





如何选择优化算法遗传算法
Genetic Algorithms are a family of optimisation techniques that loosely resemble evolutionary processes in nature. It may be a crude analogy, but if you squint your eyes, Darwin’s Natural Selection does roughly resemble an optimisation task where the aim is to craft organisms perfectly suited to thrive in their environments. While it may have taken many millennia for humans to develop opposable thumbs and eagles to develop 20/4 vision, in this article I will show how to implement a Genetic Algorithm in Python for “evolving” a rubbish collecting robot in a couple of hours.
遗传算法是一系列优化技术,与自然界的进化过程大致相似。 这可能是一个粗略的类比,但是如果您起眼睛,达尔文的《自然选择》确实类似于优化任务,其目的是制造出非常适合在其环境中繁衍生息的生物。 虽然人类可能需要花费数千年的时间才能开发出相对的拇指和鹰来开发20/4视觉,但在本文中,我将展示如何在Python中实现遗传算法,以在几小时内“进化”垃圾收集机器人。
背景 (Background)
The best example I’ve come across to demonstrate how Genetic Algorithms work comes from a fantastic book on complex systems by Melanie Mitchell called “Complexity: A Guided Tour” (highly recommended). In one chapter, Mitchell introduces a robot named Robby whose sole purpose in life is to pick up rubbish and describes how to optimise a control strategy for Robby using a GA. Below I will explain my approach to solving this problem and show how to implement the algorithm in Python. There are some great packages for constructing these kinds of algorithms (such as DEAP) but in this tutorial, I will only be using base Python, Numpy and TQDM (optional).
我碰到的最好的例子演示了遗传算法的工作原理,这是梅拉妮·米切尔(Melanie Mitchell)撰写的一本关于复杂系统的出色著作,名为“复杂性:导览”(强烈推荐)。 在一个章节中,米切尔介绍了一个名为Robby的机器人,该机器人的唯一目的是捡拾垃圾,并描述了如何使用GA优化Robby的控制策略。 下面,我将解释解决此问题的方法,并展示如何在Python中实现该算法。 有一些很棒的软件包可用于构建这类算法(例如DEAP ),但是在本教程中,我将仅使用基本的Python,Numpy和TQDM(可选)。
While this is only a toy example, GAs are used in a number of real-world applications. As a data scientist, I most often use them for hyper-parameter optimisation and model choice. While they can be computationally expensive, GAs allow us to explore multiple areas of a search space in parallel and are a good option when computing a gradient is difficult.
尽管这只是一个玩具示例,但GA已在许多实际应用中使用。 作为数据科学家,我经常将它们用于超参数优化和模型选择。 尽管它们的计算成本可能很高,但GA允许我们并行探索搜索空间的多个区域,当难以计算梯度时,它们是一个不错的选择。
问题描述 (Problem Description)
A robot named Robby lives in a two-dimensional grid world full of rubbish and surrounded by 4 walls (shown below). The aim of this project is to evolve an optimal control strategy for Robby that will allow him to pick up rubbish efficiently and not crash into walls.
名为Robby的机器人生活在一个充满垃圾的二维网格世界中,周围环绕着4面墙(如下所示)。 该项目的目的是为Robby制定最佳的控制策略,使他能够有效地捡拾垃圾而不撞墙。

Robby can only see the four squares NESW of himself as well as the square he is in and there are 3 options for each square; it can be empty, have rubbish in it or be a wall. Therefore there are 3⁵ = 243 different scenarios Robby can be in. Robby can perform 7 different actions; move NESW, move randomly, pickup rubbish or stay still. Robby’s control strategy can therefore be encoded as a “DNA” string of 243 digits between 0 and 6 (corresponding to the action Robby should take in each of the 243 possible situations).
罗比只能看到他自己的四个NESW以及他所在的正方形,每个正方形有3个选项; 它可以是空的,里面有垃圾或可以是墙壁。 因此,Robby可能有3种= 243种不同的场景。Robby可以执行7种不同的动作; 移动NESW,随机移动,捡垃圾或保持静止。 因此,Robby的控制策略可以被编码为0到6之间的243位数的“ DNA”字符串(对应于Robby在243种可能的情况下应采取的措施)。
方法 (Approach)
At a high level, the steps for optimisation with any GA are:
从总体上讲,使用任何GA进行优化的步骤如下:
- An initial “population” of random solutions to a problem are generated 生成问题的随机解决方案的初始“填充”
- The “fitness” of each individual is assessed based on how well it solves the problem 根据每个人解决问题的能力来评估每个人的“适应性”
- The fittest solutions “reproduce” and pass on “genetic” material to offspring in the next generation 最合适的解决方案“繁殖”并“遗传”材料传给下一代
- Repeat steps 2 and 3 until we are left with a population of optimised solutions 重复步骤2和3,直到剩下优化解决方案为止
For our task, you create a first generation of Robbys initialised to random DNA strings (corresponding to random control strategies). You then simulate letting these robots run around in randomly assigned grid worlds and see how they perform.
