





初学者linux系统推荐
Why do we need a recommendation system ?
为什么我们需要一个推荐系统?
Let us take the simplest and the most relatable example of E-commerce giant Amazon. When we shop at Amazon it usually gives us the options of bundles and products that are bought along with the product you are currently going to buy. For example, if you are to buy a smartphone it recommends you to buy a back cover for the product as well.
让我们以电子商务巨头亚马逊的最简单,最相关的例子为例。 当我们在亚马逊上购物时,通常会向我们提供捆绑包和购买产品以及您当前要购买的产品的选项。 例如,如果您要购买智能手机,建议您也购买该产品的后盖。
For a second let us think and try to figure out what Amazon is trying to do in the figure below:
接下来,让我们思考一下,尝试找出下图中的Amazon要做的事情:
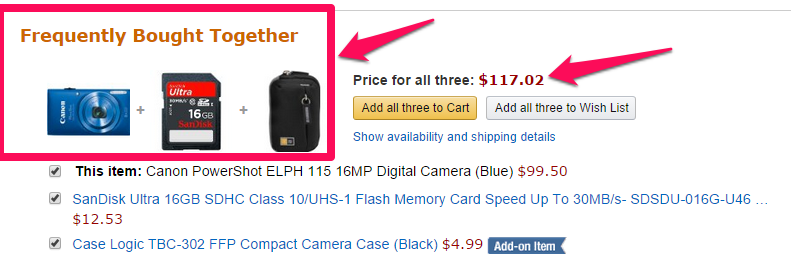
It’s quite easy to notice that they are trying to sell the equipment that is generally required for a camera (memory card and the case). Now, the main question is, how do they do it for millions of items listed on their website. This is where a recommendation system comes handy.
很容易注意到他们正在尝试出售相机通常需要的设备(存储卡和保护套)。 现在,主要问题是,他们如何处理网站上列出的数百万个项目。 这是推荐系统很方便的地方。
What does a recommendation system do ?
推荐系统有什么作用?
A recommendation system recommends you products or items that can be of your interest or liking. Let's take another example:
推荐系统会向您推荐您感兴趣或喜欢的产品或物品。 让我们再举一个例子:
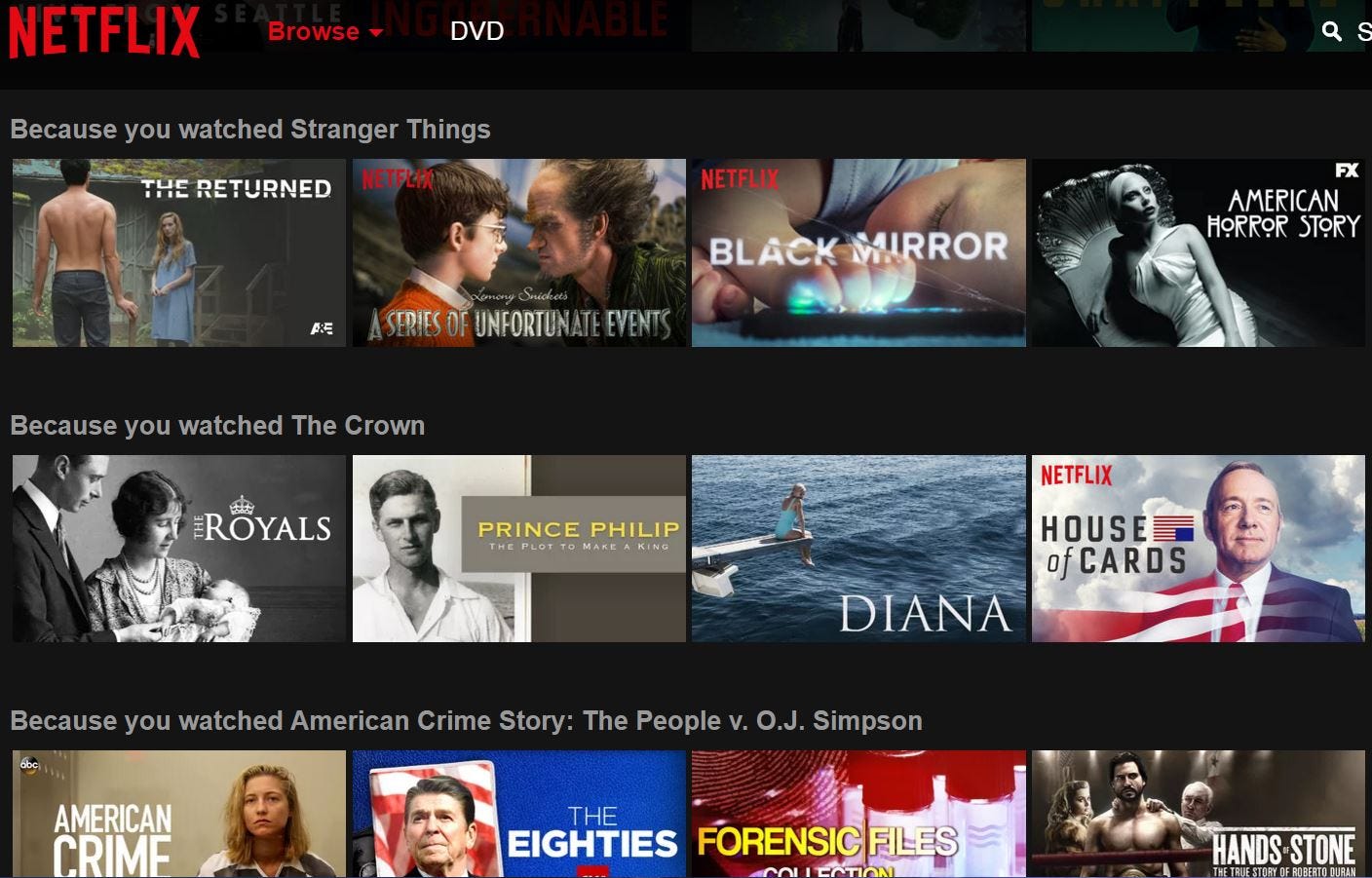
