





 本文探讨了数据验证在机器学习管道中的重要性,以及如何通过自动化工具如Pandera来提高效率。Pandera提供了一个简单灵活的API,用于数据帧和系列数据的验证,支持复杂统计验证。文章还提到了其他数据验证包,如Great Expectations、Cerberus和JsonSchema,但重点介绍了Pandera的用法,包括设置必填列、处理新列、索引验证和转换DataSchema等功能。
本文探讨了数据验证在机器学习管道中的重要性,以及如何通过自动化工具如Pandera来提高效率。Pandera提供了一个简单灵活的API,用于数据帧和系列数据的验证,支持复杂统计验证。文章还提到了其他数据验证包,如Great Expectations、Cerberus和JsonSchema,但重点介绍了Pandera的用法,包括设置必填列、处理新列、索引验证和转换DataSchema等功能。
Data is called as the new oil of 21st Century. It is very important to juggle with the data to extract and use the correct information to solve our problems. Working with data can be exciting and sometimes tedious for people. As it is rightly said, “Data Scientists spend 80% of their time cleaning the data”. Being a part of that pack, I go through the same process when encountering a new dataset. The same activity is not limited to until the Machine Learning(ML) system is implemented and deployed to production. When generating predictions in real time, the data might change due to unintuitive and unforseeable circumstances like error due to human interference, wrong data submitted, a new trend in data, problem while recording data, and many more. A simple ML system with multiple steps involved looks like shown in the diagram below:
D ata被称为21世纪的新石油 。 处理数据以提取并使用正确的信息来解决我们的问题非常重要。 处理数据可能会让人感到兴奋,有时甚至很乏味。 正确地说,“数据科学家花费80%的时间来清理数据”。 作为该包的一部分,遇到新数据集时,我将经历相同的过程。 相同的活动不仅限于实施机器学习(ML)系统并将其部署到生产中。 实时生成预测时,数据可能会由于不直观和不可预见的情况而发生变化,例如由于人为干扰导致的错误,提交的错误数据,数据的新趋势,记录数据时的问题等等。 涉及多个步骤的简单ML系统如下图所示:

This needs to be slightly shifted by introducing or labeling another component explicitly, after data preparation and before feature engineering we name as Data Validation:
在数据准备之后和功能设计之前,我们需要通过显式引入或标记另一个组件来稍微改变这一点,我们将其命名为“ 数据验证” :

The article is focused on why data validation is important and how can one use different strategies to seemlessly integrate it in their pipeline. After some work, I learnt how to implement scripts that would do data validation to save some of the time. Above that, I automated them using some of the pre-built packages, stepping up my game!
本文重点讨论了为什么数据验证很重要,以及如何使用不同的策略将其无缝集成到其管道中。 经过一些工作,我学习了如何实施脚本来进行数据验证以节省一些时间。 除此之外,我使用一些预先构建的软件包使它们自动化 ,从而增强了我的游戏!
听听我的故事! (Hear my Story!)
