





铺装s路画法
Data is a key bet for Intuit as we invest heavily in new customer experiences: a platform to connect experts anywhere in the world with customers and small business owners, a platform that connects to thousands of institutions and aggregates financial information to simplify user workflows, customer care interactions made effective with use of data and AI, etc. Data pipelines that capture data from the source systems, perform transformations on the data and make the data available to the machine learning (ML) and analytics platforms, are critical for enabling these experiences.
数据是Intuit的主要赌注,因为我们在新客户体验上投入了大量资金:一个将世界各地专家与客户和小型企业主联系起来的平台,一个与数千家机构连接并汇总财务信息以简化用户工作流程,客户的平台护理交互通过使用数据和AI等而有效。数据管道从源系统捕获数据,对数据执行转换并将数据提供给机器学习(ML)和分析平台,对于实现这些体验至关重要。
With the move to Cloud data lakes, data engineers now have a multitude of processing runtimes and tools available to build these data pipelines. The wealth of choices has lead to silos of computation, inconsistent implementation of the pipelines and an overall reduction in the effectiveness of extracting data insights efficiently. In this blog article we will describe a “paved road“ for creating, managing and monitoring data pipelines, to eliminate the silos and increase the effectiveness of processing in the data lake.
随着向Cloud数据湖的迁移,数据工程师现在拥有大量的处理运行时和可用于构建这些数据管道的工具。 众多的选择导致了计算孤岛,流水线的实现不一致以及有效提取数据见解的有效性的总体下降。 在这篇博客文章中,我们将描述用于创建,管理和监视数据管道,消除孤岛并提高数据湖中处理效率的“铺平道路”。
在数据湖中处理 (Processing in the Data Lake)
Data is ingested into the lake from a variety of internal and external sources, cleansed, augmented, transformed and made available to ML and analytics platforms for insight. We have different types of pipelines, to ingest data into the data lake, curate the data, transform, and load data into data marts.
数据从各种内部和外部来源被吸收到湖泊中,经过清洗,扩充,转换并提供给ML和分析平台以进行洞察。 我们有不同类型的管道,用于将数据提取到数据湖,整理数据,转换数据并将数据加载到数据集市。
摄取管道 (Ingestion Pipelines)
A key tenet of data transformation is to ensure that all data is ingested into the data lake and made available in a format that is easily discoverable. We standardized on Parquet as the file format for all ingestion into the data lake, with support for materialization (mutable data sets). The bulk of our datasets are materialized through Intuit’s own materialization engine, though Delta Lake is rapidly gaining momentum as a materialization format of choice. A data catalog built using Apache Atlas is used for searching and discovering the datasets, while Apache Superset is used for exploring the data sets.
数据转换的主要原则是确保所有数据都被吸收到数据湖中并以易于发现的格式提供。 我们对Parquet进行了标准化,将其作为所有数据仓库中的所有文件格式,并支持实现(可变数据集)。 我们的大部分数据集都是通过Intuit自己的实现引擎实现的,尽管Delta Lake作为选择的实现格式正在Swift获得发展。 使用Apache Atlas构建的数据目录用于搜索和发现数据集,而Apache Superset用于探索数据集。
ETL管道和数据流 (ETL Pipelines & Data Streams)
Before data in the lake is consumed by the ML and analytics platform, it needs to be transformed (cleansed, augmented from additional sources, aggregated etc). The bulk of these transformations are done periodically on schedule: once a day, once every few hours, etc, although as we begin to embrace the concepts of real-time processing, there has been an uptick in converting the batch-oriented pipelines to streaming.
在ML和分析平台使用湖中的数据之前,需要对其进行转换(清理,从其他来源扩充,汇总等)。 这些转换的大部分是按计划定期进行的:每天一次,每几个小时一次,等等,尽管随着我们开始接受实时处理的概念,将面向批处理的管道转换为流式传输的趋势有所提高。
Batch processing in the lake is done primarily through Hive and Spark SQL jobs. More complex transformations that cannot be represented in SQL are done using Spark Core. The main engine today for batch processing is AWS EMR. Scheduling of the batch jobs is done through an enterprise scheduler with more than 20K jobs scheduled daily.