When we first set up our Netflix account, they ask us what our preferences are, which movie or TV show is most likely to be watched by us or what genre of movie is our favorite. So as the first layer of recommendation, Netflix gives us recommendations based on our input, it shows us movies or shows similar to the input that we had provided to it. Once we are a frequent user, it has gathered enough data and gives recommendations more accurately based on our preferences of genres, cast, star rating, and so on ….
当我们首次设置Netflix帐户时,他们会问我们我们的喜好是什么,我们最有可能观看哪种电影或电视节目,或者我们最喜欢哪种电影类型。 因此,作为推荐的第一层,Netflix根据我们的输入为我们提供建议,它向我们展示电影或类似我们提供给它的输入的节目。 一旦成为我们的常客,它就会根据我们的流派,演员,星级等…的偏好,收集足够的数据并提供更准确的建议。
The ultimate aim here is to recommend a user with an item such that he will watch it or buy it(in the case of Amazon), this in turn makes sure that the user is engaged with the platform and the customer lifetime value(CLTV) is maintained.
这里的最终目的是向用户推荐一件商品,以便他可以观看或购买(在亚马逊的情况下),这又可以确保用户参与该平台并获得其终身价值(CLTV)被维持。
Objective of this blog
本博客的目的
By the end of this blog, one will have a basic understanding of how to approach towards building a recommendation system. To make things more lucid let us take an example and try building a Hotel recommendation system. In this process, we will cover data understanding and the algorithms that can be used to realize how a nascent recommendation engine is built. We will use analogies between diurnal used products like Amazon and Netflix to have a clearer understanding.