Almost 85% of projects will not make it to production as per Gartner. Machine Learning (ML) Pipelines usually face several hiccups when pushed in production. One of the major issues I have quite often experienced is the compromise of data quality. Spending multiple hours of a day, several times a month maybe, and figuring out that the data that came through was unacceptable because of some reason can be quite relieving but frustrating at the same time. Many reasons can contribute that leads to data type getting changed like, text getting introduced instead of an integer, an integer was on outlier (probably 10 times higher) or an entire specific column was not received in the data feed, to mention a few. That is why adding this extra step is so important. Validating manually can take some extra effort and time. Making it automated(to an extent) could reduce the burden of the Data Science team. There are some major benefits I see by integrating an automated data validation in the pipeline:
根据Gartner的 说法,几乎有85%的项目不会投入生产 。 机器学习(ML)管道在投入生产时通常会遇到一些困难。 我经常遇到的主要问题之一是数据质量的妥协 。 一天要花费多个小时,一个月可能要花费数次,并且弄清由于某种原因而传递的数据是不可接受的,但同时却很令人沮丧。 导致数据类型改变的原因有很多,例如,引入文本而不是整数,整数出现异常值(可能高10倍)或未在数据Feed中收到整个特定列的情况,仅举几例。 这就是为什么添加此额外步骤如此重要的原因。 手动验证可能会花费一些额外的精力和时间。 使它自动化(在一定程度上)可以减轻数据科学团队的负担。 通过在管道中集成自动数据验证,我看到了一些主要好处:
Saves time by a couple of hours
节省几个小时的时间
Less frustration among team members
减少团队成员的挫败感
More productive by focusing on other areas
通过专注于其他领域来提高生产力
Trying to make your production model more accurate ;)
试图使您的生产模型更准确 ;)
Python community has already built some outstanding packages to take care of these issues in a very smart way. I am going to share a few of them which I have explored and how I engineered my scripts to make them part of my pipeline.
Python社区已经构建了一些出色的软件包,可以非常聪明地解决这些问题。 我将分享一些我已经探索过的内容,以及如何设计脚本使它们成为我的管道的一部分。
Data Source: I took a very recent dataset to show how one can implement these packages. Here is the link to get the data.
数据源 :我采用了一个最近的数据集来说明如何实现这些软件包。 这是获取数据的链接。
数据验证包 (Data Validation Packages)
潘德拉(Pandera): (Pandera:)
Pandera provides a very simple and flexible API for performing data validation for data frame or series data. It also helps in performing complex statistical validation like hypothesis testing like two_sample_ttest. More details about the package and usage can be found here.
Pandera提供了一个非常简单灵活的API,用于对数据帧或系列数据执行数据验证。 它还有助于执行复杂的统计验证,如诸如two_sample_ttest的假设检验 。 有关软件包和用法的更多详细信息,请参见此处 。
import pandera as pa
import pandas as pd
# Loading the data:
data = pd.read_csv('~/Downloads/train.csv', parse_dates=['Date'])
# Taking a subsample
data_sample = data.sample(n=10, random_state = 999)
# Defining the schema
schema = pa.DataFrameSchema({
"Id" : pa.Column(pa.Int, nullable=False),
"County" : pa.Column(pa.String, nullable=True),
