





svm和k-最近邻
Recommendation systems are becoming increasingly important in today’s hectic world. People are always in the lookout for products/services that are best suited for them. Therefore, the recommendation systems are important as they help them make the right choices, without having to expend their cognitive resources.
在当今繁忙的世界中,推荐系统变得越来越重要。 人们总是在寻找最适合他们的产品/服务。 因此,推荐系统非常重要,因为它们可以帮助他们做出正确的选择,而不必花费他们的认知资源。
In this blog, we will understand the basics of Recommendation Systems and learn how to build a Movie Recommendation System using collaborative filtering by implementing the K-Nearest Neighbors algorithm. We will also predict the rating of the given movie based on its neighbors and compare it with the actual rating.
在此博客中,我们将了解推荐系统的基础知识,并学习如何通过实现K最近邻居算法使用协作过滤来构建电影推荐系统。 我们还将根据给定电影的邻居来预测给定电影的收视率,并将其与实际收视率进行比较。
推荐系统的类型 (Types of Recommendation Systems)
Recommendation systems can be broadly classified into 3 types —
推荐系统大致可分为3种类型-
- Collaborative Filtering 协同过滤
- Content-Based Filtering 基于内容的过滤
- Hybrid Recommendation Systems 混合推荐系统
协同过滤 (Collaborative Filtering)
This filtering method is usually based on collecting and analyzing information on user’s behaviors, their activities or preferences, and predicting what they will like based on the similarity with other users. A key advantage of the collaborative filtering approach is that it does not rely on machine analyzable content and thus it is capable of accurately recommending complex items such as movies without requiring an “understanding” of the item itself.
这种过滤方法通常基于收集和分析有关用户的行为,他们的活动或偏好的信息,并基于与其他用户的相似性来预测他们的需求。 协作过滤方法的主要优势在于它不依赖于机器可分析的内容,因此能够准确地推荐诸如电影之类的复杂项目,而无需“了解”项目本身。
Further, there are several types of collaborative filtering algorithms —
此外,协作过滤算法有几种类型-
User-User Collaborative Filtering: Try to search for lookalike customers and offer products based on what his/her lookalike has chosen.
用户-用户协作过滤:尝试搜索相似的客户并根据他/她的相似选择提供产品。
Item-Item Collaborative Filtering: It is very similar to the previous algorithm, but instead of finding a customer lookalike, we try finding item lookalike. Once we have item lookalike matrix, we can easily recommend alike items to a customer who has purchased an item from the store.
物料-物料协同过滤:它与先前的算法非常相似,但是我们没有找到相似的客户,而是尝试寻找相似的物料。 一旦有了商品相似矩阵,我们就可以轻松地向从商店购买商品的顾客推荐相同商品。
Other algorithms: There are other approaches like market basket analysis, which works by looking for combinations of items that occur together frequently in transactions.
其他算法:还有其他方法,例如市场篮分析,其作用是查找交易中经常出现的物品组合。

基于内容的过滤 (Content-based filtering)
These filtering methods are based on the description of an item and a profile of the user’s preferred choices. In a content-based recommendation system, keywords are used to describe the items, besides, a user profile is built to state the type of item this user likes. In other words, the algorithms try to recommend products that are similar to the ones that a user has liked in the past.
这些过滤方法基于项目的描述和用户偏好选择的配置文件。 在基于内容的推荐系统中,关键字用于描述项目,此外,还建立了一个用户资料来说明该用户喜欢的项目的类型。 换句话说,算法尝试推荐与用户过去喜欢的产品相似的产品。
混合推荐系统 (Hybrid Recommendation Systems)

