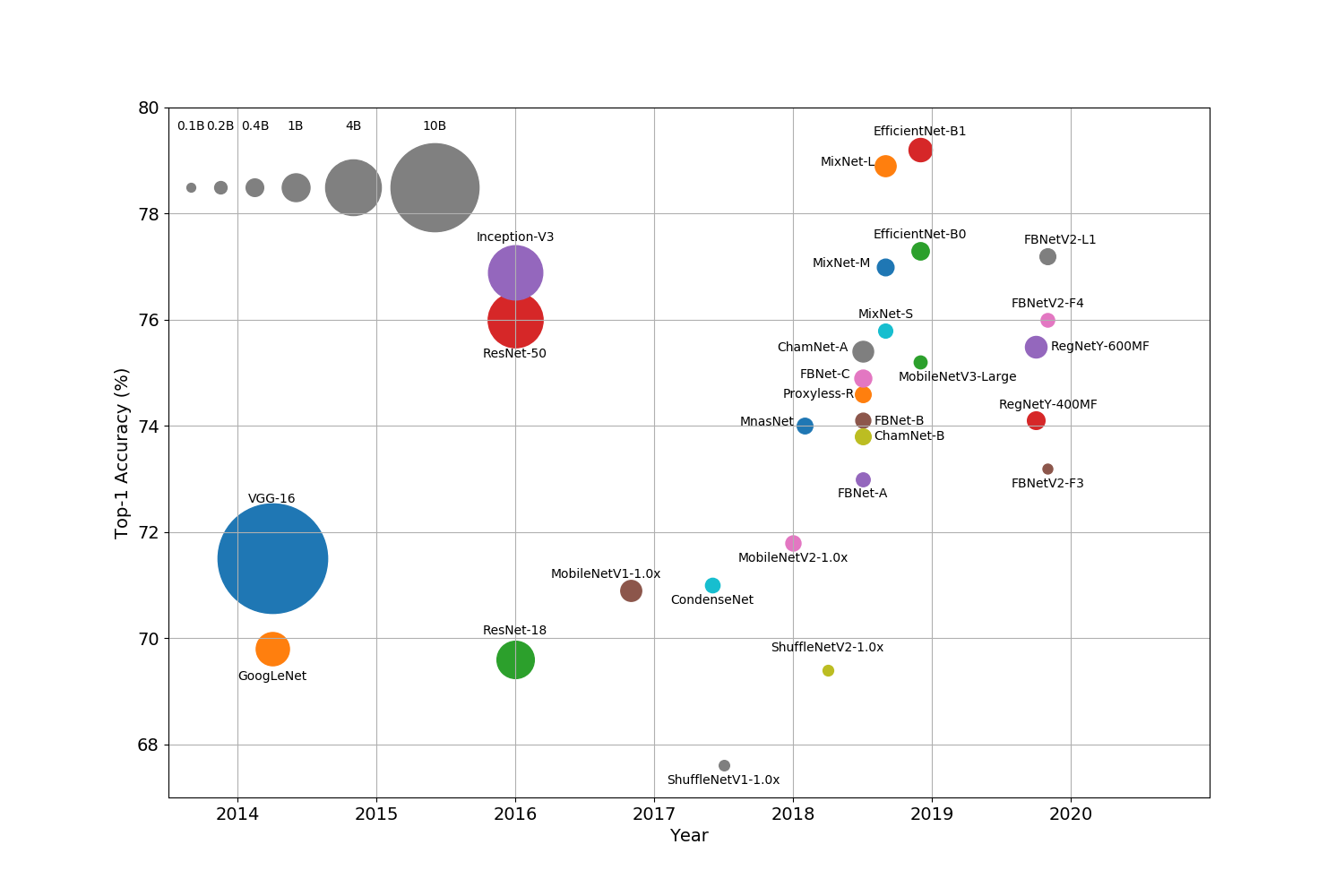
Reducing Model complexity — A better approach to control the size (memory footprint) and computation complexity of the learning algorithm is by constraining the model architecture (for e.g. by selecting a smaller hypothesis class). This approach has the added advantage that these models can be trained using traditional optimization routines. Apart from model building, this is one of the dominant approaches for deploying resource efficient models for model inference. Most importantly, this approach extends to even Deep Neural Networks (DNNs) where, as evidenced by Fig 2, there has been a slow but steady progression towards smaller, faster, leaner architectures. This progression has been helped by the increased use of Neural Architecture Search (NAS) techniques that show a preference for smaller, more efficient networks. Compared to the lightweight ML algorithms approach, model complexity reduction techniques can accommodate a broader class of ML algorithms and can more effectively capture the underlying process.
