





数据挖掘流程
1-简介 (1- Introduction)
The fact that the pace of technological change is at its peak, Silicon Valley is also introducing new challenges that need to be tackled via new and efficient ways. Continuous research is being carried out to improve the existing tools, techniques, and algorithms to maximize their efficiency. Streaming data has always remained a challenge since the last decades, nevertheless plenty of stream-based algorithms have been introduced but still, the researchers are struggling to achieve better results and performance. As you know that, when water from a fire hose starts hitting your face, chances to measure it starts decreasing gradually. This is due to the torrent nature of streams. It has introduced new challenges of analyzing and mining the streams efficiently. Stream analysis has been made easy up to some extent because of a few new tools that are introduced in the market recently. These tools are following different approaches and algorithms which are being improved continuously. However, when it comes to mining data streams, it is not possible to store and iterate over the streams like traditional mining algorithms due to their continuous, high-speed, and unbounded nature.
技术变革的步伐达到顶峰这一事实,硅谷也带来了新的挑战,需要通过新的有效方式来应对。 正在进行持续的研究以改进现有的工具,技术和算法,以使其效率最大化。 自从过去的几十年以来,流数据一直是一个挑战,尽管引入了很多基于流的算法,但是研究人员仍在努力获得更好的结果和性能。 如您所知,当消防水带上的水开始溅到您的脸上时,测量水的机会开始逐渐减少。 这是由于流的洪流性质。 它带来了有效分析和挖掘流的新挑战。 由于最近市场上引入了一些新工具,因此在某种程度上简化了流分析。 这些工具采用了不同的方法和算法,并不断得到改进。 但是,在挖掘数据流时,由于其连续,高速且无限制的特性,因此无法像传统的挖掘算法一样在数据流上进行存储和迭代。
Due to irregularity and variation in the arriving data, memory management has become the main challenge to deal with. Applications like sensor networks cannot afford mining algorithms with high memory cost. Similarly, time management, data preprocessing techniques, and choice of the data structure are also considered as some of the main challenges in the stream mining algorithms. Therefore, summarization techniques derived from the statistical science are dealing with a challenge of memory limitation, and techniques of the computational theory are being used to improve the time and space-efficient algorithms. Another challenge is the consumption of available resources, to cope with this challenge resource-aware mining is introduced which makes sure that the algorithm always consumes the available resources with some consideration.
由于到达数据的不规则性和变化,内存管理已成为要处理的主要挑战。 像传感器网络这样的应用程序无法承受具有高存储成本的挖掘算法。 同样,时间管理,数据预处理技术和数据结构的选择也被视为流挖掘算法中的一些主要挑战。 因此,源自统计科学的摘要技术正在应对内存限制的挑战,并且使用计算理论的技术来改进时间和空间效率高的算法。 另一个挑战是可用资源的消耗,为了应对这一挑战,引入了资源感知挖掘,以确保算法始终在考虑某些因素的情况下消耗可用资源。
As data stream is seen only once therefore it requires mining in a single pass, for this purpose an extremely fast algorithm is required to avoid problems like data sampling and shredding. Such algorithms should be able to run with data streams in parallel settings partitioned to many distributed processing units. Infinite data streams with high volumes are produced by many online, offline real-time applications and systems. The update rate of data streams is time-dependent. Therefore to extract knowledge from streaming data, some special mechanism is required. Due to their high volume and speed, some special mechanism is required to extract knowledge from them.
由于只能看到一次数据流,因此需要单次挖掘,为此,需要一种非常快速的算法来避免数据采样和粉碎等问题。 这样的算法应该能够与并行设置为多个分布式处理单元的数据流一起运行。 许多在线,离线实时应用程序和系统都会产生大量的无限数据流。 数据流的更新速率取决于时间。 因此,要从流数据中提取知识,需要一些特殊的机制。 由于它们的高容量和高速度,需要一些特殊的机制来从它们中提取知识。
Many stream mining algorithms have been developed and proposed by machine learning, statistical and theoretical computer science communities. The question is, how should we know which algorithm is best in terms of dealing with current challenges as mentioned above, and what is still needed in the market? This document intends to answer these questions. As this research topic is quite vast therefore deciding the best algorithm is not quite straightforward. We have compared the most recently published versions of stream mining algorithms in our distribution which are classification, clustering, and frequent itemset mining. Frequent itemset mining is a category of algorithms used to find the statistics about streaming data.
机器学习,统计和理论计算机科学界已经开发和提出了许多流挖掘算法。 问题是,就如何应对上述当前挑战而言,我们如何知道哪种算法最好,而市场仍需要什么呢? 本文档旨在回答这些问题。 由于这个研究主题非常广泛,因此确定最佳算法并不是一件容易的事。 我们比较了我们发行版中最新发布的流挖掘算法版本,它们是分类,聚类和频繁项集挖掘。 频繁项集挖掘是用于查找有关流数据的统计信息的一种算法。
2-分类 (2- Classification)
The classification task is to decide the proper label for any given record from a dataset. It is a part of Supervised learning. The way of the learning works is to have the algorithm learn patterns and important features from a set of labeled data or ground truths resulting in a model. This model will be utilized in the classification tasks. There are various metrics used to rate the performance of a model. For example, Accuracy, in which the focus of this metric is to maximize the number of correct labels. There is also, Specificity in which the focus is to minimize mislabelling negative class. There are few factors that are crucial to deciding which metrics are to be used in classification tasks, such as label distributions and the purpose of the task itself.