Recent research has demonstrated that a hybrid approach, combining collaborative filtering and content-based filtering could be more effective in some cases. Hybrid approaches can be implemented in several ways, by making content-based and collaborative-based predictions separately and then combining them, by adding content-based capabilities to a collaborative-based approach (and vice versa), or by unifying the approaches into one model.
最近的研究表明,将协作过滤和基于内容的过滤相结合的混合方法在某些情况下可能更有效。 可以通过几种方式来实现混合方法,方法是分别进行基于内容的预测和基于协作的预测,然后将它们组合在一起,将基于内容的功能添加到基于协作的方法中(反之亦然),或者将这些方法统一为一个方法模型。
Netflix is a good example of the use of hybrid recommender systems. The website makes recommendations by comparing the watching and searching habits of similar users (i.e. collaborative filtering) as well as by offering movies that share characteristics with films that a user has rated highly (content-based filtering).
Netflix是使用混合推荐系统的一个很好的例子。 该网站通过比较相似用户的观看和搜索习惯(即协作过滤),以及通过提供与用户评价很高的电影具有相同特征的电影(基于内容的过滤)来提供建议。
Now that we’ve got a basic intuition of Recommendation Systems, let’s start with building a simple Movie Recommendation System in Python.
现在,我们已经有了“推荐系统”的基本知识,让我们从用Python构建一个简单的电影推荐系统开始。
Find the Python notebook with the entire code along with the dataset and all the illustrations here.
在此处找到带有完整代码以及数据集和所有插图的Python笔记本。
TMDb —电影数据库 (TMDb — The Movie Database)
The Movie Database (TMDb) is a community built movie and TV database which has extensive data about movies and TV Shows. Here are the stats —
电影数据库(TMDb)是社区建立的电影和电视数据库,其中包含有关电影和电视节目的大量数据。 以下是统计资料-

For simplicity and easy computation, I have used a subset of this huge dataset which is the TMDb 5000 dataset. It has information about 5000 movies, split into 2 CSV files.
为了简化计算,我使用了这个庞大的数据集的一个子集,即TMDb 5000数据集。 它具有约5000部电影的信息,分为2个CSV文件。
tmdb_5000_movies.csv: Contains information like the score, title, date_of_release, genres, etc.
tmdb_5000_movies.csv:包含诸如乐谱,标题,发行日期,类型等信息。
tmdb_5000_credits.csv: Contains information of the cast and crew for each movie.
tmdb_5000_credits.csv:包含每个电影的演员和剧组信息。
The link to the Dataset is here.
数据集的链接在这里 。
第1步-导入数据集 (Step 1 — Import the dataset)
Import the required Python libraries like Pandas, Numpy, Seaborn and Matplotlib. Then import the CSV files using read_csv() function predefined in Pandas.
导入所需的Python库,例如Pandas,Numpy,Seaborn和Matplotlib。 然后使用Pandas中预定义的read_csv()函数导入CSV文件。
movies = pd.read_csv('../input/tmdb-movie-metadata/tmdb_5000_movies.csv')
credits = pd.read_csv('../input/tmdb-movie-metadata/tmdb_5000_credits.csv')第2步-数据探索和清理 (Step 2 — Data Exploration and Cleaning)
We will initially use the head(), describe() function to view the values and structure of the dataset, and then move ahead with cleaning the data.
我们将首先使用head() , describe()函数查看数据集的值和结构,然后继续清理数据。
movies.head()
movies.describe()
Similarly, we can get an intuition of the credits dataframe and get an output as follows —
同样,我们可以直观地了解信用数据框架,并获得如下输出:

Checking the dataset, we can see that genres, keywords, production_companies, production_countries, spoken_languages are in the JSON format. Similarly in the other CSV file, cast and crew are in the JSON format. Now let's convert these columns into a format that can be easily read and interpreted. We will convert them into strings and later convert them into lists for easier interpretation.
检查数据集,我们可以看到流派,关键字,production_companies,production_countries,speaked_languages为JSON格式。 同样,在其他CSV文件中,演员和船员均采用JSON格式。 现在,让我们将这些列转换为易于阅读和解释的格式。 我们将它们转换为字符串,然后将它们转换为列表,以方便解释。
The JSON format is like a dictionary (key:value) pair embedded in a string. Generally, parsing the data is computationally expensive and time consuming. Luckily this dataset doesn’t have that complicated structure. A basic similarity between the columns is that they have a name key, which contains the values that we need to collect. The easiest way to do so parse through the JSON and check for the name key on each row. Once the name key is found, store the value of it into a list and replace the JSON with the list.
JSON格式就像嵌入在字符串中的字典(键:值)对。 通常,解析数据在计算上是昂贵且费时的。 幸运的是,该数据集没有那么复杂的结构。 列之间的基本相似之处在于它们具有名称键,其中包含我们需要收集的值。 最简单的方法是通过JSON解析并检查每一行上的名称键。 找到名称键后,将其值存储在列表中,然后用列表替换JSON。
But we cannot directly parse this JSON as it has to be decoded first. For this we use the json.loads() method, which decodes it into a list. We can then parse through this list to find the desired values. Let's look at the proper syntax below.
但是我们无法直接解析此JSON,因为必须先对其进行解码。 为此,我们使用json.loads()方法,将其解码为列表。 然后,我们可以解析此列表以找到所需的值。 让我们看看下面的正确语法。
# changing the genres column from json to string
movies['genres'] = movies['genres'].apply(json.loads)
for index,i in zip(movies.index,movies['genres']):
list1 = []
for j in range(len(i)):
list1.append((i[j]['name'])) # the key 'name' contains the name of the genre
movies.loc[index,'genres'] = str(list1)In a similar fashion, we will convert the JSON to a list of strings for the columns: keywords, production_companies, cast, and crew. We will check if all the required JSON columns have been converted to strings using movies.iloc[index]
以类似的方式,我们将JSON转换为以下列的字符串列表:关键字,production_companies,cast和crew。 我们将检查是否所有必需的JSON列都已使用movie.iloc [index]转换为字符串。

第3步-合并2个CSV文件 (Step 3 — Merge the 2 CSV files)
We will merge the movies and credits dataframes and select the columns which are required and have a unified movies dataframe to work on.
我们将合并电影和片数数据框,然后选择所需的列并使用统一的电影数据框。
movies = movies.merge(credits, left_on='id', right_on='movie_id', how='left')
movies = movies[['id', 'original_title', 'genres', 'cast', 'vote_average', 'director', 'keywords']]We can check the size and attributes of movies like this —
我们可以像这样检查电影的大小和属性-