对于我们的任务,您将创建初始化为随机DNA字符串(对应于随机控制策略)的第一代Robby。 然后,您可以模拟这些机器人在随机分配的网格世界中运行,并观察它们的性能。
适合度 (Fitness)
A robot’s fitness is a function of how many pieces of rubbish it picked up in n moves and how many times it crashed into a wall. In our example, we award 10 points to a robot for every piece of rubbish picked up and subtract 5 points every time it crashes into a wall. The robots then “mate” with probabilities linked to their fitness score (i.e. robots that picked up lots of rubbish are more likely to reproduce) and a new generation is created.
机器人的适应性取决于它在n步中捡起多少垃圾以及撞到墙壁的次数。 在我们的示例中,对于每捡起的垃圾,我们会为机器人奖励10分,每次撞到墙壁时,机器人都会减去5分。 然后,机器人将与其适应度得分相关联的概率“配对”(即,捡拾大量垃圾的机器人更有可能繁殖),并创造了新一代。
交配 (Mating)
There are a few different ways that “mating” can be implemented. In Mitchell’s version she took the 2 parent DNA strings, randomly spliced them and then joined them together to create a child for the next generation. In my implementation, I assigned each gene probabilistically from each parent (i.e. for each of the 243 genes, I flip a coin to decide which parent will pass on their gene). For example, here are the first 10 genes of 2 parents and a possible child using my method:
有几种不同的方法可以实现“匹配”。 在米切尔(Mitchell)的版本中,她采用了2个父DNA字符串,随机拼接它们,然后将它们结合在一起,为下一代创造了一个孩子。 在我的实现中,我按概率从每个亲本中分配了每个基因(即,对于243个基因中的每个基因,我掷硬币决定哪一个亲本将通过其基因)。 例如,以下是使用我的方法的2个父母和一个可能的孩子的前10个基因:
Parent 1: 1440623161
Parent 2: 2430661132
Child: 2440621161突变 (Mutation)
Another concept from natural selection that we replicate with this algorithm is that of “mutation”. While the vast majority of genes in a child will be passed down from a parent, I have also built in a small possibility that the gene will mutate (i.e. will be assigned at random). This mutation rate gives us the ability to control the trade-off between exploration and exploitation.
我们使用该算法复制的自然选择的另一个概念是“变异”。 虽然孩子中的绝大多数基因会从父母那里遗传下来,但我也认为基因突变的可能性很小(即随机分配)。 这种突变率使我们能够控制勘探与开发之间的权衡。
Python实现 (Python Implementation)
The first step is to import the required packages and set our parameters for this task. I have chosen these parameters as a starting point, but they can be adjusted and I encourage you to experiment with them.
第一步是导入所需的程序包并为此任务设置参数。 我选择了这些参数作为起点,但是可以对其进行调整,建议您尝试一下。
"""
Import Packages
"""
import numpy as np
from tqdm.notebook import tqdm
"""
Set Parameters
"""
# Simulation Settings
pop_size = 200 # number of robots per generation
num_breeders = 100 # number of robots who can mate in each generation
num_gen = 400 # total number of generations
iter_per_sim = 100 # number of rubbish-collection simulations per robot
moves_per_iter = 200 # number of moves robot can make per simulation
# Grid Settings
rubbish_prob = 0.5 # probability of rubbish in each grid square
grid_size = 10 # size of grid (excluding walls)
# Evolution Settings
wall_penalty = -5 # fitness points deducted for crashing into wall
no_rub_penalty = -1 # fitness points deducted for trying to pickup rubbish in empty square
rubbish_score = 10 # fitness points awarded for picking up rubbish
mutation_rate = 0.01 # probability of a gene mutatingNext, we define a class for the grid-world environment. We represent each cell by the tokens ‘o’, ‘x’ and ‘w’ corresponding to an empty cell, a cell with rubbish and a wall respectively.