到本博客结束时,您将对如何建立推荐系统有基本的了解。 为了使事情更加清晰,让我们以一个例子为例,尝试构建一个酒店推荐系统。 在此过程中,我们将介绍数据理解以及可用于实现新生推荐引擎构建方式的算法。 我们将使用日间二手产品(例如Amazon和Netflix)之间的类比,以更清晰地理解。
Understanding the data required for building a recommendation system
了解构建推荐系统所需的数据
To build a recommendation system, we must be clear with the problem statement and the end objective to provide accurate recommendations. For example, consider the following scenarios:
要建立推荐系统,我们必须明确问题陈述和最终目标,以提供准确的推荐。 例如,请考虑以下情形:
- Providing a hotel recommendation to a user based on his/her current search and historical behavior (giving a recommendation knowing that a user is looking for a hotel in Las Vegas and prefers hotels with casinos). 根据用户当前的搜索和历史行为向其提供酒店推荐(知道用户正在拉斯维加斯寻找酒店并且偏爱带有赌场的酒店时,给出推荐)。
- Providing a hotel recommendation based on the user’s historical behavior, targeting those users who are not actively engaged (searching) but can be incentivized towards making a booking by targeting through a relevant recommendation (a general recommendation can be based on metrics such as a user’s historical star rating preference or historical budget preference). 根据用户的历史行为提供酒店推荐,以那些未积极参与(搜索)但可以通过相关推荐为目标而被激励进行预订的用户(一般推荐可以基于用户的历史记录等指标)星级评分偏好或历史预算偏好)。
These are two different objectives and hence, the approach towards achieving both of them is different.
这是两个不同的目标,因此实现这两个目标的方法是不同的。
One must be aware of what type of data is available and also needs to know how to leverage that data to proceed towards building a recommendation engine.
必须知道可用的数据类型,还必须知道如何利用该数据来构建推荐引擎。
There are two types of data which are of importance in our use case:
在我们的用例中,有两种类型的数据很重要:
Explicit Data:
显式数据:

Explicit signals or input is where a user directly gives feedback to a particular item/product. This can be star values, say in the range of 1 to 5 or just a binary 1(like) and 0(dislike). For example, when we rate an item on Amazon or when we rate a movie on IMDb these are explicit signals where we are directly giving our feedback towards an item. One thing to keep in mind is that we should be aware that each and every individual is not the same, i.e. for an Item X, User A, and User B can have different ratings, User A can be generous with his ratings and can give a rating of 5 stars whereas, User B is a critic and gives Item X 3.5 stars and gives 5 stars only for exceptions Items.
明确的信号或输入是用户直接向特定项目/产品提供反馈的地方。 它可以是1到5之间的星形值,也可以只是二进制1(喜欢)和0(喜欢)。 例如,当我们在Amazon上对商品评分或在IMDb上对电影评分时,这些都是明确的信号,我们可以直接向商品提供反馈。 要记住的一件事是,我们应该意识到每个人都不一样,即对于项X,用户A和用户B可以有不同的评分,用户A可以慷慨地提供评分,并且可以给出评级为5星,而用户B是评论家,给项X 3.5个星,仅对例外项给出5星。
Replicating the example for our Hotel recommendation use case can be summarized like, the filters that a user applies while searching for a Hotel, say, filters like swimming pool or WiFi are explicit signal, here the user is explicitly saying that he is interested in properties which have WiFi and a swimming pool.
可以为我们的酒店推荐用例复制示例,例如用户在搜索酒店时应用的过滤器,例如游泳池或WiFi等过滤器是显式信号,此处用户明确表示他对物业感兴趣有WiFi和游泳池。
Additionally, the explicit data is sparse in most of the cases, as it is not ideally possible for a user to give ratings to each and every item. Logically thinking I would not have seen each and every movie on Netflix and hence can only provide feedback for the set of movies that I have seen. These ratings reflect how much a user likes or approves of an item.
另外,在大多数情况下,显式数据是稀疏的,因为理想情况下,用户不可能对每一项进行评分。 逻辑上认为我不会在Netflix上看过每部电影,因此只能为我所看过的电影提供反馈。 这些评分反映了用户喜欢或认可某物品的程度。
Implicit Data:
隐式数据:
Implicit signals are obtained by capturing a user’s interaction with the item. This can be a continuous value, like the number of times a user has clicked on an item or the number of times a user has watched an Action movie or Binary, similar to just clicked or not clicked. For example, while scrolling through amazon.com the amount of time spent viewing an item or the number of times you have clicked the item can act as implicit feedback.