步骤4 —使用“类型”列 (Step 4 — Working with the Genres column)
We will clean the genre column to find the genre_list
我们将清理genre列以找到genre_list
movies['genres'] = movies['genres'].str.strip('[]').str.replace(' ','').str.replace("'",'')
movies['genres'] = movies['genres'].str.split(',')Let’s plot the genres in terms of their occurrence to get an insight of movie genres in terms of popularity.
让我们根据流派的出现来绘制流派,以从流行度角度了解电影流派。
plt.subplots(figsize=(12,10))
list1 = []
for i in movies['genres']:
list1.extend(i)
ax = pd.Series(list1).value_counts()[:10].sort_values(ascending=True).plot.barh(width=0.9,color=sns.color_palette('hls',10))
for i, v in enumerate(pd.Series(list1).value_counts()[:10].sort_values(ascending=True).values):
ax.text(.8, i, v,fontsize=12,color='white',weight='bold')
plt.title('Top Genres')
plt.show()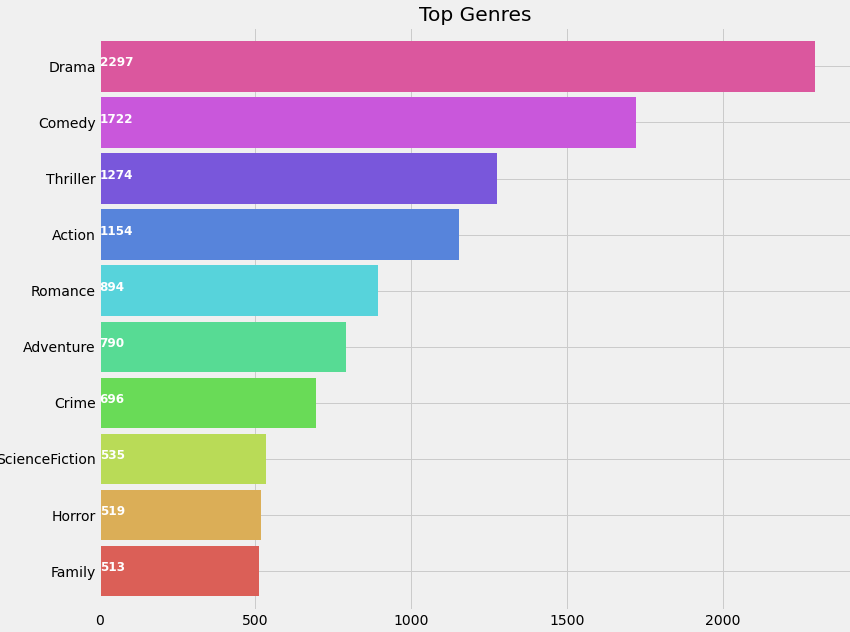
Now let's generate a list ‘genreList’ with all possible unique genres mentioned in the dataset.
现在,我们生成一个列表“ genreList”,其中包含数据集中提到的所有可能的唯一类型。
genreList = []
for index, row in movies.iterrows():
genres = row["genres"]
for genre in genres:
if genre not in genreList:
genreList.append(genre)
genreList[:10] #now we have a list with unique genres
One Hot Encoding for multiple labels
一热编码多个标签
‘genreList’ will now hold all the genres. But how do we come to know about the genres each movie falls into. Now some movies will be ‘Action’, some will be ‘Action, Adventure’, etc. We need to classify the movies according to their genres.
现在,“ genreList”将保留所有类型。 但是我们如何了解每部电影的流派。 现在,有些电影将是“动作”,某些电影将是“动作,冒险”等。我们需要根据电影的类型对电影进行分类。
Let's create a new column in the dataframe that will hold the binary values whether a genre is present or not in it. First let's create a method which will return back a list of binary values for the genres of each movie. The ‘genreList’ will be useful now to compare against the values.
让我们在数据框中创建一个新列,该列将保存二进制值,无论其中是否存在流派。 首先让我们创建一个方法,该方法将返回每个电影类型的二进制值列表。 现在,“ genreList”可用于与这些值进行比较。
Let's say for example we have 20 unique genres in the list. Thus the below function will return a list with 20 elements, which will be either 0 or 1. Now for example we have a Movie which has genre = ‘Action’, then the new column will hold [1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0].
举例来说,清单中有20种独特的流派。 因此,下面的函数将返回包含20个元素的列表,这些元素将为0或1。现在,例如,我们有一个流派='动作'的电影,那么新列将包含[1,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。
Similarly for ‘Action, Adventure’ we will have, [1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]. Converting the genres into such a list of binary values will help in easily classifying the movies by their genres.
同样,对于“动作,冒险”,我们将有[1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 0]。 将流派转换为这样的二进制值列表将有助于轻松按电影的流派对电影进行分类。
def binary(genre_list):
binaryList = []
for genre in genreList:
if genre in genre_list:
binaryList.append(1)
else:
binaryList.append(0)
return binaryListApplying the binary() function to the ‘genres’ column to get ‘genre_list’
将binary()函数应用于“类型”列以获取“ genre_list”
We will follow the same notations for other features like the cast, director, and the keywords.
对于其他功能(例如演员,导演和关键字),我们将使用相同的符号。
movies['genres_bin'] = movies['genres'].apply(lambda x: binary(x))
movies['genres_bin'].head()
第5步-使用Cast列 (Step 5 — Working with the Cast column)
Let’s plot a graph of Actors with Highest Appearances
让我们绘制出外观最高的演员图
plt.subplots(figsize=(12,10))
list1=[]
for i in movies['cast']:
list1.extend(i)
ax=pd.Series(list1).value_counts()[:15].sort_values(ascending=True).plot.barh(width=0.9,color=sns.color_palette('muted',40))
for i, v in enumerate(pd.Series(list1).value_counts()[:15].sort_values(ascending=True).values):
ax.text(.8, i, v,fontsize=10,color='white',weight='bold')
plt.title('Actors with highest appearance')
plt.show()
S
小号
When I initially created the list of all the cast, it had around 50k unique values, as many movies have entries for about 15–20 actors. But do we need all of them? The answer is No. We just need the actors who have the highest contribution to the movie. For eg: The Dark Knight franchise has many actors involved in the movie. But we will select only the main actors like Christian Bale, Micheal Caine, Heath Ledger. I have selected the main 4 actors from each movie.
最初创建所有演员表的列表时,它具有约50k的唯一值,因为许多电影都包含约15–20个演员的条目。 但是我们需要所有这些吗? 答案是否定的。我们只需要对电影贡献最大的演员即可。 例如:黑暗骑士专营权有很多演员都参与了电影。 但我们只会选择主要演员,例如克里斯蒂安·贝尔,米歇尔·凯恩,希思·莱杰。 我从每部电影中选择了主要的4位演员。
One question that may arise in your mind is that how do you determine the importance of the actor in the movie. Luckily, the sequence of the actors in the JSON format is according to the actor’s contribution to the movie.
您可能会想到的一个问题是,您如何确定演员在电影中的重要性。 幸运的是,演员的JSON格式顺序取决于演员对电影的贡献。
Let’s see how we do that and create a column ‘cast_bin’
让我们看看我们如何做到这一点并创建一列' cast_bin '
for i,j in zip(movies['cast'],movies.index):
list2 = []
list2 = i[:4]
movies.loc[j,'cast'] = str(list2)
movies['cast'] = movies['cast'].str.strip('[]').str.replace(' ','').str.replace("'",'')
movies['cast'] = movies['cast'].str.split(',')
for i,j in zip(movies['cast'],movies.index):
list2 = []
list2 = i
list2.sort()
movies.loc[j,'cast'] = str(list2)
movies['cast']=movies['cast'].str.strip('[]').str.replace(' ','').str.replace("'",'')castList = []
for index, row in movies.iterrows():
cast = row["cast"]
for i in cast:
if i not in castList:
castList.append(i)movies[‘cast_bin’] = movies[‘cast’].apply(lambda x: binary(x))
movies[‘cast_bin’].head()
第6步-使用Directors列 (Step 6 — Working with the Directors column)
Let’s plot Directors with maximum movies
让我们为导演绘制最多电影
def xstr(s):
if s is None:
return ''
return str(s)
movies['director'] = movies['director'].apply(xstr)plt.subplots(figsize=(12,10))
ax = movies[movies['director']!=''].director.value_counts()[:10].sort_values(ascending=True).plot.barh(width=0.9,color=sns.color_palette('muted',40))
for i, v in enumerate(movies[movies['director']!=''].director.value_counts()[:10].sort_values(ascending=True).values):
ax.text(.5, i, v,fontsize=12,color='white',weight='bold')
plt.title('Directors with highest movies')
plt.show()
We create a new column ‘director_bin’ like we have done earlier
我们像之前所做的那样创建一个新列' director_bin '
directorList=[]
for i in movies['director']:
if i not in directorList:
directorList.append(i)movies['director_bin'] = movies['director'].apply(lambda x: binary(x))
movies.head()So finally, after all this work we get the movies dataset as follows
最后,在完成所有这些工作之后,我们得到了电影数据集,如下所示