分类任务是为数据集中的任何给定记录确定适当的标签。 它是监督学习的一部分。 学习工作的方式是让算法从一组标记数据或模型得出的基础事实中学习模式和重要特征。 该模型将用于分类任务。 有多种指标可用于评估模型的性能。 例如,准确性,此度量标准的重点是最大化正确标签的数量。 在“特异性”中,重点是最大程度地减少标签错误的负面类别。 对于决定在分类任务中使用哪些度量至关重要的因素很少,例如标签分布和任务本身的目的。
There are also a few types in the Classification Algorithm, such as Decision Trees, Logistic Regression, Neural Networks, and Naive Bayes. In this work, we decide to focus on Decision Tree.
分类算法中也有几种类型,例如决策树,逻辑回归,神经网络和朴素贝叶斯。 在这项工作中,我们决定专注于决策树。
In Decision Tree, the learning algorithm will construct a tree-like model in which the node is a splitting attribute and the leaf is the predicted label. For every item, the decision tree will sort such items according to the splitting attribute down to the leaf which contained the predicted label.
在决策树中,学习算法将构建一个树状模型,其中节点是拆分属性,叶是预测标签。 对于每个项目,决策树将根据拆分属性将这些项目分类到包含预测标签的叶子。
2.1 Hoeffding树 (2.1 Hoeffding Trees)
Currently, Decision Tree Algorithms such as ID3 and C4.5 build the trees from large amounts of data by recursively select the best attribute to be split using various metrics such as Entropy Information Gain and GINI. However, existing algorithms are not suitable when the training data cannot be fitted to the memory.
当前,诸如ID3和C4.5之类的决策树算法通过使用诸如熵信息增益和GINI之类的各种度量来递归选择要分割的最佳属性,从而从大量数据中构建树。 但是,当训练数据无法拟合到存储器中时,现有算法不适合。
There exist few incremental learning methods in which the learning system, instead of fitting the entire data-sets at once in memory, continuously learning from the stream of data. However, it is found that those model lack of correctness guarantee compared to batch learning for the same amount of the data.
很少有增量学习方法,其中学习系统不是从内存中一次拟合整个数据集,而是从数据流中不断学习。 但是,发现对于相同数量的数据,与批处理学习相比,这些模型缺乏正确性保证。
Domingos and Hulten [1] formulated a decision tree algorithm called the Hoeffding Tree. With Hoeffding Tree, the record or training instance itself is not saved in the memory, only the tree nodes and statistics are stored. Furthermore, the most interesting property of this tree is that the correctness of this tree converges to trees built using a batch learning algorithm given sufficient massive data.
Domingos和Hulten [1]制定了一种决策树算法,称为Hoeffding树。 使用霍夫丁树,记录或训练实例本身不会保存在内存中,仅存储树节点和统计信息。 此外,该树的最有趣的属性是,在给定足够的大量数据的情况下,该树的正确性收敛到使用批处理学习算法构建的树。
The training method for this tree is simple. For each sample, sort it to the subsequent leaf and update its statistic.
这棵树的训练方法很简单。 对于每个样本,将其排序到随后的叶子并更新其统计信息。
There are two conditions that must be fulfilled in order for a leaf to be split
为了分裂叶子,必须满足两个条件
1. There exists impurity in the leaf node. That is, not every record that is stored on the leaf has the same class.
1.叶节点中存在杂质。 即,并非每个存储在叶子上的记录都具有相同的类。
2. The difference of the result of the evaluation function between the best attribute and second-best attribute denoted ∆G is greater than E, where E is
2.最佳属性和次佳属性之间的评估函数结果之差表示为∆ G大于E ,其中E为
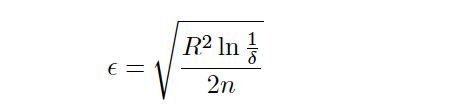
Where R is the range of the attribute, δ (provided by the user) is the desired probability of the sample not within E and n is the number of collected samples in that node.
其中R是属性的范围, δ (由用户提供)是不在E内的样本的期望概率, n是在该节点中收集的样本数。
In the paper, it is rigorously proven that the error of this tree is bounded by Hoeffding Inequality. Another excellent property of this tree is that even though we reduce the error rate exponentially, we only need to increase the sample size linearly.
在本文中,严格证明了该树的错误受Hoeffding不等式的限制。 该树的另一个出色特性是,即使我们以指数方式减少错误率,我们也只需要线性增加样本大小。
2.2 VFDT算法 (2.2 VFDT Algorithm)
Domingos and Hutten further introduced a refinement of Hoeffding Tree called VFDT (Very Fast Decision Tree). The main idea is the same as Hoeffding Tree.