隐式信号是通过捕获用户与商品的交互来获得的。 它可以是一个连续值,例如用户单击某项的次数或用户观看动作电影或二进制文件的次数,类似于单击或未单击。 例如,在amazon.com上滚动时,查看项目所花费的时间或您单击该项目的次数可以充当隐式反馈。
Drawing parallels for hotel recommendations with implicit signals can be understood as follows. Consider that we have the historical hotel bookings of a user A, and we see that in the 4 out of 5 bookings made by the user it was a property that was near the beach. This can act as an implicit signal where we can say that user A prefers hotels near the beach.
通过隐式信号绘制酒店推荐的相似之处可以理解如下。 考虑到我们拥有用户A的历史酒店预订,并且我们看到,在用户进行的5笔预订中,有4笔是靠近海滩的房产。 这可以作为一个隐含信号,可以说用户A偏爱海滩附近的酒店。
Types of Recommendation Systems
推荐系统的类型

Let us take a specific example given below to further explain the recommendation models:
让我们以下面给出的特定示例进一步解释推荐模型:
While making a hotel recommendation system, we have the user’s explicit and implicit signals. However, we do not have all the signals for all the users, for a set of users E we have explicit signals and for a set of users I we have implicit signals.
在制作酒店推荐系统时,我们会收到用户的显式和隐式信号。 但是,我们没有所有用户的所有信号,对于一组用户E,我们具有显式信号,对于一组用户I,我们具有隐式信号。
Further, let us assume that a hotel property has the following attributes:
此外,让我们假设酒店物业具有以下属性:
WiFi Availability, Couple Friendly, Budget Friendly and Nature Friendly (closer to nature)
WiFi可用性,情侣友好型,预算友好型和自然友好型(更贴近自然)
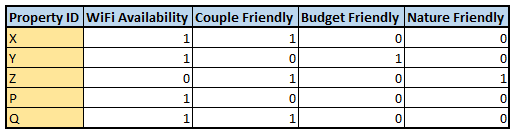
For simplicity let us assume that these are flags, such that if a property A has WiFi in it, the WiFi availability column will be 1. Hence our hotels data will look something like the following:
为简单起见,让我们假设这些是标志,例如,如果属性A中具有WiFi,则WiFi可用性列将为1。因此,我们的酒店数据将类似于以下内容:
Content Based Filtering:
基于内容的过滤:
This technique is used when explicit signals are provided by the user or when we have the user and item attributes and the interaction of the user with that item. The objective here is to show items/products which are similar to the item/product that a person has already purchased or shows a liking for or, in another case, show a product to a user where he explicitly says that he is looking for something in particular. Taking our example, consider that you are booking a hotel from xyz.com, you apply filters for couple-friendly properties, here you are explicitly saying that you are looking for a couple-friendly property and hence, xyz.com will show you properties that are couple friendly. Similarly, while providing recommendations, if we have explicit signals from a user we try to get the best match for that signal with the list of items that we have and provide recommendations accordingly.
当用户提供显式信号时,或者当我们具有用户和项目属性以及用户与该项目的交互时,使用此技术。 此处的目的是向用户显示与某人已经购买或显示出其喜欢的商品/产品相似的商品/产品,或者在另一种情况下向用户显示其明确表示他正在寻找商品的商品/产品。特别是。 以我们的示例为例,假设您正在从xyz.com预订酒店,为情侣友好型物业应用过滤器,在这里您明确表示您正在寻找情侣友好型物业 ,因此xyz.com将向您显示属性那是情侣友好的。 同样,在提供建议的同时, 如果我们收到来自用户的明确信号,我们会尝试使该信号与我们拥有的项目列表最匹配,并相应地提供建议。
Model Algorithms:
模型算法:
Cosine Similarity: It is a measure of similarity between two non-zero vectors. The values range from 0 to 1.
余弦相似度:这是两个非零向量之间相似度的量度。 取值范围是0〜1。

Cosine Similarity is used as a measure of similarity between two non-zero vectors. Here the vectors can be both user or item based.
余弦相似度用作两个非零向量之间相似度的度量。 在此,向量可以基于用户或基于项目。
Let us take an example, assume that a user A has specifically shown interest towards property X from the hotel_type table (the user has previously booked the property or has searched for the property X multiple times recently), we now have to recommend him properties that are similar to property X. To do so, we are going to find the similarity between property X and the rest of the properties in the table.