第7步-使用“关键字”列 (Step 7 — Working with the Keywords column)
The keywords or tags contain a lot of information about the movie, and it is a key feature in finding similar movies. For eg: Movies like “Avengers” and “Ant-man” may have common keywords like superheroes or Marvel.
关键字或标签包含有关电影的大量信息,这是查找相似电影的关键功能。 例如:“复仇者联盟”和“蚂蚁侠”之类的电影可能具有超级英雄或漫威等常见关键字。
For analyzing keywords, we will try something different and plot a word cloud to get a better intuition:
为了分析关键字,我们将尝试一些不同的方法并绘制词云以获得更好的直觉:
from wordcloud import WordCloud, STOPWORDS
import nltk
from nltk.corpus import stopwordsplt.subplots(figsize=(12,12))
stop_words = set(stopwords.words('english'))
stop_words.update(',',';','!','?','.','(',')','$','#','+',':','...',' ','')words=movies['keywords'].dropna().apply(nltk.word_tokenize)
word=[]
for i in words:
word.extend(i)
word=pd.Series(word)
word=([i for i in word.str.lower() if i not in stop_words])
wc = WordCloud(background_color="black", max_words=2000, stopwords=STOPWORDS, max_font_size= 60,width=1000,height=1000)
wc.generate(" ".join(word))
plt.imshow(wc)
plt.axis('off')
fig=plt.gcf()
fig.set_size_inches(10,10)
plt.show()
We find ‘words_bin’ from Keywords as follows —
我们从关键字中找到“ words_bin ”,如下所示-
movies['keywords'] = movies['keywords'].str.strip('[]').str.replace(' ','').str.replace("'",'').str.replace('"','')
movies['keywords'] = movies['keywords'].str.split(',')
for i,j in zip(movies['keywords'],movies.index):
list2 = []
list2 = i
movies.loc[j,'keywords'] = str(list2)
movies['keywords'] = movies['keywords'].str.strip('[]').str.replace(' ','').str.replace("'",'')
movies['keywords'] = movies['keywords'].str.split(',')
for i,j in zip(movies['keywords'],movies.index):
list2 = []
list2 = i
list2.sort()
movies.loc[j,'keywords'] = str(list2)
movies['keywords'] = movies['keywords'].str.strip('[]').str.replace(' ','').str.replace("'",'')
movies['keywords'] = movies['keywords'].str.split(',')words_list = []
for index, row in movies.iterrows():
genres = row["keywords"]
for genre in genres:
if genre not in words_list:
words_list.append(genre)movies['words_bin'] = movies['keywords'].apply(lambda x: binary(x))
movies = movies[(movies['vote_average']!=0)] #removing the movies with 0 score and without drector names
movies = movies[movies['director']!='']步骤8 —电影之间的相似性 (Step 8 — Similarity between movies)
We will be using Cosine Similarity for finding the similarity between 2 movies. How does cosine similarity work?
我们将使用余弦相似度来查找2部电影之间的相似度。 余弦相似度如何工作?
Let’s say we have 2 vectors. If the vectors are close to parallel, i.e. angle between the vectors is 0, then we can say that both of them are “similar”, as cos(0)=1. Whereas if the vectors are orthogonal, then we can say that they are independent or NOT “similar”, as cos(90)=0.
假设我们有2个向量。 如果向量接近平行,即向量之间的夹角为0,则可以说它们都是“相似的”,因为cos(0)= 1。 而如果向量是正交的,那么我们可以说它们是独立的或不“相似”,因为cos(90)= 0。