Domingos和Hutten进一步介绍了Hoeffding树的改进,称为VFDT(超快速决策树)。 主要思想与霍夫丁树相同。
The refinements are
细化是
•Ties VFDT introduced an extra parameter τ. It is used when the delta between the best and the second-best attribute is too similar
• 领带 VFDT引入了额外的参数τ 。 当最佳属性和次佳属性之间的差值太相似时使用
•G computation Another parameter introduced is nmin, which denotes the minimum number of samples before G is recomputed. That means the computation of the G can be deferred instead of every time a new sample arrives, which reduces global times resulted from frequents calculation of G
• G计算引入的另一个参数是nmin ,它表示重新计算G之前的最小样本数。 这意味着可以推迟G的计算,而不是每次到达新样本时都进行延迟,这减少了由于频繁计算G而导致的全局时间
•Memory VFDT introduces a mechanism of pruning the least promising leaf from the Tree whenever the maximum available memory already utilized. The criterion used to determine whether a leaf is to be prune is the product of the probability of a random example that will go to it denoted as pl and its observed error rate el. The leaf with the lowest that criteria value will be considered as the least promising and will be deactivated.
• 内存 VFDT引入了一种机制,只要已利用了最大的可用内存,就会从Tree中修剪掉前景最差的叶子。 用于确定是否要修剪叶子的标准是将要出现在叶子上的随机示例的概率乘以p1并观察到的错误率el的乘积。 具有最低标准值的叶子将被认为是最没有希望的叶子,并将被停用。
•Dropping Poor Attributes Another approach to have a performance boost is to drop attributes that are considered not promising early. If the difference of its evaluation function value between an attribute with the best attribute is bigger than E, then that attribute can be dropped. However, the paper doesn’t explain what is the exact parameter or situation for an attribute to be dropped.
• 删除较差的属性提高性能的另一种方法是删除被认为不尽早实现的属性。 如果具有最佳属性的属性之间的评估函数值之差大于E ,则可以删除该属性。 但是,本文没有说明要删除的属性的确切参数或情况是什么。
•Initialization The VFDT can be bootstrapped and combined by an existing memory-based decision tree to allow the VFDT to accomplish the same accuracy with a smaller number of examples. No detailed algorithm is provided, however.
• 初始化 VFDT可以通过现有的基于内存的决策树进行引导和合并,以使VFDT能够以更少的示例数实现相同的精度。 但是,没有提供详细的算法。
2.3 Hoeffding自适应树 (2.3 Hoeffding Adaptive Trees)
One of the fallacies in Data Mining is the assumption that the distribution of data remains stationary. This is not the case, consider data from a kind of supermarket retails, the data can change rapidly in each different season. Such a phenomenon is called concept drift.
数据挖掘的谬论之一是假设数据分布保持平稳。 情况并非如此,考虑到一种超市零售的数据,该数据在每个不同的季节都会快速变化。 这种现象称为概念漂移 。
As a solution, Bifet et al [2] proposed a sliding window and adaptively based enhancements to Hoeffding Tree. Furthermore, the algorithm to build such a tree is based on the authors’ previous work, ADWIN (Adaptive Windowing) Algorithm which is a parameter-free algorithm to detect and estimates changes in Data Stream.
作为解决方案,Bifet等人[2]提出了一个滑动窗口和对Hoeffding树的自适应增强。 此外,构建此类树的算法基于作者先前的工作,即ADWIN(自适应窗口)算法,它是一种无参数算法,可检测和估计数据流中的变化。
In building adaptive learning algorithm, needs to be able to decides these three things
在建立自适应学习算法时,需要能够决定这三件事
• What are things that need to be remembered?
•需要记住哪些事情?
• When is the correct time to upgrade the model?
• 什么时候升级模型?
• How to upgrade the model?
• 如何升级模型?
Therefore there is a need for a procedure that is able to predict and detect changes in Data Distribution. In this case, is served by ADWIN algorithm mentioned before.
因此,需要一种能够预测和检测数据分布变化的过程。 在这种情况下,由前面提到的ADWIN算法提供服务。
The main idea of Hoeffding Adaptive Tree is that aside from the main tree, alternative trees are created as well. Those alternative trees are created when distribution changes are detected in the data stream immediately. Furthermore, the alternate tree will replace the main tree when it is evidence that the alternate tree is far more accurate than the main tree. Ultimately, the changing and adaptation of trees are happening automatically judged from the time and nature of data instead of prior knowledge by the user. Note that, having said that it still retains in principle the algorithm to build and split the tree according to Hoeffding bound, similar to VFDT.