"Province_State" : pa.Column(pa.String, nullable=True),
"Country_Region" : pa.Column(pa.String, nullable=False),
"Population" : pa.Column(pa.Int),
"Weight" : pa.Column(pa.Float),
"Date" : pa.Column(pa.DateTime),
"Target" : pa.Column(pa.String, nullable=False),
"TargetValue" : pa.Column(pa.Int)
})
# Validating the data
schema.validate(data_sample)Take a sample of 10 rows from the dataset:
从数据集中抽取10行样本:
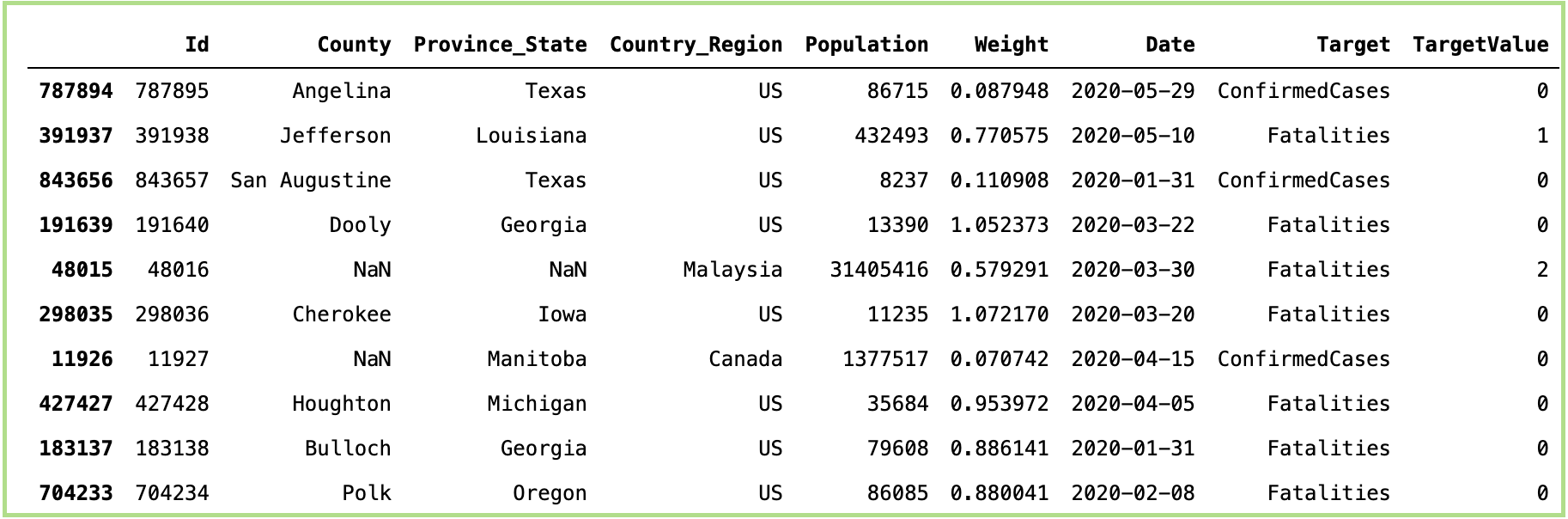
As we can see, there are multiple columns of different data types: String, Int, Float, Datetime. We need to define the schema of the data we expect. I have defined a simple schema without any strict rules for data validation checks as seen in the code above. Based on the expected data type, we can either use pa.Int for Integer, pa.String for String, pa.Float for float or pa.DateTime if there is a date and time. Here we set nullable = True if we expect NaN values else False. Moreover, if we set coerce = True, it will convert the column into the expected datatype without giving any errors. For e.g. converting float to int, int to string, etc. On validating the data, the output will the data frame itself, as it passes all the checks (try it!!!). If it fails, the output would look something like:
如我们所见,有多个不同数据类型的列:String,Int,Float,Datetime。 我们需要定义所需数据的架构 。 我已经定义了一个简单的模式,没有任何严格的数据验证检查规则,如上面的代码所示。 根据预期的数据类型,我们可以使用pa.Int 对于整数, pa.String 用于String, pa.Float 对于float或 pa.DateTime 如果有日期和时间 。 如果我们期望NaN值为False,则在此处设置nullable = True 。 而且,如果我们设置coerce = True ,它将把该列转换为期望的数据类型而不会给出任何错误。 例如,将float转换为int,将int转换为string等。在验证数据时,输出将通过所有检查(尝试!!!),从而输出数据帧本身。 如果失败,输出将类似于:
Traceback (most recent call last):
...
ValueError: cannot convert float NaN to integerThere are some amazing capabilities that I have explored about Pandera which I will try to explain with as much detail as I can.
我已经探索了有关Pandera的一些惊人功能,我将尽我所能详细解释。
设置必填列: (Setting Required Columns:)
Sometimes, columns might be optional and not required. In such a case, we can set required = False. By default required = True for all columns
有时,列可能是可选的,而不是必需的。 在这种情况下,我们可以设置required = False。 默认情况下 必需= True 对于所有列
# Defining the schema
schema = pa.DataFrameSchema({
"Id" : pa.Column(pa.Int, nullable=False, required = False),
"County" : pa.Column(pa.String, nullable=True),
"Province_State" : pa.Column(pa.String, nullable=True),
"Country_Region" : pa.Column(pa.String, nullable=False),
"Population" : pa.Column(pa.Int),
"Weight" : pa.Column(pa.Float),
"Date" : pa.Column(pa.DateTime),
"Target" : pa.Column(pa.String, nullable=False),
"TargetValue" : pa.Column(pa.Int)
})
# Dropping the Id column:
data_sample_without_id = data_sample.drop('Id', axis = 1)
# Validating the data
schema.validate(data_sample_without_id)As we see in the screenshot below, it returned data as output without any errors.