接下来,我们为网格世界环境定义一个类。 我们用标记“ o”,“ x”和“ w”表示每个单元,分别对应一个空单元,一个带有垃圾的单元和一个壁。
class Environment:
"""
Class for representing a grid environment full of rubbish. Each cell can be:
'o': empty
'x': rubbish
'w': wall
"""
def __init__(self, p=rubbish_prob, g_size=grid_size):
self.p = p # probability of a cell being rubbish
self.g_size = g_size # excluding walls
# initialise grid and randomly allocate rubbish
self.grid = np.random.choice(['o','x'], size=(self.g_size+2,self.g_size+2), p=(1 - self.p, self.p))
# set exterior squares to be walls
self.grid[:,[0,self.g_size+1]] = 'w'
self.grid[[0,self.g_size+1], :] = 'w'
def show_grid(self):
# print the grid in current state
print(self.grid)
def remove_rubbish(self,i,j):
# remove rubbish from specified cell (i,j)
if self.grid[i,j] == 'o': # cell already empty
return False
else:
self.grid[i,j] = 'o'
return True
def get_pos_string(self,i,j):
# return a string representing the cells "visible" to a robot in cell (i,j)
return self.grid[i-1,j] + self.grid[i,j+1] + self.grid[i+1,j] + self.grid[i,j-1] + self.grid[i,j]Next, we create a class to represent our robots. This class includes methods for performing actions, calculating fitness and generating new DNA from a pair of parent robots.
接下来,我们创建一个代表机器人的类。 该课程包括执行动作,计算适应性以及从一对父机器人生成新DNA的方法。
class Robot:
"""
Class for representing a rubbish-collecting robot
"""
def __init__(self, p1_dna=None, p2_dna=None, m_rate=mutation_rate, w_pen=wall_penalty, nr_pen=no_rub_penalty, r_score=rubbish_score):
self.m_rate = m_rate # mutation rate
self.wall_penalty = w_pen # penalty for crashing into a wall
self.no_rub_penalty = nr_pen # penalty for picking up rubbish in empty cell
self.rubbish_score = r_score # reward for picking up rubbish
self.p1_dna = p1_dna # parent 1 DNA
self.p2_dna = p2_dna # parent 2 DNA
# generate dict to lookup gene index from situation string
con = ['w','o','x'] # wall, empty, rubbish
self.situ_dict = dict()
count = 0
for up in con:
for right in con:
for down in con:
for left in con:
for pos in con:
self.situ_dict[up+right+down+left+pos] = count
count += 1
# initialise dna
self.get_dna()
def get_dna(self):
# initialise dna string for robot
if self.p1_dna is None:
# when no parents (first gen) initialise to random string
self.dna = ''.join([str(x) for x in np.random.randint(7,size=243)])
else:
self.dna = self.mix_dna()
def mix_dna(self):
# generate robot dna from parents
mix_dna = ''.join([np.random.choice([self.p1_dna,self.p2_dna])[i] for i in range(243)])
#add mutations
for i in range(243):
if np.random.rand() > 1 - self.m_rate:
mix_dna = mix_dna[:i] + str(np.random.randint(7)) + mix_dna[i+1:]
return mix_dna
def simulate(self, n_iterations, n_moves, debug=False):
# simulate rubbish collection
tot_score = 0
for it in range(n_iterations):
self.score = 0 # fitness score
self.envir = Environment()
self.i, self.j = np.random.randint(1,self.envir.g_size+1, size=2) # randomly allocate starting position
if debug:
print('before')
print('start position:',self.i, self.j)
self.envir.show_grid()
for move in range(n_moves):
self.act()
tot_score += self.score
if debug:
print('after')
print('end position:',self.i, self.j)
self.envir.show_grid()
print('score:',self.score)
return tot_score / n_iterations # average fitness score across n iterations
def act(self):
# perform action based on DNA and robot situation
post_str = self.envir.get_pos_string(self.i, self.j) # robot's current situation
gene_idx = self.situ_dict[post_str] # relevant idx of DNA for current situation
act_key = self.dna[gene_idx] # read action from idx of DNA
if act_key == '5':
# move randomly
act_key = np.random.choice(['0','1','2','3'])
if act_key == '0':
self.mv_up()
elif act_key == '1':
self.mv_right()
elif act_key == '2':
self.mv_down()
elif act_key == '3':
self.mv_left()
elif act_key == '6':
self.pickup()
def mv_up(self):
# move up one square
if self.i == 1:
self.score += self.wall_penalty
else:
self.i -= 1
def mv_right(self):
# move right one square
if self.j == self.envir.g_size:
self.score += self.wall_penalty
else:
self.j += 1
def mv_down(self):
# move down one square
if self.i == self.envir.g_size:
self.score += self.wall_penalty
else:
self.i += 1
def mv_left(self):
# move left one square
if self.j == 1:
self.score += self.wall_penalty
else:
self.j -= 1
def pickup(self):
# pickup rubbish
success = self.envir.remove_rubbish(self.i, self.j)
if success:
# rubbish successfully picked up
self.score += self.rubbish_score
else:
# no rubbish in current square
self.score += self.no_rub_penaltyFinally it’s time to run the Genetic Algorithm. In the code below we generate an initial population of robots and let Natural Selection run its course. I should mention that there are certainly much faster ways to implement this algorithm (e.g. utilising parallelisation) but for the purpose of this tutorial I have sacrificed speed for clarity.