For a more detailed study, follow this link.
有关更详细的研究,请单击此链接 。
Below I have defined a function Similarity, which will check the similarity between the movies.
在下面,我定义了一个相似性功能,该功能将检查电影之间的相似性。
from scipy import spatialdef Similarity(movieId1, movieId2):
a = movies.iloc[movieId1]
b = movies.iloc[movieId2]
genresA = a['genres_bin']
genresB = b['genres_bin']
genreDistance = spatial.distance.cosine(genresA, genresB)
scoreA = a['cast_bin']
scoreB = b['cast_bin']
scoreDistance = spatial.distance.cosine(scoreA, scoreB)
directA = a['director_bin']
directB = b['director_bin']
directDistance = spatial.distance.cosine(directA, directB)
wordsA = a['words_bin']
wordsB = b['words_bin']
wordsDistance = spatial.distance.cosine(directA, directB)
return genreDistance + directDistance + scoreDistance + wordsDistanceLet’s check the Similarity between 2 random movies
让我们检查两部随机电影之间的相似性

We see that the distance is about 2.068, which is high. The more the distance, the less similar the movies are. Let’s see what these random movies actually were.
我们看到该距离约为2.068,这是很高的。 距离越远,电影越不相似。 让我们看看这些随机电影实际上是什么。