让我们举个例子,假设用户A从hotel_type表中特别显示了对属性X的兴趣(该用户先前已预订该属性,或者最近多次搜索该属性X),我们现在必须向他推荐以下属性:与属性X相似。为此,我们将找到属性X与表中其余属性之间的相似性。

We can clearly see that property Q has the highest similarity with property X and followed by property P. So if we are to recommend a property to user A we will recommend him property Q knowing that he has a preference for property X.
我们可以清楚地看到,属性Q与属性X的相似性最高,其次是属性P。因此,如果我们要向用户A推荐一个属性,我们将向他推荐属性Q,因为他知道他偏爱属性X。
Pearson Correlation: It is a measure of linear correlation between two variables. The values range from -1 to 1.
皮尔逊相关性:这是两个变量之间线性相关性的量度。 取值范围是-1到1。

Let us take an example where we are getting explicit input from the user where the user is shown the 4 categories (WiFi, Budget, Couple, Nature). The user has the option to provide his input by selecting as many as he wants, he can even select none. Considering the case when a user B has selected at least one of the 4 options. Now, assume user B’s input looks like the following:
让我们举一个例子,我们从用户那里获得明确的输入,其中向用户显示了4个类别(WiFi,预算,夫妻,自然)。 用户可以选择通过选择任意数量来提供自己的输入,甚至可以不选择。 考虑用户B已经选择了四个选项中的至少一个的情况。 现在,假设用户B的输入如下所示:

While one can say that we can use cosine similarity in this case by just filling in the null values as 0. However, it is not advised to so since, cosine similarity assumes the 0’s as a negative preference and in this explicit signal we cannot for sure say that user B is not looking for a couple friendly or a budget friendly property just because the user has not given an input in that field.
虽然可以说在这种情况下我们可以通过仅将空值填充为0来使用余弦相似度。但是,不建议这样做,因为余弦相似度将0假定为负偏好,并且在此显式信号中,我们不能可以肯定地说,用户B并不是仅仅因为用户未在该字段中提供输入,而是在寻找对夫妇友好或对预算友好的属性。
Hence, to avoid this we use Pearson correlation, the output of the similarity measuring technique would look like the following:
因此,为避免这种情况,我们使用Pearson相关,相似度测量技术的输出如下所示:

We can see that property Z is highly correlated to user B’s explicit signal and hence, we will provide Z as a recommendation for user B.
我们可以看到属性Z与用户B的显式信号高度相关,因此,我们将Z作为对用户B的推荐。
So, for the set of users E (explicitly proving us their preference) we will use Pearson Correlation and for the set of users I (implicitly telling us that he/she is looking for a property with a certain set of attributes) we will use Cosine Similarity.
因此,对于用户集E(明确证明我们的偏好),我们将使用Pearson Correlation,对于用户集I(隐式告诉我们他/她正在寻找具有某些属性集的属性),我们将使用余弦相似度。
Note: A user’s explicit signal is always preferred over an implicit signal. For example, in the past I have only booked hotels in the urban areas, however, now I want to book a hotel near the beach (nature friendly). In my explicit search I specify this, but, if you are making an implicit signal from my past bookings you will see that I do not prefer hotels near the beach and would recommend me hotels in the city.
注意:与隐式信号相比,始终首选用户的显式信号。 例如,过去我只预订市区内的酒店,但是现在我想预订靠近海滩的酒店(自然友好型)。 在我的明确搜索中,我指定了此名称,但是,如果您从过去的预订中隐性地发出信号,您会发现我不喜欢海滩附近的酒店,并且会向我推荐该城市的酒店。
In conclusion, Pearson correlation and Cosine similarity are the most widely used similarity techniques, however, we need to always use the correct similarity measuring technique as per our use case. More information on different types of similarity techniques can be found here.