正如我们在下面的屏幕快照中看到的那样,它以无错误的形式返回了数据作为输出。

Try setting required=True for the same column and run the above code again.
尝试为同一列设置required = True ,然后再次运行上述代码。
处理新列: (Handling new columns:)
By default, if a new column is added to the data frame and not defined in the schema, no error will be raised. However, if you want to you can set strict = True.
默认情况下,如果将新列添加到数据框且未在架构中定义,则不会引发任何错误。 但是,如果您愿意,可以设置strict = True。
# Defining the schema
schema = pa.DataFrameSchema({
"Id" : pa.Column(pa.Int, nullable=False, required = False),
"County" : pa.Column(pa.String, nullable=True),
"Province_State" : pa.Column(pa.String, nullable=True),
"Country_Region" : pa.Column(pa.String, nullable=False),
"Population" : pa.Column(pa.Int),
"Weight" : pa.Column(pa.Float),
"Date" : pa.Column(pa.DateTime),
"Target" : pa.Column(pa.String, nullable=False),
"TargetValue" : pa.Column(pa.Int)
}, strict = True)
# Adding an extra column:
data_sample_without_id['extra_column'] = 0.0
# Validating the data
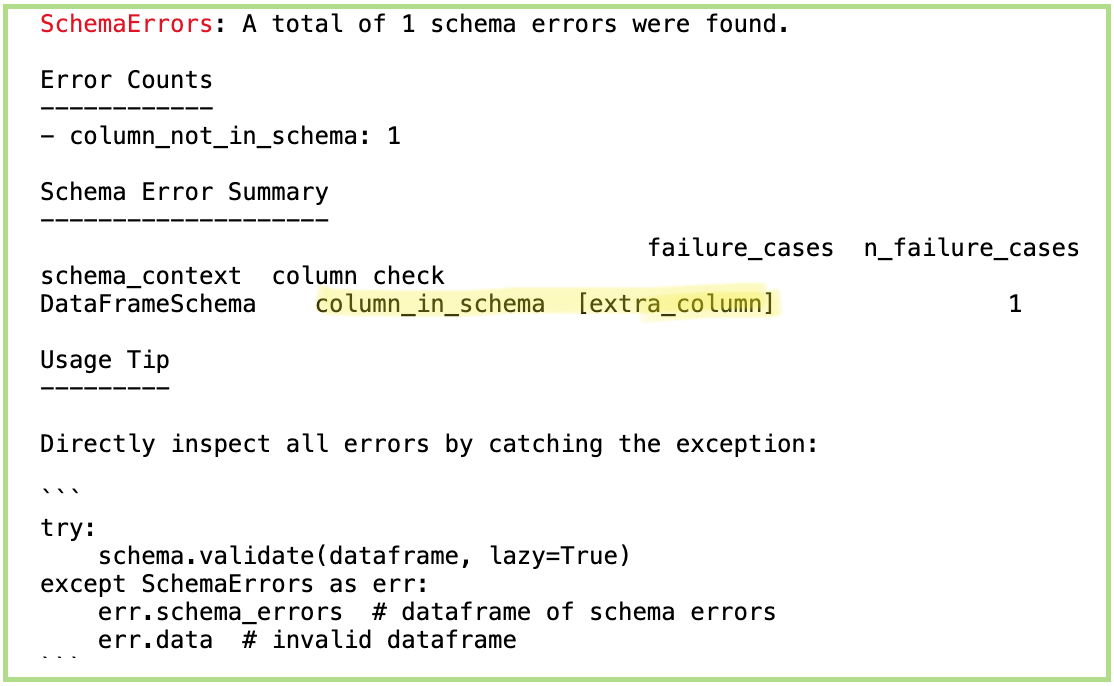
schema.validate(data_sample_without_id, lazy = True)Running the code above we see below that it throws the errors that ‘extra_column’ is not defined in the schema.