Hoeffding自适应树的主要思想是,除了主树之外,还创建替代树。 当立即在数据流中检测到分布更改时,将创建这些备用树。 此外,当有证据表明备用树比主树准确得多时,备用树将替换主树。 最终,树木的改变和适应是根据数据的时间和性质自动判断的,而不是用户的先验知识。 注意,尽管如此,它仍然保留了类似于Hoofding边界的树的构建和分割算法,类似于VFDT。
In experiments, the authors mainly compared the Hoeffding Adaptive Tree with CVFDT (Concept Adapting Very Fast Decision Tree). CVFDT itself is formulated by the same authors of VFDT, it is basically VFDT with an attempt to include concept drift. In terms of performance measured with an error rate, using a synthetically generated dataset with a massive concept change, the algorithm managed to achieve a lower error rate quickly compared to CVFDT i.e. faster adaption to other trees. In addition, it managed to lower memory consumption by half. However, the drawback is that this algorithm consumes the longest time, 4 times larger than CVFDT.
在实验中,作者主要将Hoeffding自适应树与CVFDT(概念自适应非常快决策树)进行了比较。 CVFDT本身由VFDT的相同作者制定,基本上是VFDT,试图包括概念漂移。 就以错误率衡量的性能而言,使用具有重大概念变化的综合生成的数据集,该算法设法比CVFDT更快地实现了更低的错误率,即更快地适应了其他树。 另外,它设法将内存消耗降低了一半。 但是,缺点是该算法耗时最长,是CVFDT的4倍。
3聚类 (3 Clustering)
Clustering is to partition a given set of objects into groups called clusters in a way that each group have similar kind of objects and is strictly different from other groups. Classifying objects into groups of similar objects with a goal of simplifying data so that a cluster can be replaced by one or few representatives is considered as a core of the clustering process. Clustering algorithms are considered as tools to cluster high volumes datasets. We have selected three latest clustering algorithms and compared them with others based on a performance metric i.e. efficient creation of clusters, the capability to handle a large number of clusters, and the chosen data structure.
聚类是将一组给定的对象划分为称为聚类的组,其方式是每个组具有相似的对象类型,并且与其他组完全不同。 为了简化数据,将对象分为相似对象的组,以便可以用一个或几个代表替换群集,这被认为是群集过程的核心。 聚类算法被认为是聚类大量数据集的工具。 我们选择了三种最新的聚类算法,并根据性能指标将它们与其他算法进行了比较,即有效创建集群,处理大量集群的能力以及所选的数据结构。
3.1 流KM ++聚类算法 (3.1 Stream KM++ Clustering Algorithm)
Stream KM++ clustering algorithm is based on the idea of k -MEANS++ and Lloyd’s algorithm (also called k -MEANS algorithm) [3]. Lloyd’s algorithm is one of the famous clustering algorithms. Best clustering in Lloyd’s algorithm is achieved by assigning each point to the nearest center in a given sent of centers (fixed) and MEAN of these points is considered as the best center for the cluster. Also, k -MEANS++ serves as a seeding method for Lloyd’s algorithm. It gives a good practical result and guarantees a quality solution. Both algorithms are not suitable for the data streams as they require random access to the input data.
流 KM ++聚类算法基于k -MEANS ++和劳埃德算法(也称为k -MEANS算法) [3]。 劳埃德算法是著名的聚类算法之一。 劳埃德算法中的最佳聚类是通过将每个点分配给给定发送的中心(固定)中的最近中心来实现的,这些点的MEAN被认为是聚类的最佳中心。 同样, k -MEANS ++用作劳埃德算法的播种方法。 它提供了良好的实践结果,并保证了质量解决方案。 这两种算法都不适合数据流,因为它们需要随机访问输入数据。
Def: Stream KM++ computes a representative small weighted sample of the data points (known as a coreset) via a non-uniform sampling approach in one pass, then it runs k -MEANS++ on the computed sample and in a second pass, points are assigned to the center of nearest cluster greedily. Non-uniform sampling is a time-consuming task. The use of coreset trees has decreased this time significantly. A coreset tree is a binary tree that is associated with hierarchical divisive clustering for a given set of points. One starts with a single cluster that contains the whole set of points and successively partitions existing clusters into two sub-clusters, such that points in one sub-cluster are far from the points in another sub-cluster. It is based on merge and reduces technique i.e. whenever two samples with the same number of input points are detected, it takes the union of these points in the merge phase and produces a new sample in the reduced phase which uses coreset trees.[4]
Def: Stream KM ++通过非均匀采样方法在一次通过中计算数据点的代表性小加权样本(称为核心集),然后在计算的样本上运行k -MEANS ++,在第二次通过中,分配点贪婪地到达最近的星团的中心。 非均匀采样是一项耗时的任务。 这次, 核心集树的使用已显着减少。 核心集树是与给定点集的分层除法聚类关联的二叉树。 一个群集从包含整个点集的单个群集开始,然后将现有群集依次划分为两个子群集,以使一个子群集中的点与另一个子群集中的点相距甚远。 它基于合并和归约技术,即,每当检测到两个具有相同输入点数量的样本时,它将在合并阶段合并这些点,并在归约阶段使用核心集树生成新样本。[4]
In comparison with BIRCH (A top-down hierarchical clustering algorithm), Stream KM++ is slower but in terms of the sum of squared errors, it computes a better solution up to a factor of 2. Also, it does not require trial-and-error adjustment of parameters. Quality of StreamLS algorithm is comparable to Stream KM++ but running time of Stream KM++ scales much better with the number of cluster centers than StreamLS. Stream KM++ is faster on large datasets and computes solutions that are on a par with k -MEANS++.