降低模型复杂度 —控制学习算法的大小(内存占用)和计算复杂度的更好方法是约束模型架构(例如,通过选择较小的假设类别)。 这种方法的另一个优点是可以使用传统的优化例程来训练这些模型。 除模型构建外,这是为模型推理部署资源高效模型的主要方法之一。 最重要的是,这种方法甚至扩展到了深度神经网络(DNN),如图2所示,在向更小,更快,更精简的架构发展的过程中,进展缓慢但稳定。 越来越多地使用神经体系结构搜索(NAS)技术帮助实现了这一进步,这些技术显示出对更小,更高效的网络的偏爱。 与轻量级ML算法相比,模型复杂度降低技术可以容纳更多种类的ML算法,并且可以更有效地捕获底层过程。
Modifying optimization routines — The most significant of the algorithmic advances is the design of optimization routines specifically for resource-efficient model building where resource constraints are incorporated during the model building (training) phase. Instead of limiting the model architectures beforehand, these approaches can adapt optimization routines to fit the resource constraints for any given model architecture (hypothesis class).
修改优化例程 -最先进的算法是专门针对资源效率较高的模型构建的优化例程的设计,在模型构建(训练)阶段将资源约束纳入其中。 这些方法可以预先使用优化例程以适应任何给定模型体系结构(假设类)的资源约束,而不是预先限制模型体系结构。
Resource-constrained model-centric optimization routines focus on improving the performance of models that will be quantized after training either through stochastic rounding, weight initialization, or by introducing quantization error into gradient updates. Also prevalent are layer-wise training and techniques that trade computation for memory, both of which try to reduce the computational requirements associated with training DNNs. In certain cases, this approach can also dynamically modify the architecture to fit the resource constraints. Although this approach provides a wider choice of the class of models, the design process is still tied to a specific problem type (classification, regression, etc.) and depends on the selected method/loss function (linear regression, ridge regression for regression problems).
资源受限的以模型为中心的优化例程着重于提高模型的性能,这些模型将在训练后通过随机舍入,权重初始化或将量化误差引入梯度更新来进行量化。 分层训练和以内存换取计算的技术也很普遍,它们都试图减少与训练DNN相关的计算要求。 在某些情况下,此方法还可以动态修改体系结构以适应资源限制。 尽管此方法提供了更多的模型类别选择,但设计过程仍与特定的问题类型(分类,回归等)相关,并且取决于所选的方法/损失函数(线性回归,针对回归问题的岭回归) )。
Resource-constrained generic optimization routines such as Buckwild! And SWALP focuses on reducing the resource-footprint for model training by using low-precision arithmetic for gradient computations. An alternative line of work involves implementing fixed point Quadratic Programs (QP) such as QSGD or QSVRG for solving linear Model Predictive Control (MPC). Most of these algorithms involve modifying fast gradient methods for convex optimization to obtain a suboptimal solution in a finite number of iterations under resource-constrained settings .
资源受限的通用优化例程,例如Buckwild !! SWALP致力于通过使用低精度算术进行梯度计算来减少模型训练的资源占用。 另一种工作方式是实施定点二次程序(QP),例如QSGD或QSVRG,以解决线性模型预测控制(MPC)。 这些算法大多数都涉及修改快速梯度方法以进行凸优化,以在资源受限的设置下以有限次数的迭代获得次优解。
Data Compression — Rather than constraining the model size/complexity, data compression approaches target building models on compressed data. The goal is to limit the memory usage via reduced data storage and computation through fixed per-sample computation cost. A more generic approach includes adopting advanced learning settings that accommodates algorithms with smaller sample complexity. However, this is a broader research topic and is not just limited to on-device learning.
数据压缩 - 数据压缩不是限制模型的大小/复杂性,而是针对压缩数据构建目标模型。 目的是通过减少数据存储和通过固定的每样本计算成本进行计算来限制内存使用。 更为通用的方法包括采用高级学习设置,以适应样本复杂度较小的算法。 但是,这是一个更广泛的研究主题,而不仅限于设备上的学习。
New protocols for data observation — Finally, completely novel approaches are possible that completely change the traditional data observation protocol (like the availability of i.i.d data in batch or online settings). These approaches are guided by an underlying resource-constrained learning theory which captures the interplay between resource constraints and the goodness of the model in terms of the generalization capacity. Compared to the above approaches, this framework provides a generic mechanism to design resource-constrained algorithms for a wider range of learning problems applicable to any method/loss function targeting that problem type.