运行上面的代码,我们在下面看到,它将引发错误“ schema”中未定义的“ extra_column” 。

If you see my code, I have added lazy = True which gives a more detailed view as follows:
如果您看到我的代码,则添加了lazy = True ,它提供了更详细的视图,如下所示:
索引验证: (Index Validation:)
Index can also be validated if there is any specific pattern or holds any special importance in the dataset. For example, see below:
如果数据集中有任何特定模式或具有任何特殊重要性,也可以验证索引。 例如,请参见以下内容:
# Creating a copy and setting index:
data_sample_copy = data_sample.copy()
data_sample_copy['id_index'] = data_sample_copy['Id'].apply(lambda x: 'index_' + str(x))
data_sample_copy.set_index('id_index', inplace = True)
data_sample_copy.index.name = None
# Defining the schema
schema = pa.DataFrameSchema({
"Id" : pa.Column(pa.Int, nullable=False, required = False),
"County" : pa.Column(pa.String, nullable=True),
"Province_State" : pa.Column(pa.String, nullable=True),
"Country_Region" : pa.Column(pa.String, nullable=False),
"Population" : pa.Column(pa.Int),
"Weight" : pa.Column(pa.Float),
"Date" : pa.Column(pa.DateTime),
"Target" : pa.Column(pa.String, nullable=False),
"TargetValue" : pa.Column(pa.Int)
},
index=pa.Index(
pa.String,
pa.Check(lambda x: x.str.startswith("index_"))))
# Validating the data
schema.validate(data_sample_copy)I created and set that column as an index to show how we can do Index validation. Outside the parenthesis of the schema, one can specify the index format that is expected. Again the output is the same as before
我创建了该列并将其设置为索引,以显示我们如何进行索引验证。 在模式的括号之外,可以指定所需的索引格式。 同样,输出与之前相同

Here we performed a single index validation. MultiIndex validation can be performed in a similar way. Check out here.
在这里,我们执行了单个索引验证。 MultiIndex验证可以类似的方式执行。 在这里查看 。
DataSchema转换: (DataSchema Tranformations:)
Once we have defined the schema to validate the data, it is possible to transform the schema in the pipeline itself, after new columns have been introduced because of additional computation (which happens 100% of the time). Let’s say initially we only have Id, County, Province_State, Country_Region, Population as the columns. We add new columns Weight, Date, Target, TargetValue to the schema as follows:
一旦我们定义了模式以验证数据,就可以在管道中转换模式,因为引入了额外的计算(在100%的时间中发生),因此引入了新的列。 假设最初我们只有Id,County,Province_State,Country_Region,Population作为列。 我们向架构添加新列Weight,Date,Target,TargetValue ,如下所示:
# Defining the schema
schema = pa.DataFrameSchema({
"Id" : pa.Column(pa.Int, nullable=False, required = False),
"County" : pa.Column(pa.String, nullable=True),
"Province_State" : pa.Column(pa.String, nullable=True),
"Country_Region" : pa.Column(pa.String, nullable=False),
"Population" : pa.Column(pa.Int)
})
# Transformed schema
transformed_schema = schema.add_columns({
"Weight" : pa.Column(pa.Float),
"Date" : pa.Column(pa.DateTime),
"Target" : pa.Column(pa.String, nullable=False),
"TargetValue" : pa.Column(pa.Int)
})
# Validating the data
transformed_schema.validate(data_sample)
# Pring new schema
print(transformed_schema)On printing the schema as we show above, we get the following:
如上所示,在打印模式时,我们得到以下信息:

On the other hand, we can also remove some columns from the schema if needed as below:
另一方面,如果需要,我们还可以从模式中删除一些列 ,如下所示:
# Removing columns from the schema
transformed_remove_col_schema = transformed_schema.remove_columns(["Weight", "Population"])
# Printing the schema
print(transformed_remove_col_schema)
检查列属性: (Checking Column Properties:)
One can do a more detailed check on the column using Check object as follows:
可以使用Check对象对列进行更详细的检查,如下所示:
# Defining the schema
schema = pa.DataFrameSchema({
"Id" : pa.Column(pa.Int, nullable=False),
"County" : pa.Column(pa.String, nullable=True),
"Province_State" : pa.Column(pa.String, pa.Check(lambda s: len(s) <= 10), nullable=True),
"Country_Region" : pa.Column(pa.String, nullable=False),
"Population" : pa.Column(pa.Int, checks=pa.Check.greater_than(0)),
"Weight" : pa.Column(pa.Float),
"Date" : pa.Column(pa.DateTime, checks=pa.Check.greater_than_or_equal_to('2020-01-01')),
"Target" : pa.Column(pa.String, checks=pa.Check.isin(['ConfirmedCases','Fatalities']), nullable=False),
"TargetValue" : pa.Column(pa.Int, checks=pa.Check.less_than(4))
})
# Validating the data
schema.validate(data_sample)Pandera has some pre-built checks that can be directly used like greater_than_or_equal_to, less_than. A custom check can also be passed for e.g. here we have used lambda argument to calculate the length of the string. This is one of the best functionalities in Pandera and can bring a lot more value to the data validation strategy. Find more details here
潘特罗具有可直接使用像GREATER_THAN_OR_EQUAL_TO,LESS_THAN一些预建的检查。 还可以通过自定义检查,例如,这里我们使用了lambda参数来计算字符串的长度。 这是Pandera中最好的功能之一,可以为数据验证策略带来更多价值。 在这里找到更多详细信息
使用方式和时间: (How and when to use:)
- I create separate scripts that run and gives a report of the validation, once the final data has been received before it goes to the next step. People can integrate them as a part of pre-processing as well. 一旦收到最终数据,我将创建单独的脚本来运行并提供验证报告,然后再进行下一步。 人们也可以将它们集成为预处理的一部分。
One can also use them as decorators directly. See how here.
也可以将它们直接用作装饰器 。 看看这里如何。
Apart from using directly on a data frame, it can also be applied to a series, a specific column check, or even an element-wise check.
除了直接在数据框上使用之外,它还可以应用于序列 ,特定列检查甚至是逐元素检查 。
Because of the flexibility regex operations can also be carried out on the data using Pandera.
由于灵活性, 正则表达式操作也可以使用Pandera对数据进行。
Importantly, you would not have a perfect data validation schema right in first go. More than likely, you will make data validation schema “perfect” and ML pipeline more robust by incorporating different validation strategies as you encounter data in real time, over a long course of period.
重要的是,您一开始就不会拥有完美的数据验证架构。 在很长一段时间内实时遇到数据时,通过合并不同的验证策略,很有可能使数据验证模式“完美”和ML管道更加健壮。
其他套餐: (Other Packages:)
寄予厚望: (Great Expectations:)
As the name of the package suggests, you can set expectations for the data to be validated. Honestly, I got so comfortable with Pandera, that I have not got a chance to explore to the full potential. It seems to be quite easy to implement and straight forward package to use. Below is a small snippet of the implementation of the same data:
就像软件包名称所暗示的那样,您可以为要验证的数据设置期望值。 老实说,我对Pandera感到很满意,以至于我没有机会发掘全部潜力。 它似乎很容易实现并且直接使用了软件包。 以下是实现相同数据的一小段代码:
import great_expectations as ge
# Loading the dataset into greater expectations object:
df = ge.dataset.PandasDataset(data_sample)
# Some conditions:
df.expect_column_values_to_be_of_type(column='Id', type_ = 'String')
df.expect_column_values_to_be_of_type(column='Province_State', type_ = 'String', catch_exceptions = {'raised_exception': True})
df.expect_column_unique_value_count_to_be_between(column = 'Province_State', min_value = 0, max_value = 10)
df.expect_column_values_to_be_of_type(column='Country_Region', type_ = 'String', catch_exceptions = {'raised_exception': True})地狱犬 (Cerberus:)
This is another package whose syntax is similar to Pandera. It can be more applied when data is in a dictionary form or JSON format.