It is evident that The Dark Knight Rises and How to train your Dragon 2 are very different movies. Thus the distance is huge.
显然,《黑暗骑士崛起》和《驯龙高手2》是非常不同的电影。 因此距离很大。
第9步-得分预测器(最后一步!) (Step 9 — Score Predictor (the final step!))
So now when we have everything in place, we will now build the score predictor. The main function working under the hood will be the Similarity() function, which will calculate the similarity between movies, and will find 10 most similar movies. These 10 movies will help in predicting the score for our desired movie. We will take the average of the scores of similar movies and find the score for the desired movie.
因此,当我们准备就绪时,我们现在将建立得分预测器。 幕后工作的主要功能是“ 相似性”函数,该函数将计算电影之间的相似度,并找到10个最相似的电影。 这10部电影将有助于预测我们所需电影的得分。 我们将取相似电影的平均得分,然后找到所需电影的得分。
Now the similarity between the movies will depend on our newly created columns containing binary lists. We know that features like the director or the cast will play a very important role in the movie’s success. We always assume that movies from David Fincher or Chris Nolan will fare very well. Also if they work with their favorite actors, who always fetch them success and also work on their favorite genres, then the chances of success are even higher. Using these phenomena, let's try building our score predictor.
现在,电影之间的相似性将取决于我们新创建的包含二进制列表的列。 我们知道导演或演员等功能将在电影的成功中扮演非常重要的角色。 我们始终认为,大卫·芬奇(David Fincher)或克里斯·诺兰(Chris Nolan)的电影会很不错。 同样,如果他们与自己喜欢的演员合作,他们总是获得成功,并且也按照自己喜欢的类型工作,那么成功的机会就更高。 利用这些现象,让我们尝试构建分数预测器。
import operatordef predict_score():
name = input('Enter a movie title: ')
new_movie = movies[movies['original_title'].str.contains(name)].iloc[0].to_frame().T
print('Selected Movie: ',new_movie.original_title.values[0])
def getNeighbors(baseMovie, K):
distances = []
for index, movie in movies.iterrows():
if movie['new_id'] != baseMovie['new_id'].values[0]:
dist = Similarity(baseMovie['new_id'].values[0], movie['new_id'])
distances.append((movie['new_id'], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(K):
neighbors.append(distances[x])
return neighbors
K = 10
avgRating = 0
neighbors = getNeighbors(new_movie, K)print('\nRecommended Movies: \n')
for neighbor in neighbors:
avgRating = avgRating+movies.iloc[neighbor[0]][2]
print( movies.iloc[neighbor[0]][0]+" | Genres: "+str(movies.iloc[neighbor[0]][1]).strip('[]').replace(' ','')+" | Rating: "+str(movies.iloc[neighbor[0]][2]))
print('\n')
avgRating = avgRating/K
print('The predicted rating for %s is: %f' %(new_movie['original_title'].values[0],avgRating))
print('The actual rating for %s is %f' %(new_movie['original_title'].values[0],new_movie['vote_average']))Now simply just run the function as follows and enter the movie you like to find 10 similar movies and it’s predicted ratings
现在,只需按如下所示运行该功能,然后输入您想要的电影,即可找到10部相似的电影及其预测的收视率
predict_score()


Thus we have completed the Movie Recommendation System implementation using the K Nearest Neighbors algorithm.
因此,我们已经使用K最近邻算法完成了电影推荐系统的实现。
旁注— K值 (Sidenote — K Value)
In this project, I have arbitrarily chosen the value K=10.
在这个项目中,我任意选择了值K = 10。
But in other applications of KNN, finding the value of K is not easy. A small value of K means that noise will have a higher influence on the result and a large value make it computationally expensive. Data scientists usually choose as an odd number if the number of classes is 2 and another simple approach to select k is set K=sqrt(n).
但是在KNN的其他应用中,找到K的值并不容易。 较小的K值意味着噪声将对结果产生更大的影响,而较大的值将使其在计算上昂贵。 如果类别数是2,并且选择k的另一种简单方法是K = sqrt(n),则数据科学家通常选择作为奇数。
This is the end of this blog. Let me know if you have any suggestions/doubts.
这是本博客的结尾。 如果您有任何建议/疑问,请告诉我。
Find the Python notebook with the entire code along with the dataset and all the illustrations here.Let me know how you found this blog :)
在 此处 找到带有完整代码以及数据集和所有插图的Python笔记本 。让我知道您如何找到此博客:)
进一步阅读 (Further Reading)
svm和k-最近邻















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