湖中的批处理主要通过Hive和Spark SQL作业完成。 无法使用SQL表示的更复杂的转换是使用Spark Core完成的。 如今,用于批处理的主要引擎是AWS EMR。 批处理作业的调度是通过企业调度程序完成的,每天调度超过2万个作业。
Stream pipelines process messages that are read from a Kafka-based event bus, use Apache Beam for analyzing the data streams and Apache Flink as the engine for stateful computation on the data streams.
流管道处理从基于Kafka的事件总线读取的消息,使用Apache Beam分析数据流,并使用Apache Flink作为对数据流进行状态计算的引擎。
为什么我们需要一条“柏油路”? (Why do we need a “Paved Road”?)
With the advent of cloud data lakes and open source, data engineers have a wealth of choices for implementing the pipelines. For batch computation users have the option of picking from AWS EMR, AWS Glue, AWS Batch, AWS Lambda from AWS, Apache Airflow data pipelines, Apache Spark etc from Opensource/enterprise vendors. Data Streams can be implemented on AWS Kinesis streams, Apache Beam, Spark Streaming, Apache Flink etc.
随着云数据湖和开放源代码的到来,数据工程师拥有许多实现管道的选择。 对于批处理计算,用户可以选择从AWS EMR,AWS Glue,AWS Batch,来自AWS的AWS Lambda,来自开放源代码/企业供应商的Apache Airflow数据管道,Apache Spark等中进行选择。 数据流可以在AWS Kinesis流,Apache Beam,Spark流,Apache Flink等上实现。
Though choice is a good thing to aspire to, if not applied carefully can lead to fragmentation and islands of computing. As users adopt different infrastructure and tools for their pipelines it can inadvertently lead to silos and inconsistencies in the capabilities across pipelines.
尽管选择是一件好事,但如果应用不当,则会导致碎片化和计算孤岛。 当用户为他们的管道采用不同的基础结构和工具时,可能会无意间导致跨管道的孤岛和功能不一致。
Lineage: Different infrastructure and tools provide different levels of lineage and in some cases none at all and do not integrate with each other. For example pipelines built using EMR do not share the lineage with pipelines built using other frameworks.
沿袭 :不同的基础架构和工具提供不同级别的沿袭,在某些情况下根本没有,并且彼此不集成。 例如,使用EMR构建的管道不会与使用其他框架构建的管道共享血统。
Pipeline Management: Creation and Management of pipelines can be different and inconsistent across different pipeline infrastructures.
管道管理 : 管道的创建和管理在不同的管道基础架构中可能是不同的且不一致的。
Monitoring & Alerting: Monitoring and Alerting is not standardized across different pipeline infrastructures.
监视和警报 :监视和警报未在不同的管道基础结构之间标准化。
数据管道的铺装之路 (A Paved Road for Data Pipelines)
A Paved Road for the data pipelines provides a consistent set of infrastructure components and tools for implementing data pipelines.
数据管道的铺平道路为实现数据管道提供了一致的基础结构组件和工具集。
- A standard way to create and manage pipelines 创建和管理管道的标准方法
- A standard way to promote the pipelines from development/QA to production environments. 从开发/质量保证到生产环境的管道升级的标准方法。
- A standard way to monitor, debug, analyze failures and remediate errors in the pipelines. 监视,调试,分析故障和修复管道中错误的标准方法。
- Pipelines tools such for Lineage, Data Anomaly detection and Data Parity checks work consistently across all the pipelines. 流水线,数据异常检测和数据奇偶校验等流水线工具在所有流水线中始终如一地工作。
- A small set of execution environments that host the pipelines and provide a consistent experience to the users of the pipelines. 托管管道并为管道用户提供一致体验的一小组执行环境。
The Paved Road begins with Intuit’s Development Portal where data engineers manage their pipelines.
铺平的道路始于Intuit的开发门户,由数据工程师管理其管道。
Intuit开发门户 (Intuit Development Portal)
Our development portal is an entry point for all developers at Intuit for managing their web applications, microservices, AWS Accounts and other types of assets.
我们的开发门户是Intuit所有开发人员管理其Web应用程序,微服务,AWS账户和其他类型资产的入口。
We extended the development portal to allow data engineers to manage their data pipelines. It is a central location for data engineers to create, manage, monitor and remediate their pipelines.