数据观察的新协议 —最后,完全新颖的方法可能会彻底改变传统的数据观察协议(例如,批量或在线设置中的iid数据的可用性)。 这些方法以一种潜在的资源受限学习理论为指导,该理论从泛化能力的角度捕获了资源约束与模型优度之间的相互作用。 与上述方法相比,此框架提供了一种通用机制来设计资源受限算法,用于更广泛的学习问题,适用于针对该问题类型的任何方法/损失函数。
ChallengesThe major challenge in algorithms research is proper software-centric characterization of the hardware constraints and the appropriate use of this characterization for better metric designs. If hardware dependencies are not properly abstracted away, the same model and algorithm can have very different performance profiles on different hardware. While novel loss functions can take such dependencies into account, it is still a relatively new field of study. The assumption in many cases is that the resource budget available for training does not change but that is usually never the case. Our everyday devices are often multi-tasking — checking emails, social media, messaging people, playing videos… the list goes on. Each of these apps and services are constantly vying for resources at any given moment in time. Taking this changing resource landscape into account is an important challenge for effective model training on the edge.
挑战算法研究中的主要挑战是对硬件约束进行正确的以软件为中心的表征,以及为更好的度量设计而适当使用此表征。 如果没有正确抽象出硬件依赖关系,则相同的模型和算法在不同的硬件上可能具有非常不同的性能。 尽管新颖的损失函数可以考虑这种依赖性,但它仍然是一个相对较新的研究领域。 许多情况下的假设是,可用于培训的资源预算不会改变,但通常永远不会改变。 我们的日常设备通常是多任务处理的-检查电子邮件,社交媒体,消息传递者,播放视频...等等。 这些应用程序和服务中的每一个都在任何给定的时间不断争夺资源。 考虑到这种不断变化的资源格局,这是在边缘进行有效模型训练的重要挑战。
Finally, improved methods for model profiling are needed to more accurately calculate an algorithm’s resource consumption. Current approaches to such measurements are abstract and focus on applying software engineering principles such as asymptotic analysis or low-level measures like FLOPS or MACs (Multiply-Add Computations). None of these approaches give a holistic idea of resource requirements and in many cases represent an insignificant portion of the total resources required by the system during learning.
最后,需要用于模型分析的改进方法来更准确地计算算法的资源消耗。 当前进行此类测量的方法是抽象的,并且侧重于应用软件工程原理,例如渐近分析或诸如FLOPS或MAC(乘加计算)的低级测量。 这些方法都没有一个全面的资源需求概念,并且在许多情况下,它们在学习过程中只占系统所需总资源的很小一部分。
理论 (Theory)
Every learning algorithm is based on an underlying theory that guarantees certain aspects of its performance. Research in this area focuses mainly on Learnability — the development of frameworks to analyze the statistical aspects (i.e. error guarantees) of algorithms. While traditional machine learning theories underlie most current approaches, developing newer notions of learnability that include resource constraints will help us better understand and predict how algorithms will perform under resource-constrained settings. There are two broad categories of theories into which most of the existing resource-constrained algorithms can be divided
每种学习算法均基于保证其性能某些方面的基础理论。 该领域的研究主要集中在可学习性上 —开发用于分析算法统计方面(即错误保证)的框架。 尽管传统的机器学习理论是大多数当前方法的基础,但发展包括资源约束在内的更新的可学习性概念将有助于我们更好地理解和预测算法在资源受限的环境下的性能。 有两大类理论可将大多数现有的资源受限算法分为
Traditional Learning Theories — Most existing resource-constrained algorithms are designed following traditional machine learning theory (like PAC Learning Theory, Mistake Bounds, Statistical Query). A limitation of this approach is that such theories are built mainly for analyzing the error guarantees of the algorithm used for model estimation. The effect of resource constraints on the generalization capability of the algorithm is not directly addressed through such theories. For example, algorithms developed using the approach of reducing the model complexity typically adopts a two-step approach. First, the size of the hypothesis class is constrained beforehand to those that use fewer resources. Next, an algorithm is designed guaranteeing the best-in-class model within that hypothesis class. What is missing in such frameworks is the direct interplay between the error guarantees and the resource constraints.