与BIRCH(自上而下的层次聚类算法)相比, Stream KM ++速度较慢,但就平方误差的总和而言,它计算出的最佳解决方案高达2倍。而且,它不需要反复试验。参数的误差调整。 流 LS算法的质量可媲美流 KM ++但比流 LS集群中心的数量要好得多流 KM ++秤的运行时间。 在大型数据集上, Stream KM ++更快,并且可以计算与k -MEANS ++相当的解决方案。
3.2动态物联网数据流的自适应集群 (3.2 Adaptive Clustering for Dynamic IoT Data Streams)
A dynamic environment such as IoT where the distribution of data streams changes overtime requires a type of clustering algorithm that can adapt according to the flowing data. Many stream clustering algorithms are dependent on different parameterization to find the number of clusters in data streams. Determining the number of clusters in the unknown flowing data is one of the key tasks in clustering. To deal with this problem, an adaptive clustering method is introduced by P. B. Daniel Puschmann and R. Tafazoll in this research paper [5]. It is specifically designed for IoT stream data. This method updates the cluster centroids upon detecting a change in the data stream by analyzing its distribution. It allows us to create dynamic clusters and assign data to these clusters by investigating data distribution settings at a given time instance. It is specialized in adapting to data drifts of the data streams. Data drift describes real concept drift (explained in 2.3) that is caused by changes in the streaming data. It makes use of data distribution and measurement of the cluster quality to detect the number of categories which can be found inherently in the data stream. This works independently of having prior knowledge about data and thus discover inherent categories.
诸如IoT之类的动态环境,其中数据流的分布会随着时间的变化而变化,这需要一种可以根据流动数据进行适应的聚类算法。 许多流聚类算法依赖于不同的参数化来查找数据流中的聚类数量。 确定未知流动数据中的聚类数量是聚类的关键任务之一。 为了解决这个问题,PB Daniel Puschmann和R.Tafazoll在本文中介绍了一种自适应聚类方法[5]。 它是专门为物联网流数据设计的。 此方法通过分析数据流的分布来检测数据流中的变化,从而更新群集质心。 它允许我们通过研究给定时间实例的数据分发设置来创建动态集群并将数据分配给这些集群。 它专门用于适应数据流的数据漂移。 数据漂移描述了由流数据的更改引起的实际概念漂移(在2.3中进行了说明) 。 它利用数据分布和群集质量的度量来检测可以在数据流中固有地找到的类别数量。 这独立于具有有关数据的先验知识而工作,因此可以发现固有类别。
A set of experiments has been performed on synthesized and intelligent live traffic data scenarios in this research paper [5]. These experiments are performed using both adaptive and non-adaptive clustering algorithms and results are compared based on cluster’ quality metric (i.e. silhouette coefficient). The result has shown that the adaptive clustering method produces clusters with 12.2 percent better in quality than non-adaptive.
在这篇研究论文中,已经对合成的和智能的实时交通数据场景进行了一组实验[5]。 这些实验使用自适应和非自适应聚类算法进行,并基于聚类的质量度量(即轮廓系数)比较结果。 结果表明,自适应聚类方法产生的聚类质量比非自适应聚类好12.2%。
In comparison to Stream KM++ algorithm explained in 3.1, it can be induced that Stream
与3.1中解释的Stream KM ++算法相比,可以推断出Stream
KM++ is not designed for evolving data streams.
KM ++不适用于不断发展的数据流。
3.3 PERCH-一种用于极端聚类的在线分层算法 (3.3 PERCH-An Online Hierarchical Algorithm for Extreme Clustering)
The number of applications requiring clustering algorithms is increasing. Therefore, their requirements are also changing due to the rapidly growing data they contain. Such modern clustering applications need algorithms that can scale efficiently with data size and complexity.
需要集群算法的应用程序数量正在增加。 因此,由于其中包含的数据快速增长,它们的要求也在发生变化。 这样的现代集群应用程序需要能够随着数据大小和复杂性而有效扩展的算法。
As many of the currently available clustering algorithms can handle the large datasets with high dimensionality, very few can handle the datasets with many clusters. This is also true for Stream Mining clustering algorithms. As the streaming data can have many clusters, this problem of having a large number of data points with many clusters is known as an extreme clustering problem. PERCH (Purity Enhancing Rotations for Cluster Hierarchies) algorithm scales mildly with high N (data points) and K (clusters), and thus addresses the extreme clustering problem. Researchers of the University of Massachusetts Amherst published it in April 2017.