我们扩展了开发门户,以允许数据工程师管理其数据管道。 它是数据工程师创建,管理,监视和修复其管道的中心位置。
处理器与管道 (Processors & Pipelines)
Processors are reusable code artifacts that represent a task within a data pipeline. In batch pipelines, they correspond to a HiveSQL or Spark SQL code that performs a transformation by reading data from input tables in the data lake and writing the transformed data back to another table. In stream pipelines, messages are read from the event bus, transformed and written back to the event bus.
处理器是可重用的代码工件,它们代表数据管道中的任务。 在批处理管道中,它们对应于HiveSQL或Spark SQL代码,该代码通过从数据湖中的输入表中读取数据并将转换后的数据写回到另一个表中来执行转换。 在流管道中,从事件总线读取消息,将其转换并写回到事件总线。
Pipelines are a series of processors chained together to perform an activity/job. Batch pipelines are typically scheduled or triggered on the completion of other batch pipelines. Stream pipelines execute when messages arrive on the event bus.
管道是一系列链接在一起以执行活动/作业的处理器。 通常在其他批处理管道完成时调度或触发批处理管道。 当消息到达事件总线时,流管道将执行。
Defining the Pipelines
定义管道
Intuit data engineers create pipelines using the data pipeline widget in the development portal. During the pipeline creation, data engineers implement the pipeline’s processors, define its schedule, and specify upstream dependencies or additional triggers required for initiating the pipelines.
Intuit数据工程师使用开发门户中的数据管道小部件创建管道。 在管道创建过程中,数据工程师将实施管道的处理器,定义其时间表并指定上游依赖项或启动管道所需的其他触发器。
Processors within a pipeline specify the datasets they work on and the datasets they output to define the lineage. Pipelines are defined in development/QA environments, tested and promoted to production.
流水线中的处理器指定它们要处理的数据集以及它们输出的数据集以定义谱系。 在开发/ QA环境中定义管道,将其测试并提升为生产。
Managing the Pipelines
管理管道
From the development portal users are able to navigate to their pipelines and manage them. Each pipeline has a custom monitoring dashboard that displays the current active instances of the pipeline and historical instances. The dashboard also has widgets for metrics such as execution time, cpu, memory usage metrics etc. A pipeline specific logging dashboard allows users to look at the pipeline logs and debug in case of errors.
通过开发门户,用户可以导航到其管道并进行管理。 每个管道都有一个自定义的监控仪表板,可显示管道的当前活动实例和历史实例。 仪表板还具有用于度量标准的小部件,例如执行时间,cpu,内存使用率指标等。特定于管道的日志记录仪表板允许用户查看管道日志并在发生错误的情况下进行调试。
Users can edit the pipelines to add or delete processors, change the schedules and upstream dependencies, etc. as a part of the day-to-day operations for managing the pipelines.
