





Recently, at Twelve Data we needed to implement a search by the beginning of the string, in fact, WHERE name LIKE 'beginning%'. This was a search by the name of stock symbols (AAPL, AMZN, EUR/USD, etc.). We wanted the search to work quickly and without loading the database too much. As a result, I came to implement a search tree in memory, and now I will tell you about it.
最近,在Twelve Data中,我们需要在字符串的开头(实际上是WHERE name LIKE 'beginning%' 。 这是按股票代码(AAPL,AMZN,EUR / USD等)的名称进行的搜索。 我们希望搜索能够快速进行,而又不会加载太多数据库。 结果,我开始在内存中实现搜索树,现在我将告诉您。
In our case, the search is performed on about 55,000 short strings (stock symbols). So, the index based on this data is completely stored in RAM without any problems. It is just needed to create it tidily so that you can quickly find the data on the request.
在我们的例子中,搜索是在大约55,000个短字符串(股票代码)上执行的。 因此,基于此数据的索引完全存储在RAM中,没有任何问题。 仅需要整齐地创建它,以便您可以快速找到请求中的数据。
The search implementation is described below. I will immediately note that this is not a balanced BTree tree, but a suffix trie, where at each level — is the next character of the string. The implementation of this tree variant is very simple and quite effective for many tasks when you need to index non-long strings.
搜索实现如下所述。 我将立即注意到,这不是平衡的BTree树,而是后缀trie,在每个级别上-是字符串的下一个字符。 当您需要索引非长字符串时,此树变体的实现非常简单,并且对于许多任务而言非常有效。
In this article, I tried to describe the search algorithm without code examples. I’ll give you a link to the code at the end of the article. I’ve issued the code in a separate ready-to-use package.
在本文中,我试图描述没有代码示例的搜索算法。 在文章结尾,我将为您提供代码链接。 我已经在单独的即用型包装中发布了代码。
树状结构 (Tree structure)
In each element of the tree, we store child elements as a sorted hash table and the node value as a list.
在树的每个元素中,我们将子元素存储为已排序的哈希表,并将节点值存储为列表。
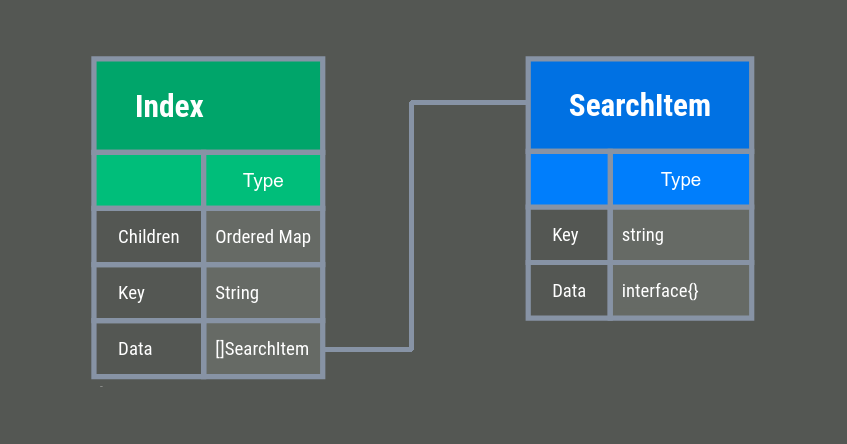
The node value is stored as a list so that it is easier to handle cases when different data with the same key may occur in the desired values. In our case, these are, for example, ticker symbols in different markets:
节点值存储为列表,因此,当具有相同键的不同数据可能出现在所需值中时,将更易于处理。 在我们的例子中,这些是例如不同市场中的股票代码:
- AAA (BetaShares Australian High Interest Cash ETF, ASX), AAA(BetaShares澳大利亚高息现金ETF,ASX),
- AAA (All Active Asset Capital LTD, LSE). AAA(All Active Asset Capital LTD,LSE)。
Then we’ll write it in Index.Data one record, inside which in Index.Data will be a list of two AAA stock symbols.