由于许多当前可用的聚类算法可以处理具有高维数的大型数据集,因此很少能处理具有许多聚类的数据集。 对于Stream Mining聚类算法也是如此。 由于流数据可以具有许多群集,因此具有许多群集的大量数据点的问题被称为极端群集问题。 PERCH(用于群集层次结构的纯度增强旋转)算法在N(数据点)和K(群集)较高的情况下进行适度缩放,从而解决了极端的群集问题。 麻省大学阿默斯特分校的研究人员于2017年4月发表了该论文。
This algorithm maintains a large tree data structure in a well efficient manner. Tree construction and its growth are maintained in an increment fashion over the incoming data points by directing them to leaves while maintaining the quality via rotation operations. The choice of a rich tree data structure provides an efficient (logarithmic) search that can scale to large datasets along with multiple clustering that can be extracted at various resolutions. Such greedy incremental clustering procedures give rise to some errors which can be recovered using rotation operations.
该算法以高效的方式维护大型树数据结构。 通过将传入的数据点定向到叶子,并通过旋转操作保持质量,以增量方式保持树的构造及其生长。 丰富树数据结构的选择提供了一种有效的(对数)搜索,该搜索可以缩放到大型数据集,并且可以以各种分辨率提取多个聚类。 这种贪婪的增量聚类过程会引起一些错误,这些错误可以使用旋转操作来恢复。
It is being claimed in [6] that this algorithm constructs a tree with the perfect dendrogram purity regardless of the number of data points and without the knowledge of the number of clusters. This is done by recursive rotation procedures. To achieve scalability, another type of rotation operation is also introduced in this research paper which encourages balance and an approximation that enables faster point insertions. This algorithm also possesses a leaf collapsing mode to cope with limited memory challenge i.e. when the dataset does not fit in the main memory (like data streams). In this mode, the algorithm expects another parameter which is an upper bound on the number of leaves in the cluster tree. Once the balance rotations are performed, the COLLAPSE procedure is invoked which merges leaves as necessary to meet the upper bound.
在[6]中要求保护的是,该算法构建的树具有完美的树状图纯度,而与数据点的数量无关,并且不知道簇的数量。 这是通过递归循环过程完成的。 为了实现可伸缩性,本研究论文中还引入了另一种旋转操作类型,该操作鼓励平衡和近似实现更快的点插入。 该算法还具有叶子折叠模式以应对有限的存储挑战,即当数据集不适合主存储时(如数据流)。 在这种模式下,算法需要另一个参数,该参数是群集树中叶数的上限。 完成天平旋转后,将调用COLLAPSE过程,该过程会根据需要合并叶子以达到上限。
In comparison with other online and multipass tree-building algorithms, perch has achieved the highest dendrogram purity in addition to being efficient. It is also competitive with all other scalable clustering algorithms. In comparison with both type of algorithms which uses the tree as a compact data structure or not, perch scales best with the number of clusters K. In comparison with BIRCH, which is based on top-down hierarchical clustering methods in which leaves of each internal node are represented by MEAN and VARIANCE statistics, and these node statistics are used to insert points greedily and there are no rotation operations performed, it has been proved that BIRCH constructs worst clustering as compared to its competitors. In comparison with Stream KM++, it shows that coreset construction is an expensive operation and it does not scale to the extreme clustering problem where K is very large.
与其他在线和多遍树构建算法相比,鲈鱼除效率高外,还获得了最高的树状图纯度。 它与所有其他可伸缩群集算法相比也具有竞争力。 与使用树作为紧凑数据结构或不使用树作为紧凑数据结构的两种算法相比,鲈鱼的最佳扩展群集数为K。与BIRCH相比,BIRCH是基于自顶向下的层次聚类方法,其中每个内部节点由MEAN和VARIANCE统计信息表示,这些节点统计信息用于贪婪地插入点,并且不执行任何旋转操作,已证明BIRCH与其竞争者相比构成最差的聚类。 与Stream KM ++相比,它表明核心集构建是一项昂贵的操作,并且无法扩展到K非常大的极端聚类问题。
PERCH algorithm has been applied on a variety of real-world datasets by writers of this research paper and it has proven as correct and efficient. [6]
本研究的作者将PERCH算法应用于各种现实数据集,并被证明是正确有效的。 [6]
4频繁项集挖掘 (4 Frequent Itemset mining)
Frequent Itemset Mining refers to mine a pattern or item that appears frequently from a dataset. Formally, assume there exist a set I comprising of n distinct items {i1, i2, . . . , in}. A subset of it X, X⊆I is called a pattern. The source of data to be mined is transactions. If a pattern is a subset of a transaction denoted t, X⊆t, then it is said X occurs in t. A metric for Frequent Item Mining is called support. Support of a pattern is the number of how many transactions in which that pattern occurs. For a natural number min sup, given as a parameter, any pattern in which support is greater or equal to it is called a frequent pattern.