用户可以作为管理管道的日常操作的一部分,编辑管道以添加或删除处理器,更改计划和上游依存关系等。
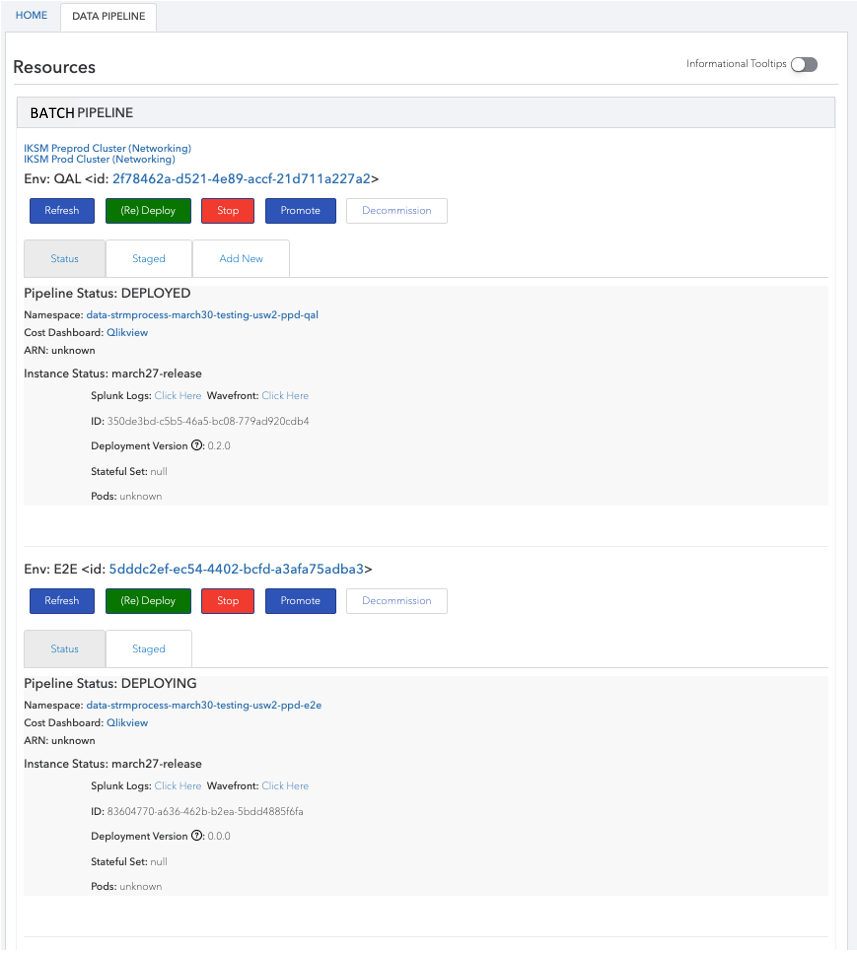
管道执行环境 (Pipeline Execution Environments)
The primary execution environment for our batch pipelines is AWS EMR. These pipelines are scheduled using an enterprise scheduler. This environment has been the workhorse and will continue to remain so, but it has started to show its age. The scheduler built in an enterprise world and has struggled to make the transition to cloud environment. Hadoop/YARN, which forms the basis of AWS EMR have not kept pace with advances in container runtimes. In the target state for batch pipelines we are working towards execution environments that are optimized for container runtimes and cloud native schedulers.
我们的批处理管道的主要执行环境是AWS EMR。 这些管道使用企业调度程序进行调度。 这种环境一直是工作的重心,并将继续保持这种状态,但是它已经开始显示其年代久远。 调度程序构建在企业环境中,一直在努力过渡到云环境。 构成AWS EMR基础的Hadoop / YARN未能跟上容器运行时的发展步伐。 在批处理管道的目标状态下,我们正在努力为容器运行时和云本机调度程序优化的执行环境。
We’re also investing in reducing the friction to switch the pipelines from one execution environment to another. To change the execution environment for example from Hadoop/YARN to Kubernetes, all the data engineer is required to do is to redeploy the pipeline to the new environment.
我们还投资减少摩擦,以将管道从一个执行环境切换到另一个执行环境。 要将执行环境从Hadoop / YARN更改为Kubernetes,数据工程师要做的就是将管道重新部署到新环境。
管道工具 (Pipeline Tools)
A key aspect of a paved road is a comprehensive set of tools for capabilities such as lineage, data parity, anomaly detection, etc. Consistency of tools across all pipelines and their execution environments is crucial for increasing the value we extract from the data and confidence/trust we instill in consumers of this data.
铺装道路的一个关键方面是一套用于功能的综合工具,例如沿袭,数据奇偶校验,异常检测等。所有管道及其执行环境中工具的一致性对于增加我们从数据中提取的价值和信心至关重要/ trust,我们向这些数据的使用者灌输。
Lineage
血统
A lineage tool is critical for the productivity of the data engineers and their ability to operate the data pipelines because it tracks the lineage of all the pipelines from the source systems to the ingestion frameworks to the data lake and the analytics/reporting systems.
沿袭工具对于数据工程师的生产力及其操作数据管道的能力至关重要,因为它可以跟踪从源系统到摄取框架再到数据湖和分析/报告系统的所有管道的沿袭。
Data Anomaly Detection
数据异常检测
Another important tool in the data pipelines arsenal is detection of data anomalies. There is a multitude of data anomalies to consider, including data freshness, lack of new data coming in, missing/duplicated data, etc.