然后,将其写入Index.Data一条记录中,其中在Index.Data中将是两个AAA股票代码的列表。
In SearchIndex.Data we can store data of any structure. This way, it is possible to index any data by a string key.
在SearchIndex.Data中,我们可以存储任何结构的数据。 这样,可以通过字符串键索引任何数据。
建立搜寻树 (Building a search tree)
The tree must be built once, and then you can search by this ready-made index.
该树必须构建一次,然后您才能通过该现成索引进行搜索。
Before building a tree, keys are pre-processed as follows.
在构建树之前,对密钥进行如下预处理。
- All separators are replaced with spaces. 所有分隔符都用空格替换。
- Double spaces are replaced with single spaces. 双空格替换为单空格。
- Whitespaces are trimmed at the edges of the lines. 在线条的边缘修剪空白。
- Strings are converted to lowercase. 字符串将转换为小写。
Similar characters are transformed to a single format, for example, ã → a.
相似字符将转换为单一格式,例如ã → a。
- Stop words are excluded (optional). 停用词被排除(可选)。
After that, the data is sorted, by default — by key in ascending order, in alphabetical order.
此后,默认情况下将对数据进行排序-按键以升序,字母顺序进行排序。
Then the sorted data is grouped by key to put the ready list in Index.Data.
然后,将已排序的数据按键分组以将就绪列表放入Index.Data。
Now we are ready to add data to the index. Our task now is to create an Index.Children so that at each level of the tree there is the next key piece (in our case, the key piece is a character of the indexed string). For example, if we add the AAPL to the index, we will form a tree structure like this (red line):
现在我们准备将数据添加到索引。 现在,我们的任务是创建一个Index.Children,以便在树的每个级别上都有下一个键(在本例中,键是索引字符串的一个字符)。 例如,如果我们将AAPL添加到索引,我们将形成一个像这样的树结构(红线):
Here on the red line are located on each vertex of the tree elements [A], [A], [P], [L]. Square brackets indicate the keys that are used at each vertex for indexing. Complete keys that are obtained when passing from the root to the vertex are indicated without brackets.
在这里,红线上位于树元素[A],[A],[P],[L]的每个顶点上。 方括号表示每个顶点用于索引的键。 从根传递到顶点时获得的完整关键点不带括号。
Since we form a tree, it is convenient to add to the index recursively. We add intermediate nodes if there are none. And we add the value that we index into the tree leaf.
由于我们形成一棵树,因此方便地递归添加到索引。 如果没有中间节点,则添加中间节点。 然后,我们将索引的值添加到树叶中。
In the same way, we add all the values to the index sequentially.
同样,我们将所有值顺序添加到索引中。
按树搜索 (Search by tree)
When the tree is already built, it is a fairly simple task to search through it. To do this, we follow three steps.
当树已经被构建时,搜索它是一个相当简单的任务。 为此,我们遵循三个步骤。
- Preprocess the search string using the same algorithm that processed the keys before indexing (see above). 使用在索引之前处理键的相同算法对搜索字符串进行预处理(请参见上文)。
- Find an element in the tree where the key matches the string we are looking for. 在树中找到一个与键匹配的元素。
- Then we get the desired result by iterating through the child vertexes. 然后我们通过遍历子顶点获得所需的结果。
For example, if we enter AA in the search, we expect to get such strings in this sequence for the tree described above:
例如,如果我们在搜索中输入AA,则我们期望按上述顺序为上述树获得这样的字符串:
- АА АА
- ААА ААА
- АAAL АAAL
- AAALF 美国空军
- AAAP 美国AAAP
- AAB AAB
- AAP 行动计划
- AAPJ 亚太地区
- AAPL AAPL
- AAPT AAPT
To get this result, in the first step of the search, we move to the vertex AA. In the second step, we iterate through all the child vertexes from left to right from top to bottom.