最后是时候运行遗传算法了。 在下面的代码中,我们生成了机器人的初始填充,然后让Natural Selection运行其过程。 我应该提到,当然有更快的方法来实现该算法(例如,利用并行化),但是出于本教程的目的,我为了清晰起见而牺牲了速度。
# initial population
pop = [Robot() for x in range(pop_size)]
results = []
# run evolution
for i in tqdm(range(num_gen)):
scores = np.zeros(pop_size)
# iterate through all robots
for idx, rob in enumerate(pop):
# run rubbish collection simulation and calculate fitness
score = rob.simulate(iter_per_sim, moves_per_iter)
scores[idx] = score
results.append([scores.mean(),scores.max()]) # save mean and max scores for each generation
best_robot = pop[scores.argmax()] # save the best robot
# limit robots who are able to mate to top num_breeders
inds = np.argpartition(scores, -num_breeders)[-num_breeders:] # get indices of top robots based on fitness
subpop = []
for idx in inds:
subpop.append(pop[idx])
scores = scores[inds]
# square and normalise fitness scores
norm_scores = (scores - scores.min()) ** 2
norm_scores = norm_scores / norm_scores.sum()
# create next generation of robots
new_pop = []
for child in range(pop_size):
# choose parents with probability proportionate to squared fitness scores
p1, p2 = np.random.choice(subpop, p=norm_scores, size=2, replace=False)
new_pop.append(Robot(p1.dna, p2.dna))
pop = new_popWhile initially most of the robots pick up no rubbish and consistently crash into walls, within a few generations we start to see simple strategies (such as “if in square with rubbish, pick it up” and “if next to wall, don’t move into wall”) propagate through the population. After a few hundred iterations, we are left with a generation of incredible rubbish-collecting geniuses!
最初,大多数机器人没有捡拾垃圾,并且始终撞到墙壁上,但在几代人之后,我们开始看到简单的策略(例如“如果与垃圾成一直线,捡拾垃圾”和“如果靠近墙壁,不要捡垃圾”)。进入墙壁”)在人群中传播。 经过几百次迭代,我们剩下了一代令人难以置信的垃圾收集天才!
结果 (Results)
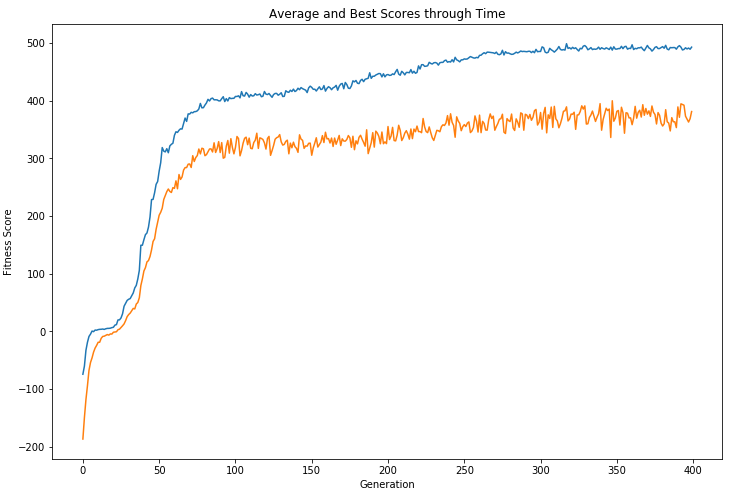
The plot below shows that we were able to “evolve” a successful rubbish collection strategy in 400 generations.