数据管道中的另一个重要工具是检测数据异常。 有许多数据异常需要考虑,包括数据新鲜度,缺少新数据,丢失/重复的数据等。
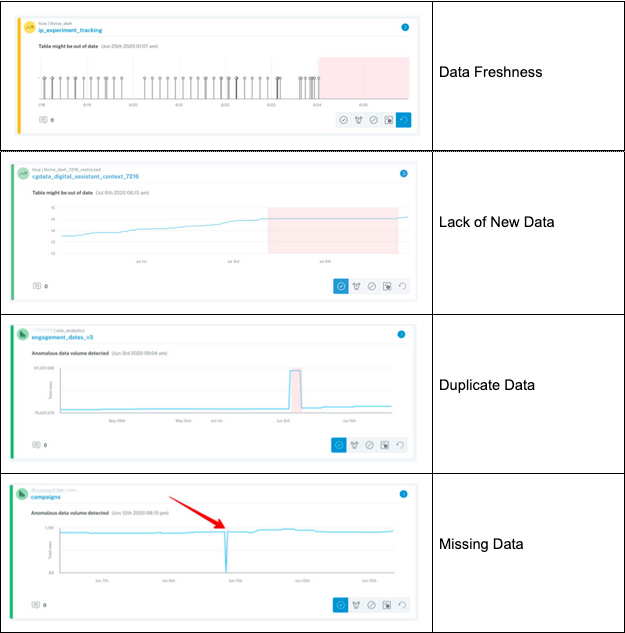
Data anomaly detection tools increase the confidence/trust in the correctness of the data. The anomaly detection algorithms model seasonality, dynamically adjust thresholds, and alert consumers when anomalies are detected.
数据异常检测工具可提高对数据正确性的置信度/信任度。 异常检测算法可对季节性进行建模,动态调整阈值,并在检测到异常时提醒消费者。
Data Parity
数据奇偶校验
Data Parity checks are performed at multiple stages of the data pipelines to ensure the correctness of the data as it flows through the pipeline. Parity checks are another key capability for addressing the compliance requirements such as SOX.
数据奇偶校验在数据管道的多个阶段执行,以确保数据流经管道时的正确性。 奇偶校验是满足合规性要求(如SOX)的另一项关键功能。
结论与未来工作 (Conclusion & Future Work)
Intuit has thousands of data pipelines that span across all business units and across various functions such as marketing, customer success, risk, etc. These pipelines are critical to enabling the data-driven experiences.. The paved road described here provides a consistent environment for managing the pipelines. But, it’s only the beginning of our data pipeline journey.
Intuit拥有成千上万的数据管道,涵盖所有业务部门以及各种功能,例如市场营销,客户成功,风险等。这些管道对于实现数据驱动的体验至关重要。管理管道。 但是,这仅仅是我们数据管道之旅的开始。
Pipelines & Entity Graphs
管道和实体图
Data lakes are a collection of thousands of tables that are hard to discover and explore, poorly documented, and continue to remain difficult to use because they don’t capture the entities that describe a business and the relationships between them. In future, we envision Entity Graphs that represent how business use and extract insights from data. The data pipelines to acquire, transform and serve data will evolve to understand these entity graphs.
数据湖是成千上万个表的集合,这些表很难发现和探索,记录不良,并且由于难以捕获描述业务及其之间关系的实体而仍然难以使用。 将来,我们会设想实体图,这些图代表业务如何使用和从数据中提取见解。 用于获取,转换和提供数据的数据管道将不断发展,以了解这些实体图。
Data Mesh
数据网格
In her paper on “Distributed Data Mesh,” Zhamak Dehghani, principal consultant, member of technical advisory board, and portfolio director at ThoughtWorks, lays the foundation for domain-oriented decomposition and ownership of data pipelines. To realize the vision of a data mesh and successfully enable domain owners to define and manage their own data pipelines, the “paved road” for data pipelines described here is a foundational stepping stone.
ThoughtWorks首席顾问,技术顾问委员会成员兼投资总监 Zhamak Dehghani在其有关“ 分布式数据网格 ”的论文中 ,为面向领域的分解和数据管道所有权奠定了基础。 为了实现数据网格的愿景并成功地使域所有者定义和管理自己的数据管道,此处所述的数据管道“铺平的道路”是基础的垫脚石。
翻译自: https://medium.com/intuit-engineering/a-paved-road-for-data-pipelines-779004143e41
铺装s路画法















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