为了获得此结果,在搜索的第一步中,我们移至顶点AA。 在第二步中,我们从上到下从左到右迭代所有子顶点。
搜索合适的股票代码 (Search for a suitable stock symbol)
The above algorithm is well suited for searching like WHERE name LIKE 'start%'. To make it convenient to search for a suitable symbol in the financial markets, this was not enough and had to take into account the following points.
上面的算法非常适合搜索WHERE name LIKE 'start%' 。 为了方便在金融市场中寻找合适的符号,这还不够,必须考虑以下几点。
- If you enter “EUR” in the search, the output must be “EUR”, “EUR/USD”, “USD/EUR”. In other words, the search should work not only from the beginning of the string but also from the beginning of each word in the string. 如果在搜索中输入“ EUR”,则输出必须为“ EUR”,“ EUR / USD”,“ USD / EUR”。 换句话说,搜索不仅应从字符串的开头开始,而且还应从字符串中每个单词的开头开始。
- The search should work not only by the stock symbol name but also by the company name. For example, if we enter “APL” in the search, we should output “APL” or “AAPL” (Apple) in the results. 搜索不仅应通过股票代号名称进行,而且应通过公司名称进行。 例如,如果在搜索中输入“ APL”,则应在结果中输出“ APL”或“ AAPL”(苹果)。
- Display popular ticker symbols at the top of the list. 在列表顶部显示流行的股票代码。
So when entering ”EUR“ to get not only ”EUR“, ”EUR/USD“, but also ”USD/EUR“, we decided to put several instances of data with different keys in the index: substrings starting from each word of the indexed string. For example, when indexing the string “USD/EUR”, the following keys are included in the index: “usd eur”, “eur”. When indexing the string “Grupo Financiero Galicia SA“, the keys ”Grupo Financiero Galicia SA“, ”Financiero Galicia SA“, ”Galicia SA“, ”SA” fall into the index.
因此,当输入“ EUR”以获取不仅“ EUR”,“ EUR / USD”而且还获得“ USD / EUR”时,我们决定将几个具有不同键的数据实例放入索引:从字符串的每个单词开始的子字符串索引字符串。 例如,在为字符串“ USD / EUR”建立索引时,索引中包含以下键:“ usd eur”,“ eur”。 在对字符串“ Grupo Financiero Galicia SA”进行索引时,键“ Grupo Financiero Galicia SA”,“ Financiero Galicia SA”,“ Galicia SA”,“ SA”将落入索引。
Also, to take into account the above nuances, it was necessary to perform a search in 4 stages.
此外,考虑到上述细微差别,有必要分四个阶段进行搜索。
- Search for ticker symbols by the exact match with the search string. 通过与搜索字符串完全匹配的方式搜索股票代号。
- Finding and adding to the results the most popular stock symbols that have the beginning of the string that matches the string entered for the search. 查找最流行的股票代码并将其添加到结果中,这些股票代码的字符串开头与为搜索输入的字符串匹配。
- Search for ticker symbols by company name, adding results to the ones above. 按公司名称搜索代码,将结果添加到上面的结果中。
- Search for ticker symbols that match the search string that have the beginning of the string that matches the string entered for the search, and add these results to the final list. 搜索与搜索字符串匹配的代码符号,该符号的字符串开头与为搜索输入的字符串匹配,并将这些结果添加到最终列表中。
To get the desired result, we managed to use the index described in the previous sections. To do this, we created three indexes.
为了获得理想的结果,我们设法使用了前面几节中描述的索引。 为此,我们创建了三个索引。
SearchSymbolIndex— index for the stock symbols from all of the financial markets.SearchSymbolIndex—来自所有金融市场的股票SearchSymbolIndex索引。SearchPopularIndex— index only for popular ticker symbols (10% of all).SearchPopularIndex—仅索引流行的股票代码(占全部股票代码的10%)。SearchInstrumentindex— index by company name.SearchInstrumentindex—按公司名称的索引。
Next, just a sequential search for each index with a small difference in the criteria.