下图显示了我们能够在400代内“演变”成功的垃圾收集策略。
To assess the quality of the evolved control strategy, I manually created a benchmark strategy with some intuitively sensible rules:
为了评估改进的控制策略的质量,我手动创建了一些具有直观意义的规则的基准策略:
- If rubbish is in current square, pick it up 如果垃圾在当前方块中,请捡起
- If rubbish is visible in an adjacent square, move to that square 如果在相邻的正方形中可见垃圾,请移至该正方形
- If next to a wall, move in the opposite direction 如果靠近墙壁,请朝相反方向移动
- Else, move in a random direction 否则,朝随机方向移动
On average, this benchmark strategy achieved a fitness score of 426.9 but this was no match for our final “evolved” robot which had an average fitness score of 475.9.
平均而言,该基准策略的适应度得分为426.9,但这与我们最终的“进化”机器人的平均适应度得分为475.9并不匹配。
策略分析 (Strategy Analysis)
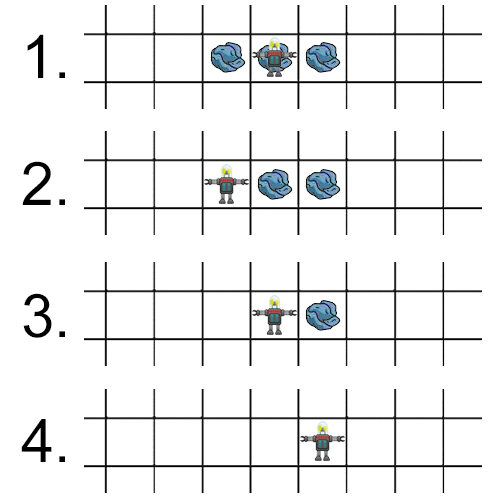
One of the coolest things about this approach to optimisation is that you can find counter-intuitive solutions. Not only were the robots able to learn sensible rules that a human might design, they also spontaneously came up with strategies that humans might never consider. One sophisticated technique that emerged was the use of “markers” to overcome short-sightedness and a lack of memory. For example, if a robot is currently in a square with rubbish in it and can see rubbish in the squares to the east and west, a naive approach would be to immediately pickup the rubbish in the current square and then move to one of the adjacent squares. The problem with this strategy is that once the robot has moved (say to the west), he has no way of remembering that there is rubbish 2 squares to the east. To overcome this problem, we observed our evolved robots performing the following steps:
关于这种优化方法的最酷的事情之一是,您可以找到违反直觉的解决方案。 机器人不仅能够学习人类可能设计的明智规则,而且还自发提出了人类可能永远不会考虑的策略。 一种新兴的先进技术是使用“标记”来克服近视和缺乏记忆。 例如,如果一个机器人当前在一个有垃圾的正方形中并且可以看到东西方的正方形中的垃圾,那么幼稚的方法是立即在当前正方形中拾取垃圾,然后移到相邻的一个正方形中。方块。 这种策略的问题在于,一旦机器人移动(例如向西移动),他就无法记住东边有2个正方形的垃圾。 为了克服这个问题,我们观察了我们进化的机器人执行以下步骤:
- move to the west (leave the rubbish in the current square as a marker) 向西移动(将垃圾放在当前广场中作为标记)
- pick up the rubbish and move back to the east (it can see the rubbish left as a marker) 捡起垃圾并向东移动(可以看到垃圾作为标记)
- pick up the rubbish and move to the east 捡起垃圾,然后移到东方
- pick up the final piece of rubbish 捡起最后一块垃圾
Another example of counter-intuitive strategies emerging from this kind of optimisation is shown below. OpenAI taught agents to play hide and seek using reinforcement learning (a more sophisticated optimisation approach). We see that the agents learn “human” strategies at first but eventually learn novel solutions such as “Box Surfing” that exploit the physics of OpenAI’s simulated environment.
这种优化产生的反直觉策略的另一个示例如下所示。 OpenAI教给代理商使用强化学习(一种更复杂的优化方法)玩捉迷藏的游戏。 我们看到代理首先学习“人性化”策略,但最终学习了新颖的解决方案,例如“盒式冲浪”,它们利用了OpenAI模拟环境的物理特性。
结论 (Conclusion)
Genetic Algorithms combine biology and computer science in a unique way and while not necessarily the fastest algorithms, in my opinion they are among the most beautiful. All of the code featured in this article is available on my Github along with a demo notebook. Thanks for reading!
遗传算法以独特的方式结合了生物学和计算机科学,虽然不一定是最快的算法,但我认为它们是最漂亮的算法之一。 我的Github和演示笔记本都提供了本文中介绍的所有代码。 谢谢阅读!
如何选择优化算法遗传算法















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}