频繁项集挖掘是指挖掘从数据集中频繁出现的模式或项目。 形式上,假设存在一个集合I ,该集合I由n个不同的项{i 1 ,i 2 ,...组成。 。 。 ,in}中 。 X的子集X⊆I称为模式。 要挖掘的数据源是交易。 如果模式是表示为t的交易的子集X⊆t ,则称X出现在t中 。 频繁项目挖掘的度量标准称为支持 。 模式的支持是发生该模式的事务数量。 对于作为参数给出的自然数min sup ,任何支持大于或等于它的模式都称为频繁模式。
One of the most famous data structures for Frequent Itemset Mining is FP-Tree [7]. However, FP-Tree requires multiple scanning of item databases, something that is very costly for fast-moving data streams. An ideal algorithm should have a one-pass like property to function optimally.
频繁项集挖掘最著名的数据结构之一是FP-Tree [7]。 但是,FP-Tree需要对项目数据库进行多次扫描,这对于快速移动的数据流而言非常昂贵。 理想的算法应具有类似单次通过的属性才能发挥最佳功能。
Common recurrent property in Data Stream Mining is the utilization of window models. According to Jin et al, there are three types of window model [8]
数据流挖掘中的常见重复属性是窗口模型的利用。 根据Jin等人的说法,窗口模型有三种类型[8]
1. Landmark window In this window model, the focus is to find frequent itemsets from a starting time a to time point b. Consequently, if a is set to 1, then the Mining Algorithm will mine the entire data stream
1. 地标窗口在此窗口模型中,重点是查找从开始时间a到时间点b的频繁项目集。 因此,如果将a设置为1,则挖掘算法将挖掘整个数据流
2. Sliding window From a time point b and given the length of the window a, the algorithm will mine item from time b − a + 1 and b. In other words, it only considers item that enters our window stream at a time
2. 滑动窗口从时间点b开始并给定窗口a的长度,该算法将从时间b − a + 1和b挖掘项目。 换句话说,它只是认为,在同一时间进入我们的窗口流项目
3. Damped window model In this model, we give more weight to newly arrived items. This can be done simply by assigning a decaying rate to the itemsets. 1, t]
3. 阻尼窗口模型在此模型中,我们将更多权重分配给新到达的物品。 只需将衰减率分配给项目集即可完成。 1,t]
4.1基于FP-Tree挖掘数据流中最大频繁项集 (4.1 Mining Maximal Frequent Itemsets in Data Streams Based on FP- Tree)
This work [9] introduces a new algorithm FpMFI-DS, which is an improvement of FpMFI (frequent pattern tree for maximal frequent itemsets) [10] algorithm for the data stream. FpMFI itself is an algorithm to compress the FP-Tree and to check the superset pattern optimally.
这项工作[9]介绍了一种新的算法FpMFI-DS,它是对数据流FpMFI(最大频繁项集的频繁模式树) [10]算法的改进。 FpMFI本身是一种算法,用于压缩FP-Tree并以最佳方式检查超集模式。
FmpMFI-DS is designed to store the transactions in Landmark Window or Sliding Windows. The consequence of adapting Windows for mining is that the FP-Tree needs to be updated when the transaction is out of the window. This is done by tidlist a list of transactions’ ID and a pointer to the ultimate node of the transaction in the tree. Other important details of FpMFI-DS are due to the requirement of having a one-pass algorithm, instead of ordering items in FP-Tree with its frequency, it is done lexicographically.
FmpMFI-DS旨在将事务存储在“地标窗口”或“滑动窗口”中。 使Windows适用于挖掘的结果是,当事务不在窗口中时,需要更新FP-Tree。 这是通过tidlist做交易ID列表和一个指向树中的交易的最终节点。 FpMFI-DS的其他重要细节是由于需要使用一次遍历算法,而不是按频率顺序对FP-Tree中的项目进行排序,而是按字典顺序进行。
A further improvement of FpMFI-DS is the introduction of a new technique called ESEquivPS. In ESEquivPS. From an experiment by the authors, the size of the search space can be reduced by about 30%.
FpMFI-DS的进一步改进是引入了一种称为ESEquivPS的新技术。 在ESEquivPS中。 根据作者的实验,搜索空间的大小可以减少约30%。
4.2在事务数据库和动态数据流中挖掘最大频繁模式:一种基于火花的方法 (4.2 Mining maximal frequent patterns in transactional databases and dynamic data streams: A spark-based approach)
In this work [11], Karim et al describes how to build a tree-like structure to mine Maximal Frequent Pattern effectively. Maximal Frequent Patterns refers to patterns with a maximal number of items, that is: it should not have any superset patterns.
在这项工作中[11], Karim等人描述了如何构建树状结构来有效挖掘最大频繁模式。 最大频繁模式是指项目数量最多的模式,即:它不应具有任何超集模式。
For example, assume that in our transaction database, there are three patterns AB, BC, and ABD with the occurrences of 7, 5, and 3. If we decide that the minimum support is 2, all of them are frequent patterns. However, AB is not a maximal frequent pattern, since it is a subset of ABD which is a frequent pattern.