接下来,仅对每个索引进行顺序搜索,但条件稍有不同。
var searchedData []searchindex.SearchData
searchedData = r.SearchSymbolIndex.Search(searchindex.SearchParams{
Text: key,
OutputSize: outputSize,
Matching: searchindex.Strict,
})
searchedData = r.SearchPopularIndex.Search(searchindex.SearchParams{
Text: key,
OutputSize: outputSize,
Matching: searchsymbol.Strict,
StartValues: searchedData,
})
searchedData = r.SearchSymbolIndex.Search(searchindex.SearchParams{
Text: key,
OutputSize: outputSize,
Matching: searchindex.Beginning,
StartValues: searchedData,
})
searchedData = r.SearchInstrumentIndex.Search(searchindex.SearchParams{
Text: key,
OutputSize: outputSize,
Matching: searchindex.Beginning,
StartValues: searchedData,
})StartValues — are values found at the previous stage, they are passed to the next stage of the search, so that duplicates are not added to the output, and unnecessary search iterations are not performed, if enough data has already been collected (OutputSize).
StartValues —是在上一阶段找到的值,它们被传递到搜索的下一阶段,因此,如果已经收集了足够的数据, OutputSize重复项添加到输出中,并且不会执行不必要的搜索迭代( OutputSize )。
searchindex.Strict — search for exact matches.
searchindex.Strict搜索完全匹配。
searchindex.Beginning — search for matches at the beginning of a string.
searchindex.Beginning在字符串开头搜索匹配项。
摘要 (Summary)
As a result, we have a compact implementation of a quick search by strings in RAM. The code currently takes up less than 300 lines. Moreover, the implementation of the index turned out to be quite universal, so that it can be used for implementing various similar tasks.
结果,我们可以通过RAM中的字符串进行快速搜索的紧凑实现。 该代码当前占用不到300行。 而且,该索引的实现被证明是非常通用的,因此可以用于执行各种相似的任务。
I didn’t make large performance benchmarks, but on my data of 55,000 rows, creating three indexes takes about 2 seconds, this is taking into account the selection from the database and additional actions. A search in 4 consecutive iterations in three indexes is performed in 100–200 nanoseconds (this is if you exclude the time to process the http request and count only the search time), which is more than enough for my task.
我没有制定大型性能基准,但是在我的55,000行数据上,创建三个索引大约需要2秒钟,这要考虑到从数据库中选择的内容和其他操作。 在100-200纳秒内执行三个索引中的4个连续迭代的搜索(这是如果您排除处理http请求的时间并且仅计算搜索时间),这对于我的任务已经足够了。
Code as a ready-made package: https://github.com/twelvedata/searchindex
将代码作为现成的软件包: https : //github.com/twelvedata/searchindex
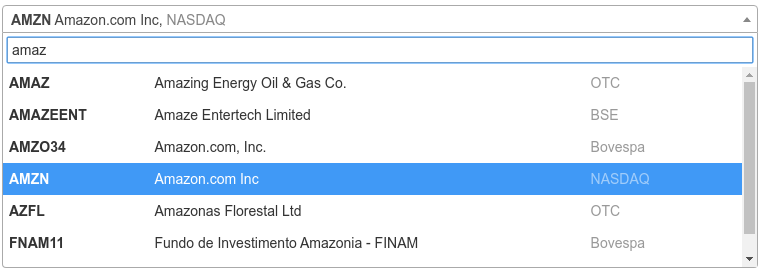
This search is currently used in the Twelve Data API for developers, an example can be found on this page, where you can try it live.
该搜索当前在开发人员专用的十二数据 API中使用,可以在此页面上找到示例,在此处可以进行尝试。
翻译自: https://medium.com/twelve-data/in-memory-text-search-index-for-quotes-on-go-5243adc62c26















 3968
3968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









