






 本文探讨了贝塞尔修正的原理,主要聚焦于为何在统计学中使用n-1作为样本方差的除数,从而提供更准确的估计。通过翻译自《Towards Data Science》的文章,深入解析了这一修正背后的原因。
本文探讨了贝塞尔修正的原理,主要聚焦于为何在统计学中使用n-1作为样本方差的除数,从而提供更准确的估计。通过翻译自《Towards Data Science》的文章,深入解析了这一修正背后的原因。
贝塞尔修正
A standard deviation seems like a simple enough concept. It’s a measure of dispersion of data, and is the root of the summed differences between the mean and its data points, divided by the number of data points…minus one to correct for bias.
标准偏差似乎很简单。 它是对数据分散性的一种度量,是均值与其数据点之和的总和之差除以数据点的数量…… 减去1即可校正偏差 。
This is, I believe, the most oversimplified and maddening concept for any learner, and the intent of this post is to provide a clear and intuitive explanation for Bessel’s Correction, or n-1.
我认为,对于任何学习者来说,这都是最简单和令人发疯的概念,这篇文章的目的是为贝塞尔修正(n-1)提供清晰直观的解释。
To start, recall the formula for a population mean:
首先,回顾一下总体均值的公式:
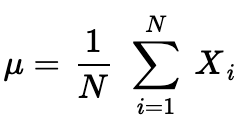
What about a sample mean?
样本的意思是什么?

Well, they look identical, except for the lowercase N. In each case, you just add each xᵢ, and divide by how many x’s there are. If we are dealing with an entire population, we would use N, instead of n, to indicate the total number of points in the population.
好吧,除了小写字母N之外,它们看起来相同。在每种情况下,您只需将每个xᵢ相加,然后除以x的个数即可。 如果要处理整个总体,则将使用N而不是n来表示总体中的总点数。
Now, what is standard deviation σ (called sigma)?
现在,标准偏差σ是多少?
If a population contains N points, then the standard deviation is the square root of the variance, which is the summed-and-averaged squared differences of each data point and the population mean, or μ:
如果总体包含N个点,则标准偏差为方差的平方根,即每个数据点与总体平均值或μ的求和平均值平方差。
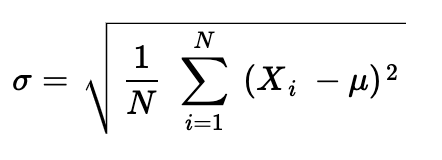
But what about a sample standard deviation, s, with n data points and sample mean x-bar:
但是,具有n个数据点和样本均值x-bar的样本标准偏差s呢?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8244
8244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