传统学习理论 -大多数现有资源受限的算法都是按照传统的机器学习理论(如PAC学习理论,误区,统计查询)设计的。 这种方法的局限性在于,建立这种理论主要是为了分析用于模型估计的算法的误差保证。 通过这种理论不能直接解决资源约束对算法泛化能力的影响。 例如,使用降低模型复杂度的方法开发的算法通常采用两步法。 首先,假设类的大小事先限制为使用较少资源的类。 接下来,设计一种算法,以确保该假设类别内的同类最佳模型。 这种框架中缺少的是错误保证和资源约束之间的直接相互作用。
Resource-constrained learning theories — Newer learning theories try to overcome the drawbacks of traditional theories especially since new research has shown that it may be impossible to learn a hypothesis class under resource constrained settings. Most of the algorithms from earlier that assume new protocols for data observation fall in this category of resource-constrained theories. Typically, such approaches modify the traditional assumption of i.i.d data being presented in a batch or streaming fashion and introduces a specific protocol of data observability that limits the memory/space footprint used by the approach. These theories provide a platform to utilize existing computationally efficient algorithms under memory-constrained settings to build machine learning models with strong error guarantees. Prominent resource-constrained learning theories include Restricted Focus of Attention (RFA), newer Statistical Query (SQ) based learning paradigms, and graph-based approaches that model the hypothesis class as a hypothesis graph. Branching programs translate the learning algorithm under resource constraints (memory) in the form of a matrix (as opposed to a graph) where there is a connection between the stability of the matrix norm (in the form of an upper bound on its maximum singular value) and the learnability of the hypothesis class with limited memory. Although such theory-motivated design provides a generic framework through which algorithms can be designed for a wide range of learning problems, to date, very few algorithms based on these theories have been developed.
资源受限的学习理论 -较新的学习理论试图克服传统理论的弊端,特别是因为新的研究表明,在资源受限的环境下学习假设类是不可能的。 早先的大多数假设使用新协议进行数据观察的算法都属于这种资源受限的理论。 通常,此类方法修改了以批量或流方式呈现iid数据的传统假设,并引入了数据可观察性的特定协议,该协议限制了该方法使用的内存/空间占用量。 这些理论提供了一个平台,可以在内存受限的设置下利用现有的高效计算算法来构建具有强大错误保证的机器学习模型。 突出的资源受限学习理论包括限制注意力集中(RFA),更新的基于统计查询(SQ)的学习范例,以及将假设类别建模为假设图的基于图的方法。 分支程序在资源约束(内存)下以矩阵(而不是图)的形式转换学习算法,其中矩阵范数的稳定性(以其最大奇异值的上限形式)之间存在联系)和假设类的可记忆性有限。 尽管这种基于理论的设计提供了一个通用的框架,通过该框架可以针对各种学习问题设计算法,但迄今为止,基于这些理论的算法很少。
ChallengesPerhaps the biggest drawback to theoretical research is that while it is flexible enough to apply across classes of algorithms and hardware systems, it is limited due to the inherent difficulty of such research and the need to implement a theory in the form of an algorithm before its utility can be realized.
挑战理论研究的最大缺点可能是,尽管它具有足够的灵活性以适用于各种算法和硬件系统,但由于这种研究的固有困难以及需要以算法的形式实现理论而受到限制。它的效用可以实现。
结论 (Conclusion)
A future full of smart devices was the stuff of science fiction when we slipped the first iPhones into our pockets. Thirteen years later, devices have become much more capable and now promise the power of AI and ML right at our fingertips. However, these new-found capabilities are a facade propped up by massive computational resources (data centers, compute clusters, 4G/5G networks etc) that bring AI and ML to life. But devices can only be truly powerful on their own when it is possible to sever the lifeline that extends between them and the cloud. And that requires the ability to train machine learning models on these devices rather than in the cloud.
当我们将第一批iPhone放入口袋时,科幻小说充满了未来的智能设备。 十三年后,设备变得更加强大,现在可以在指尖获得AI和ML的强大功能。 但是,这些新发现的功能是使AI和ML栩栩如生的大量计算资源(数据中心,计算集群,4G / 5G网络等)支撑的立面。 但是,只有在可以切断在设备与云之间延伸的生命线的情况下,设备才能真正发挥真正的强大功能。 这就要求能够在这些设备上而不是在云中训练机器学习模型。
Training ML models on a device has so far remained an academic pursuit, but with the increasing number of smart devices and improved hardware, there is interest in performing learning on the device itself. In the industry, this interest is fueled mainly by hardware manufacturers promoting AI-specific chipsets that are optimized for certain mathematical operations, and startups providing ad hoc solutions to certain niche domains mostly in computer vision and IoT. From an AI/ML perspective, most of the activity lies in two areas — the development of algorithms that can train models under resource constraints and the development of theoretical frameworks that provide guarantees about the performance of such algorithms.