这是另一个语法与Pandera相似的软件包。 当数据采用字典形式或JSON时,可以更加应用 格式。
# Importing the package
from cerberus import Validator
# Defining the data
data_dict = {'name': 'John Doe', 'age': 50}
# Defining the schema
schema = {'name': {'type': 'string'}, 'age': {'type': 'integer', 'min': 10}}
# Initiating the validator
v = Validator(schema)
# Validating
v.validate(data_dict)More details about the package can be found here.
有关该软件包的更多详细信息,请参见此处 。
滤器: (Colander:)
This is another great package if your data is obtained via XML, JSON or HTML form post. In other words, it is beneficial to validate any type of strings, mappings, and lists type of data. Below are some of their useful links:
如果您的数据是通过XML,JSON或HTML表单发布获取的,则这是另一个很好的软件包。 换句话说,验证任何类型的字符串,映射和列表数据类型都是有益的。 以下是一些有用的链接:
Github: https://github.com/Pylons/colander
GitHub : https : //github.com/pylons/colander
Documentation: https://docs.pylonsproject.org/projects/colander/en/latest/
文档 : https : //docs.pylonsproject.org/projects/colander/zh/latest/
JsonSchema: (JsonSchema:)
JsonSchema is an implementation of JSON schema for Python. As the name suggests, this package is very helpful for validating JSON data. Take the following example with valid JSON data and invalid JSON data:
JsonSchema是Python的JSON模式的实现。 顾名思义,此包对于验证JSON数据非常有帮助。 以有效的JSON数据和无效的JSON数据为例:
# Importing the package
from jsonschema import validate
# Defining the schema
schema = {
"type" : "object",
"properties" : {
"price" : {"type" : "number"},
"name" : {"type" : "string"},
},
}
# Defining a valid data:
validate(instance={"name" : "Milk", "price" : 3.99}, schema=schema)
# Defining an invalid data:
validate(instance={"name" : "Milk", "price" : "Unknown"}, schema=schema)On running the invalid data, it will throw an error:
运行无效数据时,将引发错误:

As we can see, the price is expected to be number but string was provided rather. More details about it can be found here.
如我们所见,价格应该是数字,但是提供了字符串。 关于它的更多细节可以在这里找到。
结论: (Conclusion:)
The post might seem to be mostly dominated by Pandera, as it is one of the packages that I use often. Writing this post was purely to share the voyage I embarked on. I am sure one can benefit more from these packages for their specific use case. Often walking the extra mile can achieve extraordinary results. Data validation is definitely that “extra mile”. Developing data validation strategies might feel extra work but one can definitely benefit a lot if such a habit of creating automated scripts is formed, even for taking care of small things.
该帖子似乎主要由Pandera主导,因为它是我经常使用的软件包之一。 写这篇文章纯粹是为了分享我的旅程。 我敢肯定,对于他们的特定用例,他们可以从这些软件包中受益更多。 通常,多走一英里可达到非凡的效果。 数据验证绝对是“额外的努力”。 开发数据验证策略可能会感到额外的工作,但如果养成了养成创建自动脚本的习惯,即使是为了照顾小事情,肯定会从中受益匪浅。
Please, feel free to share your comments and suggestions if you have any!
请随时分享您的意见和建议!
翻译自: https://towardsdatascience.com/how-automated-data-validation-made-me-more-productive-7d6b396776















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