总之, Pearson相关和余弦相似度是使用最广泛的相似度技术 ,但是,根据我们的用例,我们需要始终使用正确的相似度测量技术。 有关不同类型的相似性技术的更多信息,请参见此处 。
Collaborative Filtering:
协同过滤:
This modeling technique is used by leveraging user-item interaction. Here we try to match or group similar users and recommend based on the preferences of similar users. Let us consider a user-item interaction matrix (rating matrix) where we have the hotel rating a user has given a particular hotel:
通过利用用户-项目交互来使用此建模技术。 在这里,我们尝试匹配或分组相似用户,并根据相似用户的偏好进行推荐。 让我们考虑一个用户-项目交互矩阵(评分矩阵),在该矩阵中,我们获得了用户给与特定酒店的酒店评分:
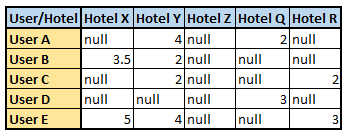
Now let us compare user A and user E, we can see that they both have similar tastes and have rated Hotel Y as 4, seeing this let us assume that user A will rate Hotel X as 5 and hotel R as 3. Hence, we can give a recommendation of hotel X to user A by noticing the similarity between user A and user E (considering that he will like Hotel X and rate it 5).
现在让我们比较用户A和用户E,我们可以看到他们两个都具有相似的品味,并且将酒店Y的评分定为4,这让我们假设用户A将酒店X的评分定为5,酒店R的评分为3。因此,我们可以通过注意到用户A和用户E之间的相似性(考虑他会喜欢酒店X并将其评级为5)向用户A提供酒店X的推荐。
So, if we are provided with the interaction of a user with an item where the user has given feedback towards the item, we can use collaborative filtering (for example, the rating matrix). Explicit ratings such as star rating given by the user or Implicit signals such as a flag if the user has booked a property or not are examples of user-item interaction.
因此,如果向我们提供了用户与某项商品之间的交互,而用户已经对该商品提供了反馈,则可以使用协作过滤(例如,评分矩阵)。 用户与项目交互的示例包括用户给出的星级(例如星级)等显式等级或标志(例如标记)的隐式信号。
Model Algorithms:
模型算法:
Memory and Model-Based Approach are the two types of techniques to implement collaborative filtering. The key difference between the two is that in the memory-based approach we do not use parametric machine learning models.
内存和基于模型的方法是实现协作过滤的两种技术。 两者之间的主要区别在于,在基于内存的方法中,我们不使用参数化机器学习模型。
Memory-Based Approach: It can be divided into two sub-divisions, user-item filtering, and item-item filtering. In the user-item approach, we identify clusters of similar users and utilize the interaction of a particular user in that cluster to predict the interaction of the whole cluster. For example, to predict the rating user C gives to a hotel X, we will take a weighted sum of hotel X’s rating by the other users, here weight is the similarity number between user X and the other users. Adjusted cosine similarity can also be used to remove the difference in the nature of individuals, which brings critics and the general public on the same scale.
基于内存的方法:它可以分为两个细分,用户项目过滤和项目项目过滤。 在用户项方法中,我们识别相似用户的集群,并利用该集群中特定用户的交互来预测整个集群的交互。 例如,为了预测用户C对酒店X的评分,我们将对其他用户对酒店X的评分进行加权总和,这里的权重是用户X与其他用户之间的相似度。 调整后的余弦相似度也可以用来消除个体性质的差异,从而使批评者和普通大众处于同一规模。
Item-item filtering is similar to user-item filtering but here we take an item and see the users that liked that item and find other sets of items that those set of users or similar users also liked. It takes items, finds similar items, and outputs those items as recommendations.
项过滤类似于用户项过滤,但是在这里我们获取一个项,查看喜欢该项的用户,并找到那些用户或相似用户也喜欢的其他项。 它接受项目,找到相似的项目,并将这些项目作为建议输出。
Model-Based Approach: In this technique, we use machine learning models to predict the rating for an item that could have been given by a user and hence, provide recommendations.
基于模型的方法:在这种技术中,我们使用机器学习模型来预测用户可能已经给定的商品的评分,从而提供建议。
There are several ML models that are used, to name a few, Matrix factorization, SVD (singular value decomposition), ALS, and SVD++. Some also use neural networks, decision trees, and latent factor models to enhance the results. We will delve into Matrix Factorization below.