迄今为止,在设备上训练ML模型仍是一项学术追求,但是随着智能设备和硬件的改进,人们对在设备上进行学习感兴趣。 在行业中,这种兴趣主要是由硬件制造商推动的,这些制造商推广了针对特定数学运算进行了优化的AI专用芯片组,并且初创公司主要在计算机视觉和IoT中为某些特定领域提供了临时解决方案。 从AI / ML的角度来看,大多数活动都在两个领域中:可以在资源约束下训练模型的算法的开发以及为此类算法的性能提供保证的理论框架的开发。
At the algorithmic level, it is clear that current efforts are mainly targeted at either utilizing already lightweight machine learning algorithms or modifying existing algorithms in ways that reduce resource utilization. There are a number of challenges before we can consistently train models on the edge including the need for decoupling algorithms from the hardware, and designing effective loss functions and metrics that capture resource constraints. Also important are an expanded focus on traditional as well as advanced ML algorithms with low sample complexity and dealing with situations where the resource budget is dynamic rather than static. Finally, the availability of an easy and reliable way to profile algorithm behavior under resource constraints will speed up the entire development process.
在算法级别,很明显,当前的工作主要针对利用已经很轻量级的机器学习算法或以减少资源利用的方式修改现有算法。 在我们不断地在边缘训练模型之前,存在许多挑战,包括需要将算法与硬件解耦,以及设计有效的损失函数和指标以捕获资源约束的需求。 同样重要的是,应进一步关注具有低样本复杂度的传统以及高级ML算法,并应对资源预算是动态而非静态的情况。 最后,在资源限制下提供一种简单可靠的方法来描述算法行为的方法将加速整个开发过程。
Learning theory for resource-constrained algorithms is focused on the un-learnability of an algorithm under resource constraints. The natural step forward is to identify techniques that can instead provide guarantees on the learnability of an algorithm and the associated estimation error. Existing theoretical techniques also mainly focus on the space(memory) complexity of these algorithms and not their compute requirements. Even in cases where an ideal hypothesis class can be identified that satisfies resource constraints, further work is needed to select the optimal model from within that class.
资源受限算法的学习理论集中于资源约束下算法的不可学习性。 向前迈出的自然步伐是确定可以替代地为算法的可学习性和相关的估计误差提供保证的技术。 现有的理论技术也主要集中在这些算法的空间(存储器)复杂度上,而不是它们的计算要求上。 即使在可以确定满足资源约束的理想假设类别的情况下,也需要进一步的工作以从该类别中选择最佳模型。
Despite these difficulties, the future for machine learning on the edge is exciting. Model sizes, even for deep neural networks, have been trending down. Major platforms such as Apple’s Core/CreateML support the retraining of models on the device. While the complexity and training regimen of models continue to grow, it is within the realm of possibility that we will continue to see a push to offload computation from the cloud to the device for reasons of privacy and security, cost, latency, autonomy, and better personalization.
尽管存在这些困难,但是边缘机器学习的未来还是令人兴奋的。 甚至对于深度神经网络,模型的大小一直在下降。 苹果的Core / CreateML等主要平台支持对设备上的模型进行再培训。 尽管模型的复杂性和训练方案不断增长,但出于隐私和安全性,成本,延迟,自治性和安全性的考虑,我们将继续看到将计算从云上卸载到设备的可能性。更好的个性化。
This article was written with contributions from Sauptik Dhar, Junyao Guo, Samarth Tripathi, Jason Liu, Vera Serdiukova, and Mohak Shah.
本文是由Sauptik Dhar,Guunyao Guo,Samarth Tripathi,Jason Liu,Vera Serdiukova和Mohak Shah撰写的。
If you are interested in a more comprehensive survey of edge learning, read our full paper on this topic.
如果您对边缘学习的更全面的研究感兴趣,请阅读我们 关于该主题的全文 。
神码ai人工智能写作机器人


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