例如,假设在我们的交易数据库中,存在三种模式AB,BC和ABD,它们的出现次数分别为7、5和3。如果我们确定最小支持为2,则它们都是频繁模式。 但是,AB不是最大的频繁模式,因为它是频繁模式ABD的子集。
The author utilized prime numbers for having faster computation and lower memory computation. The idea is that each distinct item from the database is represented as a distinct prime number. A transaction is represented as the multiplication of the prime number representing each item in that transaction which is called Transaction Value. From these formulations, there are few interesting properties.
作者利用质数来实现更快的计算和更低的内存计算。 这个想法是将数据库中每个不同的项目都表示为一个不同的素数。 交易表示为代表该交易中每个项目的质数的乘积,称为交易值。 根据这些公式,几乎没有有趣的特性。
1. A huge number of possible distinct items For a 32-bit integer, the biggest prime number is 105097565 thus theoretically we can represent around 100 million different items. However, the computation of Transaction Value may result in Integer Overflow, thus class like BigInteger is used.
1. 大量可能的不同项目对于32位整数,最大质数为105097565,因此从理论上讲,我们可以表示大约1亿个不同项目。 但是,交易值的计算可能会导致整数溢出,因此使用了BigInteger之类的类。
2. No two different transactions have the same Transaction Value. Since the Transaction Value is the product of prime numbers, it is trivial to show that every Transaction Value should be unique and bijective.
2. 没有两个不同的交易具有相同的交易价值 。 由于交易价值是素数的乘积,因此证明每个交易价值都应该是唯一的且是双射的很简单。
3. Greatest Common Divisor to denote common item If δ is the GCD of the Transaction Value of a transaction α and the Transaction Value of a transaction β, we can get the common items from those two transactions by factoring δ
3. 表示公共项目的最大公因数如果δ是交易的交易价值α的GCD和交易的交易价值β的GCD,我们可以通过分解δ来从这两个交易中获得公共项目。
With the Transaction Value of the transaction, a tree-like structure called ASP-tree is constructed. Inside this structure, the Transaction Value and its count is preserved. Furthermore, the tree contains the following invariants
利用交易的交易价值,构造了一个称为ASP-tree的树状结构。 在此结构内部,保留了交易值及其计数。 此外,树包含以下不变量
1. Every node α is a descendant direct or indirect of all nodes in which TV value is a multiple of TV of α.
1.每个节点α是TV值是α的TV的倍数的所有节点的直接或间接后代。
2. The count of each node is the total support of the transaction represented by its TV
2.每个节点的数量是其电视代表的交易的总支持
The authors also introduce the MFPAS algorithm to generate the Maximal Frequent Itemsets from the ASP-tree. The algorithm simply scans the tree bottom-up and do necessary pruning to get the relevant Transaction Value to be decoded to a real list of items. Interestingly, all information to get the frequent itemset are available on the tree without a need to scan the database.
作者还介绍了MFPAS算法,以从ASP树生成最大频繁项集。 该算法仅对树进行自下而上的扫描,并进行必要的修剪,以获取相关的交易值,以将其解码为真实的项目列表。 有趣的是,获取频繁项集的所有信息都可以在树上找到,而无需扫描数据库。
The procedure is suitable for either Batch or Data Stream environment. The authors include a Spark Implementation for this procedure. It is also shown that the differences between Batch or Data Stream lie only on using correct Spark API i.e. use Spark Stream API when doing works on stream data, while the proposed algorithm remains intact.
该过程适用于批处理或数据流环境。 作者包括此过程的Spark实施。 还显示了批处理或数据流之间的区别仅在于使用正确的Spark API,即在对流数据进行处理时使用Spark Stream API,而所提出的算法保持完整。
5汇总表 (5 Summary Table)

六,结论 (6 Conclusion)
In this report, we have conducted a survey of recent streaming data algorithms. Each algorithm is explained briefly along with key points and comparisons with other algorithms of the same class. In the end, we have presented a summary table with a crux of all the algorithms explained. We found out that recently introduced algorithms have solved the data problems (e.g. concept drift, data shredding, and sampling) and few of the main challenges (e.g. Memory limitation and data structure) which were considered as drawbacks of algorithms a few years back. As the wheel of advancement has no destination, we expect further evolution in data streams mining algorithms, opening research lines for further developments.
在此报告中,我们对最近的流数据算法进行了调查。 简要说明了每种算法,以及要点和与同类的其他算法的比较。 最后,我们给出了一个汇总表,其中包含了所有已解释算法的关键。 我们发现,最近推出的算法解决了数据问题(例如概念漂移,数据粉碎和采样)以及少数主要挑战(例如内存限制和数据结构),这些挑战被视为几年前算法的缺点。 由于前进的轮子没有终点,我们希望数据流挖掘算法会进一步发展,为进一步的发展打开研究路线。
翻译自: https://medium.com/@kashirabbani/data-streams-mining-c5012ff1b4c1
数据挖掘流程















 8943
8943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