仅使用了几种ML模型,例如矩阵分解,SVD(奇异值分解),ALS和SVD ++。 有些还使用神经网络,决策树和潜在因子模型来增强结果。 我们将在下面深入研究矩阵分解。
Matrix Factorization:
矩阵分解:
In matrix factorization, the goal is to complete the matrix and fill in the null values in the rating matrix.
在矩阵分解中,目标是完成矩阵并在评级矩阵中填写空值。

The preferences of the users are identified by a small number of hidden features of the user and items. Here there are two hidden feature vectors for users(user matrix 4x2) and items(item matrix 2x4). Once we multiply the user and item matrix back together we get back our ratings matrix with null values replaced by predicted values. Once we get the predicted values we can recommend an Item with the highest rating for a user (not considering the items already interacted with).
用户的喜好由用户和项目的少量隐藏特征来标识。 这里有两个针对用户(用户矩阵4x2)和项(项目矩阵2x4)的隐藏特征向量。 一旦将用户矩阵和项目矩阵相乘在一起,我们便得到了用零值替换为预测值的评级矩阵。 一旦获得预测值,我们便可以为用户推荐评分最高的商品(不考虑已经与之互动的商品)。
Note: Here we are not providing any feature vector for the users or the items, the computation decomposes and creates vectors on its own and, finally, predicts by filling in the null values.
注意:此处我们不为用户或商品提供任何特征向量,计算将自行分解并创建向量,最后通过填充空值进行预测。
If we have user demographics information and user’s features and preference information and item features we can use SVD++ where we can pass users and item feature vectors as well to get the best recommendation results.
如果我们拥有用户人口统计信息,用户特征,偏好信息以及商品特征,那么我们可以使用SVD ++,我们可以传递用户和商品特征向量来获得最佳推荐结果。
Hybrid Models:
混合模型:
The hybrid model combines multiple models/algorithms to build a recommendation system. To improve the effectiveness of the recommendation we can combine collaborative filtering and content-based filtering giving appropriate weights to the individual models and finally using this hybrid system to give out a recommendation.
混合模型结合了多个模型/算法以构建推荐系统。 为了提高推荐的有效性,我们可以将协作过滤和基于内容的过滤相结合,为各个模型赋予适当的权重,最后使用此混合系统给出推荐。
For example, we can combine the results of the following by giving weights:
例如,我们可以通过赋予权重来合并以下结果:
- Using Matrix factorization (collaborative filtering) on ratings matrix to match similar users and predict a rating for the user-item pair. 在评分矩阵上使用矩阵分解(协作过滤)以匹配相似的用户并预测该用户项对的评分。
- Using Pearson correlation (content-based filtering) to find similarity between users who provide explicit filters and the hotels with feature vectors. 使用Pearson相关(基于内容的过滤)查找提供显式过滤器的用户与具有特征向量的酒店之间的相似性。
The combined results can be used to provide recommendations to users.
合并的结果可用于向用户提供建议。
Conclusion:
结论:
Building a recommendation system highly depends on the end objective and the data we have at hand. Understanding the algorithms and knowing which one to use to get recommendations plays a vital role in building a good recommendation system. Additionally, a good recommendation system also uses multiple algorithms and combines the results to provide the final recommendations.
建立推荐系统在很大程度上取决于最终目标和我们掌握的数据。 理解算法并知道使用哪个算法来获得推荐对于构建良好的推荐系统至关重要。 此外,良好的推荐系统还使用多种算法,并将结果组合起来以提供最终的推荐。
https://pdfs.semanticscholar.org/943a/e455fafc3d36ae4ce68f1a60ae4f85623e2a.pdf
https://pdfs.semanticscholar.org/943a/e455fafc3d36ae4ce68f1a60ae4f85623e2a.pdf
https://towardsdatascience.com/introduction-to-recommender-systems-6c66cf15ada
https://towardsdatascience.com/introduction-to-recommender-systems-6c66cf15ada
翻译自: https://medium.com/@ibrahimmk11/recommendation-systems-for-beginners-c53765547ef9
初学者linux系统推荐















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









